






 本文介绍如何在YARN集群中正确配置日志监控功能,包括启用日志聚合、设置日志服务地址等步骤,确保用户能通过YARN Web界面查看任务日志。
本文介绍如何在YARN集群中正确配置日志监控功能,包括启用日志聚合、设置日志服务地址等步骤,确保用户能通过YARN Web界面查看任务日志。
执行spark on yarn 执行:./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn-cluster --executor-memory 1G --num-executors 3 ./lib/spark-examples-1.6.3-hadoop2.6.0.jar 10 命令执行成功后在yarn 资源管理界面查看不了logs
参考博客:https://blog.youkuaiyun.com/lisongjia123/article/details/78639058
问题描述
在yarn上跑一个hadoop任务时,通过yarn的web管理后台(serveraddress:8088)想查看该任务的的任务时,发现提示如下错误:
Java.lang.Exception:Unknown container.Container either has not started or has already completed or doesn;t belong to this node at all.
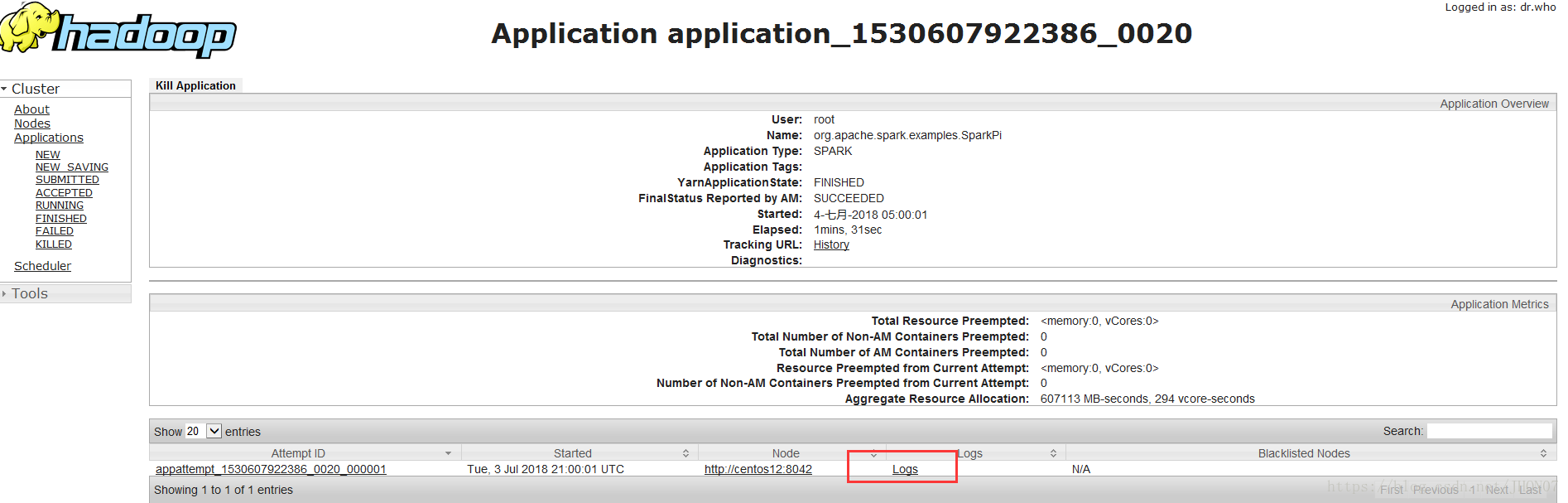

参考博客给出的解放方法
下来查询官方文档后,才了解到yarn的日志监控功能默认是处于关闭状态的,需要我们进行开启,开启步骤如下:
Ps:下面配置的文件的位置在hadoop根目录 etc/haddop文件夹下,比较老版本的Hadoop是在hadoop根目录下的conf文件夹中
一、在yarn-site.xml文件中添加日志监控支持
该配置中添加下面的配置:
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>二、在mapred-site.xml文件中添加日志服务的配置
该配置文件中添加如下配置:
<property>
<!-- 表示提交到hadoop中的任务采用yarn来运行,要是已经有该配置则无需重复配置 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--日志监控服务的地址,一般填写为nodenode机器地址 -->
<name>mapreduce.jobhistroy.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistroy.webapp.address</name>
<value>master:19888</value>
</property>三、将修改后的配置文件拷贝到集群中的其他机器(单机版hadoop可以跳过该步骤)
快捷一点可以使用 scp 命令将配置文件拷贝覆盖到其他机器
scp yarn-site.xml skyler@slave1:/hadoopdir/etc/hadoop/
scp mapred-site.xml skyler@slave1:/hadoopdir/etc/hadoop/
…其他datanode机器同理
四、重新启动集群的Hdfs和Yarn服务
在namenode机器上分别对hdfs和yarn服务进行重启
bin/stop-dfs.sh
bin/start-dfs.sh
bin/stop-yarn.sh
bin/start-yarn.sh
五、 开启日志监控服务进程
在nodenode机器上执行 sbin/mr-jobhistory-daemon.sh start historyserver 命令,执行完成后使用jps命令查看是否启动成功,若启动成功则会显示出JobHistoryServer服务

以上内容执行后log 日志还是不能不来:
后来参考博客:https://blog.youkuaiyun.com/u012037852/article/details/71405054
在yarn-site 中添加了这个超链接就OK 了
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://centos11:19888/jobhistory/logs/</value>
</property>



















 430
430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











