




 本文深入解析了Feature Pyramid Network (FPN)的结构与工作原理,介绍了一种自顶向下网络结构,通过侧连接融合不同尺度的特征图,有效提升了目标检测的准确性。详细解释了自底向上与自顶向下分支的作用,以及如何通过逐元素相加实现特征融合。
本文深入解析了Feature Pyramid Network (FPN)的结构与工作原理,介绍了一种自顶向下网络结构,通过侧连接融合不同尺度的特征图,有效提升了目标检测的准确性。详细解释了自底向上与自顶向下分支的作用,以及如何通过逐元素相加实现特征融合。
FPN论文(https://arxiv.org/abs/1612.03144)
特征金字塔结构是进行多尺度目标检测常见架构。在论文之前因为计算量过大很少有相关的检测器。
一、论文贡献
1)、提出一种带有构建各种尺度的高层特征图的侧连接的自顶向下网络结构,称之为Feature Pyramid Network (FPN)。
这句话有点绕,什么是自顶向下结构?何为顶部?何为底部?对于输入图片,使用CNN提取特征过程中,越往后特征图经过池化或者跨步卷积操作越来越小,这个结构就像金字塔结构一样,输入图片出于金字塔底部,包含了原始的图片信息,越后面的特征图层越小或者说越顶端,包含了更加抽象的特征,更加高级的特征,整个特征提取的过程就是常见的bottom up的过程。论文中的top down architecture实际上就是自顶向下,从高级特征图利用上采样或者反卷积等操作,恢复到低一级的特征图。然后和之前bottom up的层进行特征融合。这样包含了更加丰富的语义信息。解决了CNN中卷积核管中窥豹的不足。不赘述。特种融合是CNN中常见的提升性能涨点方式。
二、简介
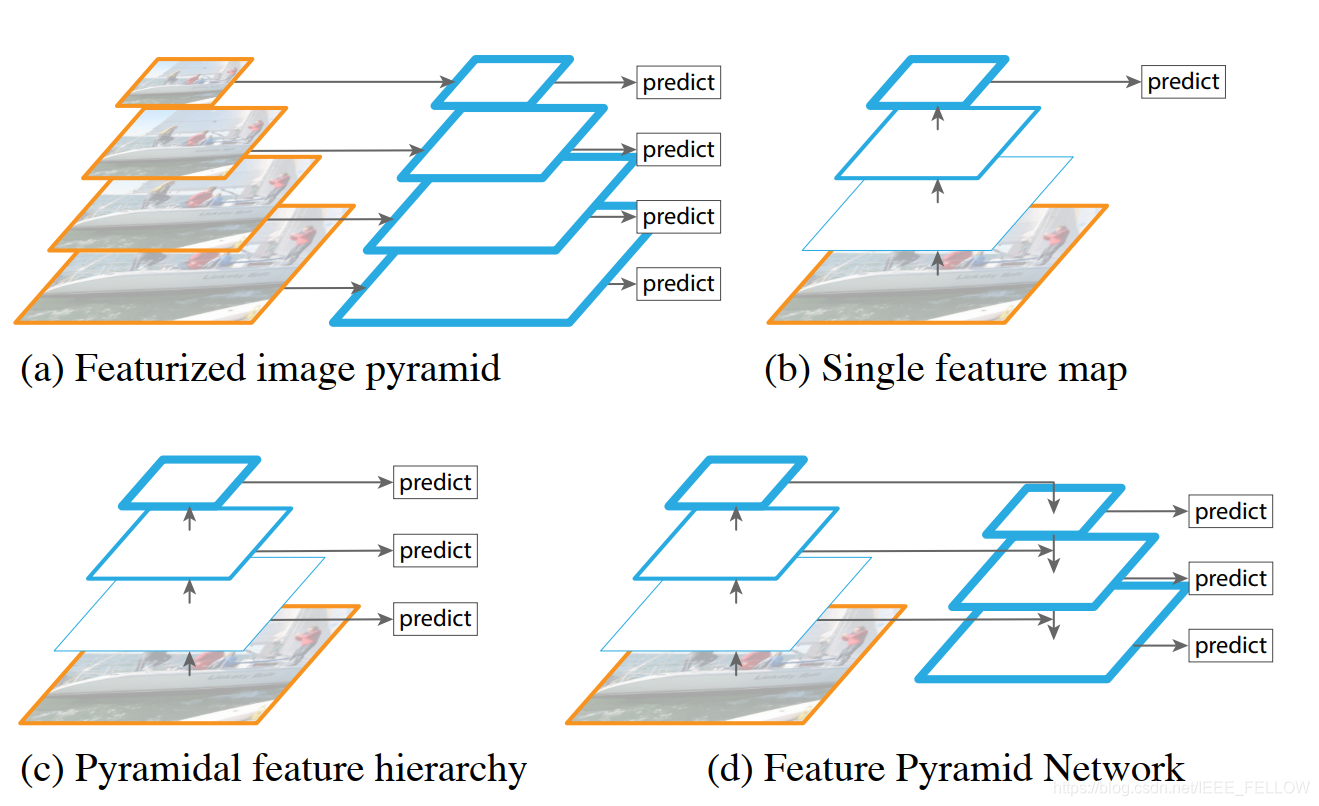
上图总结了多尺度的常见操作:
a)、通过输入图片resize到不同尺度,然后分别独立计算,一个字:慢。
b)、常见的CNN提取输入图像特征然后预测。Faster RCNN之类使用该架构。
c)、利用特征提取网络中间层进行多尺度预测,例如SSD就是通过该结构涨点很多。
