




 本文详细介绍了Kafka作为消息队列的作用、消息模式分类,以及Kafka的架构、启动操作、生产者与消费者的原理。内容涵盖Kafka的分布式特性、消费者组、数据存储机制,并探讨了CAP理论在Kafka中的应用。
本文详细介绍了Kafka作为消息队列的作用、消息模式分类,以及Kafka的架构、启动操作、生产者与消费者的原理。内容涵盖Kafka的分布式特性、消费者组、数据存储机制,并探讨了CAP理论在Kafka中的应用。
kafka消息队列
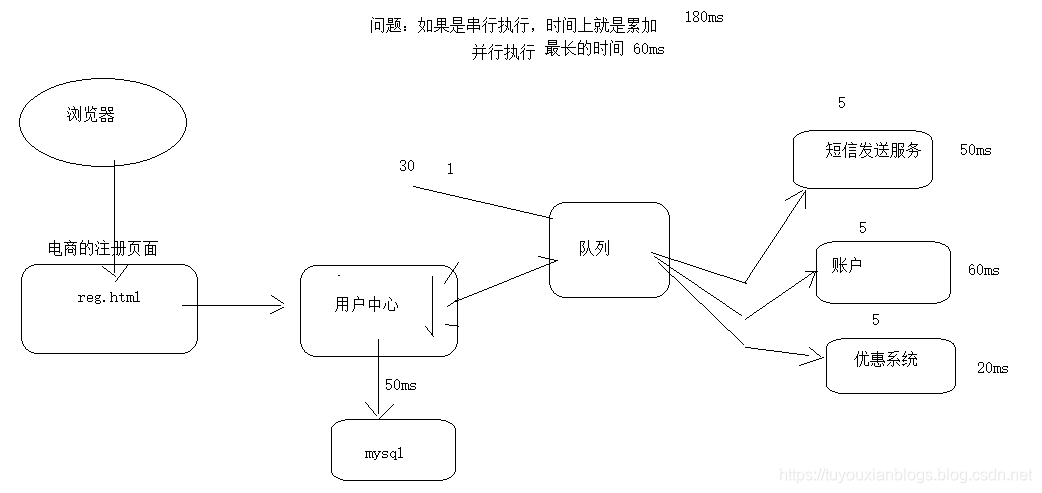
1.消息队列的作用:
- 解耦:快递
- 异构:同步变异步
- 缓冲:削峰填谷,降低下游服务器的压力,减少生产成本
2.消息模式的分类:
- 点对点:生产者生产的消息只能被一个消费者所消费
- 发布/订阅:生产者生产的数据可以被多个消费者所消费
- 主题topic:就是消息的分类
- 生产者:生产数据的系统
- 消费者:获取数据的系统
3.消息队列的介绍
- 大部分都是基于JMS(java message service)的实现
- kafka是类似于JMS的实现
4.kafka介绍:
kafka是linkedin公司开发的分布式消息平台
5.kafka架构
-
四大核心API
- 生产者API–producer
- 消费者API–consumer
- Stream API–Stream processor
- Connector API–Connector
-
架构
- broker:掮客,安装了kafka服务的服务器
- zookeeper:kafka借助于zookeeper协调管理
- producer:生产者采用推的方式发送消息到kafka
- consumer:消费者采用拉的方式从kafka获取消息
- offset:偏移量,记录消费者在整个消息中消费的位置—书签
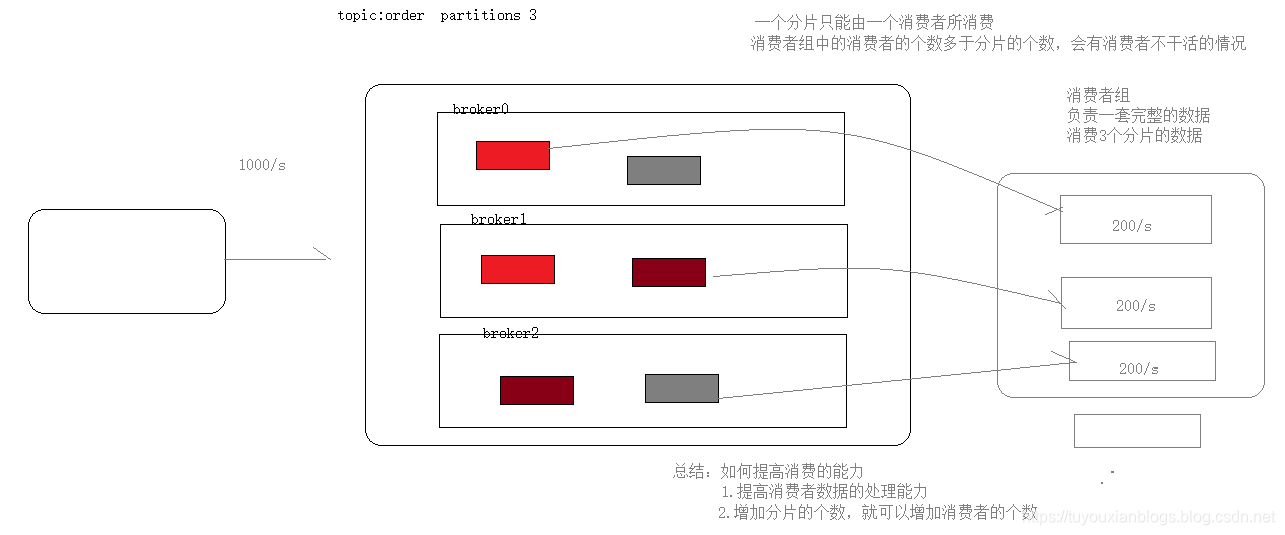
- group:消费者组,每一个消费者组负责一套完整的数据,在一个消费者组中一条数据只能被一个消费者所消费
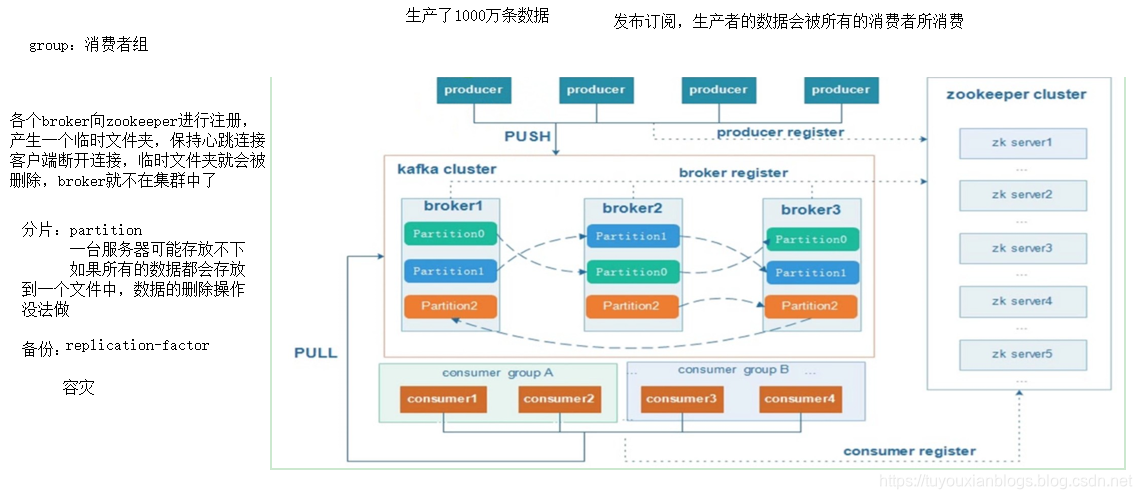
消费者组
kafka的启动
#后台启动命令 --2>&1>/dev/null 建议省略
nohup ./kafka-server-start.sh ../config/server.properties 2>&1>/dev/null &
kafka的操作
1.控制台操作
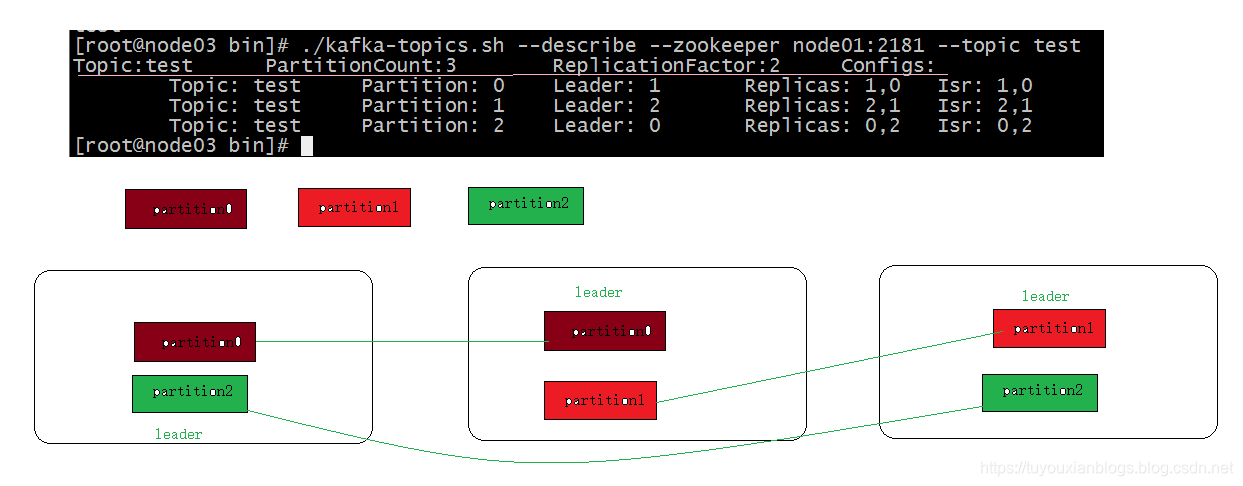
创建topic
./kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic test --partitions 3 --replication-factor 2
模拟一个生产者生产数据
./kafka-console-producer.sh --broker-list node01:9092 --topic test
模拟一个消费者消费数据
./kafka-console-consumer.sh --zookeeper node01:2181 --topic test
