




13.子集Ⅱ
思路: 本题和上题类似,但多了去重操作。使用used数组记录当前子集中使用的元素,若当前元素与其前一元素相同,并且前一元素未在当前子集中,则跳过当前元素。
class Solution {
private:
vector<vector<int>> res;
vector<int> path;
// used数组记录nums中哪些元素已在当前子集中
void backtracing(vector<int> &nums, int index, vector<bool> &used) {
res.push_back(path);
for(int i = index; i < nums.size(); i++){
// 去除重复元素
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == false)
continue;
path.push_back(nums[i]);
used[i] = true;
backtracing(nums, i + 1, used);
used[i] = false;
path.pop_back();
}
return;
}
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
res.clear();
path.clear();
sort(nums.begin(), nums.end()); // 将数组排序
vector<bool> used(nums.size(), false);
backtracing(nums, 0, used);
return res;
}
};
时间复杂度: O(n*2^n)
空间复杂度: O(n)
14.非递减序列
思路: 利用递归回溯的算法,本次要理清楚去重的目标。同一父节点下的同层上使用过的元素就不能再使用了。
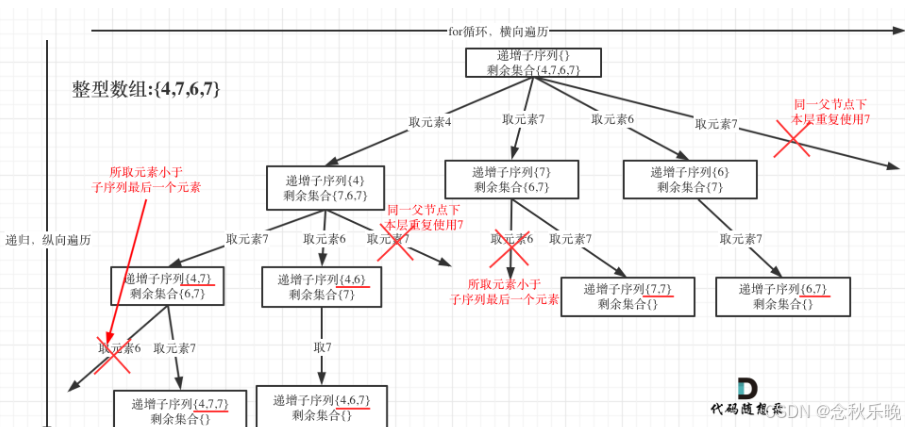
因此,使用一个set记录本层已经使用过的元素,遇到重复元素略过即可。
class Solution {
private:
vector<vector<int>> res;
vector<int> path;
void backtracing(const vector<int> &nums, int index) {
if (path.size() > 1)
res.push_back(path);
unordered_set<int> used; // 记录本层使用过的元素,使用过本层就不再使用
for (int i = index; i < nums.size(); i++) {
if ((path.size() > 0 && path[path.size() - 1] > nums[i])
|| used.find(nums[i]) != used.end())
continue;
// 记录nums[i]在本层已经使用过了,每一层会有新的used,因此不需要回溯
used.insert(nums[i]);
path.push_back(nums[i]);
backtracing(nums, i + 1);
path.pop_back();
}
return;
}
public:
vector<vector<int>> findSubsequences(vector<int>& nums) {
res.clear();
path.clear();
backtracing(nums, 0);
return res;
}
};
时间复杂度: O(n*2^n)
空间复杂度: O(n)
15. 全排列
思路: 全排列也是使用回溯算法,但与组合问题不同的是,全排列的for循环的起点是0,而不是上一层传来的下标,使用used数组记录哪些数据已在本次排列中,continue。
class Solution {
private:
vector<vector<int>> res;
vector<int> path;
void backtracing(const vector<int>& nums, vector<bool> &used) {
if (path.size() == nums.size()) {
res.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
if (used[i]) continue;
path.push_back(nums[i]);
used[i] = true;
backtracing(nums, used);
used[i] = false;
path.pop_back();
}
return;
}
public:
vector<vector<int>> permute(vector<int>& nums) {
res.clear();
path.clear();
vector<bool> used(nums.size(), false);
backtracing(nums, used);
return res;
}
};
时间复杂度: O(n!)
空间复杂度: O(n)
16. 全排列Ⅱ
思路: 总体思路与上题类似,但需要进行去重操作,去重的对象是同一父节点的同一层,每个元素只会出现一次,需去除重复元素。
// 对重复元素去重,对于同一父节点下的同一层,每个元素只出现一次
if (i > 0 && nums[i] == nums[i - 1] && !used[i-1])
continue;
整体代码:
class Solution {
private:
vector<vector<int>> res;
vector<int> path;
void backtracing(const vector<int> &nums, vector<bool> used) {
if (path.size() == nums.size()) {
res.push_back(path);
return;
}
for (int i = 0; i < nums.size(); i++) {
// 对重复元素去重,对于同一父节点下的同一层,每个元素只出现一次
if (i > 0 && nums[i] == nums[i - 1] && !used[i-1])
continue;
if (used[i]) // 若当前元素已统计,则跳过
continue;
path.push_back(nums[i]);
used[i] = true;
backtracing(nums, used);
used[i] = false;
path.pop_back();
}
}
public:
vector<vector<int>> permuteUnique(vector<int>& nums) {
res.clear();
path.clear();
vector<bool> used(nums.size(), false);
sort(nums.begin(), nums.end());
backtracing(nums, used);
return res;
}
};
时间复杂度: O(n*n!)
空间复杂度: O(n)
拓展:
如果改成 used[i - 1] == true, 也是正确的!,去重代码如下:
if (i > 0 && nums[i] == nums[i - 1] && used[i - 1] == true) {
continue;
}
这么写的实质是对树枝进行去重,而原本的写法是对树层进行去重。
对于排列问题,树层上去重和树枝上去重,都是可以的,但是树层上去重效率更高!
并且,一定要加上 used[i - 1] == false或者used[i - 1] == true,因为 used[i - 1] 要一直是 true 或者一直是false 才可以,而不是 一会是true 一会又是false。 所以这个条件要写上。

















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









