




简介

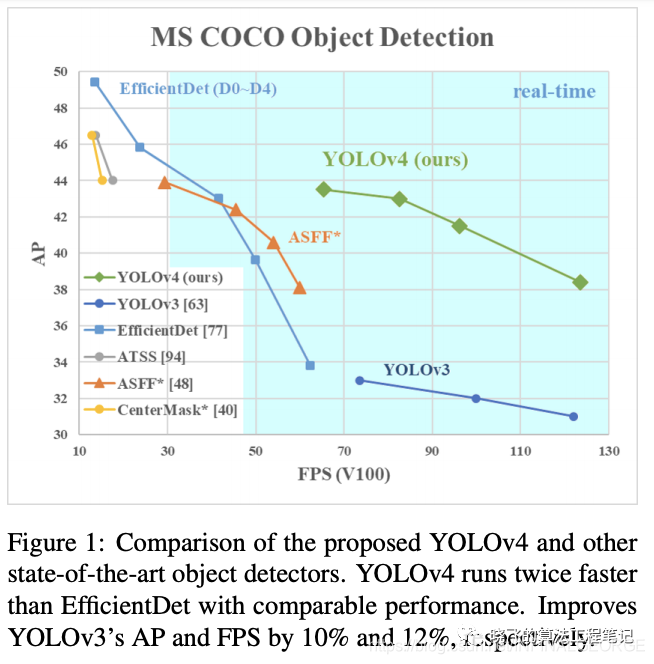
论文提出YOLOv4,从图1的结果来看,相对于YOLOv3在准确率上提升了近10个点,然而速度并几乎没有下降.
论文主要贡献如下:
提出速度更快、精度更好的检测模型,仅需要单张1080Ti或2080Ti即可完成训练。
验证了目前SOTA的Bag-ofFreebies(不增加推理成本的trick)和Bag-of-Specials(增加推理成本的trick)的有效性。
修改了SOTA方法,让其更高效且更合适地在单卡进行训练,包括CBN、PAN、SAM等。
方法论
Selection of architecture
对检测模型来说,分类最优的主干网络不一定是最合适的,适用于目标检测的主干网络需满足以下要求:
高输入分辨率,提高小物体的检测准确率。
更多的层,提高感受域来适应输入的增加。
更多的参数,提高检测单图多尺寸目标的能力。

理论来讲,应该选择感受域更大且参数了更大的模型作为主干网络,表1对比了三种SOTA主干网络的,可以看到CSPDarknet53的感受域、参数量以及速度都是最好的,故选其为主干网络。
另外,使用不同大小的感受域有以下好处:
匹配物体大小,可以观察完整的物体。
匹配网络大小,可以观察物体的上下文信息。
超过网络的大小,增加点与最终激活之间的连接数。
为此,YOLOv4加入了SPP block,能够显著地改善感受域大小,而且速度几乎没有什么下降。
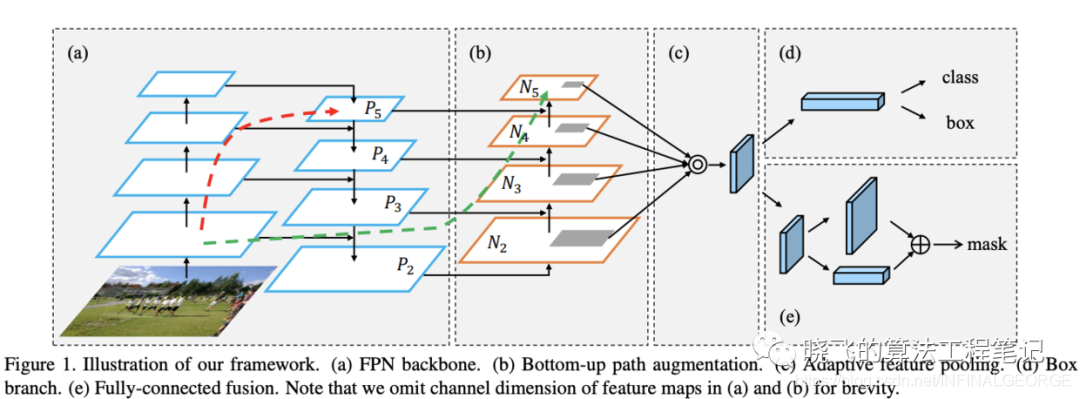
另外,使用PANet替换FPN来进行多通道特征的融合。
最终,YOLOv4选择CSPDarknet53作为主干网络,配合SPP模块,PANet通道融合以及YOLOv3的anchor based head。
Selection of BoF and BoS
目前比较有效的目标检测提升的trick:
激活函数: ReLU, leaky-ReLU, parametric 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3372
3372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