删除topic
#1.添加配置
delete.topic.enable=true
#2.topic中没有数据
#3.重启kafka
2.Java API操作
生产者代码
package cn.itcast.cloud.kafka.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* @ClassName OrderProducer
* @Description 创建一个生产者,生产数据到topic:order中
*/
public class OrderProducer {
public static void main(String[] args) {
//生产者配置参数
Properties props = new Properties();
//TODO 部分属性先不讲
props.put("bootstrap.servers", "node01:9092");//hosts文件
props.put("acks", "all");//消息确认 --生产者保证数据不丢失
props.put("retries", 0);//重试的次数
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
//1.创建一个生产者对象 <String,String> key和value的泛型
KafkaProducer<String,String> producer = new KafkaProducer<String,String>(props);
//2.创建一条消息 封装数据的pojo
ProducerRecord<String, String> record = new ProducerRecord<String, String>("order","订单1");
//3.发送数据到kafka集群
producer.send(record);
//4.关闭操作
producer.flush();
//producer.close();
}
}
消费者代码–自动提交
package cn.itcast.cloud.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
/**
* @ClassName OrderConsumer
* @Description 创建一个消费者,消费topic:order中的数据
*/
public class AutomaticConsumer {
public static void main(String[] args) {
//配置消费者参数
//TODO 有3个属性待讲
Properties props = new Properties();
props.put("bootstrap.servers", "node01:9092");
props.put("group.id", "test");//消费者组
props.put("enable.auto.commit", "true");//自动提交
props.put("auto.commit.interval.ms", "1000");//1s修改一次offset值
