




Linux 进程间通信(IPC,Inter-Process Communication)的核心目标是打破进程地址空间的隔离性(每个进程有独立的虚拟地址空间),实现进程间的数据交换、同步(协调执行顺序)或通知。Linux 提供了多类 IPC 机制,按设计渊源可分为「传统 Unix IPC」「System V IPC」「POSIX IPC」「套接字(Socket)」四大类,下面从原理、使用流程、示例代码、优缺点、适用场景 逐层拆解。
前置基础:进程的「地址空间隔离」是 IPC 存在的根本原因 —— 内核为每个进程分配独立的虚拟地址空间,进程无法直接访问其他进程的内存,必须通过内核作为 “中介”(或共享内核外的资源)实现通信。
一、传统 Unix IPC(基础、简单)
这类 IPC 是 Unix 早期设计,接口简单,适用于本地进程的基础通信。
1. 匿名管道(Pipe)
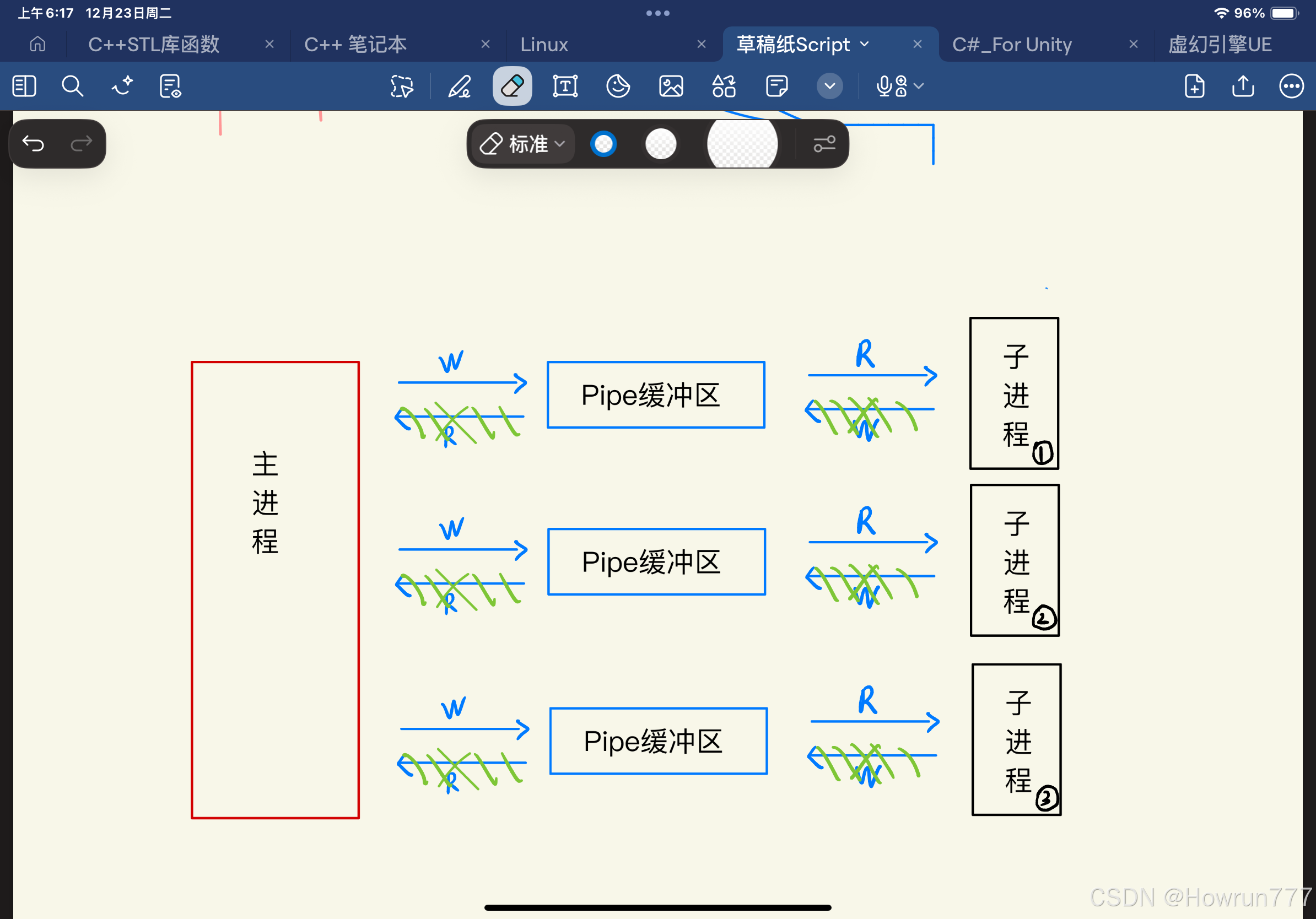
pipe()是 Linux/Unix 系统提供的系统调用,核心功能是创建一条「匿名管道」—— 内核中的一块内存缓冲区,用于亲缘进程间(父子 / 兄弟进程)的单向字节流通信。它是最基础的 IPC 机制之一,也是管道符|(如ls | grep txt)的底层实现。
函数原型与基础用法
函数定义(需包含头文件
<unistd.h>)int pipe(int pipefd[2]);参数:
pipefd[2]是一个整型数组,用于接收管道的两个文件描述符:
pipefd[0]:管道的读端(只能读,不能写);pipefd[1]:管道的写端(只能写,不能读)。返回值:
- 成功:返回
0;- 失败:返回
-1,并设置errno(如EMFILE表示文件描述符耗尽)。核心功能
- 内核在内存中创建一个单向(半双工通信)的字节流缓冲区(管道),通过两个文件描述符(fd)操作:
fd[0]读端、fd[1]写端;- 仅支持父子 / 兄弟进程(有共同祖先)间通信(因为管道无名字,只能通过 fork 继承 fd);
- 随进程销毁:所有关联的文件描述符关闭后,内核自动释放缓冲区,无持久化存储。
匿名管道的核心特性
1. 阻塞特性(默认)
代码中子进程的
read(read_fd, &task, sizeof(Task))是阻塞调用:
- 若无任务时,子进程会阻塞在
read处,直到父进程write任务;- 可通过
fcntl(pipe_fd[0], F_SETFL, O_NONBLOCK)设置为非阻塞(无数据时返回EAGAIN)。2. 引用计数决定管道生命周期
管道的 “整个关闭 / 销毁” 由内核的「引用计数」决定,单一方关闭 FD(或进程结束)只会减少对应端的引用计数,只有当管道的所有读端、写端引用计数都归 0 时,内核才会销毁管道缓冲区(即 “关闭整个管道”)
代码中进程池析构时
close(fd)的核心作用:
- 父进程关闭所有写端 FD 后,管道的
writers引用计数变为 0;- 子进程的
read会返回 0(EOF),触发退出逻辑;- 若不关闭无用 FD(比如父进程不关闭读端),子进程的
read会一直阻塞(因为writers > 0)。3. 数据是字节流(无边界)
管道传输的是「无结构的字节流」,需上层约定数据格式:
- 代码中
Task是 POD 类型,通过sizeof(Task)固定长度读取,确保数据完整性;- 若传输变长数据(如字符串),需在数据中增加长度标识(如先写长度,再写内容),避免粘包。
使用流程
- 父进程调用
pipe()创建管道,得到读 / 写两个文件描述符;- 父进程调用
fork()创建子进程,子进程会继承父进程的两个管道文件描述符;- 父 / 子进程关闭不需要的端(比如父写子读:父关闭读端
pipefd[0],子关闭写端pipefd[1]);- 进程通过
read()/write()操作管道的读 / 写端传输数据;- 通信完成后,关闭剩余的文件描述符。
示例代码(父写子读)
#include <unistd.h> #include <stdio.h> #include <string.h> #include <sys/wait.h> int main() { int pipefd[2]; // pipefd[0] = 读端,pipefd[1] = 写端 pid_t pid; char buf[1024]; // 1. 创建管道 if (pipe(pipefd) == -1) { perror("pipe failed"); // 错误打印 return 1; } // 2. 