









 本文介绍了图像分类的基础知识,深度学习的发展历程,从AlexNet到VGG、GoogLeNet,再到残差网络ResNet的演变。同时探讨了Transformer在图像分类中的应用,以及轻量化模型如ConvNeXt如何通过优化参数量和计算量来提升效率。
本文介绍了图像分类的基础知识,深度学习的发展历程,从AlexNet到VGG、GoogLeNet,再到残差网络ResNet的演变。同时探讨了Transformer在图像分类中的应用,以及轻量化模型如ConvNeXt如何通过优化参数量和计算量来提升效率。
图像分类与基础视觉模型学习笔记
课程从什么是图像开始逐渐深入,讲解了图像分类与基础视觉模型的基础知识,以及卷积神经网络等。
一、发展
1.问题的数学表示

2.超越规则:让机器从数据中学习:收集数据-定义模型(含参变量的函数)-训练(寻找最佳参数 Θ ∗)-预测(对于新图像 𝑋,用训练好的模型预测其类别)
3.从特征工程到特征学习
(1)传统方法:设计图像特征 (1990s~2000s)

(2)从特征工程到特征学习
方向梯度直方图(Histogram of Oriented Gradients) 在局部区域统计像素梯度的方向的分布,将图像映射成一 个相对低维的特征向量,同时保留足够识别物体的信息