props.put("session.timeout.ms", "30000");//消费者连接超时时间
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//1.创建一个消费者对象
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(props);
//2.订阅topic:order
consumer.subscribe(Arrays.asList("order"));
while (true){
//3.循环的拉取方式获取数据 批量拉取
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println("当前数据的偏移量:"+record.offset()+" 得到的数据:"+record.value());
}
}
}
}
消费者代码–手动提交
工作中如果对数据的准确定要求比较高的时候,推荐用手动提交offset的方式,而且最好是同步的方式(缺点是性能不高),如果要求不高可以采用自动提交的方式
点对点和发布订阅的一个区别:
-
点对点–消费者可以消费到历史数据
-
发布订阅–默认是不能获取到历史数据
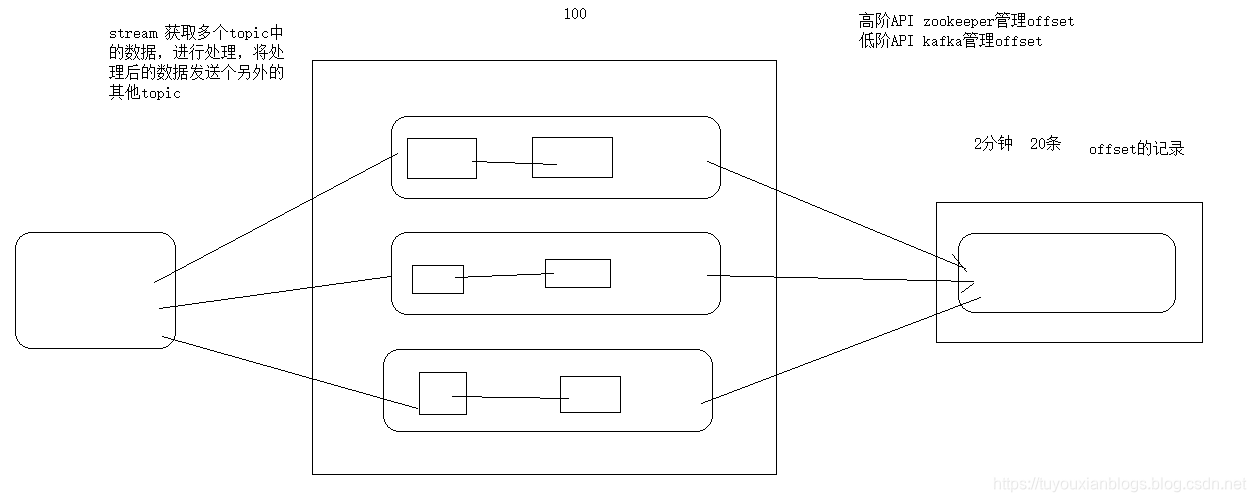
stream-API
分析图
package cn.itcast.cloud.kafka.steam;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStreamBuilder;
import java.util.Properties;
/**
* @ClassName TestToTest2
* @Description TODO 获取test中的数据变成大写,发送到test2中
*/
public class TestToTest2 {
public static void main(String[] args) {
//参数2:配置
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "stream");//中间临时目录
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9092");
props.put(StreamsConfig.KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
//参数1:任务创建对象
KStreamBuilder builder = new KStreamBuilder();
builder.stream("test").mapValues(line -> line.toString().toUpperCase()).to("test2");
//1.创建steam的处理对象
KafkaStreams streams = new KafkaStreams(builder, props);
//2.启动任务
streams.start();
}
}
