







 本文详细介绍了使用Python进行时间序列数据分析的流程,包括利用pandas处理时序数据,检查数据稳定性(Stationarity)的方法,如Rolling统计和Dickey-Fuller Test,以及通过平滑处理和差分化去除趋势和季节性,使数据稳定。接着,文章演示了如何应用ARIMA模型进行时序数据预测,通过ACF和PACF确定模型参数,并选择最佳模型进行预测。
本文详细介绍了使用Python进行时间序列数据分析的流程,包括利用pandas处理时序数据,检查数据稳定性(Stationarity)的方法,如Rolling统计和Dickey-Fuller Test,以及通过平滑处理和差分化去除趋势和季节性,使数据稳定。接着,文章演示了如何应用ARIMA模型进行时序数据预测,通过ACF和PACF确定模型参数,并选择最佳模型进行预测。
本文主要分为四个部分:
- 用pandas处理时序数据
- 怎样检查时序数据的稳定性
- 怎样让时序数据具有稳定性
- 时序数据的预测
1. 用pandas导入和处理时序数据
第一:导入相关库
# 库函数导入
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
#rcParams设定好画布的大小
rcParams['figure.figsize'] = 15, 6第二:导入数据
# 导入数据
# 下载链接
# https://github.com/aarshayj/analytics_vidhya/tree/master/Articles/Time_Series_Analysis
data = pd.read_csv(path+"AirPassengers.csv")
print (data.head())
print ('\n Data types:')
print (data.dtypes)运行结果如下:数据包括每个月对应的passenger的数目。
可以看到data已经是一个DataFrame,包含两列Month和#Passengers,其中Month的类型是object,而index是0,1,2...
Month #Passengers
0 1949-01 112
1 1949-02 118
2 1949-03 132
3 1949-04 129
4 1949-05 121
Data types:
Month object
#Passengers int64
dtype: object第三步:处理时序数据
需要将Month的类型变为datetime,同时作为index
dateparse = lambda dates: pd.datetime.strptime(dates, '%Y-%m')
#--- 其中parse_dates 表明选择数据中的哪个column作为date-time信息,
#--- index_col 告诉pandas以哪个column作为 index
#--- date_parser 使用一个function(本文用lambda表达式代替),使一个string转换为一个datetime变量
data = pd.read_csv('AirPassengers.csv', parse_dates=['Month'], index_col='Month',date_parser=dateparse)
print (data.head())
print (data.index)结果如下:可以看到data的index已经变成datetime类型的Month了。
#Passengers
Month
1949-01-01 112
1949-02-01 118
1949-03-01 132
1949-04-01 129
1949-05-01 121
DatetimeIndex(['1949-01-01', '1949-02-01', '1949-03-01', '1949-04-01',
'1949-05-01', '1949-06-01', '1949-07-01', '1949-08-01',
'1949-09-01', '1949-10-01',
...
'1960-03-01', '1960-04-01', '1960-05-01', '1960-06-01',
'1960-07-01', '1960-08-01', '1960-09-01', '1960-10-01',
'1960-11-01', '1960-12-01'],
dtype='datetime64[ns]', name='Month', length=144, freq=None)2.怎样检查时序数据的稳定性(Stationarity)
因为ARIMA模型要求数据是稳定的,所以这一步至关重要。
1. 判断数据是稳定的常基于对于时间是常量的几个统计量:
- 常量的均值
- 常量的方差
- 与时间独立的自协方差
用图像说明如下:
- 均值
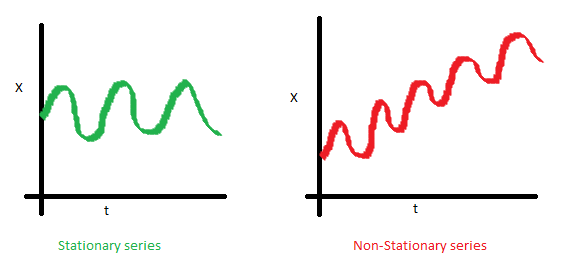
X是时序数据的值,t是时间。可以看到左图,数据的均值对于时间轴来说是常量,即数据的均值不是时间的函数,所有它是稳定的;右图随着时间的推移,数据的值整体趋势是增加的,所有均值是时间的函数,数据具有趋势,所以是非稳定的。 - 方差
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









