




爱因斯坦在 1915 年提出的广义相对论石破天惊地指出,质量不仅能产生引力,还会弯曲其周围的时空,光线和物质的运动都遵循着弯曲的时空路径。因此,大质量天体就像一个天然的透镜,能够使附近经过的光线发生偏折。
在现代天文学中,强引力透镜(strong gravitational lens)是研究宇宙大尺度结构和黑洞-星系共演化的重要工具。充当强引力透镜的类星体(Quasars),为研究超大质量黑洞与其宿主星系之间标度关系(尤其是 MBH–Mhost 关系)随红移演化的规律,提供了极为罕见的观测机会。借助这一强有力的探针,可以通过爱因斯坦半径 θE 精确推断宿主星系的质量。然而,类星体极为罕见,其识别一直是天文学家面临的巨大挑战——在斯隆数字巡天(SDSS)编目的近 30 万个类星体中,仅发现了 12 个候选者,最终确认的也只有 3 个。
在此背景下,由斯坦福大学、SLAC 国家加速器实验室、北京大学、意大利国家天体物理研究院布雷拉天文台、伦敦大学学院、加州大学伯克利分校等众多科研机构组建的团队,利用创新的机器学习方法和暗能量光谱仪的数据,极大地扩展了这个原本微小的样本。
该研究团队开发了一套数据驱动的流程,用于在 DESI DR1 的光谱数据中识别作为强引力透镜的类星体, 覆盖的红移范围为 0.03 ≤ z ≤ 1.8。该方法利用卷积神经网络(CNN),在由真实 DESI QSO 和 ELG 光谱构建的现实感模拟透镜上进行训练。应用该流程后,研究人员识别出 7 个高质量(A 级)类星体透镜候选体,它们均呈现出强烈的、位于前景类星体红移之上的 [OII] 双线发射;其中 4 个候选体还额外呈现 Hβ、[OIII]λ4959Å 和 [OIII]λ5007Å 发射线。
注:DESI DR1 是暗能量光谱巡天 DESI 发布的第一期光谱巡天数据
相关研究成果以「Quasars acting as Strong Lenses Found in DESI DR1」为题,已发表于印本于 arXiv。
研究亮点:
-
扩展了此前研究中识别的类星体透镜样本(此前仅 12 个候选体、3 个得到确认)
-
为建立首个 QSO 强透镜统计样本打开了大门,并展示了数据驱动方法在大规模识别这类罕见系统上的潜力
-
所得样本将为研究黑洞与星系的共演化提供强有力的新途径,通过跨越宇宙时间的直接质量测量来锚定尺度关系
论文地址:
https://arxiv.org/abs/2511.02009
关注公众号,后台回复「类星体」获取完整 PDF
更多 AI 前沿论文:
https://hyper.ai/papers
数据集:在 DESI DR1 中选取 812118 个类星体
在 DESI 首次数据发布中,提供了约 180 万条类星体光谱,涵盖了广泛的红移范围。 本研究选取了 812,118 个类星体,基于 DESI DR1 主巡天的 HEALPixel 红移目录,并采用「暗时(dark time)」程序,以避免月光增加蓝色相机噪声对光谱的影响(「明时(bright time)」程序)。
