



值类型和引用类型

值类型 引用类型 指针类型的区别
值类型 变量存储的是对应的值
引用类型 是某一个变量的别名 相当于一个人拥有两个名字 存储空间地址和某个变量是一致的
指针类型 存储的是一个地址 这个地址对应的空间储存的才是真正的数据


指针与值
&获得当前变量的地址
内存中每一个存储单元都有一个地址
a的存储单元的值是1 存储单元对应的地址为&a
如果存储单元的值是一个指针 那么*就可以获得这个指针对应地址的存储单元的值
而且*只能作用在指针类型
go中都是值传递 没有引用传递 但是map slice chan类型的传递本质上也是值传递 但是传递的值是一个指针
new和make的区别
new 和 make 均是用于分配内存:new 用于值类型和用户定义的类型,如自定义结构,make 用 于内置引用类型(切片、map 和通道)。它们的用法就像是函数,但是将类型作为参数: new(type)、make(type)。
new(T) 分配类型 T 的零值并返回其地址,也就是指向类型 T 的 指针。它也可以被用于基本类型:v := new(int)。
make(T) 返回类型 T 的初始化之后的值, 因此它比 new 进行更多的工作。 new() 是一个函数,不要忘记它的括号。
二者都是内存的分配 (堆上),但是make只用于slice、map以及channel的初始化(非零值);而new用于类型的内存分配,并且内存置为零
new是一个用来分配内存的内置函数,在golang中返回一个指向新分配的类型参数的指针,指针指向的内容为零 被初始化为类型的零值
make返回的是类型本身 因为chan slice map本身就是引用类型 并且初始化
反射
reflect.TypeOf(x) 获得类型
reflect.ValueOf(x) 获得值
x参数是指针时 就要.Elem()获得指针对应地址的值
x参数时结构体时 Filed()获得对应结构体中某个字段
go数据结构
slice map chan interface为引用类型
切片slice
结构图

array指针指向底层数组,len表示切片长度,cap表示底层数组容量

扩容
使用append向Slice追加元素时,如果Slice空间不足,将会触发Slice扩容,扩容实际上重新一配一块更大的内 存,将原Slice数据拷贝进新Slice,然后返回新Slice,扩容后再将数据追加进去

地址是新的地址
扩容操作只关心容量,会把原Slice数据拷贝到新Slice,追加数据由append在扩容结束后完成。上图可见,扩容后 新的Slice长度仍然是5,但容量由5提升到了10,原Slice的数据也都拷贝到了新Slice指向的数组中。 扩容容量的选择遵循以下规则:
如果原Slice容量小于1024,则新Slice容量将扩大为原来的2倍;
如果原Slice容量大于等于1024,则新Slice容量将扩大为原来的1.25倍
每个切片都指向一个底层数组 每个切片都保存了当前切片的长度、底层数组可用容量 使用len()计算切片长度时间复杂度为O(1),不需要遍历切片 使用cap()计算切片容量时间复杂度为O(1),不需要遍历切片 通过函数传递切片时,不会拷贝整个切片,因为切片本身只是个结构体而矣 使用append()向切片追加元素时有可能触发扩容,扩容后将会生成新的切片
map
结构图


tophash是个长度为8的数组,哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈 希值的高位存储在该数组中,以方便后续匹配。
data区存放的是key-value数据,存放顺序是key/key/key/…value/value/value,如此存放是为了节省 字节对齐带来的空间浪费。
overflow 指针指向的是下一个bucket,据此将所有冲突的键连接起来。

哈希冲突
当有两个或以上数量的键被哈希到了同一个bucket时,我们称这些键发生了冲突。Go使用链地址法来解决键冲突。由 于每个bucket可以存放8个键值对,所以同一个bucket存放超过8个键值对时就会再创建一个键值对,用类似链表的 方式将bucket连接起来

哈希扩容 增量扩容
扩容就必须要讲到负载因子
负载因子 = 键数量/bucket数量
go官方的负载因子为6.5
而Go的bucket可能存8个键值对, 所以Go可以容忍更高的负载因子
条件
1.负载因子 > 6.5时,也即平均每个bucket存储的键值对达到6.5个
2.overflow数量 > 2^15时,也即overflow数量超过32768时
渐进式扩容
当负载因子过大时,就新建一个bucket,新的bucket长度是原来的2倍,然后旧bucket数据搬迁到新的bucket。 考虑到如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,Go采用逐步搬迁策略,即每次访 问map时都会触发一次搬迁,每次搬迁2个键值对
等量扩容
所谓等量扩容,实际上并不是扩大容量,buckets数量不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对 重新排列一次,以使bucket的使用率更高,进而保证更快的存取。在极端场景下,比如不断的增删,而键值对正好集 中在一小部分的bucket,这样会造成overflow的bucket数量增多,但负载因子又不高,从而无法执行增量搬迁的 情况
map并不是线程安全的
要么加读写锁
要么使用sync.map
sync.map的结构