d)、本文提出的架构,左边是常见的特征提取过程,右边是top down结构,从高层语义通过上采样恢复低层。中间通过lateral connection连接。实现不同层,不同尺度特征的融合。更鲁邦、更加丰富的语义,用作者的话说是semantically stronger features。
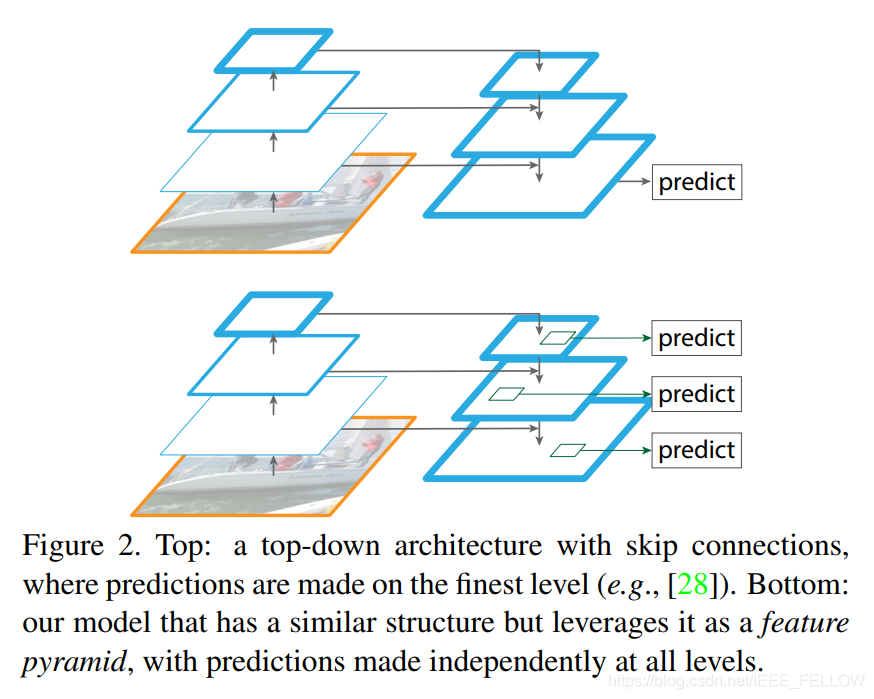
上图两种结构区别:
上方) 带有跳连结构的自顶向下架构,预测通过最优层作出。
下方)论文提出的架构,所有层独立预测。
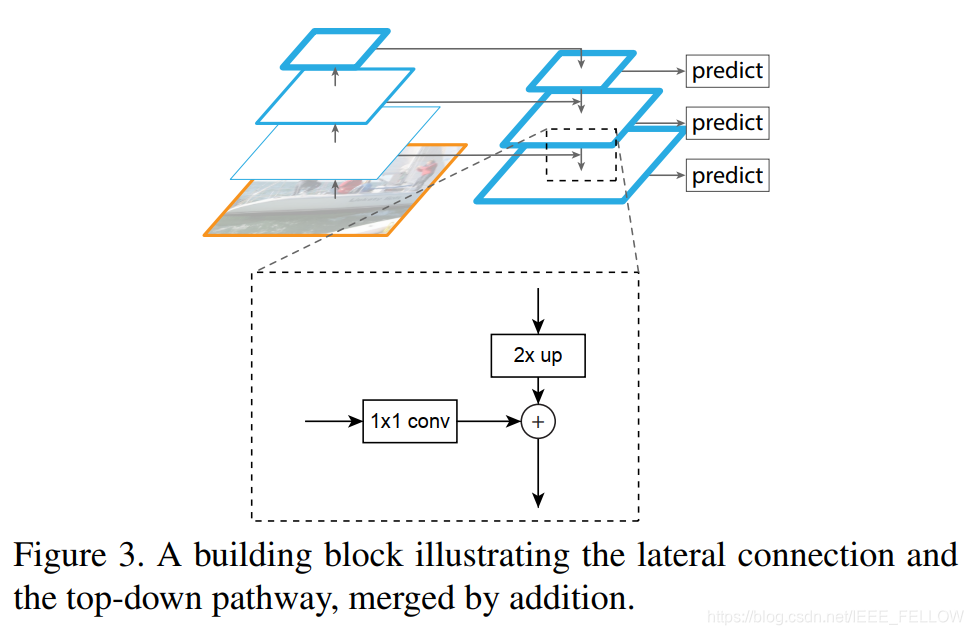
论文提出的侧连接(lateral connection )和自顶向下分支(top-down pathway )是通过逐元素相加(element-wise addition)实现特征融合。
-
自底向上分支
该路径为主干网络(backbone ConvNet)前向传播路径。该分支计算获得尺度为输入图片2阶乘缩放的特征图。
在这些输出特征图中有很多具有相同的大小,我们称这些特征图在网络的同一stage。对于论文提出的特征图金字塔结构,我们定义一个stage中的网络层为同一金字塔级别(one pyramid level for each stage )。我们选择每一stage的最后一层输出特征作为我们FPN的特征图,用于构建特征金字塔。其实这个想法是比较自然的,因为每一stage的最后一层特征图往往具有这一阶段最佳的特征。

对于ResNet系列网络(上图),作者提出使用每个stage的最后一个卷积块(residual block)的激活输出构建金字塔结构。
原文:
We denote the output of these last residual blocks as {C2, C3, C4, C5} for conv2, conv3, conv4, and conv5 outputs, and note that they have strides of {4, 8, 16, 32} pixels with respect to the input image.
不使用C1是因为C1的特征图尺寸很大,计算量开销过大,比如SSD中也是仅仅对后面几个stage的特征图做多尺度预测。太底层的特征图计算量呈现指数增加。
-