研究人员使用了 Redrock 提供的信息,Redrock 的输出包括类星体的 TARGETID、红移(z)及其红移误差(Guy et al. 2023)。基于这些信息,仅选择 OBJTYPE = TGT 且 ZCAT PRIMARY = 1 的天体,以排除天空目标以及非主光谱或红移拟合失败的光谱。最后,进一步筛选 ZWARN = 0 且 SPECTYPE = QSO 的对象,从而排除那些可能被标记为类星体但光谱分类不同的天体。此筛选方法保证了红移的准确性,并确保训练样本仅来自红移计算无异常的类星体光谱。
在选取类星体之后,研究人员使用 FastSpec 目录构建发射线星系(ELG)样本; 这一步对于构建模拟透镜至关重要。该目录基于 FastSpecFit1,这是一个轻量级处理管线,可提供 DESI 天体的光谱信息,包括发射线通量、红移、分类等。FastSpecFit 利用模板拟合特定参数和光谱模型,以构建无噪声光谱。研究人员首先以与类星体相同的方法和红移范围选取 ELG,但要求 SPECTYPE = GALAXY。通过这一筛选,其选取了 16,500 个发射线星系,但仅保留主巡天中 OII 3726 通量 > 2×10^-17 erg cm^-2 s^-1 的 ELG,以确保所选发射线高于数据噪声水平。
训练时使用真实观测数据,以在训练集中囊括所有可能的天体物理和仪器噪声。然而,同一批数据不能同时用于训练和实际透镜搜索。因此,其将数据集划分并分两阶段使用——阶段 1 使用 812,118 个对象中的 47%,剩余部分用于阶段 2。
阶段 1:
-
训练样本:使用阶段 1 训练样本中的 384,873 个类星体中的 70% 来训练分类网络和红移预测网络。
-
验证样本:阶段 1 训练样本中剩余的 30% 用于在训练过程中验证模型性能。
-
盲样本:盲样本由 427,245 个未在训练、验证和测试中使用的类星体组成。在训练完成后,在该数据集中搜索真实透镜。
-
测试样本:测试时,使用阶段 1 盲样本中的 3,170 个类星体,并为其中 10% 构建模拟透镜系统。该测试样本用于在超参数优化完成后评估网络性能。
阶段 2:
在阶段 2 中,将训练样本与盲样本互换,并重复相同流程。
-
训练样本:使用阶段 1 盲样本中的 427,245 个类星体的 70% 训练 CNN。
-
验证样本:验证时使用该 427,245 个样本中的 30%。
-
盲样本:盲样本由 384,873 个未在训练、验证和测试中使用的类星体组成。
-
测试样本:阶段 2 测试时,使用阶段 2 盲样本中的 3,547 个类星体,这些样本与训练和验证子集相互独立。其中 10% 的类星体构建为模拟透镜系统。
在模拟透镜系统和未受透镜影响的类星体光谱上训练 CNN
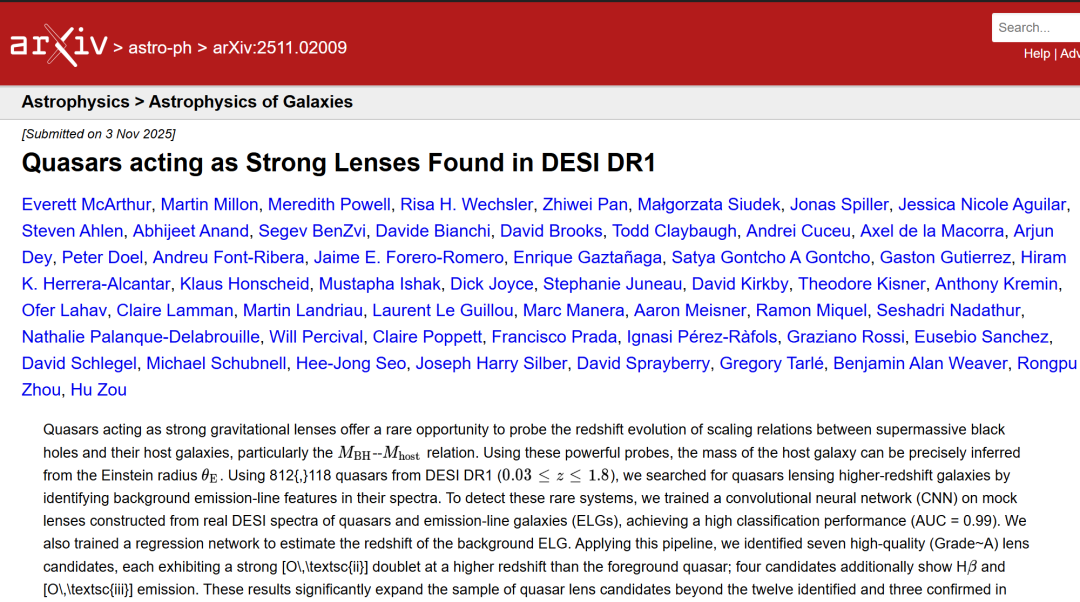
构建一个能够成功识别充当强引力透镜类星体的模型,关键在于使用标注数据集训练模型,使其能够区分充当透镜的类星体光谱与非透镜类星体光谱的特征, 下图展示了训练的完整流程:
完整流程示意图,展示了在 DESI DR1 数据集中识别类星体透镜系统的步骤顺序
研究人员利用 DESI 观测到的类星体(QSO)和发射线星系(ELG)光谱,在模拟透镜系统(正样本)和未受透镜影响的类星体光谱(负样本)上训练卷积神经网络(CNN),训练集的正负样本比例为 10% 对 90%。