创建子进程 pid = fork(); if (pid == -1) { perror("fork failed"); return 1; } if (pid == 0) { // 子进程:读数据 close(pipefd[1]); // 关闭写端(子进程只读) ssize_t n = read(pipefd[0], buf, sizeof(buf)); // 从管道读 if (n > 0) { printf("子进程收到数据:%s\n", buf); } close(pipefd[0]); // 关闭读端 return 0; } else { // 父进程:写数据 close(pipefd[0]); // 关闭读端(父进程只写) const char *msg = "Hello from Parent Process!"; write(pipefd[1], msg, strlen(msg) + 1); // +1 包含字符串终止符 '\0' close(pipefd[1]); // 关闭写端(触发子进程 read() 返回 EOF) wait(NULL); // 等待子进程执行完毕 return 0; } }优缺点 & 适用场景
- 优点:接口简单、无额外资源开销(管道在内存中,随进程销毁);
- 缺点:仅父子 / 兄弟进程、半双工、无消息边界;
- 适用:父子进程间简单的单向数据传输(如父进程给子进程传递配置)。
底层原理
内核数据结构(核心)
管道的本质是内核维护的一个「管道对象」,包含以下关键结构:
// 内核中管道对象的简化模型(实际定义在 linux/pipe_fs_i.h) struct pipe_inode_info { char* buffer; // 核心:环形缓冲区(默认大小 4KB,可配置) unsigned int size; // 缓冲区总大小(通常为 PAGE_SIZE,即 4096 字节) unsigned int r_pos; // 读指针:下一次读取的位置 unsigned int w_pos; // 写指针:下一次写入的位置 unsigned int count; // 缓冲区中已存储的字节数 int readers; // 读端引用计数(有多少进程持有读端 FD) int writers; // 写端引用计数(有多少进程持有写端 FD) struct wait_queue_head wait_read; // 读等待队列(缓冲区空时,读进程阻塞) struct wait_queue_head wait_write; // 写等待队列(缓冲区满时,写进程阻塞) };
- 环形缓冲区:解决缓冲区首尾衔接问题,写指针到末尾后回到起点,避免内存碎片;
- 引用计数:内核通过
readers/writers判断管道是否可用(比如写端引用为 0 时,读端读取会直接返回 EOF);- 等待队列:实现读写的阻塞机制(无数据时读阻塞,无空间时写阻塞)。
管道的创建流程(
pipe()系统调用)代码中
pipe(pipe_fd)的底层执行逻辑:// 代码中的调用 int pipe_fd[2]; pipe(pipe_fd); // 触发以下内核操作内核执行步骤:
- 分配缓冲区:在内核态申请一块连续的内存作为管道的环形缓冲区(默认 4KB);
- 创建管道对象:初始化
pipe_inode_info(读写指针置 0、引用计数置 0、等待队列初始化);- 分配文件描述符:从当前进程的文件描述符表中,分配两个未使用的 FD(如 3 和 4):
pipe_fd[0](读端):关联管道对象的读操作接口;pipe_fd[1](写端):关联管道对象的写操作接口;- 更新引用计数:将管道对象的
readers和writers各加 1(当前进程同时持有读写端);- 返回用户态:将两个 FD 写入
pipe_fd数组,返回 0 表示成功。进程间共享管道(
fork()的关键作用)匿名管道只能用于亲缘进程,核心原因是
fork()会复制父进程的文件描述符表:// 代码中 fork 后的 FD 继承逻辑 pid_t pid = fork(); if (pid == 0) { // 子进程:继承父进程的 pipe_fd[0] 和 pipe_fd[1] close(pipe_fd[1]); // 关闭写端,只保留读端 } else { // 父进程:保留 pipe_fd[1],关闭 pipe_fd[0] close(pipe_fd[0]); }
fork()后,父子进程的pipe_fd[0]和pipe_fd[1]都指向同一个内核管道对象;- 父子进程通过关闭不需要的 FD(父关读端、子关写端),形成「父写子读」的单向通信链路;
- 若没有
fork(),其他进程无法获取管道的 FD(匿名管道无文件路径,无法通过open()打开)。管道的读写机制
(1)写操作(
write(pipe_fd[1], data, len))内核执行逻辑:
- 检查管道写端引用计数(
writers > 0):若为 0,触发SIGPIPE信号(进程默认崩溃);- 检查缓冲区剩余空间:
- 若空间足够:将数据拷贝到缓冲区,更新写指针
w_pos和字节数count,唤醒读等待队列中的进程;- 若空间不足:当前进程进入写等待队列(阻塞),直到读进程取走数据、腾出空间;
