




「豆包手机」尚在讨论风口时,智谱 AI 宣布开源其手机端智能助理框架 Open-AutoGLM, 实现了对屏幕内容的多模态理解与自动化操作。
与传统手机自动化工具不同,Phone Agent 采用视觉语言模型实现了对屏幕内容的深度语义理解,结合智能规划能力自动生成并执行操作流程。 系统通过 ADB(Android Debug Bridge)控制设备,用户只需用自然语言描述需求,如「打开小红书搜索美食」,Phone Agent 即可自动解析意图、理解当前界面、规划下一步动作并完成整个流程。
在安全与可控性方面,系统设计了敏感操作确认机制,并在登录、支付或验证码等需要人工介入的场景中支持用户接管,确保使用过程安全可靠。同时,Phone Agent 还具备远程 ADB 调试能力,支持通过 WiFi 或移动网络连接设备,为开发者与高级用户提供灵活的远程控制与实时调试支持。
目前,基于该框架实现的 Open-AutoGLM 已覆盖微信、淘宝、小红书等 50 余款主流中文应用, 能够处理从社交互动、电商购物到内容浏览等多种日常任务,正逐步发展为覆盖用户衣食住行全场景的智能助手。
目前,HyperAI超神经官网已上线了「Open-AutoGLM:手机端智能助理」,快来试试吧~
在线使用:https://go.hyper.ai/QwvOU
12 月 8 日-12 月 12 日,hyper.ai 官网更新速览:
-
优质公共数据集:10 个
-
优质教程精选:5 个
-
本周论文推荐: 5 篇
-
社区文章解读:5 篇
-
热门百科词条:5 条
-
1 月截稿顶会:11 个
访问官网:hyper.ai
公共数据集精选
1. Envision 多阶段事件视觉生成数据集
Envision 是由上海人工智能实验室发布的一个多图像文本对数据集,旨在测试模型在真实世界事件中的因果理解与多阶段生成能力。数据集共包含 1,000 个事件序列与 4,000 条四阶段文本提示,涵盖自然科学与人文历史六大领域。事件素材来自教材与在线资料,经专家筛选并由 GPT-4o 生成与润色,形成具备清晰因果链与阶段递进结构的叙事提示。
直接使用:https://go.hyper.ai/xD4j6
2. DetectiumFire 多模态火灾理解数据集
DetectiumFire 是由杜兰大学联合 Aalto University 发布的一个面向火焰检测、视觉推理与多模态生成任务的数据集,已经被纳入 NeurIPS 2025 Datasets and Benchmarks Track,旨在为计算机视觉与视觉 – 语言模型提供统一的火焰场景训练与评测资源。该数据集包含超过 14.5 万张高质量真实火灾图像和 2.5 万个火灾相关视频。
直接使用:https://go.hyper.ai/7Z92Z

数据集示例
3. Care-PD 帕金森三维步态评估数据集
CARE-PD 是由多伦多大学联合 Vector Institute 、 KITE Research Institute–UHN 等机构发布的目前公开规模最大的帕金森病三维步态网格数据集,已入选 NeurIPS 2025 Datasets and Benchmarks,旨在为临床评分预测、帕金森步态表征学习及跨机构统一分析提供高质量数据基础。数据集共包含 362 名受试者的步态记录,来自 8 个临床机构的 9 个独立队列。所有步态视频和动作捕捉数据均经统一处理,转换为匿名化的 SMPL 三维人体步态网格。
直接使用:https://go.hyper.ai/CH7Oi
4. PolyMath 多语言数学推理基准数据集
PolyMath 是由阿里巴巴千问团队联合上海交通大学发布的一个多语言数学推理评测数据集,并已入选 NeurIPS 2025 Datasets and Benchmarks,旨在系统评估大语言模型在多语种条件下的数学理解、推理深度与跨语言一致性表现。
直接使用:https://go.hyper.ai/VM5XK
5. VOccl3D 三维人体遮挡视频数据集
VOccl3D 是由加州大学发布的一个专注于复杂遮挡场景下人体三维理解的大规模合成数据集,旨在为人体姿态估计、重建与多模态感知任务提供更贴近真实遮挡环境的评测基准。该数据集共包含超过 25 万张图像和约 400 段视频序列,由背景场景、人类动作与多样化贴图共同构建。
直接使用:https://go.hyper.ai/vBFc2