-
为什么多线程是安全
- 内部分为两个map,read和dirty,读写分离,读取时原子操作;即使在读取时有删除操作也不影响;
- 更改和插入数据时,在内部会加锁
具体操作
| 主要字段 | read | amended | misses | dirty |
| 作用 | 当dirty有read没有的key时则标记为true | 当misses等于dirty的长度时 触发dirty 数据覆盖到read中(主要时把新增的key给到read)dirty设为nil misses设为0 amended设为false | ||
| 增 | 首先查找read 肯定发现read中不存在 如果amended为false 则把amended设为true 给dirty加锁 把read的数据复制到dirty中 删除掉标记为删除的数据 在dirty中新增数据 misses不操作 给dirty解锁 如果amended就为true则无需修改 给ditry加锁 在dirty中新增数据 misses无需操作 给dirty解锁 | |||
| 删 | 首先在read中查找 如果找到则原子操作数据修改为删除标记(实际上没有删除) 如果没有找到 且amended为false 则结束操作 如果没有找到 且amened为true 则给dirty加锁 在dirty中查找 如果有数据就删除数据 给dirty解锁 | |||
| 改 | 首先在read中查找 如果找到且没有标记为删除 则原子操作修改 如果找不到 且amended为false 则结束操作 如果找不到 且amended为true 则给dirty加锁 去dirty中查找 在dirty查找 如果有数据就修改 给dirty解锁 | |||
| 查 | 首先在read中查找 如果找到且没有标记为删除则返回 如果没有找到 且amended为false 则结束操作 如果没有找到且amended为true 则给dirty加锁 在dirty中查找 如果找到则给misses+1 给dirty解锁返回 后续根据misses的操作是否要将dirty覆盖到read | |||
sync.map主要针对读多写少的情况
在读少写多时还是用原生的map加锁处理
在load的时候 会先查找read中的数据 原子操作 如果没有则寻找dirty中的 misses加一
当misses达到一定的值 则dirty覆盖到read中 自身为nil read中的amended为false
在delete时 如果read有则设为nil 如果没有并且amended为true 则去dirty中查找并删除
在store时 如果read有并且没有删除则更新 如果没有则更新到dirty中 并且amended为false的时候将 read没过期的复制到dirty中 然后过期的给个标志
个人总结 使用sync.map的时候 第一次插入 是存到dirty中的 然后如果查询过多 misses变大就会把dirty覆盖到read中 dirty为nil 期间的新增全部都到dirty中
在第一次覆盖后 read中有了数据 不过read中的数据是不会增加的 有新增的数据还是会到dirty中 这时会判断amended 为false就会把read没过期的复制到dirty中 并且之后新增的都会到dirty而且不会再复制了 在read中的过期有标志的也会更新到dirty中
之后一直等到misses变大 循环操作dirty覆盖到read中 dirty为nil
channel
| 操作 | chan正常 无缓存 | chan正常 有缓存 | chan为nil | 已关闭chan |
| 读 <-chan | 没有发送者时阻塞 | 缓存空间为空时阻塞 | 阻塞 | 默认整型类型为0 其他空 |
| 写 chan<- | 没有接收者时阻塞 | 缓存空间满时阻塞 | 阻塞 | panic |
| 关闭 close | 正常关闭 | 正常关闭 | panic | panic |
底层结构

在读写时会加锁保证并发安全
struct
结构体
内嵌与聚合: 外部类型只包含了内部类型的类型名, 而没有field 名, 则是内嵌。外部类型包含了内部类型的类 型名,还有filed名,则是聚合