- 特殊规则:原子写—— 若写入长度 ≤
PIPE_BUF(默认 4KB),内核保证写操作原子性(多进程同时写不会出现数据错乱);若超过 4KB,不保证原子性。(2)读操作(
read(pipe_fd[0], buf, len))内核执行逻辑:
- 检查管道读端引用计数(
readers > 0):若为 0,返回 -1(错误);- 检查缓冲区数据:
- 若有数据:将数据拷贝到用户态缓冲区,更新读指针
r_pos和字节数count,唤醒写等待队列中的进程;- 若无数据:
- 若写端引用计数
writers > 0:当前进程进入读等待队列(阻塞),直到写进程写入数据;- 若写端引用计数
writers = 0:返回 0(EOF,标识管道已关闭);- 返回值:实际读取的字节数(≤ 请求长度
len)。
管道不是磁盘文件,是内核态的一块连续内存缓冲区(大小通常为 4KB~64KB,可通过
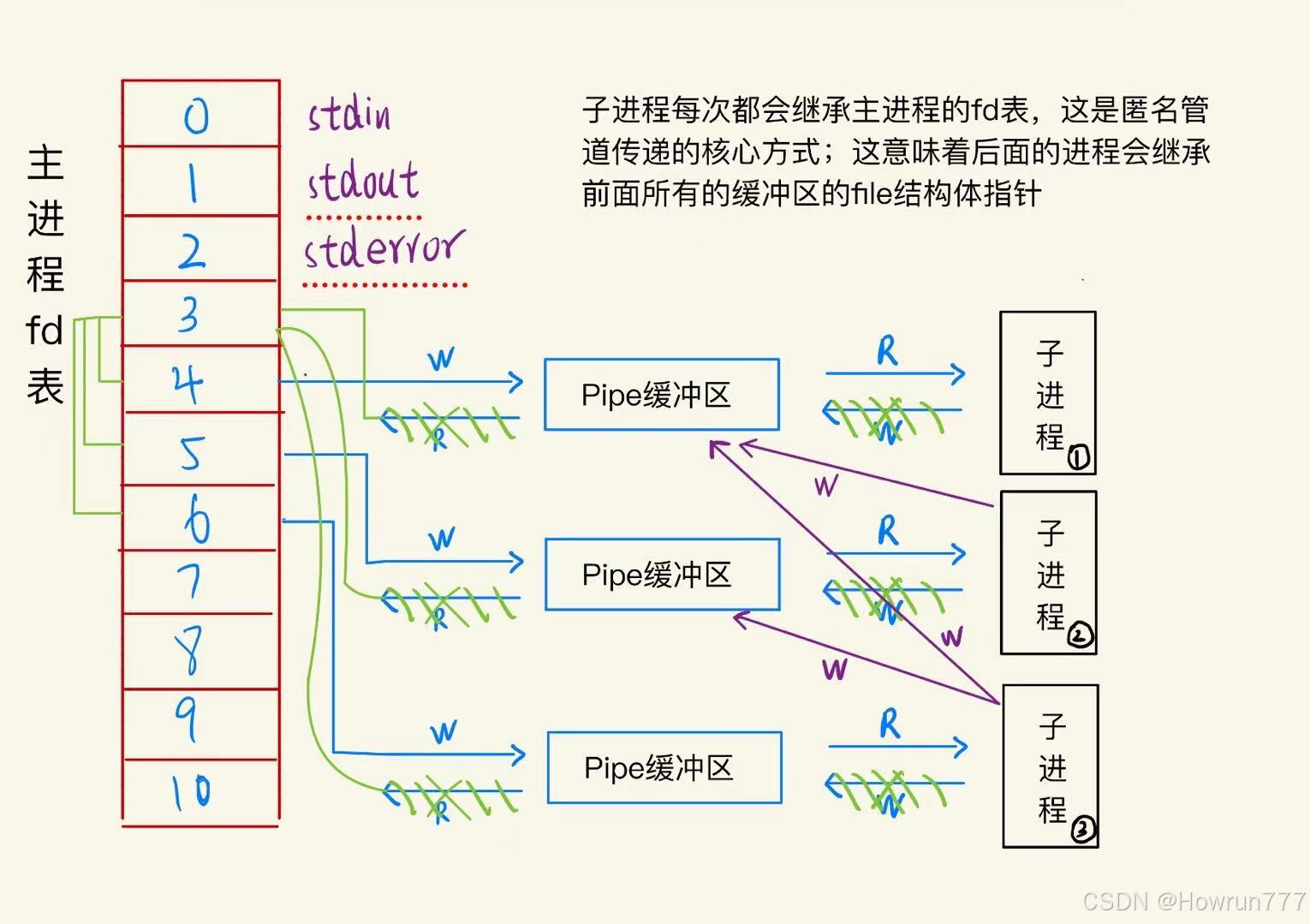
fcntl调整),由内核管理,进程无法直接访问,只能通过文件描述符(fd)间接操作;我们知道每个进程都会有一个fd表指针, 指向进程的fd表.
fork 子进程时:内核为子进程创建全新的 FD 表,并将父进程 FD 表中「FD 编号 → 文件表项」的映射关系完整复制到子进程的 FD 表中;结果:父子进程的 FD 表是「两个独立的内核对象」,只是表项内容(比如 FD 3 都指向文件表项 X)完全相同
因此操作系统 引入了COW写时拷贝, 当子进程修改父进程的全局变量, 就会触发COW, 为子进程单独创建一个新的全局变量;对于管道也是类似的道理, 管道同样由子进程和父进程通过fd表关联, 但是管道有个特点: 管道不属于虚拟地址空间, 也不是用户态的文件.
匿名管道的「一块环形缓冲区」对应一个内存 inode(资源载体),而「两个 file 结构体」是内核为「读、写两个操作端点」创建的独立上下文:
- 共享 inode → 保证读写操作的是同一块缓冲区;
- 独立 file → 实现读写端的操作逻辑、状态、生命周期分离,满足管道「半双工、读写分离」的核心语义。
为什么 “修改管道相关内容” 不触发 COW?
COW 的核心触发条件(关键前提)
写时拷贝仅针对 进程虚拟地址空间的「用户态物理内存页」,且必须同时满足三个条件:
- 多进程共享同一块「用户态」物理内存页;
- 该内存页被标记为「只读 + COW 标识」;
- 有进程尝试「修改」该内存页。
核心关键点:内核态的所有数据(包括 file 结构体、管道缓冲区)都不在 COW 的管辖范围内——COW 是为了优化「进程用户态内存共享」设计的,和内核态数据无关。
「通过 fd 写管道缓冲区」和「修改 fd 表 /file 结构体」,两者都不触发 COW,原因分别如下:
场景 1:通过 fd 写管道缓冲区(核心操作)
当父 / 子进程调用
write(fd[1], data, len)写管道时,流程是:plaintext
进程用户态内存(data) → 内核态 file 结构体 → 管道缓冲区
- 写操作的本质是「将用户态数据拷贝到内核态的管道缓冲区」,而非 “修改共享的用户态内存页”;
- 管道缓冲区是内核态内存,不属于任何进程的用户态地址空间,因此即使多个进程写,也不存在 “共享用户态页” 的前提,自然不触发 COW;
- 每个进程的
data是自己的私有用户态内存,修改自己的私有内存(比如给 data 赋值),也不会触发 COW(COW 仅针对「共享页」)。场景 2:修改 fd 表(比如子进程 close (fd [0]))
fork 后父子进程的 fd 表初始是共享同一块物理内存页(标记为 COW),但:
- 若子进程仅「使用」fd(比如读 / 写管道),不修改 fd 表 → 无 COW;
- 若子进程「修改」fd 表(比如 close (fd [0])、dup (fd))→ 触发 fd 表所在页的 COW(子进程获得 fd 表的独立副本);
- 但这是「fd 表的 COW」,而非「管道 /file 结构体的 COW」:
- file 结构体是内核态数据,多个进程的 fd 指向同一个 file 结构体是内核的 “引用计数管理”(file 结构体有
f_count字段,记录引用它的进程数),修改 fd 表只会改变引用计数,不会拷贝 file 结构体;- 管道缓冲区仍为内核态唯一副本,不受 fd 表 COW 的影响。
实例代码:进程池