数据集示例
6. Spatial-SSRL-81k 空间感知自监督数据集
Spatial-SSRL-81k 是由上海人工智能实验室联合上海交通大学、香港中文大学等机构发布的一个面向空间理解与空间推理的自监督视觉 – 语言数据集,旨在为大模型提供无需人工标注的空间感知能力,从而提升其在多模态场景中的推理与泛化效果。
直接使用:https://go.hyper.ai/AfHSW

数据集示例
7. WenetSpeech-Chuan 川渝方言语音数据集
WenetSpeech-Chuan 是由西北工业大学联合希尔贝壳、中国电信人工智能研究院等机构发布的一个规模庞大的川渝方言语音数据集,该数据集覆盖 9 大真实场景领域,其中短视频占 52.83%,其余还包括娱乐、直播、有声书、纪录片、采访、新闻、阅读和剧集,呈现出高度多样且贴近现实的语音分布。
直接使用:https://go.hyper.ai/dFlE2

数据集分布
8. PhysDrive 驾驶员生理测试数据集
PhysDrive 是由香港科技大学(广州)、香港科技大学、清华大学等机构发布的首个面向真实驾驶环境、用于车内非接触式生理测量的大规模多模态数据集,已入选 NeurIPS 2025 Datasets and Benchmarks,旨在支撑驾驶员状态监测、智慧座舱系统以及多模态生理感知方法的研究与评测。
直接使用:https://go.hyper.ai/4qz9T
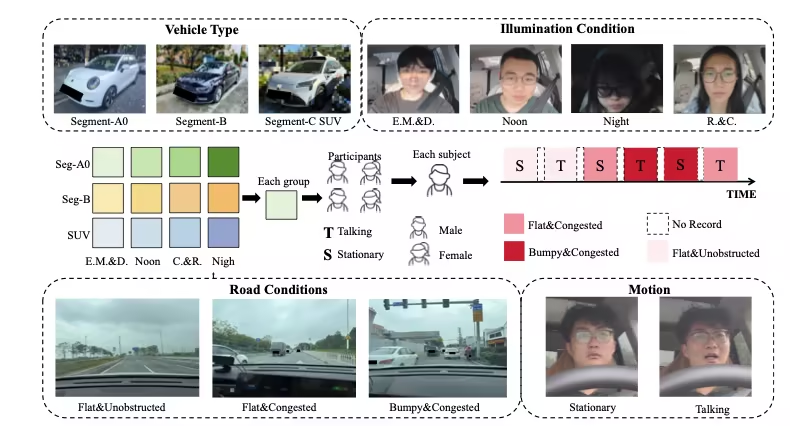
数据集构建流程
9. MMSVGBench 多模态矢量图生成基准数据集
MMSVG-Bench 是由复旦大学联合 StepFun 发布的一个面向多模态 SVG 生成任务设计的综合评测基准,已入选 NeurIPS 2025 Datasets and Benchmarks,旨在填补当前矢量图生成领域缺乏统一、开放、标准化测试集的空白。
直接使用:https://go.hyper.ai/WiZCR
10. PolypSense3D 息肉尺寸感知数据集
PolypSense3D 是由杭州师范大学联合丹麦技术大学、河海大学等机构发布的一个专为深度感知息肉尺寸测量任务设计的多源基准数据集,已入选 NeurIPS 2025,旨在为息肉检测、深度估计、尺寸测量及 sim-to-real 迁移研究提供高质量训练与评测资源。
直接使用:https://go.hyper.ai/SZnu6
公共教程精选
1. Dia2-TTS:实时语音合成服务
Dia2-TTS 是一个基于 nari-labs 团队发布的 Dia2 大规模语音生成模型(Dia2-2B)构建的实时语音合成服务,支持多轮对话脚本输入、双角色语音提示(Prefix Voice)、多参数可控采样,并通过 Gradio 提供完整的 Web 端交互界面,用于高质量对话级语音合成。模型可直接输入连续多轮对话脚本,生成自然连贯、角色音色一致的高质量语音,适用于虚拟客服、语音助手、AI 配音、短剧生成等应用场景。
在线运行:https://go.hyper.ai/Qbfni