自顶向下分支和侧连接
对高层特征进行粗略的上采样(nearest neighbor upsample),获得和低一级特征图相同的尺寸,通过侧连接和前向传播的特征相加进行融合。
具体实现结构见Figure3。
bottom-up的特征图{C2, C3, C4, C5}经过1x1卷积(256个)先进行降维,top的特征图通过上采样,然后两者相加。所有的侧连接都使用了256个1x1卷积核进行降维。最后对融合的特征图使用3x3卷积(平滑上采样的锯齿等)获得最终特征图{P2, P3, P4, P5 }。值得注意的是这些额外层并未引入非线性!
Pytorch中的实现:
-
# Bottom-up c1 = self.RCNN_layer0(im_data) c2 = self.RCNN_layer1(c1) c3 = self.RCNN_layer2(c2) c4 = self.RCNN_layer3(c3) c5 = self.RCNN_layer4(c4) # Top-down p5 = self.RCNN_toplayer(c5) p4 = self._upsample_add(p5, self.RCNN_latlayer1(c4)) p4 = self.RCNN_smooth1(p4) p3 = self._upsample_add(p4, self.RCNN_latlayer2(c3)) p3 = self.RCNN_smooth2(p3) p2 = self._upsample_add(p3, self.RCNN_latlayer3(c2)) p2 = self.RCNN_smooth3(p2) p6 = self.maxpool2d(p5) rpn_feature_maps = [p2, p3, p4, p5, p6]其中_upsample_add函数实现上采样并求和:
-
def _upsample_add(self, x, y): _,_,H,W = y.size() return F.upsample(x, size=(H,W), mode='bilinear') + y

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