Tag 本身是一个字符串,但字符串中却是: 以空格分隔的 key:value 对 。 key : 必须是非空字符串,字符串不能包含控制字符、空格、引号、冒号。 value : 以双引号标记的字符串 注意:冒号前后不能有空格
Tag是Struct的一部
常见的tag用法,主要是JSON数据解析、ORM映射等。
func main() {
s := Server{}
st := reflect.TypeOf(s)
field1 := st.Field(0)
fmt.Printf("key1:%v\n", field1.Tag.Get("key1"))
fmt.Printf("key11:%v\n", field1.Tag.Get("key11"))
filed2 := st.Field(1)
fmt.Printf("key2:%v\n", filed2.Tag.Get("key2"))
}
unsafe.Pointer
unsafe.Pointer的底层实现原理_gc 和 unsafe.pointer-优快云博客
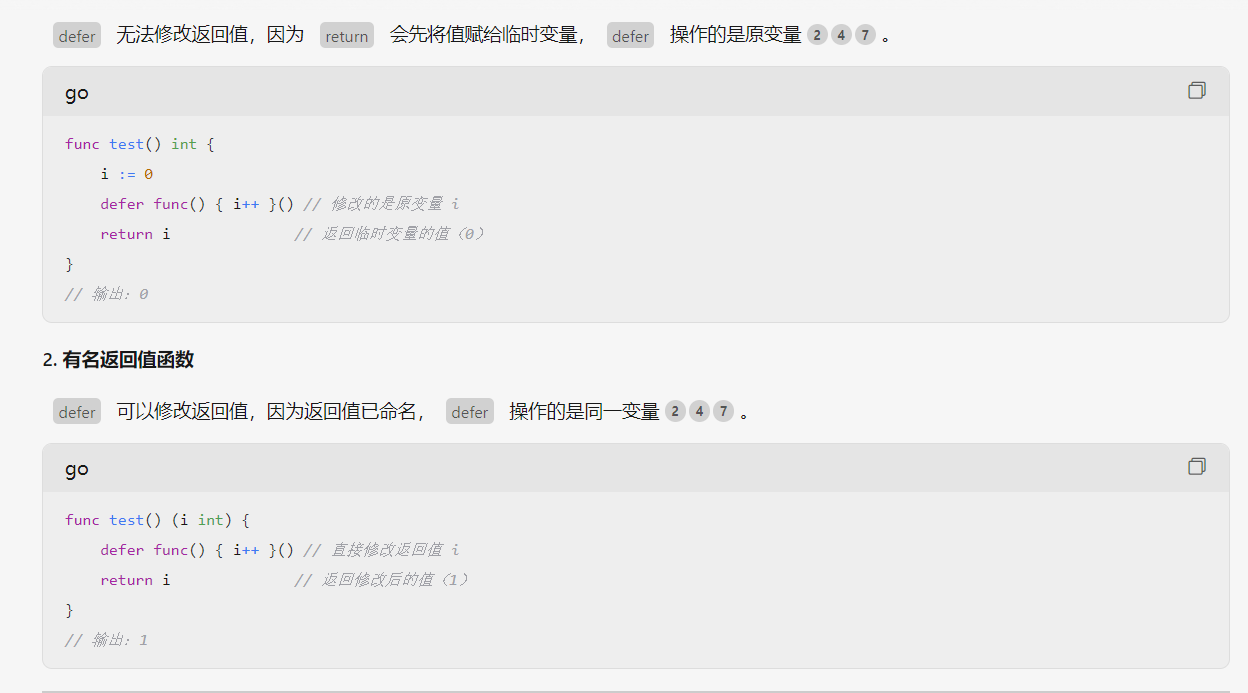
defer