效果示例
2. Open-AutoGLM:手机端智能助理
Open-AutoGLM 是由智谱 AI 发布的手机端智能助理框架,基于 AutoGLM 构建。该框架能够以多模态方式理解手机屏幕内容,并通过自动化操作帮助用户完成任务。与传统手机自动化工具不同,Phone Agent 采用视觉语言模型进行屏幕感知,结合智能规划能力自动生成并执行操作流程。
在线运行:https://go.hyper.ai/QwvOU
3. VibeVoice-Realtime TTS:实时语音合成服务
VibeVoice-Realtime TTS 是一个高质量的实时文本转语音(Text-to-Speech, TTS)系统,由 Microsoft Research 团队发布的 VibeVoice-Realtime-0.5B 流式语音合成模型构建。该系统支持多说话人语音生成、低延迟实时推理,以及 Gradio Web 端可视化交互。
在线运行:https://go.hyper.ai/RviLs

效果示例
4. Z-Image-Turbo:高效 6B 参数图像生成模型
Z-Image-Turbo 是由阿里巴巴通义千问团队发布的新一代高效图像生成模型。该模型以仅 6B 的参数规模,实现了与 20B 以上参数闭源旗舰模型相媲美的性能,特别擅长生成高保真度的照片级真实人像。
在线运行:https://go.hyper.ai/R8BJF
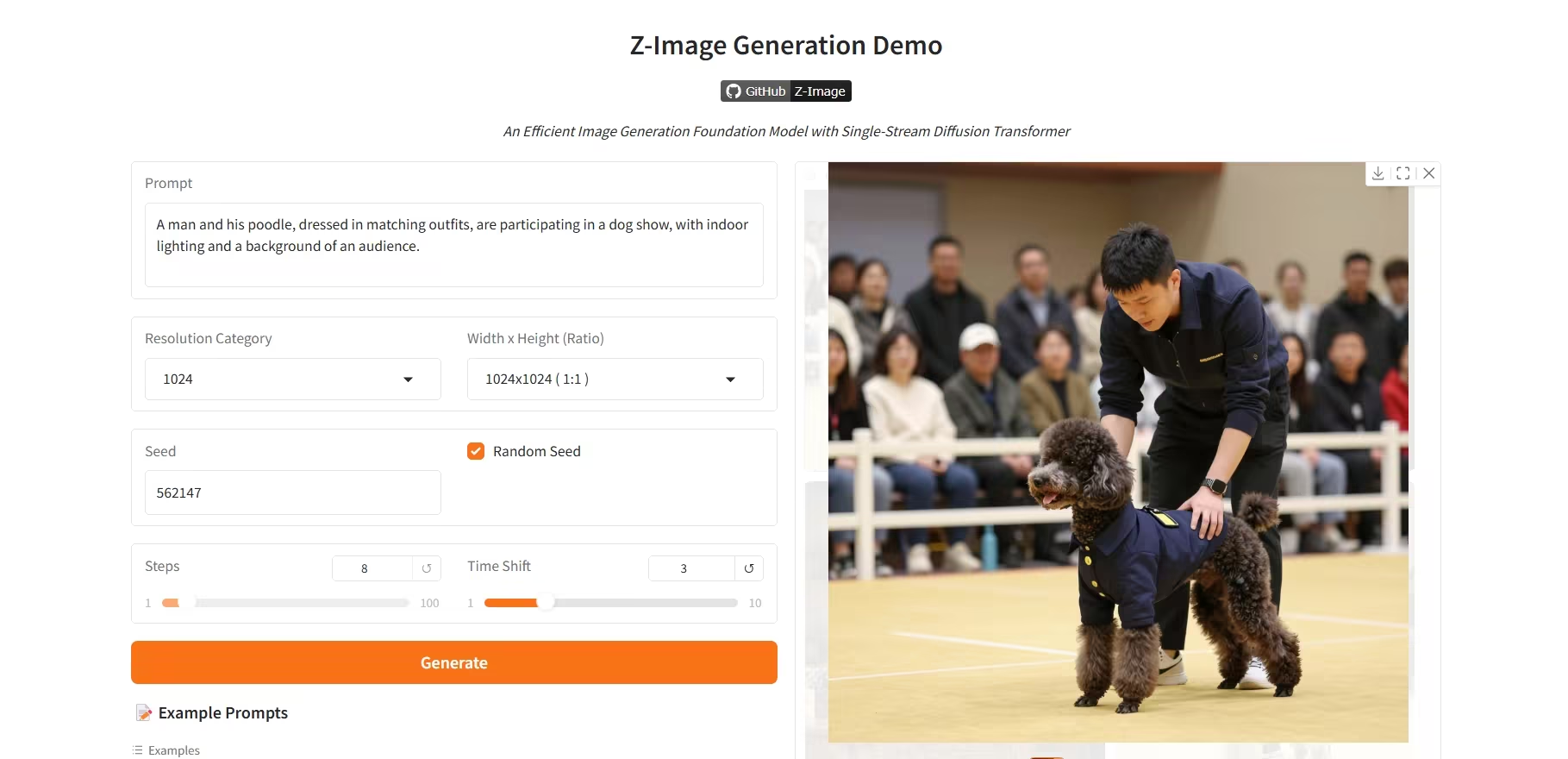
效果示例
5. Ovis-Image:高质量图像生成模型
Ovis-Image 是一个高质量图像生成模型(Text-to-Image, T2I)系统,由 AIDC-AI 团队发布的 Ovis-Image-7B 高保真文本到图像生成模型构建。该系统采用多尺度 Transformer 编码器与自回归生成架构,在高分辨率图像生成、细节表现及多风格适配能力上表现卓越。
在线运行:https://go.hyper.ai/NoaDw