① 训练集构建与模拟透镜系统
虽然可以使用模拟光谱为 QSO 和 ELG 生成训练集,但本研究希望保留 DESI 光谱固有的特征, 无论这些特征是由仪器、观测条件还是天体自身引起的。由于各种原因(如谱线展宽、光度差异等),QSO 光谱和 ELG 的 [OII] 谱线呈现出高度多样性,因此研究人员直接使用 DR1 获得的观测数据来训练神经网络,从而在构建上匹配 QSO 和 ELG 的巡天总体属性。
然而,作为强透镜的 QSO 极为罕见。在 SDSS 中,297,301 个类星体中仅有 12 个候选,而在本研究考虑的红移范围内,DESI DR1 数据集中仅包含 1 个。因此,研究中的正样本,即 QSO 透镜,需要通过将真实 QSO 的光谱与高红移 ELG 的光谱叠加来构建,以模拟引力透镜光谱,从而获得包含足够数量正负样本的训练集。
② CNN 分类器的训练与架构
分类器网络由六层卷积层(前三层 50 个滤波器,后三层 100 个滤波器)和两层全连接层(30 个和 25 个节点)组成。卷积层用于提取光谱中的局部特征,如类星体和 ELG 光谱的发射线,最终输出 0 到 1 的评分。训练过程中,将阈值设为 0.5,预测分数≥0.5 的样本判定为透镜候选,最终在盲样本应用时,阈值优化为 0.7 以最大化 F1 评分。
CNN 架构由六个卷积层组成:前三层各有 50 个滤波器,后三层各有 100 个滤波器。第一全连接层有 30 个节点,第二层有 25 个节点,如上图左侧所示。网络输出一个介于 0 到 1 之间的评分。在训练期间,研究人员将阈值设为 0.5,任何预测评分大于或等于 0.5 的样本被神经网络判定为透镜。
训练过程中,使用 Adam 优化器并采用指数学习率衰减,每 500 步学习率下降 0.95 倍。训练使用 TensorFlow 完成,scikit-learn 用于训练集划分、混淆矩阵和指标计算。
随后,研究人员分别使用 Phase 1 和 Phase 2 的训练样本训练两个 CNN:Phase 1 训练的 CNN 用于 Phase 1 盲样本,Phase 2 训练的 CNN 用于 Phase 2 盲样本。 训练完成后,模型在测试样本上评估分类性能,并根据 F1 分数调整阈值,F1 分数结合了真阳性(TP)、假阳性(FP)和假阴性(FN),两阶段的最高 F1 分数均对应阈值 0.7。
最后,将每个网络应用于盲样本(模型未见过的观测类星体)以生成首批透镜候选列表。
③ 红移预测
类星体光谱中前景 QSO 的红移易于测定,但背景 ELG 红移难以直接获取。研究团队采用两种方法对比性能:
-
Redrock:通过 PCA 模板拟合光谱并网格搜索红移,以最小化 χ²。
-
红移 CNN 回归模型:采用与分类器类似的 CNN 结构,但输出为连续红移值,通过均方误差(MSE)训练。
在CNN预测红移的基础上,研究团队进一步对[OII]双线进行局部双高斯拟合,以 Δz=0.1 范围内精炼红移预测,同时计算信噪比(SNR)筛选高质量候选者。
成果展示:发现 7 个强透镜候选对象
① CNN 分类器性能:在训练和验证集上表现优异