defer语句用于延迟函数的调用,每次defer都会把一个函数压入栈中,函数返回前再把延迟的函数取出并执行
个人实际运用时 就是解锁的时候用到 和recover的时候
异常处理
recover panic
recover()必须配合defer配合使用
panic后就会执行defer的代码
处理并发
并发解决方式
1 加锁
2 go协程和channel
3 atomic
协程之间控制
使用go和channel 就是多协程处理并发 那么多协程之间的操作也需要控制
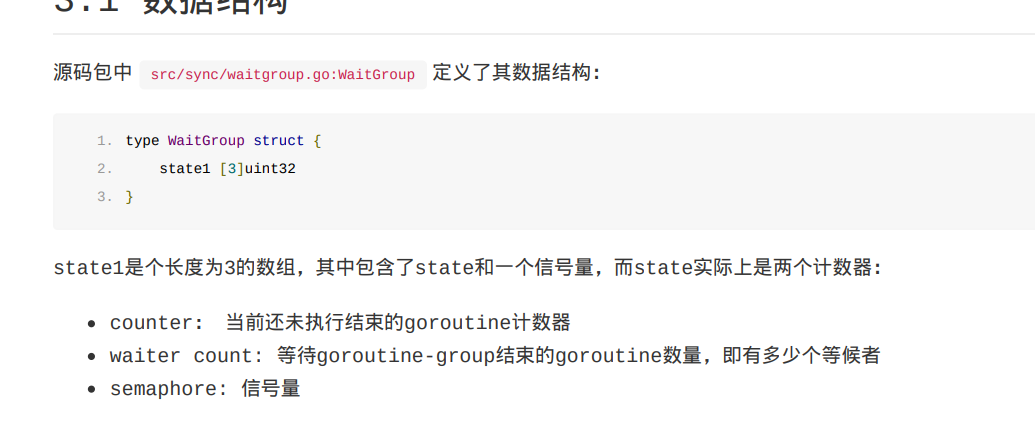
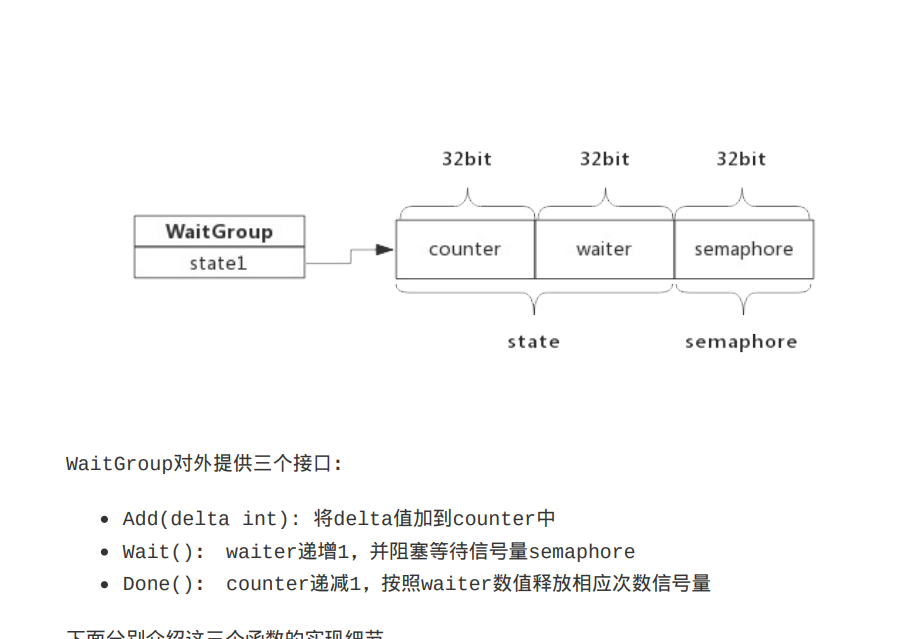
waitgroup
var wg sync.WaitGroup
wg.Add(2)
wg.Done()
wg.Wait()
context
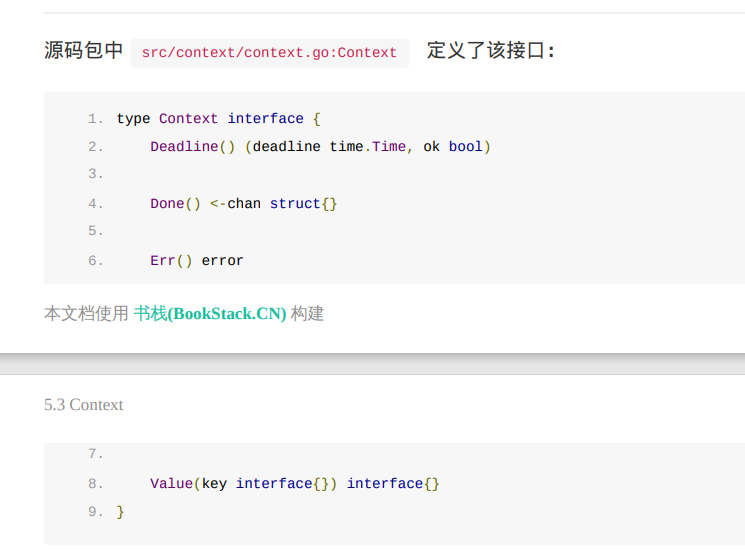
context包提供了4个方法创建不同类型的context,使用这四个方法时如果没有父context,都需要传入 backgroud,即backgroud作为其父节点:
WithCancel()