效果示例
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD教程】,入群探讨各类技术问题、分享应用效果~

本周论文推荐
1. Wan-Move: Motion-controllable Video Generation via Latent Trajectory Guidance
本文提出 Wan-Move,一个简单且可扩展的框架,为视频生成模型引入了运动控制能力。现有运动可控方法通常存在控制粒度粗略、可扩展性有限的问题,导致生成结果难以满足实际应用需求。为缩小这一差距,Wan-Move 实现了高精度、高质量的运动控制。其核心思想是直接使原始条件特征具备运动感知能力,以指导视频生成。
论文链接:https://go.hyper.ai/h3uaG
2. Visionary: The World Model Carrier Built on WebGPU-Powered Gaussian Splatting Platform
本文提出 Visionary——一个开源、原生面向网页的实时渲染平台,支持多种高斯点阵与网格的实时渲染。该平台基于高效的 WebGPU 渲染引擎,并结合每帧执行的 ONNX 推理机制,实现了动态神经处理能力,同时保持轻量化与「点击即运行」的浏览器体验。
论文链接:https://go.hyper.ai/NaBv3
3. Native Parallel Reasoner: Reasoning in Parallelism via Self-Distilled Reinforcement Learning
本文提出原生并行推理器(Native Parallel Reasoner, NPR),这是一种无需教师指导的框架,使大语言模型(LLMs)能够自主演化出真正的并行推理能力。在八项推理基准测试中,基于 Qwen3-4B 模型训练的 NPR 实现了最高达 24.5% 的性能提升,推理速度最高提升 4.6 倍。
论文链接:https://go.hyper.ai/KWiZQ
4. TwinFlow: Realizing One-step Generation on Large Models with Self-adversarial Flows
本文提出生成模型训练框架 TwinFlow,该方法无需依赖固定的预训练教师模型,且在训练过程中避免使用标准对抗网络,因而特别适用于构建大规模、高效率的生成模型。在文本到图像生成任务中,该框架在仅 1 次函数求值(1-NFE)下即可达到 GenEval 评分 0.83,显著优于 SANA-Sprint(基于GAN损失的框架)与 RCGM(基于一致性机制的框架)等强基线模型。
论文链接:https://go.hyper.ai/l1nUp
5. Beyond Real: Imaginary Extension of Rotary Position Embeddings for Long-Context LLMs
旋转位置编码(RoPE)通过在复数平面上对查询(query)和键(key)向量进行旋转变换,已成为大语言模型(LLMs)中编码序列顺序的标准方法。然而,现有标准实现仅使用复数点积的实部来计算注意力分数,忽略了包含重要相位信息的虚部,从而可能导致建模长程依赖关系时丢失关键的相对关系细节。本文提出一种扩展方法,重新引入此前被舍弃的虚部信息。该方法充分利用完整的复数表示,构建双成分注意力分数。
论文链接:https://go.hyper.ai/iGTw6
更多 AI 前沿论文:https://go.hyper.ai/iSYSZ
社区文章解读
1. 200 亿美元豪赌!xAI 单押马斯克巨注叫板 OpenAI,未来商业续航成最大问号
