







 本文详细介绍了如何高效阅读和理解论文,分为三步:筛选有价值文章、精度阅读和重点研读。通过逐段精读《ResNet》、《Transformer》、《图神经网络》等论文,探讨了深度学习中的关键概念,如残差学习、自注意力机制、图神经网络的挑战和优势。此外,还涵盖了多种模型如BERT、ViT及其应用,并讨论了无监督学习、预训练和模型并行训练等方法。
本文详细介绍了如何高效阅读和理解论文,分为三步:筛选有价值文章、精度阅读和重点研读。通过逐段精读《ResNet》、《Transformer》、《图神经网络》等论文,探讨了深度学习中的关键概念,如残差学习、自注意力机制、图神经网络的挑战和优势。此外,还涵盖了多种模型如BERT、ViT及其应用,并讨论了无监督学习、预训练和模型并行训练等方法。
目录
- 第一遍——选出有价值的文章
- 第二遍——精度部分文章
- 第三遍—重点研读一篇文章
- ResNet论文逐段精读【论文精读】 ——训练比较快
- Transformer论文逐段精读【论文精读】——处理时序信息,如机器翻译
- 零基础多图详解图神经网络(GNN/GCN)【论文精读】
- 5 GAN 论文精度
- BERT ——自然语言处理NLP
- 2. Related work
- 3.BERT (预训练,微调)
- 7-ViT论文逐段精读【论文精读】
- 8-MAE 论文精读
- 12 如何找研究想法1
- 13 MoCo ——无监督表征学习
- 15 Alphafold2 科学界的最大突破2021
- 16 Deepmind 用机器学习帮助数学文章
- 17 Swin transformer (ICCV21最佳论文)
- 18 研究工作的价值
- 19 AlphaFold2
- 20 研究新意度(Novelty)
- 21 CLIP论文 (openAI)未开源
- 22 双流网络论文——视频分类领域开山之作
- 23 GPT, GPT2, GPT3 —— openAI
- openAI codex ——gpt (关注他们解决的问题)
- deepmind alphaCode
- 26 HAI 人工智能的报告
- 27 双流I3D网络—— 视频识别 kinetics (有代码)
- 28 视频理解串
- 29 操作系统方向——参数服务器
- 30 串烧
- GPipe: Efficient training of Giant Neural Networks using Pipeline Parallelism ——系统方向
- title
- abs
- intro
- method
- exp
- conclusion
第一遍——选出有价值的文章
看题目, 摘要,直接看结论
要知道文章,大概讲什么,,方法怎么样
决定要不要继续读
第二遍——精度部分文章
了解作者是怎么想的,怎么讲述东西的
可以从头到尾读,
作者提出的方法,和别人的方法差别有多大,,流程图,,x轴,y轴
读它引用的文献
第三遍—重点研读一篇文章
知道每一句话在干什么,,,重复,实现这一片文章,脑补文章
我会怎么办?能不能走下去?
ResNet论文逐段精读【论文精读】 ——训练比较快
https://www.bilibili.com/video/BV1P3411y7nn/?spm_id_from=333.788
1. intro
介绍应该是,摘要的强化版,介绍工作
解决梯度消失或者梯度爆炸的方法?
- 随机初始化时,不要太大, 也不要太小
- 在中间加入一些正则化,batch normalization,可以使得校验每个层之间的输出,梯度的均值和方差,可以使得很深的网络可以训练
是可以训练,可以收敛,但是精度会变差?
但是这不是过拟合,,因为训练误差也降低了,,而overfitting是说,训练误差很好,测试误差很大
identity mapping
指的是,输入是x, 输出是 x
如果后面的那些层,都学成 x ->x 的结果,那么,更深的网络,也不应该精度变差!
deep residual learning framework
新增加的层,不应该直接去学 h(x), 而应该去学 h(x) - x, 也就是,新增加的层,要去学,,前几层预测值 与 最终结果 之间的残差
那最后的输出,就是 后基层预测的F(x)(理论上应该与,h(x) - x ,越接近越好) + x
2. Related work
残差连接,如何处理输入和输出是不同的情况?
- 输入和输出中添加一些额外的0, 使得这两个形状能对应起来
- 1*1的卷积层,,空间维度上不做改变,可以改变通道
如何适应更深的网络?