原理1-生产者
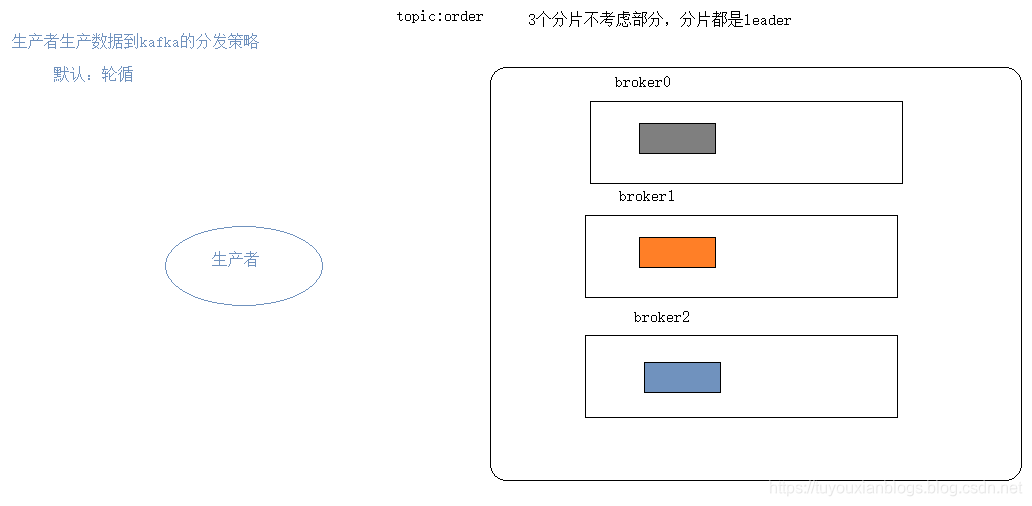
生产者数据分发策略
第一种:指定了partition 就向这个分区去发数据
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, null, key, value);
}
第二种:没有指定分区,但是指定了key ,对key进行hashcode 取模分区数据,key是固定会将所有的数据发送到相同的分区
// hash the keyBytes to choose a partition
return DefaultPartitioner.toPositive(Utils.murmur2(keyBytes)) % numPartitions;
第三种:默认方式–轮循的方式
ProducerRecord中有两个参数:topic 、value
ProducerRecord<String, String> record = new ProducerRecord<String, String>("order","订单"+i);
第四种:自定义,和DefaultPartitioner就没有关系
package cn.itcast.cloud.kafka.partition;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* @ClassName MyPartitioner
* @Description TODO
*/
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return 2;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
//重点指定自定义的分区
props.put("partitioner.class", "cn.itcast.cloud.kafka.partition.MyPartitioner");
原理2-消费者
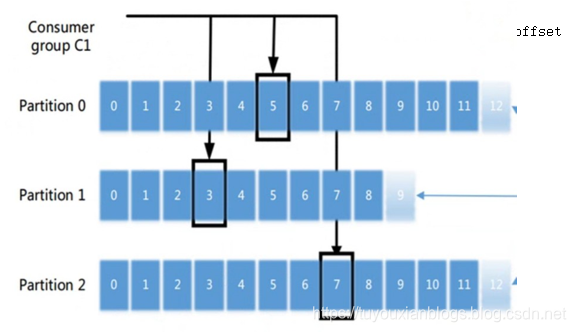
按分区修改偏移量offset
package cn.itcast.cloud.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;
import java.util.*;
/**
* @ClassName PartitionConsumer
* @Description TODO 按照分区进行offset的更新
*/
public class PartitionConsumer {
public static void main(String[] args) {
//配置消费者参数
//TODO 有3个属性待讲
Properties props = new Properties();
props.put("bootstrap.servers", "node01:9092");
props.put("group.id", "test");//消费者组
props.put("enable.auto.commit", "true");//自动提交