2025 年,xAI 在马斯克强力推动下获得前所未有的资本动能,但商业化仍高度依赖 X 与 Tesla 生态,现金流与监管压力同步攀升。Grok 的「弱对齐」路线在全球监管日趋严格的背景下愈发危险,而与 X 的深度绑定也削弱了其独立成长性。面对成本失衡、模式受限与监管摩擦,xAI 的未来仍在巨头叙事、政策变动与马斯克个人意志之间摇摆。
*查看完整报道: *https://go.hyper.ai/NmLi4
2. 完整议程|上海创智/TileAI/华为/先进编译实验室/AI9Stars齐聚上海,深度拆解算子优化的全链路实践
2025 Meet AI Compiler 第 8 期技术沙龙将于 12 月 27 日在上海创智学院举办。本期我们邀请了来自上海创智学院、TileAI 社区、华为海思、先进编译实验室、AI9Stars 社区的多位专家,他们将带来从软件栈设计、算子开发到性能优化的全链路分享,内容涵盖 TVM 的跨生态互操作、PyPTO 的融合算子优化、TileRT 的低延迟系统、Triton 面向多架构的关键优化技术以及 AutoTriton 的算子优化,呈现从理论到落地的完整技术路径。
查看完整报道:https://go.hyper.ai/xpwkk
3. 在线教程丨30毫秒处理100个检测对象,SAM 3实现可提示概念分割,性能提升2倍
SAM、SAM 2 模型在图像分割领域取得了显著进展,但仍未实现在输入内容中自动寻找并分割某一概念的所有实例。为填补这一空白,Meta 推出最新迭代版本 SAM 3,新版本不仅显著超越了前代模型的可提示视觉分割(PVS)性能,更率先为可提示概念分割(PCS)任务确立了新标准。
查看完整报道:https://go.hyper.ai/YfmLc
4. 卡内基跨学科团队利用随机森林模型,基于406份样本成功捕捉33亿年前生命遗迹
美国卡内基科学研究所联合全球多所院校组成跨领域团队,精进了热解气相色谱-质谱+监督机器学习的「技术融合」解决方案,可在混乱的分子碎片中捕捉古老的生命遗迹。
查看完整报道:https://go.hyper.ai/CNPMQ
5. 活动回顾丨 北京大学/清华大学/Zilliz/MoonBit 共话开源,覆盖视频生成/视觉理解/向量数据库/AI 原生编程语言
HyperAI超神经作为 COSCon’25 的联合出品社区,于 12 月 7 日举办了「产研开源协同论坛」。本文为 4 位讲师的深度分享精华摘要,后续我们还会以视频的形式分享完整演讲,敬请期待!
查看完整报道:https://go.hyper.ai/XrCEl
热门百科词条精选
-
双向长短期记忆 Bi-LSTM
-
地面真实值 Ground Truth
-
布局控制 Layout-to-Image
-
具身导航 Embodied Navigation
-
每秒帧数 Frames Per Second (FPS)
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
1 月截稿顶会

一站式追踪人工智能学术顶会:https://go.hyper.ai/event
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
关于 HyperAI超神经 (hyper.ai)
HyperAI超神经 (hyper.ai) 是国内领先的人工智能及高性能计算社区, 致力于成为国内数据科学领域的基础设施,为国内开发者提供丰富、优质的公共资源,截至目前已经:
-
为 1800+ 公开数据集提供国内加速下载节点
-
收录 600+ 经典及流行在线教程
-
解读 200+ AI4Science 论文案例
-
支持 600+ 相关词条查询
-
托管国内首个完整的 Apache TVM 中文文档
访问官网开启学习之旅:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