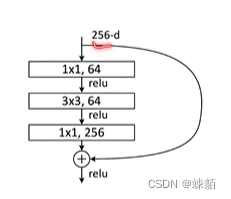
可以用更多的通道数 ,比如256,,如果不想计算力上升的话,,那可以先用11的卷积核 改变通道数,相当于降维,在进行运算,,在用11的卷积核回到原来的维度!
对比SGD 和 ResNet
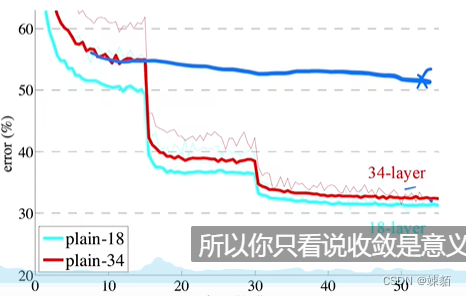
如果训练误差像蓝色一样,,那就需要在中间调一下,学习率,,就会像红色一样了
总结一下,也就是,当训练不动了之后,,需要调节学习率,已达到更优的效果
虽然层数很深,但是模型复杂度不大的话,也不容易过拟合
residual 和 机器学习中gradient boosting不同
gradient boosting 实在标号上做 residual
而,他实在特征上做 residual
Transformer论文逐段精读【论文精读】——处理时序信息,如机器翻译
最近几年,深度学习最重要的文章之一
深度学习模型
- MLP
- Cl
- RNN
- Transformer
abstract
BLEU score: 是机器翻译中,常见的衡量标准
主要是用在机器翻译领域的transformer,之后,bert , bgt把这个架构用在了更多的自然语言处理的任务上,,几乎什么东西都能用
结论
有代码:https://github.com/tensorflow/tensor2tensor
intro
RNN 的特点是什么?缺点是什么?
在RNN中,给定一个序列的话,它的计算是把这个序列从左到右一步一步的往前做
假设一个序列是一个句子的话,一个词一个词的看
对t个词,会计算一个输出,叫ht,,是一个隐藏状态,是有ht-1 和 t 这个词决定的
这样就可以,把前面学到的历史信息放在ht-1加上现在的t,得到输出。
问题是
- 难以并行,在GPU和 TPU上运行困难,计算性能差
- 历史信息一步一步传递,就像串行进位的加法器,,如果时序比较长的话,较前面的信息可能丢掉
但这一块也有很多改进,并行呀,分解呀,但本质上没有解决太多问题
attention在RNN中的应用:
怎么样把编码器的东西 有效的传递给 解码器
** transformer**
纯用attention,并行度高
Background
讲清楚相关工作是谁,联系是什么,区别是什么
第一段:如何用卷积神经网络替换掉循环神经网络,使得减少时序的计算?
CNN: 卷积在做计算时,每一次看一个比较小的窗口,如果两个像素隔得比较远的话,,则需要用很多层的卷积,才能把这两个隔得远的像素点融合起来
如果使用transformer的attention机智的话,,只需要一层就可以看到所有信息
卷积优点是:可以做多个输出通道,一个通道可以识别不同的模式
第二段:自注意力机制
3. model architecture
编码器-解码器架构?
编码器 : 有一个长度为n的序列,对于每一个单词,编码器会 把 它表示成, zt,是每一个单词对应的向量
解码器:拿到编码器的输出,然后会生成一个长度为m的序列,m和n不一定长
auto-regressive : 过去时刻的输出,也会作为当前时刻的输入,,成为 自回归
3.1 Encoder and decoder stacks
layer norm是什么?
** batch norm** : 每一次,把 每一列,就是每一个特征,把它在一个小的mini-batch里面,把它的均值变为0,方差变为1(算出这一列的均值和方差,,正态分布化标准)
在训练时这么做,,在测试机上,是全部的均值和方差,而不是每一列的
batch-norm也会学两个参数,使得能初始化为 任意均值和方差的矩阵
layer-norm : 把每一行,取出来,标准化
layer-norm 用的多,因为,在持续的序列模型中,每个样本长度可能会发成变化
当样本长度相差较大时,计算出的均值和方差差别也很大 ,如果样本序列太长,在训练时,没有见过,那么batchnorm结果可能不怎么好
3.2 注意力层
没听懂
transfromer 对于长信息的处理会更好?
attention 对于模型的假设更少,特征邵,也就是需要大数据量训练
是的,但是transformer需要更大的数据量才能训练出来,,相比如 RNN, 和卷积
5 training
bpe : 提取出词根,使得字典更小
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