#include <iostream> // 标准输入输出流(cout, cerr) #include <vector> // 动态数组容器,用于存储PID和文件描述符 #include <unistd.h> // Unix标准库(fork, pipe, read, write, close等) #include <sys/wait.h> // 进程等待相关(waitpid) #include <sys/types.h>// 系统类型定义(pid_t等) #include <cstring> // C字符串操作(strerror) #include <stdexcept> // 标准异常类(std::runtime_error, std::invalid_argument) // 定义简易任务结构体(序列化传输) struct Task { int task_id; // 任务ID,-1表示退出指令(特殊信号) int a; // 计算参数1 int b; // 计算参数2 // 这个结构体需要满足: // 1. 是POD(Plain Old Data)类型,可以安全序列化 // 2. 大小固定(3个int,通常12字节),方便通过管道传输 // 3. 没有指针成员,避免跨进程地址空间问题 // 4. 包含退出机制(task_id = -1) }; // 简易进程池类 class ProcessPool { public: // 构造函数:创建指定数量的子进程 ProcessPool(int num_processes) : num_processes_(num_processes) { if (num_processes <= 0) { throw std::invalid_argument("进程数必须大于0"); } create_processes(); } // 析构函数:回收子进程、关闭文件描述符 ~ProcessPool() { // 向所有子进程发送退出指令 Task exit_task{-1, 0, 0}; // 特殊任务:task_id = -1表示退出 for (int fd : write_fds_) { // 1. 发送退出信号 write(fd, &exit_task, sizeof(Task)); // 2. 关闭写端,触发子进程read返回0(管道EOF) close(fd); } // write_fds_中的fd是父进程的写端,关闭它们会: // - 使子进程的read返回0,从而退出循环 // - 释放内核中的管道资源 // 等待所有子进程退出(避免僵尸进程) for (pid_t pid : pids_) { waitpid(pid, nullptr, 0); // 阻塞等待,不关心退出状态 std::cout << "子进程 " << pid << " 已退出" << std::endl; } // 设计要点: // 1. 确保资源释放:管道文件描述符必须关闭 // 2. 避免僵尸进程:必须waitpid回收子进程资源 // 3. 优雅关闭:先通知退出,再等待,避免强制kill } // 提交任务到进程池(简易版:轮询分发任务) void submit_task(const Task& task) { static int idx = 0; // 静态变量,保持轮询状态 // 获取当前轮询的子进程对应的管道写端 int fd = write_fds_[idx]; // 向子进程管道写端写入任务(阻塞写入) ssize_t ret = write(fd, &task, sizeof(Task)); if (ret != sizeof(Task)) { // 错误处理:写入失败(可能管道已关闭) throw std::runtime_error("任务提交失败:" + std::string(strerror(errno))); } std::cout << "父进程:提交任务 " << task.task_id << " 到子进程 " << pids_[idx] << std::endl; // 更新轮询索引,实现简单的负载均衡 idx = (idx + 1) % num_processes_; // 轮询策略分析: // 优点:简单、公平,每个子进程获得相同数量的任务 // 缺点:不考虑子进程的负载差异,可能某些进程处理慢 } private: int num_processes_; // 子进程数量,决定并行度 std::vector<pid_t> pids_; // 子进程PID数组,用于进程管理 std::vector<int> write_fds_; // 父进程写端文件描述符数组 // 设计说明: // 1. num_processes_:控制并发级别,根据CPU核心数调整 // 2. pids_:记录所有子进程ID,便于后续管理和回收 // 3. write_fds_:每个子进程对应一个管道写端,父进程通过这些fd发送任务 // 子进程处理逻辑:循环读取任务并执行 static void child_process(int read_fd) { // 注意:这是静态方法,没有this指针,可以安全地在子进程中运行 Task task; // 无限循环,直到收到退出指令或管道关闭 while (true) { // 阻塞读取管道中的任务,从read_fd读取sizeof(task)字节的内容,存放在task ssize_t