




深入理解CPU缓存:原理、结构、案例与市场趋势全解析
适用人群: 嵌入式工程师、系统开发者、后端/高性能开发者、面试准备者
文末附:面试官常问问题及高分答法
目录
- 什么是CPU缓存?为什么需要它?
- CPU缓存的层级与结构
- 缓存的核心原理
- 缓存的常见类型及工作机制
- 缓存与内存、TLB的关系
- 缓存的主流趋势与市场发展
- 实际项目中的缓存案例详解
- 缓存调优与性能优化实战
- 面试常考问题总结与高分答案
- 总结与学习建议
1. 什么是CPU缓存?为什么需要它?
1.1 概念简述
CPU缓存(Cache)是位于CPU与主存(物理内存)之间的高速、容量较小的临时存储区。它专门缓存最近访问、最频繁使用的数据和指令,目的是加速CPU访问速度,减少等待内存的延迟。
-
通俗类比:
- Cache像你办公桌上常用的文件,主存(物理内存)像远处的档案柜。
- 取用办公桌文件(Cache)很快,去档案柜(主存)则慢许多。
1.2 为什么需要Cache?
- 现代CPU速度极快,但内存速度提升远远跟不上。
- 如果CPU每次都直接访问主存,会极大浪费性能,甚至出现“内存墙(Memory Wall)”现象。
- 通过Cache,CPU大部分数据能在几纳秒内读取,大幅减少等待和空转。
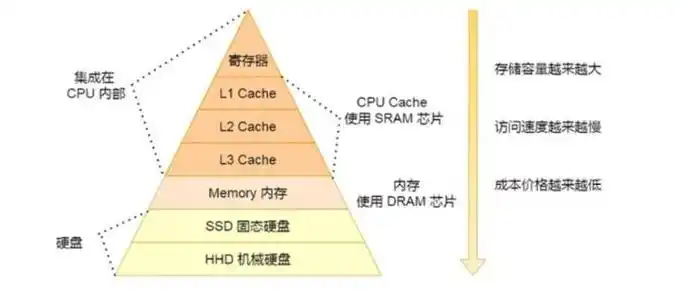
2. CPU缓存的层级与结构
2.1 Cache的分级(L1/L2/L3/L4)
现代CPU普遍采用多级Cache体系:
| 层级 | 所在位置 | 容量 | 速度 | 作用 |
|---|---|---|---|---|
| L1 | 每核内部 | 32~128KB | 极快(1-4ns) | 近期热点数据/指令缓存 |
| L2 | 每核内部/小组共享 | 256KB~2MB | 快(10ns) | 进一步缓解主存压力 |
| L3 | 多核间共享 | 2~64MB | 较快(几十ns) | 加速多核数据共享 |
| L4 | 特定高端平台 | 64MB~几百MB | 慢(百ns级) | 系统级大容量缓存 |
i.MX8MP示例:
- L1 Cache:每核32KB指令+32KB数据
- L2 Cache:所有A53核共享512KB
2.2 Cache的结构
- 指令Cache(I-Cache): 缓存指令
- 数据Cache(D-Cache): 缓存数据
- 统一Cache(Unified Cache): 指令和数据混合存储(通常L2/L3)
- Cache行(Line): Cache的最小管理单位(通常32-128字节)
3. 缓存的核心原理
3.1 局部性原理
-
时间局部性(Temporal Locality):
- 程序中被访问过的数据很快会再次被访问(比如循环变量)
-
空间局部性(Spatial Locality):
- 程序倾向于访问和最近访问地址相邻的数据(如顺序读数组)
3.2 Cache Hit 与 Cache Miss
- Cache Hit: 数据命中缓存,CPU可高速获取
- Cache Miss: 数据未命中缓存,CPU需向更低一级Cache或主存请求,耗时显著增加
Cache Miss的三种类型
- 冷Miss(Cold/Compulsory Miss):首次访问数据,Cache还没装入
- 容量Miss(Capacity Miss):Cache装不下全部需要数据,老数据被替换出
- 冲突Miss(Conflict Miss):不同数据被映射到同一个Cache行,发生替换
4. 缓存的常见类型及工作机制
4.1 Cache的映射方式
-
直接映射(Direct Mapping)
- 每个主存块只对应Cache的一个位置
- 简单、速度快,但易冲突
-
全相联(Fully Associative)
- 每个主存块可放在Cache任意位置
- 灵活、冲突少,但硬件成本高
-
组相联(Set Associative)
- 折中方案,主流CPU常用(如4路、8路组相联)
4.2 替换策略
- LRU(最近最少使用)
- FIFO(先进先出)
- 随机(Random)
4.3 一致性与写策略