props.put("auto.commit.interval.ms", "1000");//1s修改一次offset值
props.put("session.timeout.ms", "30000");//消费者连接超时时间
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//1.创建一个消费者对象
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(props);
//2.订阅topic:order
consumer.subscribe(Arrays.asList("order"));
while (true){
//3.循环的拉取方式获取数据 批量拉取 [2 5 8 ][ 3 6 9 ] [1 4 7 ] 1 2 3 4 5 6 7 8 9
ConsumerRecords<String, String> records = consumer.poll(100);
//3.1获取9条记录所在的所有分区对象 0 1 2
Set<TopicPartition> partitions = records.partitions();
//3.2 将9条记录划分到不同的集合中 每个集合都对应一个分区
for (TopicPartition partition : partitions) {//分片对象 0 1 2
//从9条记录中找出属于当前partition所在的数据
List<ConsumerRecord<String, String>> records1 = records.records(partition);
for (ConsumerRecord<String, String> record : records1) {
System.out.println("当前数据的偏移量:"+record.offset()+" 得到的数据:"+record.value());
}
//3.3按照分区去提交offset
//获取当前列表中最后的一条数据
ConsumerRecord<String, String> record = records1.get(records1.size() - 1);
//根据列表中最后一条记录的偏移量,更新当前分区的offset +1
consumer.commitSync(Collections.singletonMap(partition, new OffsetAndMetadata(record.offset()+1)));
}
}
}
}
消费者指定要消费分区的数据
package cn.itcast.cloud.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import java.util.Arrays;
import java.util.Properties;
/**
* @ClassName ConsumerPartitions
* @Description TODO 消费指定的分区
*/
public class ConsumerPartitions {