ret = read(read_fd, &task, sizeof(Task)); // 读取失败或管道关闭 if (ret <= 0) { break; // 退出循环,结束子进程 } // 检查是否为退出指令 if (task.task_id == -1) { break; // 收到退出信号,终止子进程 } // 处理任务(这里只是简单的加法计算) int result = task.a + task.b; // 输出执行结果 std::cout << "子进程 " << getpid() << ":处理任务 " << task.task_id << " -> " << task.a << " + " << task.b << " = " << result << std::endl; } // 清理资源:关闭管道读端 close(read_fd); // 子进程正常退出 exit(0); // 关键点: // 1. 子进程完全独立,有自己的地址空间 // 2. 通过read系统调用阻塞等待任务 // 3. exit(0)确保子进程正确退出,不会执行父进程代码 } // 创建子进程和通信管道 void create_processes() { for (int i = 0; i < num_processes_; ++i) { // 步骤1:创建管道 int pipe_fd[2]; // pipe_fd[0]: 读端,pipe_fd[1]: 写端 if (pipe(pipe_fd) == -1) { throw std::runtime_error("管道创建失败:" + std::string(strerror(errno))); } // pipe() 在内核中创建缓冲区,返回两个文件描述符 // 父子进程通过读写这两个fd进行通信 // 步骤2:创建子进程 pid_t pid = fork(); if (pid == -1) { throw std::runtime_error("fork失败:" + std::string(strerror(errno))); } if (pid == 0) { // 子进程代码块 // ------------------------------------------ // 重要:子进程继承父进程的所有文件描述符 // 包括刚创建的pipe_fd[0]和pipe_fd[1] // 子进程关闭写端,只保留读端 close(pipe_fd[1]); // 原因:子进程只需要读取任务,不需要写入 // 进入任务处理循环(不会返回) child_process(pipe_fd[0]); // 注意:child_process会调用exit(),所以后面的代码不会执行 // ------------------------------------------ } else { // 父进程代码块 // ------------------------------------------ // 父进程关闭读端,保留写端 close(pipe_fd[0]); // 原因:父进程只需要发送任务,不需要读取 // 记录子进程信息 pids_.push_back(pid); // 保存子进程PID write_fds_.push_back(pipe_fd[1]); // 保存管道写端 std::cout << "父进程:创建子进程 " << pid << std::endl; // ------------------------------------------ } } // fork() 工作原理: // 1. 创建子进程,复制父进程的地址空间 // 2. 子进程从fork()返回0,父进程返回子进程PID // 3. 父子进程并发执行,调度由操作系统决定 } }; // 测试代码 int main() { try { // 创建包含3个子进程的进程池 ProcessPool pool(3); // 提交5个测试任务 for (int i = 0; i < 5; ++i) { Task task{i, i * 10, i * 20}; pool.submit_task(task); usleep(100000); // 模拟任务提交间隔(可选) } } catch (const std::exception& e) { std::cerr << "错误:" << e.what() << std::endl; return 1; } return 0; }表面上看起来:
实际上:
输入:
ls /proc/进程PID/fd -l即可查询此进程的fd表
2. 命名管道(FIFO / 有名管道)
命名管道(Named Pipe),也称为FIFO(First In First Out),是 Linux 系统中一种特殊的进程间通信(IPC)机制。它的本质是一个存在于文件系统中的特殊文件,通过文件路径名标识,允许任意进程(无论是否有亲缘关系)通过打开该文件进行数据传输,数据遵循 "先进先出" 的原则。