随着卷积神经网络和Transformer的出现,进一步发展为层次化的特征实现,提高了运行的效率:
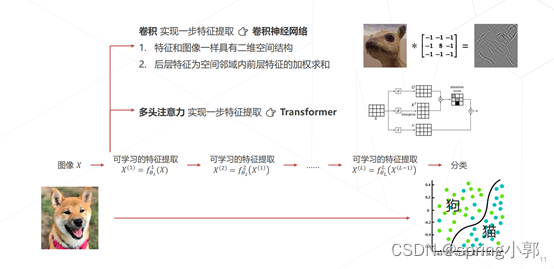
二、深度学习
1.发展过程
AlexNet(2012)→Going Deeper (2012~2014) →VGG (2014)→GoogLeNet (Inception v1, 2014) →残差网络 ResNet (2015)
2.介绍
(1)AlexNet
5 个卷积层,3 个全连接层,共有 60M 个可学习参数,使用 ReLU 激活函数,大幅提高收敛速度。
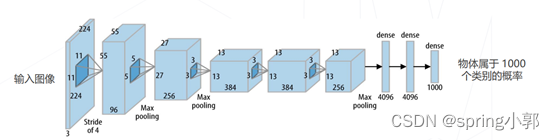
(2)Going Deeper
VGG-19 19 层,将大尺寸的卷积拆解为多层 3×3 的卷,相同的感受野、更少的参数量、更多的层数和表达能力。
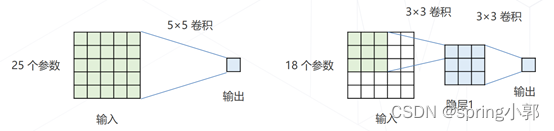
网络层数:11、13、16、19 层,3×3 卷积配合 1 像素的边界填充,维持空间分辨率,每隔几层倍增通道数、减半分辨率,生成 1/2、1/4 尺度的更高抽象层级的特征。
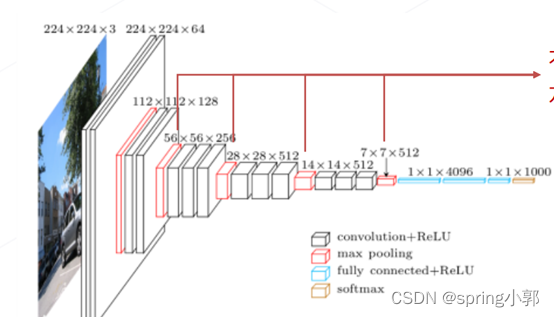
GoogLeNet 22 层,使用 Inception 模块堆叠形成, 22 个可学习层,最后的分类仅使用单层全连接层,可节省大量参数,仅 7M 权重参数(AlexNet 60M、VGG 138M)
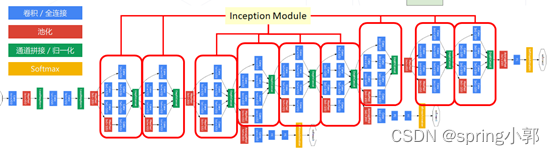
- 残差网络 ResNet
(1)基本思路
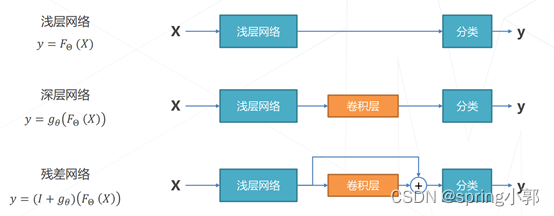
让新增加的层拟合浅层网络与深层网络之间的差异,更容易学习;梯度可以直接回传到浅层网络监督浅层网络的学习;不引入额外参入,让参数更有效贡献到最终的模型
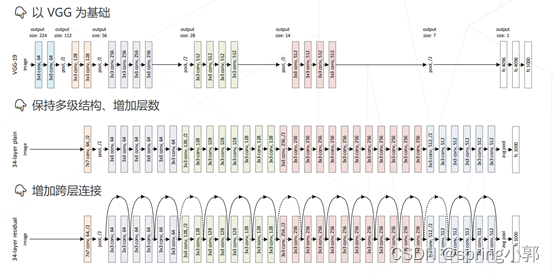
(2)残差网络
ResNet-34 34层 ImageNet Top-5 ,5 级,每级包含若干残差模块,不同残差模块个数不同 ResNet 结构,每级输出分辨率减半,通道倍增,全局平均池化压缩空间维度,单层全连接层产生类别概率
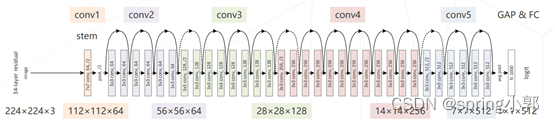
三、更强的图像分类模型
(1)Vision Transformers
使用 Transformer 替代卷积网络实现图像分类,使用更大的数据集训练,达到超越卷积网络的精度
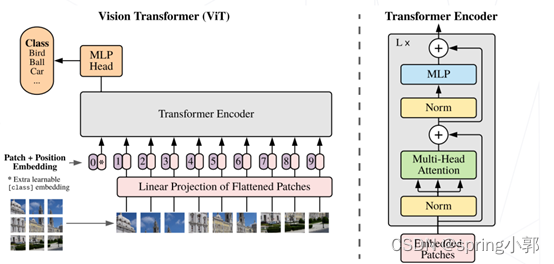
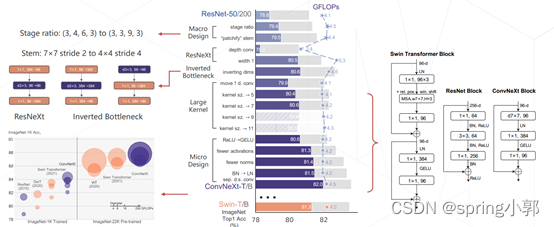
(2)ConvNeXt
将 Swin Transformer 的模型元素迁移到卷积网络中,性能反超 Transformer
四、轻量化卷积神经网络
(1)卷积的参数量
卷积层的可学习参数包括:卷积核 + 偏置值
参数量计算公式: 𝐶 ′ × (𝐶 × 𝐾 × 𝐾 + 1) = 𝐶 ′𝐶𝐾 2 + 𝐶 ′
(2)卷积的计算量(乘加次数)

(3)可分离卷积
将常规卷积分解为逐层卷积和逐点卷积,降低参数量和计算量


















 5919
5919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