调用了cancel() 所有的子协程都会收到ctx.Done()

WithDeadline()
WithTimeout()
WithValue()
反射
个人觉得反射就是为了处理interface传进来的类型的
Go提供一组方法提取interface的 value,提供另一组方法提取interface的type
反射第一定律:反射可以将interface类型变量转换成反射对象

反射第二定律:反射可以将反射对象还原成interface对象

interface类型可以进行断言
反射第三定律:反射对象可修改,value值必须是可设置的
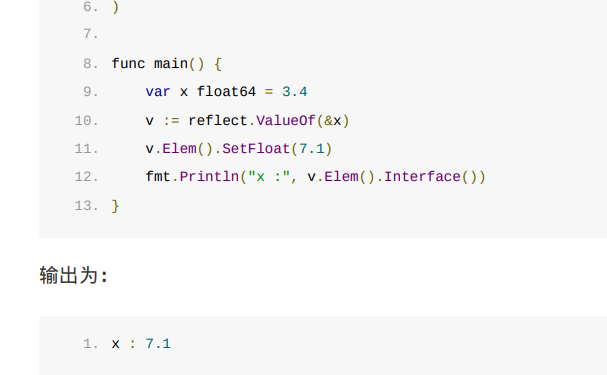
reflect.TypeOf() 返回的是这个结构
type rtype struct {
size uintptr
ptrdata uintptr // number of bytes in the type that can contain pointers
hash uint32 // hash of type; avoids computation in hash tables
tflag tflag // extra type information flags
align uint8 // alignment of variable with this type
fieldAlign uint8 // alignment of struct field with this type
kind uint8 // enumeration for C
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte // garbage collection data
str nameOff // string form
ptrToThis typeOff // type for pointer to this type, may be zero
}这个结构要实现这个接口
reflect.ValueOf() 返回这个结构
type Value struct {
// typ holds the type of the value represented by a Value.
typ *rtype
// Pointer-valued data or, if flagIndir is set, pointer to data.
// Valid when either flagIndir is set or typ.pointers() is true.
ptr unsafe.Pointer
// flag holds metadata about the value.
// The lowest bits are flag bits:
// - flagStickyRO: obtained via unexported not embedded field, so read-only
// - flagEmbedRO: obtained via unexported embedded field, so read-only
// - flagIndir: val holds a pointer to the data
// - flagAddr: v.CanAddr is true (implies flagIndir)
// - flagMethod: v is a method value.
// The next five bits give the Kind of the value.
// This repeats typ.Kind() except for method values.
// The remaining 23+ bits give a method number for method values.
// If flag.kind() != Func, code can assume that flagMethod is unset.
// If ifaceIndir(typ), code can assume that flagIndir is set.
flag
// A method value represents a curried method invocation
// like r.Read for some receiver r. The typ+val+flag bits describe
// the receiver r, but the flag's Kind bits say Func (methods are
// functions), and the top bits of the flag give the method number
// in r's type's method table.
}interface
闭包
闭包(closure)是一个函数以及其捆绑的周边环境状态(lexical environment,词法环境)的引用的组合。 换而言之,闭包让开发者可以从内部函数访问外部函数的作用域。 闭包会随着函数的创建而被同时创建
闭包=函数+引用环境
内存逃逸
逃逸策略
每当函数中申请新的对象,编译器会跟据该对象是否被函数外部引用来决定是否逃逸: 1. 如果函数外部没有引用,则优先放到栈中; 2. 如果函数外部存在引用,则必定放到堆中; 注意,对于函数外部没有引用的对象,也有可能放到堆中,比如内存过大超过栈的存储能力。
逃逸总结
栈上分配内存比在堆中分配内存有更高的效率
栈上分配的内存不需要GC处理
堆上分配的内存使用完毕会交给GC处理
逃逸分析目的是决定内分配地址是栈还是堆
逃逸分析在编译阶段完成
就是对象从栈空间移到了堆空间
逃逸场景
指针逃逸
栈空间不足逃逸
动态类型逃逸
闭包引用对象逃逸
逃逸检测

测试模块gotest
xxxx_test.go创建 TestXXX() 然后 go test
测试文件名必须以”_test.go”结尾;
测试函数名必须以“TestXxx”开始;
命令行下使用”go test”即可启动测试;
性能分析工具pprof
go tool pprof -http=:xxxx
查看性能 火焰图等
内存模型
go实现自主管理内存 为了方便自主管理内存,做法便是先向系统申请一块内存,然后将内存切割成小块,通过一定的内存分配算法管理内存

预申请的内存划分为spans、bitmap、arena三部分。
其中arena即为所谓的堆区,应用中需要的内存从这里分配。
其中spans和bitmap是为了管理arena区而存在的。
arena的大小为512G,为了方便管理把arena区域划分成一个个的page,每个page为8KB,一共有512GB/8KB个 页;
spans区域存放span的指针,每个指针对应一个page,所以span区域的大小为(512GB/8KB)*指针大小8byte = 512M
bitmap区域大小也是通过arena计算出来,不过主要用于GC
分为
heap(全部内存)
arena(里面分成8KB的page)
span(管理arena) 每个span管理一种class 可以有多个span管理同一种class 一种class里有1个或者多个对象 一种class的大小加上碎片是8KB的整数倍
page(8kb)

class的类型大小


上表中每列含义如下:
class: class ID,每个span结构中都有一个class ID, 表示该span可处理的对象类型
bytes/obj:该class代表对象的字节数
bytes/span:每个span占用堆的字节数,也即页数*页大小
objects: 每个span可分配的对象个数,也即(bytes/spans)/(bytes/obj)
waste bytes: 每个span产生的内存碎片,也即(bytes/spans)%(bytes/obj)
上表可见最大的对象是32K大小,超过32K大小的由特殊的class表示,该class ID为0,每个class只包含一个对 象
有了管理内存的基本单位span,还要有个数据结构来管理span,这个数据结构叫mcentral,各线程需要内存时从 mcentral管理的span中申请内存,为了避免多线程申请内存时不断的加锁,Golang为每个线程分配了span的缓存,这个缓存即是cache
alloc为mspan的指针数组,数组大小为class总数的2倍。数组中每个元素代表了一种class类型的span列表,每 种class类型都有两组span列表,第一组列表中所表示的对象中包含了指针,第二组列表中所表示的对象不含有指 针,这么做是为了提高GC扫描性能,对于不包含指针的span列表,没必要去扫描。 根据对象是否包含指针,将对象分为noscan和scan两类,其中noscan代表没有指针,而scan则代表有指针,需要 GC进行扫描

