







【机器学习】图解随机梯度下降(SGD):你为什么需要它?
在现代机器学习训练中,梯度下降(Gradient Descent)是优化模型参数最核心的算法之一,而其中的“随机梯度下降(SGD)”则是高效处理大规模数据的关键技术。
本文通过一张直观手绘图,拆解随机梯度下降背后的数学逻辑、更新机制和执行流程,帮助你用最清晰的方式理解这个看似简单却至关重要的优化策略。
一、什么是随机梯度下降?
梯度下降的目标是:通过不断调整参数,使损失函数 Loss 达到最小值。
在传统(批量)梯度下降中,我们每次都会用整个训练集来计算梯度,这在数据量庞大时代价非常高。而**随机梯度下降(SGD)**则只使用一个训练样本就更新一次参数。
这极大地加快了迭代速度,也提高了模型收敛效率。
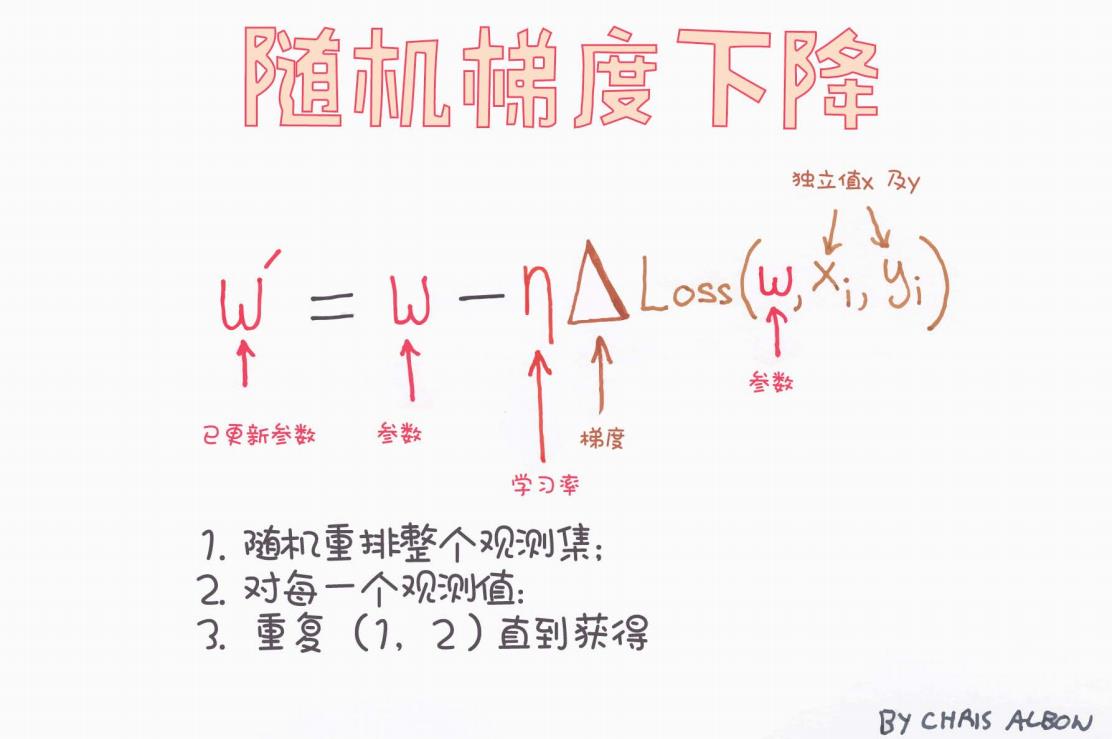
二、SGD 的核心公式解析
图中展示的是 SGD 的参数更新公式:
我们逐一解析这个公式的含义:
| 符号 | 含义 | 图中备注 |
|---|---|---|
| 当前模型参数(如权重) | “参数” | |
| 更新后的参数 | “已更新参数” | |
| η | 学习率(Learning Rate) | “学习率” |
| 当前参数下损失函数对参数的梯度 | “梯度” | |
| 当前的一个样本数据 | “独立值 x 和 y” |
直观地说,我们在每次迭代时:
观察一个样本
,计算当前模型在该样本上的损失(Loss),然后按照损失函数对参数
的导数方向进行调整。
三、SGD 的执行流程图解
图中给出了 SGD 的三步执行流程:
-
随机重排整个观测集
-
在每个 epoch 开始前,打乱样本顺序,以避免模型受样本分布的顺序影响。
-
-
对每一个观测值进行更新
-
每次选取一个样本
-
-
重复(1)、(2)直到收敛
-
多轮(epoch)重复,直到参数不再明显变化或达到预设轮数。
-
这与批量梯度下降(每次使用整个训练集计算平均梯度)相比,在效率和泛化能力上都有显著优势。
四、SGD 的优点和缺点
优点:
-
计算效率高:不需要遍历整个数据集即可更新参数;
-
更快收敛:尤其在冗余数据集上更高效;
-
能跳出局部最优:更新中自带“噪声”,有助于跳出鞍点或局部最小值;
-
适合在线学习:数据流式输入时可实时更新模型。
缺点:
-
更新不稳定:每次用一个样本更新,路径更“抖”;
-
收敛过程波动大:Loss 曲线不像批量梯度下降那样平滑;
-
需要调参技巧:学习率 η\etaη 不合理会导致发散或过慢。
五、SGD 在实际中的改进版本
现代深度学习中,几乎不会直接使用“纯SGD”,而是使用其变体:
| 算法 | 简述 |
|---|---|
| SGD with Momentum | 加入“惯性项”,减少震荡,提高稳定性 |
| Adagrad / RMSprop / Adam | 自适应学习率,根据梯度变化调整更新幅度 |
| Mini-batch SGD | 一次用多个样本(如 32/64)而不是单个样本更新,提高稳定性 |
六、Python 示例:使用 PyTorch 实现 SGD
import torch
import torch.nn as nn
# 假设一个简单的线性模型
model = nn.Linear(10, 1)
# 使用 SGD 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 假设一个训练样本
x = torch.randn(1, 10)
y = torch.tensor([[1.]])
# 损失函数
criterion = nn.MSELoss()
# 前向传播
output = model(x)
loss = criterion(output, y)
# 后向传播 + 参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
七、总结
随机梯度下降(SGD)是一种基础却高效的优化算法,几乎存在于每一个现代机器学习模型中。
它的“每次一个样本更新”的策略,带来了更快的训练速度和更强的泛化能力,也让我们能够处理海量数据。
通过图中这条更新公式,我们不仅看到了一行数学公式的魔力,也窥见了 AI 模型背后不断迭代进化的本质。
图解作者:Chris Albon
推荐补充阅读:
-
《Deep Learning》by Ian Goodfellow 等
-
《Pattern Recognition and Machine Learning》by Christopher M. Bishop
-
PyTorch Docs: SGD

















 1425
1425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