CNN 分类器在应用于 Phase 1 和 Phase 2 的训练集与验证集时的性能指标如下表所示:
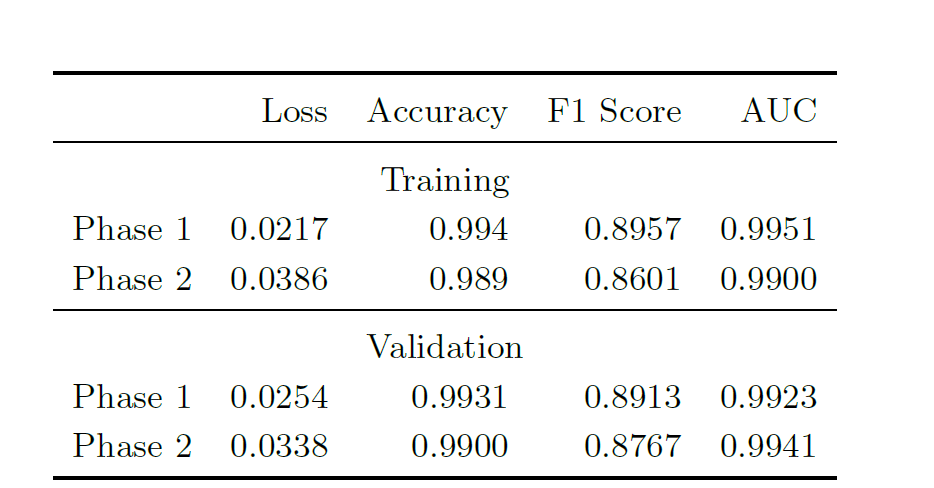
Phase 1 和 Phase 2 的训练与验证结果,各指标的数值
结果显示,CNN 分类器在训练和验证集上表现优异,F1 评分和 AUC 指标均表明模型能有效平衡精确率与召回率。
②红移测定器性能:所有 SNR 区间,CNN 红移测定器精度明显优于 Redrock
在测试样本中,研究人员按高红移 ELG 的信噪比(SNR)对每个对象进行排序,以观察 CNN 和 Redrock 在 [OII] 发射特征不同信噪比范围内的表现。 他们将样本按百分位分为三个组:低 SNR(3 ≤ SNR < 7.52)、中 SNR(7.52 ≤ SNR < 16.63)、高 SNR(SNR ≥ 16.63)。
结果显示:
-
高 SNR:CNN 在 Δz = 0.1 内恢复了 100% 的源红移,高斯拟合后为 99.48%,Redrock 为 51.04%。
-
中 SNR:CNN 为 99.48%,高斯拟合为 100%,Redrock 为 37.70%。
-
低 SNR:CNN 为 100.00%,高斯拟合为 96.88%,Redrock 为 29.17%。
综上所述,在所有 SNR 区间,CNN 红移测定器结合高斯拟合对背景 ELG 红移的恢复精度明显优于 Redrock。 即使在红外通道存在大量天空线和噪声残留的情况下(即使进行了掩蔽),CNN 仍优于标准 Redrock 方案。高斯拟合在中等 SNR 区间几乎达到精确结果,但在非常低的 SNR 下表现不佳,而纯 CNN 方法反而更优。
③对盲样本的应用:确认 7 个 A 级高优先级透镜候选者
应用训练完成的 CNN 至 812,118 个类星体光谱后,共筛选出 494 个候选者。通过人工视觉检查并结合 SNR 和红移信息,最终确认 7 个 A 级高优先级透镜候选者,如下表所示:
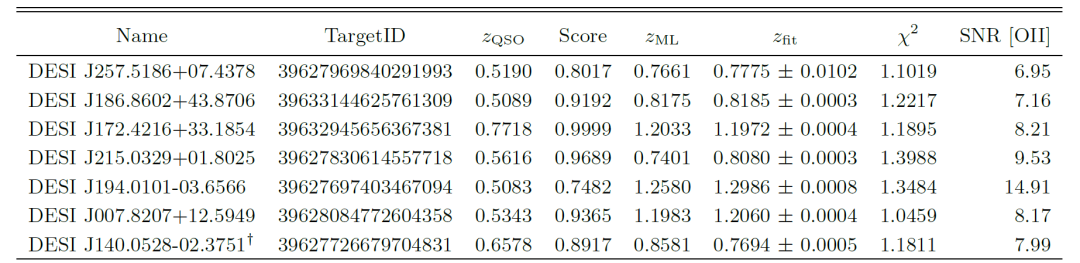
通过完整流程在 DESI DR1 中发现的 QSO–ELG 候选对象
所有 7 个 A 级候选对象似乎在比 QSO 更高的红移下显示强 [OII] 双线,如下图;其中四个候选对象还显示在同一红移下的 [OIII]λ 4959˚A 和 Hβ 谱线。
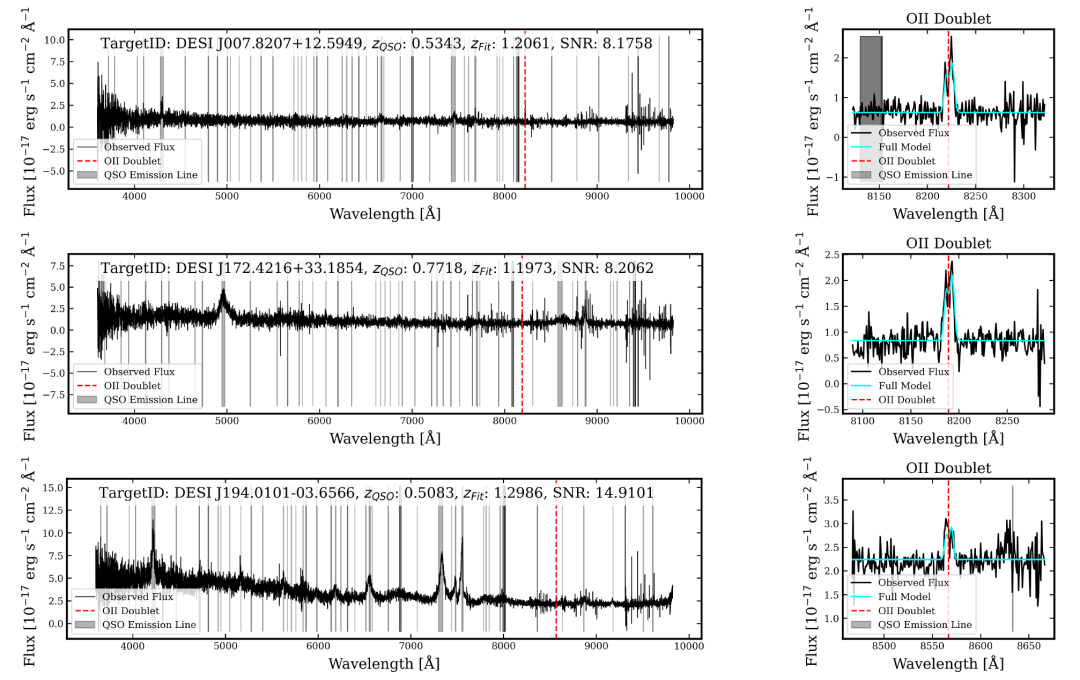
3 个 A 级 QSO–ELG 透镜候选对象,仅显示 [OII] 发射线
深度学习重塑天文学研究范式
在过去十年中,AI 尤其是深度学习,正迅速重塑天文学的研究范式。从数据获取、特征提取到科学发现流程,AI 在天文领域的作用已从「辅助工具」演变为推动前沿突破的核心动力。其背后的根本原因在于:天文学正在进入一个前所未有的数据爆发时代。
大型巡天(如 DESI、LSST、Euclid)每年产生 PB 级数据,远超传统人工分析与经a典算法的处理能力。深度学习模型尤其擅长从海量观测数据中自动提取复杂模式,使之成为处理光谱、图像和时序数据的理想选择。