内存分配过程
1. 获取当前线程的私有缓存mcache
2. 跟据size计算出适合的class的ID
3. 从mcache的alloc[class]链表中查询可用的span
4. 如果mcache没有可用的span则从mcentral申请一个新的span加入mcache中
5. 如果mcentral中也没有可用的span则从mheap中申请一个新的span加入mcentral
6. 从该span中获取到空闲对象地址并返回
1. Golang程序启动时申请一大块内存,并划分成spans、bitmap、arena区域
2. arena区域按页划分成一个个小块
3. span管理一个或多个页
4. mcentral管理多个span供线程申请使用
5. mcache作为线程私有资源,资源来源于mcentral
垃圾回收算法
不需要的数据在内存中就是垃圾,需要回收,不然就会造成内存泄漏,说通俗点就是占着内存却没有任何作用


Golang垃圾回收一般分为2个阶段,标记和清除
golang使用三色标记法
白色 灰色 黑色
白色是标记结束后被回收的对象
灰色是正在等待的对象(需要从灰色的对象中找引用的对象 并且标记为灰色 自身变成黑色)
黑色是标记结束后不会被回收的对象
插入写屏障
在一个对象引用另一个对象时(即写操作),如果被引用的对象是白色的,将其标记为灰色
删除写屏障
在删除一个对象的引用时,如果被删除引用的对象是白色的,将其标记为灰色
混合写屏障
Go 1.8 及以后版本采用了混合写屏障,结合了插入写屏障和删除写屏障的优点,减少了 STW 时间
- 栈上的对象:不使用写屏障,在标记开始时对栈进行 STW 扫描,将栈上的对象标记为黑色。
- 堆上的对象:
- 当一个黑色对象引用一个白色对象时,将白色对象标记为灰色。
- 当删除一个对象的引用时,不做特殊处理。
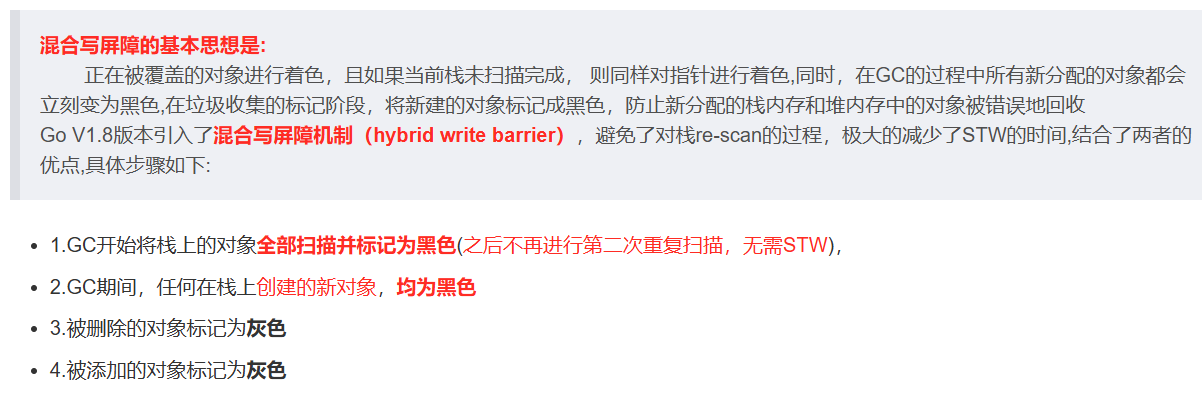
gc的过程
会出现两次stw
会使用混合写屏障
GC的四个阶段
Mark Prepare - STW: 做标记阶段的准备工作,需要停止所有正在运行的goroutine(即STW),标记根对象,启用内存屏障,内存屏障有点像内存读写钩子,它用于在后续并发标记的过程中,维护三色标记的完备性(三色不变性),这个过程通常很快,大概在10-30微秒
Marking - Concurrent:标记阶段会将大概25%(gcBackgroundUtilization)的P用于标记对象,逐个扫描所有G的堆栈,执行三色标记,在这个过程中,所有新分配的对象都是黑色,被扫描的G会被暂停,扫描完成后恢复,这部分工作叫后台标记(gcBgMarkWorker),这会降低系统大概25%的吞吐量,比如MAXPROCS=6,那么GC P期望使用率为6*0.25=1.5,这150%P会通过专职(Dedicated)/兼职(Fractional)/懒散(Idle) 三种工作模式的Worker共同来完成。这还没完,为了保证在Marking过程中,其它G分配堆内存太快,导致Mark跟不上Allocate的速度,还需要其它G配合做一部分标记的工作,这部分工作叫辅助标记(mutator assists),在Marking期间,每次G分配内存都会更新它的”负债指数”(gcAssistBytes),分配得越快,gcAssistBytes越大,这个指数乘以全局的”负载汇率”(assistWorkPerByte),就得到这个G需要帮忙Marking的内存大小(这个计算过程叫revise),也就是它在本次分配的mutator assists工作量(gcAssistAlloc)。
