 Hive笛卡尔积优化与排序策略
Hive笛卡尔积优化与排序策略





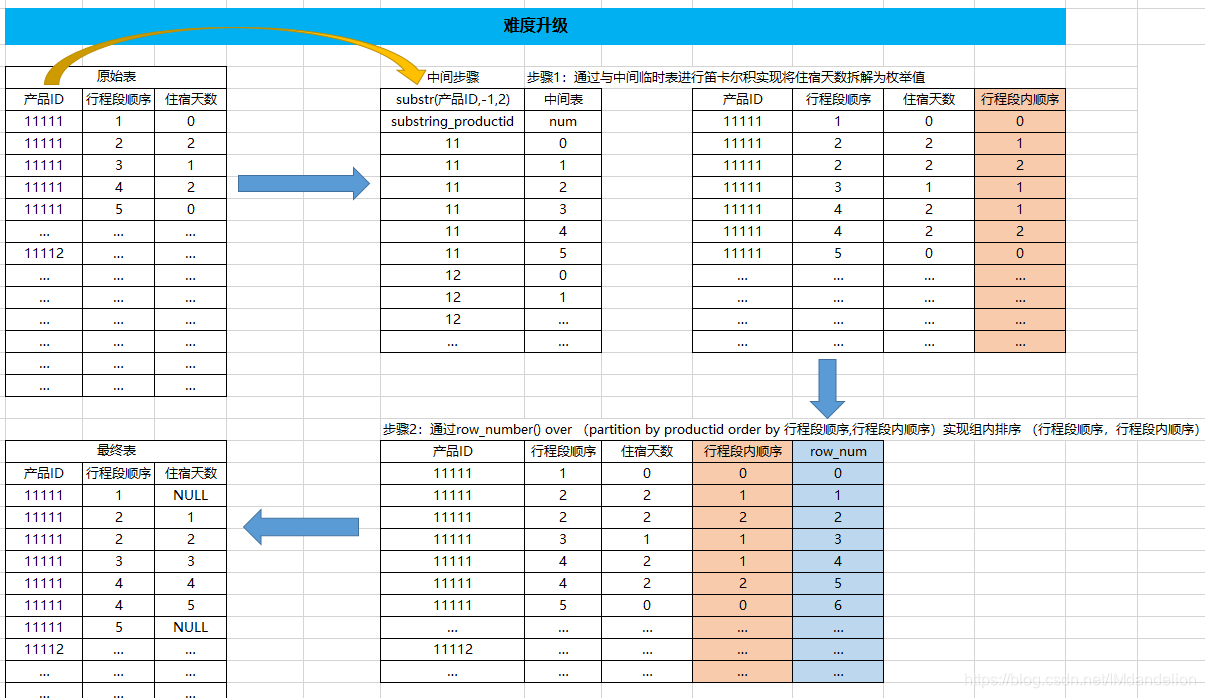
 在遇到Hive中大表与小表进行笛卡尔积时,由于Hive默认仅使用1个reducer导致效率低下。为解决这个问题,可以采用给join添加join key的方法。具体做法包括扩充小表的join key并复制其条目,同时让大表的join key为随机数,以分散到多个reducer中处理,避免数据倾斜。通过利用产品ID的后n位作为join key,可以实现多reducer并行处理,提高运算速度。
在遇到Hive中大表与小表进行笛卡尔积时,由于Hive默认仅使用1个reducer导致效率低下。为解决这个问题,可以采用给join添加join key的方法。具体做法包括扩充小表的join key并复制其条目,同时让大表的join key为随机数,以分散到多个reducer中处理,避免数据倾斜。通过利用产品ID的后n位作为join key,可以实现多reducer并行处理,提高运算速度。
原始需求

| 解决方案:笛卡尔积 + 排序 |
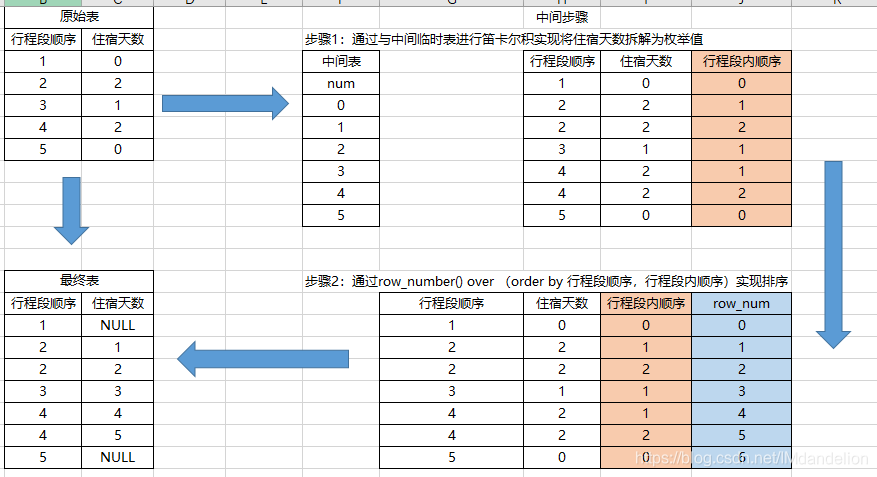
2)但是如果左表很大,大表和小表做笛卡尔积时,Hive只能用1个reducer来完成笛卡尔积,速度会非常慢;避免笛卡尔积的方法是,给join添加一个join key。
原理很简单:将小表扩充一列join key,并将小表的条目复制数倍,join key 各不相同;将大表扩充一列join key为随机数。
精髓在于复制几倍,最后就有几个reduce来做,而且大表的数据是前面小表扩张key值范围里面随机出来的,所以复制了几倍n,就相当于这个随机范围就有多大n,那么相应的大表的数据就被随机的分为了n份。并且最后处理所用的reduce数量也是n,不会出现数据倾斜。
这里有产品ID可以利用,使用产品ID的后n位,根据实际情况而定,作为join key,这样就会有多个reducer,也不会出现数据倾斜。
参考文章:
https://blog.youkuaiyun.com/lirika_777/article/details/89330006
https://www.jianshu.com/p/159842671877
https://www.cnblogs.com/qingyunzong/p/8847775.html#_label3

















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