1.1 与匿名管道的核心区别
特性 命名管道(FIFO) 匿名管道(Pipe) 存在形式 存在于文件系统中,有具体路径名 仅存在于内核中,无文件系统实体 适用进程 任意进程(无亲缘关系也可通信) 仅适用于有亲缘关系的进程(父子 / 兄弟) 创建方式 mkfifo()系统调用或mkfifo命令pipe()系统调用生命周期 手动删除( rm)或文件系统卸载随进程退出自动销毁 打开方式 通过 open()函数按路径打开直接使用 pipe()返回的文件描述符可复用性 可被多个进程反复打开和使用 仅能被创建它的进程及其子进程使用 1.2 核心特性
- 先进先出:数据的读取顺序与写入顺序完全一致,不支持随机访问。
- 半双工通信:同一时刻只能单向传输数据,双向通信需要两个命名管道。
- 文件系统可见:通过
ls -l命令查看时,文件类型标识为p(pipe)。- 内核缓冲:数据存储在内核缓冲区中,不落地到磁盘,性能接近匿名管道。
- 原子操作保障:当写入数据量小于等于
PIPE_BUF时,系统保证写入的原子性(不会被其他进程的写入打断)。
2.1 内核数据结构
命名管道的底层实现依赖于内核中的两个核心结构:
struct inode:文件系统中的索引节点,标识命名管道的存在,其i_pipe指针指向管道的核心数据结构。struct pipe_inode_info:管道的核心控制结构,包含:
- 环形缓冲区:存储传输的数据(默认大小通常为 64KB,可通过
fcntl调整)。- 读写等待队列:阻塞的读 / 写进程队列,用于实现同步机制。
- 引用计数:记录当前打开该管道的进程数。
- 互斥锁与自旋锁:保障并发访问的线程安全。
2.2 数据传输流程
命名管道的数据传输本质是用户态 - 内核态 - 用户态的拷贝过程:
- 写进程:通过
write()将用户空间数据拷贝到内核的管道缓冲区。- 内核调度:当缓冲区有数据时,唤醒阻塞的读进程。
- 读进程:通过
read()将内核缓冲区的数据拷贝到用户空间。注意:命名管道的数据不会写入磁盘,仅存在于内核内存中,因此性能远高于普通文件传输。
3.1 创建命名管道
3.1.1 命令行创建
使用
mkfifo命令直接在文件系统中创建命名管道:# 创建名为myfifo的命名管道,权限为0666(读写权限) mkfifo -m 0666 myfifo # 查看管道文件 ls -l myfifo # 输出:prw-rw-rw- 1 user user 0 6月 10 10:00 myfifo3.1.2 系统调用创建
mkfifo()函数是创建命名管道的核心系统调用,原型如下:#include <sys/types.h> #include <sys/stat.h> int mkfifo(const char *pathname, mode_t mode);
- 参数说明:
pathname:管道文件的路径名(绝对路径或相对路径)。mode:管道文件的权限(如0666),实际权限会受umask影响。- 返回值:成功返回 0,失败返回 - 1 并设置
errno。- 常见错误码:
EEXIST:指定路径的文件已存在。ENOENT:路径中的目录不存在。EACCES:没有权限创建文件。3.2 打开命名管道
命名管道通过
open()函数打开,但其行为与普通文件有显著区别:#include <fcntl.h> int open(const char *pathname, int flags);3.2.1 阻塞模式(默认)
- 只读打开(O_RDONLY):如果没有进程以只写模式打开该管道,调用会阻塞,直到有写进程打开。
- 只写打开(O_WRONLY):如果没有进程以只读模式打开该管道,调用会阻塞,直到有读进程打开。
- 读写打开(O_RDWR):不会阻塞,但这种用法不符合管道的设计初衷,一般不推荐。
3.2.2 非阻塞模式(O_NONBLOCK)
当
flags包含O_NONBLOCK时,open()不会阻塞:
- 只读打开:如果没有写进程,立即返回成功(后续读操作可能返回 0)。
- 只写打开:如果没有读进程,立即返回失败,
errno设为ENXIO。3.3 读写操作
命名管道的读写操作与普通文件一致,使用
read()和write()函数,但有特殊的行为规则:3.3.1 读操作(read ())
#include <unistd.h> ssize_t read(int fd, void *buf, size_t count);
参数名 类型 核心作用 fdint文件描述符,即通过 open()打开 FIFO 后返回的整数(必须是O_RDONLY/O_RDWR模式)bufvoid *指向用户空间缓冲区的指针,用于存储从 FIFO 读取的数据(需提前分配内存) countsize_t期望读取的最大字节数(不能超过 buf的内存大小,否则会导致缓冲区溢出)返回值