- 写回(Write-back): 数据先写Cache,延后写内存
- 写直达(Write-through): 数据同步写Cache和内存
5. 缓存与内存、TLB的关系
5.1 Cache与内存的区别
| 项目 | Cache | 物理内存(主存/DRAM) |
|---|---|---|
| 位置 | CPU内部或芯片上 | 主板上的内存条 |
| 容量 | 小(KB~MB) | 大(GB~TB) |
| 速度 | 极快 | 较慢 |
| 作用 | 缓存热点数据/指令 | 存储全部程序、数据 |
5.2 Cache与TLB的区别
- Cache:缓存实际的数据和指令,加速读写
- TLB(Translation Lookaside Buffer):缓存虚拟地址到物理地址的映射关系,加速地址转换
TLB关注“地址映射”,Cache关注“数据存取”,两者互为补充。
6. 缓存的主流趋势与市场发展
6.1 趋势一:层级加深,容量持续提升
- 新一代CPU L1~L3容量不断增大,部分高端平台引入L4 Cache(如Intel eDRAM)
6.2 趋势二:多核共享Cache设计
- L2/L3 Cache通常为多核共享,提升多线程/多核系统的数据一致性和协作效率
6.3 趋势三:智能Cache管理与分区
- 新型CPU支持Cache QoS(质量管理)、分区和优先级调整,满足AI、图形、网络等多业务需求
6.4 趋势四:专用加速器Cache
- GPU、NPU、DSP等专用核心集成独立Cache,提升异构运算性能
6.5 趋势五:Cache安全性关注提升
- 随着Meltdown、Spectre等安全漏洞,硬件Cache安全成为芯片设计新焦点
7. 实际项目中的缓存案例详解
7.1 案例一:嵌入式图像处理Cache调优
背景: i.MX8MP做实时摄像头帧处理,C代码逐像素操作大矩阵
- 问题:原代码按列优先遍历,Cache Miss率高,帧率低
- 分析:行主存储,列遍历时相邻访问跨度大,数据每次都不在Cache里
- 优化:改为按行优先遍历,Cache命中率大幅提升,系统帧率显著提高
7.2 案例二:高性能Web服务器缓存策略
背景: Web服务请求大量数据库数据
- 问题:频繁读取“热点”数据,访问主存延迟大
- 优化:将热点数据结构优化为连续数组,尽量利用Cache局部性,同时采用内存池和对象复用机制减少分散分配,Cache命中率提升,QPS大幅提高
7.3 案例三:AI/深度学习推理中的Cache命中优化
- 现代AI推理框架(如TensorFlow Lite、ONNX Runtime)重视内存布局、张量对齐和连续分配,尽量让运算核心的数据流在Cache内完成,减少DRAM带宽压力,明显提升模型推理速度。
7.4 案例四:多核系统Cache一致性与False Sharing
- 多线程同时写入同一Cache Line内的不同变量,造成频繁同步和失效,导致性能下降。实际项目通过变量填充和对齐,或优化多线程数据结构,解决False Sharing问题,提升多核性能。
8. 缓存调优与性能优化实战
8.1 优化思路
- 优化数据局部性:顺序访问、结构体合并、数组替代链表
- 减少数据体积:分块处理,精简存储
- 多线程亲和性:保证线程用本地数据
- 避免False Sharing:变量对齐,减少Cache Line竞争
8.2 常用分析工具
- perf(Linux硬件事件分析)
- valgrind cachegrind(函数/行级Cache Miss分析)
- oprofile、ftrace(内核/硬件热点分析)
- Intel VTune/ARM DS-5(商用高阶分析)
8.3 性能分析实战
# 用perf查看cache-miss
perf stat -e cache-misses,cache-references ./your_program
# 用valgrind cachegrind定位代码热点
valgrind --tool=cachegrind ./your_program
cg_annotate cachegrind.out.<pid>
9. 面试常考问题总结与高分答案
Q1: 什么是CPU缓存?为什么需要Cache?