Mark Termination - STW: 标记阶段的最后工作是Mark Termination,关闭内存屏障,停止后台标记以及辅助标记,做一些清理工作,整个过程也需要STW,大概需要60-90微秒,在此之后,所有的P都能继续为应用程序G服务了
Sweeping - Concurrent :在标记工作完成之后,剩下的就是清理过程了,清理过程的本质是将没有被使用的内存块整理回收给上一个内存管理层级(mcache -> mcentral -> mheap -> OS),清理回收的开销被平摊到应用程序的每次内存分配操作中,直到所有内存都Sweeping完成,当然每个层级不会全部将待清理内存都归还给上一级,避免下次分配再申请的开销,比如Go1.12对mheap归还OS内存做了优化,使用NADV_FREE延迟归还内存 这时新增的对象会标记为黑色
而在Marking - Concurrent 阶段,有三个问题:
GC 协程和业务协程是并行运行的,大概会占用 25% 的CPU,使得程序的吞吐量下降
如果业务goroutine 分配堆内存太快,导致 Mark(标记) 跟不上Allocate(分配) 的速度,那么业务goroutine会被招募去做协助标记,暂停对业务逻辑的执行,这会影响到服务处理请求的耗时
Go GC在稳态场景下可以很好的工作,但是在瞬态场景下,如定时的缓存失效,定时的流量脉冲,GC 影响会急剧上升
在Mark Prepare、Mark Termination - STW 阶段,这两个阶段虽然按照官方说法时间会很短,但是在实际的线上服务中,有时会在 trace 图中观测到长达十几 ms 的停顿,原因可能为:OS 线程在做内存申请的时候触发内存整理被“卡住”,Go Runtime 无法抢占处于这种情况的 goroutine ,进而阻塞 STW 完成
个人总结 标记和清理时都是并行的
标记时从root出发 将直接引用的对象标记为灰色
一般是全局变量 然后从灰色的对象中找到引用的对象标记为灰色 并把自身标记为黑色 递归下去
在标记期间其他gorountine也是在运行了 也有有新的对象产生 这时把栈上新的对象都标记为黑色
堆上变换的对象标记为灰色
gmp调度算法
线程数过多,意味着操作系统会不断的切换线程,频繁的上下文切换就成了性能瓶颈。Go提供一种机制,可以在线程中自己实现调度,上下文切换更轻量,从而达到了线程数少,而并发数并不少的效果。而线程中调度的就是 Goroutine
gmp模型当中p作为一个分配器 给本地队列种的g分配m来获得cpu的执行
G(Goroutine): 即Go协程,每个go关键字都会创建一个协程。
M(Machine): 工作线程,在Go中称为Machine。
P(Processor): 处理器(Go中定义的一个摡念,不是指CPU),包含运行Go代码的必要资源,也有调度 goroutine的能力 每个p有一个mcache (缓存span)全局有一个mcentol
M必须拥有P才可以执行G中的代码,P含有一个包含多个G的队列,P可以调度G交由M执行

一般m多于p

M1的来源有可能是M的缓存池,也可能是新建的。当G0系统调用结束后,跟据M0是否能获取到P,将会将G0做不同的 处理: 1. 如果有空闲的P,则获取一个P,继续执行G0。 2. 如果没有空闲的P,则将G0放入全局队列,等待被其他的P调度。然后M0将进入缓存池睡眠