作为典型代表之一,2025 年 11 月,来自加州大学伯克利分校、剑桥大学、牛津大学等全球十余所科研机构的团队联合推出了首个面向天文学的大规模多模态基础模型家族 AION-1 (天文全模态网络,AstronomIcal Omni-modal Network), 通过统一的早期融合骨干网络,将图像、光谱和星表数据等异质观测信息进行集成建模,不仅在零样本场景下表现优异,其线性探测准确率也可媲美针对特定任务专门训练的模型。AION-1 通过系统解决数据异质性、噪声和仪器多样性等核心挑战,为天文学乃至其他科学领域提供了可行的多模态建模范式。
论文标题: AION-1: Omnimodal Foundation Model for Astronomical Sciences
论文地址: https://openreview.net/forum?id=6gJ2ZykQ5W
在天体分类方面,深度学习已成为明星技术。无论是星系形态分类、超新星识别还是强引力透镜搜索,CNN 与 Transformer 架构都能够在高维、非结构化数据中找到与物理过程相关的关键特征,实现远超人工的速度与一致性。
例如,中国科学院云南天文台博士封海成团队联合郑州大学博士李瑞、意大利那不勒斯费德里科二世大学教授 Nicola R. Napolitano, 提出了多模态神经网络模型,创新性地融合了天体形态特征与 SED 信息,实现对恒星、类星体及星系等天体的高精度自动识别。该方法已应用于欧洲南方天文台千平方度巡天项目(KiDS)第五次数据发布的 1,350 平方度天区,完成了超 2,700 万个 r 波段亮于 23 等天体的分类。
论文标题: Morpho-photometric Classification of KiDS DR5 Sources Based on Neural Networks: A Comprehensive Star–Quasar–Galaxy Catalog
论文地址: https://iopscience.iop.org/article/10.3847/1538-4365/adde5a
总体而言,AI 不是简单替代传统天文方法,而是在不断推动科研范式升级:让天文学家从繁琐的数据处理解放出来,专注于物理本质问题;让稀有天体不再被浩瀚数据淹没;并让宇宙的结构与演化得以被更快、更深刻地理解。
参考文献:
1.https://arxiv.org/abs/2511.02009
2.https://phys.org/news/2025-11-machine-quasars-lenses.html
3.https://www.cpsjournals.cn/data/article/wl/preview/pdf/10.7693/wl20250701.pdf
4.https://mp.weixin.qq.com/s/6zlnE5-fIw21TQeg1QPPnQ
5.https://www.cas.cn/syky/202507/t20250711_5076040.shtml

















 7593
7593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