A:
CPU缓存是位于CPU与内存之间的高速临时存储区,用于缓存热点数据和指令,加速CPU数据访问,弥补CPU与主存之间的速度鸿沟。
Q2: Cache命中与未命中(Cache Hit/Miss)是什么意思?
A:
命中(Hit)是指所需数据已在Cache内,CPU能快速访问;未命中(Miss)则要去更低一级缓存或主存读取数据,导致访问延迟增加。
Q3: Cache有几级?各级作用分别是什么?
A:
现代CPU通常有L1/L2/L3甚至L4 Cache,L1速度最快容量最小,每核独有,L2/L3容量更大,多核共享,用于缓解内存瓶颈和多核协作。
Q4: 什么是局部性原理?对缓存设计有何影响?
A:
时间局部性和空间局部性原理决定了程序访问数据/指令有“重复利用”和“相邻访问”特性,这也是Cache加速的理论基础。
Q5: 如何降低Cache Miss?实际优化手段有哪些?
A:
优化数据和指令访问的顺序,提升局部性;采用连续存储结构;合理分块处理大数据集;避免多线程False Sharing等。
Q6: TLB和Cache有什么区别?
A:
TLB缓存虚拟地址到物理地址的映射,加速地址转换;Cache缓存实际的数据和指令,加速内容访问,两者层次和作用不同。
Q7: 如何分析和定位Cache相关的性能瓶颈?
A:
可用perf、valgrind等工具统计cache-miss、cache-references指标,通过报告定位热点函数和问题代码行,再有针对性地优化。
10. 总结与学习建议
- CPU缓存是现代计算系统性能的核心基石之一,理解Cache原理有助于优化任何对性能敏感的系统。
- 学会用工具:perf、valgrind等是开发者的“显微镜”,会用工具,才能科学定位问题。
- 优化从数据结构和访问模式做起,多数性能瓶颈其实就在于局部性优化不够好。
- 关注主流趋势和硬件特性,新一代CPU的Cache架构、AI/NPU Cache、异构Cache等也是必备知识。
- 案例学习很重要:把理论和实际项目结合起来,提升调优和面试通过率。
经典面试真题及答案整理
- Cache和内存的区别与联系?
- Cache Miss的类型及产生原因?
- 为什么多线程容易造成Cache失效?怎么优化?
- 什么是False Sharing?怎么解决?
- TLB Miss和Cache Miss有何区别?对性能影响如何?
- 请举例说明一次Cache Miss可能带来的性能损失和优化思路。
- 在实际项目中,遇到过哪些典型Cache问题?如何解决?
建议对每个问题准备具体案例和工具数据,让回答更有说服力!
附:市场流行趋势与技术走向小结
- 大型云服务器、AI芯片和SoC正不断加大Cache投入,Cache容量、带宽、一致性和安全特性是芯片厂商竞争焦点。
- AI推理、数据中心高性能计算等新场景对Cache友好性要求更高,优化Cache利用是算法/系统设计的重要课题。
- 工业、车载等嵌入式市场,合理利用Cache资源能大幅提升产品响应和能效。
结语
CPU缓存知识是系统性能优化的基础,只有真正理解底层原理并结合实际项目经验,才能写出高效、可扩展的软件。希望本文能帮助你打下坚实的基础,无论是面试、开发还是架构设计,都能自信应对!

















 3556
3556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