public static void main(String[] args) {
//配置消费者参数
//TODO 有3个属性待讲
Properties props = new Properties();
props.put("bootstrap.servers", "node01:9092");
props.put("group.id", "test");//消费者组
props.put("enable.auto.commit", "true");//自动提交
props.put("auto.commit.interval.ms", "1000");//1s修改一次offset值
props.put("session.timeout.ms", "30000");//消费者连接超时时间
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//1.创建一个消费者对象
KafkaConsumer<String,String> consumer = new KafkaConsumer<String, String>(props);
//2.订阅topic:order
//consumer.subscribe(Arrays.asList("order"));
//指定要消费的分片 我要消费分片1和分片2 订阅分区和topic二选一
TopicPartition partition1 = new TopicPartition("order",0);
TopicPartition partition2 = new TopicPartition("order",1);
consumer.assign(Arrays.asList(partition1,partition2));
while (true){
//3.循环的拉取方式获取数据 批量拉取
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println("当前数据的偏移量:"+record.offset()+" 得到的数据:"+record.value());
}
}
}
}
消费者消费数据的三种模式
- at least once 至少一次 数据会发生重复
- at most once 至多一次 数据会发生丢失
- excalty once 恰一次 完美 事务offset是手动提交
High Level API
- 是由zookeeper帮我们管理offset 相对安全,缺点每次消费者都要去zookeeper获取offset(kafka0.8版本前都是由zookeeper维护)
Low Level API
- 是由kafka创建一个topic,维护offset,从broker中选出一个leader负责维护元数据的topic
原理3-数据的存储机制&消息不丢失
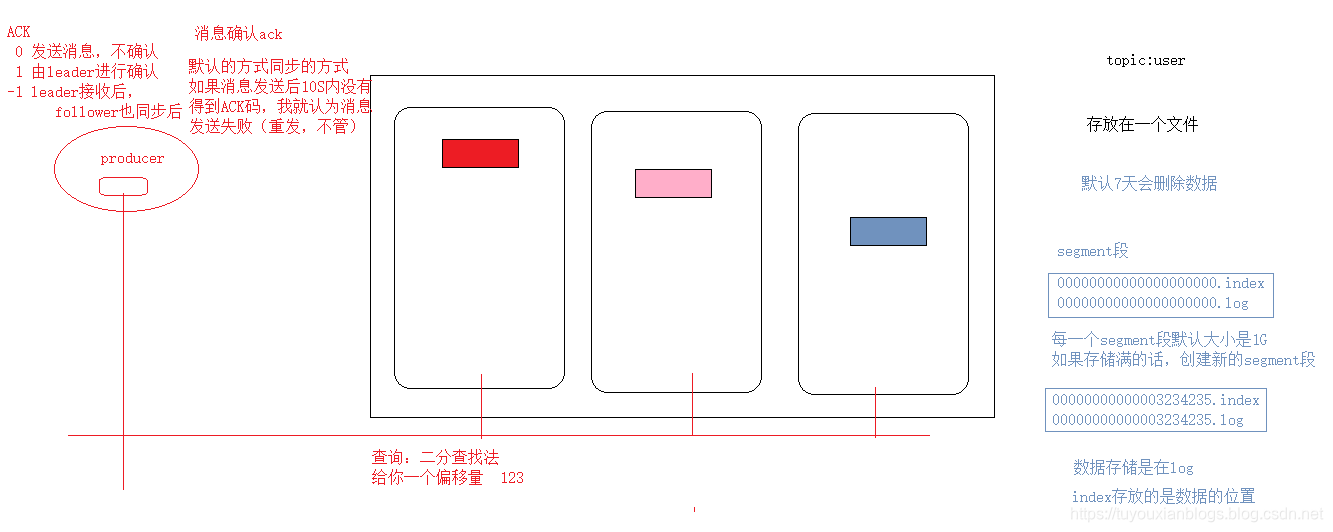
CAP
kafka选择是CA---- P(ISR)

















 1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