gopprof
参考文章一文搞懂pprof
在本地生成了对应的pprof文件后 可以使用命令 go toole pprof 文件名 进入交互界面
top list web
常见问题
解决循环依赖
golang热更新问题
比较大小
切片 map channel 函数 含有不可比较大小的结构体 不可比较大小
指针可以 == 和!=
map的key 只要可以== 或者!=就能作为key
所以指针能作为key
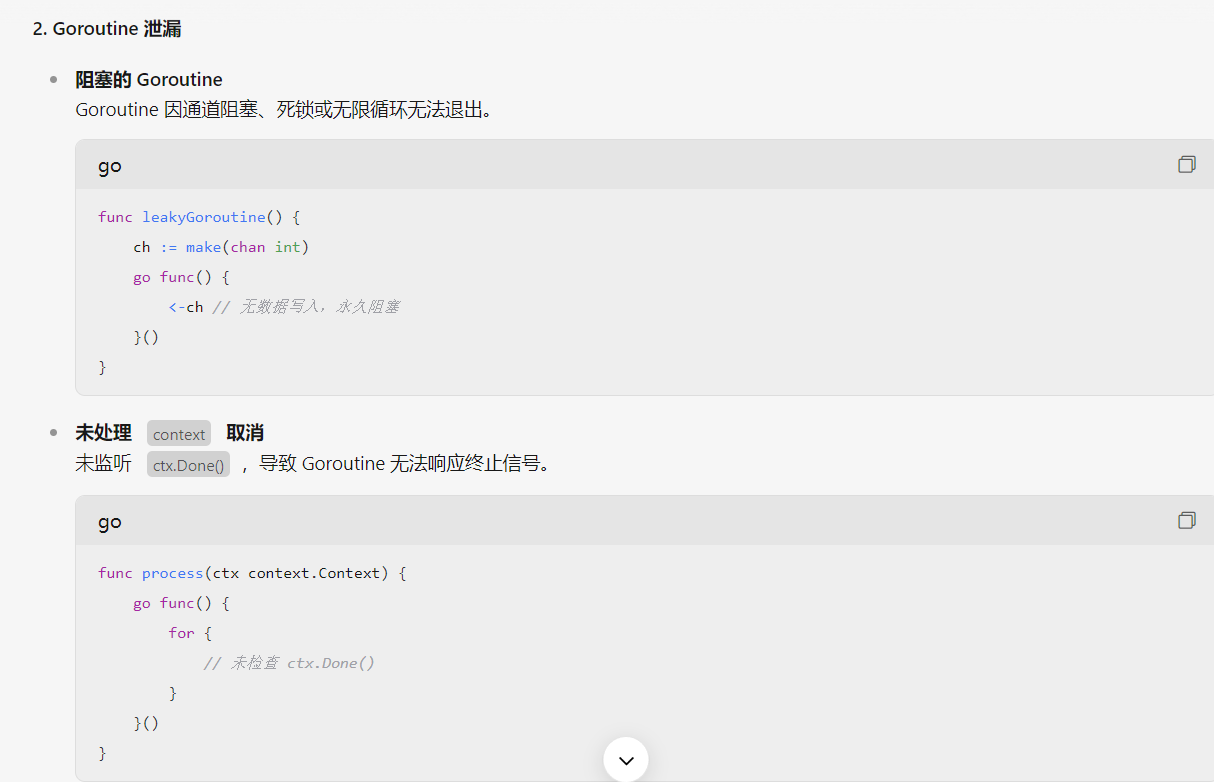
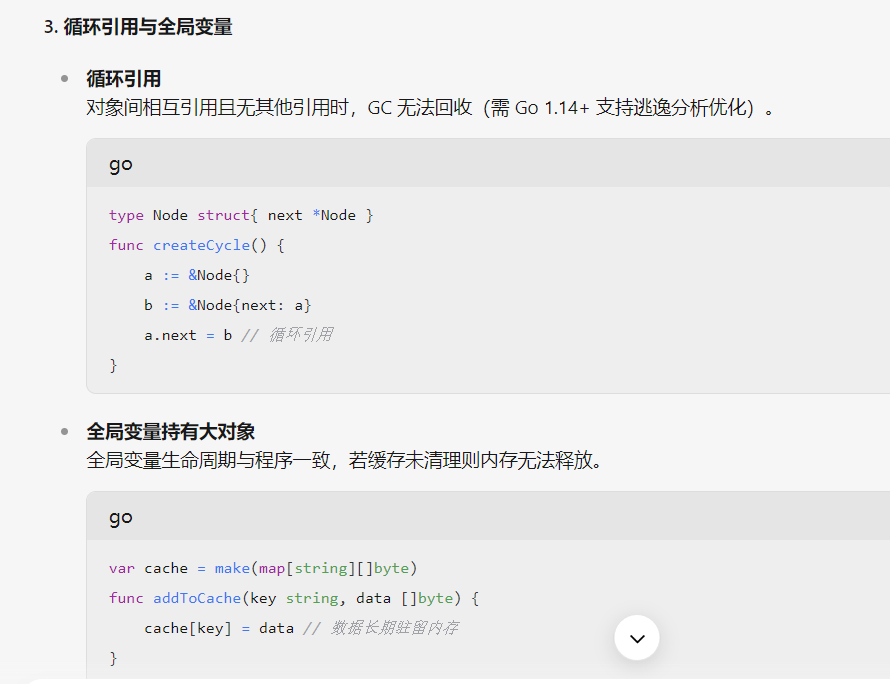
内存泄漏的问题


















 2501
2501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