- 正数:成功读取的字节数(可能小于
count,比如 FIFO 中剩余数据不足);- 0:所有写端已关闭(FIFO 到达 EOF,这是命名管道的关键特征);
- -1:读取失败,需检查
errno(结合 FIFO 场景的关键错误码见下文)。FIFO 场景专属注意事项(对应之前的 3.3.1)
- 阻塞模式(默认):若 FIFO 无数据但写端未关闭,
read()会阻塞,直到有数据写入或写端全部关闭;- 非阻塞模式(
O_NONBLOCK):若 FIFO 无数据,read()立即返回 - 1,且errno = EAGAIN(需重试,非真正错误);- 常见错误码:
EAGAIN:非阻塞模式下无数据;EBADF:fd不是有效的读文件描述符;EINTR:读取过程中被信号中断(可重试)。3.3.2 写操作(write ())
#include <unistd.h> ssize_t write(int fd, const void *buf, size_t count);
参数名 类型 核心作用 fdint文件描述符,即通过 open()打开 FIFO 后返回的整数(必须是O_WRONLY/O_RDWR模式)bufconst void *指向用户空间缓冲区的指针,存储要写入 FIFO 的数据(数据需提前准备) countsize_t期望写入的字节数(注意 PIPE_BUF阈值,保证原子性)返回值
- 正数:成功写入的字节数(可能小于
count,比如 FIFO 缓冲区空间不足);- -1:写入失败,需检查
errno(结合 FIFO 场景的关键错误码见下文);- 注意:
write()不会返回 0(这是与read()的核心区别)。FIFO 场景专属注意事项(对应之前的 3.3.2)
- 阻塞模式(默认):若 FIFO 缓冲区空间不足,
write()会阻塞,直到有读进程取走数据、缓冲区有空间;- 非阻塞模式(
O_NONBLOCK):若缓冲区不足,write()立即返回 - 1,且errno = EAGAIN(需重试);- 关键错误 / 信号:
- 若所有读端已关闭,
write()会触发SIGPIPE信号(默认终止进程),若捕获该信号,write()返回 - 1 且errno = EPIPE;- 常见错误码:
EAGAIN(非阻塞无空间)、EPIPE(读端全关)、EBADF(无效写描述符)、EINTR(被信号中断);- 原子性:当
count ≤ PIPE_BUF(通常 4096 字节)时,系统保证写入原子性,多进程并发写入不会错乱;超过则无原子性保证。3.3.3 原子操作与 PIPE_BUF
PIPE_BUF是 Linux 内核定义的宏(在<limits.h>中),表示管道的原子写入阈值,通常为 4096 字节(4KB)。
- 当写入数据量 ≤
PIPE_BUF时,系统保证写入的原子性,不会被其他进程的写入打断。- 当写入数据量 >
PIPE_BUF时,写入可能被拆分,不保证原子性,多进程并发写入可能导致数据错乱。可以通过
sysconf()函数获取系统的PIPE_BUF值:#include <unistd.h> long pipe_buf = sysconf(_SC_PIPE_BUF);3.4 关闭与销毁
- 关闭:通过
close()函数关闭管道的文件描述符,当最后一个进程关闭管道时,内核会释放管道的内核缓冲区资源。- 销毁:命名管道作为文件系统中的实体,需要手动通过
unlink()系统调用或rm命令删除,否则会一直存在于文件系统中。
4.1 基础读写通信示例
写进程(fifo_writer.c)
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <fcntl.h> #include <sys/stat.h> #include <sys/types.h> #define FIFO_PATH "./myfifo" #define BUFFER_SIZE 1024 int main() { // 1. 创建命名管道,权限0666(读写权限) int ret = mkfifo(FIFO_PATH, 0666); if (ret == -1) { perror("mkfifo failed"); // 若管道已存在,忽略错误(允许复用) if (errno != EEXIST) { exit(EXIT_FAILURE); } } // 2. 以只写模式打开管道(阻塞模式) int fd = open(FIFO_PATH, O_WRONLY); if (fd == -1) { perror("open fifo failed"); exit(EXIT_FAILURE); } printf("Writer: 成功打开管道,等待读进程连接...\n"); // 3. 写入数据 const char *messages[] = { "Hello from writer!", "This is a named pipe example.", "End of message." }; int msg_count = sizeof(messages) / sizeof(messages[0]); for (int i = 0; i < msg_count; i++) { ssize_t bytes_written = write(fd, messages[i], strlen(messages[i]) + 1); if (bytes_written == -1) { perror("write failed"); close(fd); exit(EXIT_FAILURE); } printf("Writer: 已写入数据: %s\n", messages[i]); sleep(1); // 模拟间隔写入 } // 4. 关闭管道 close(fd); printf("Writer: 数据写入完成,关闭管道\n"); return 0; }读进程(fifo_reader.c)
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <fcntl.h> #include <sys/stat.h> #include <sys/types.h> #define FIFO_PATH "./myfifo" #define BUFFER_SIZE 1024 int main() { // 1. 以只读模式打开管道(阻塞模式) int fd = open(FIFO_PATH, O_RDONLY); if (fd == -1) { perror("open fifo failed"); exit(EXIT_FAILURE); } printf("Reader: 成功打开管道,开始读取数据...\n"); // 2. 读取数据 char buffer[BUFFER_SIZE]; ssize_t bytes_read; while ((bytes_read = read(fd, buffer, BUFFER_SIZE)) > 0) { printf("Reader: 读取到数据: %s\n", buffer); memset(buffer, 0, BUFFER_SIZE); // 清空缓冲区 } // 3. 处理读取结果 if (bytes_read == 0) { printf("Reader: 写端已关闭,读取完成\n"); } else if (bytes_read == -1) { perror("read failed"); close(fd); exit(EXIT_FAILURE); } // 4. 关闭管道并删除文件 close(fd); unlink(FIFO_PATH); // 读取完成后删除管道 printf("Reader: 关闭管道并删除文件\n"); return 0; }编译与运行
# 编译 gcc fifo_writer.c -o writer gcc fifo_reader.c -o reader # 运行(两个终端分别执行) # 终端1:运行读进程 ./reader # 终端2:运行写进程 ./writer4.2 非阻塞模式通信示例
修改读进程的打开方式,使用非阻塞模式:
// 以只读+非阻塞模式打开管道 int fd = open(FIFO_PATH, O_RDONLY | O_NONBLOCK); if (fd == -1) { perror("open fifo failed"); exit(EXIT_FAILURE); } // 非阻塞读取逻辑 while (1) { ssize_t bytes_read = read(fd, buffer, BUFFER_SIZE); if (bytes_read > 0) { printf("Reader: 读取到数据: %s\n", buffer); memset(buffer, 0, BUFFER_SIZE); } else if (bytes_read == 0) { printf("Reader: 写端已关闭\n"); break; } else { if (errno == EAGAIN) { // 无数据,等待1秒后重试 printf("Reader: 暂无数据,等待...\n"); sleep(1); } else { perror("read failed"); break; } } }
5.1 阻塞与非阻塞机制的底层逻辑
命名管道的阻塞机制依赖于内核的等待队列:
- 当读进程打开管道但无数据时,读进程会被加入到管道的读等待队列,进程状态变为
TASK_INTERRUPTIBLE,让出 CPU。- 当写进程写入数据后,内核会唤醒读等待队列中的进程,使其恢复运行并读取数据。
- 非阻塞模式下,进程不会被加入等待队列,而是立即返回错误或 0,由用户态程序自行处理重试逻辑。
5.2 SIGPIPE 信号处理
当写进程向已关闭读端的管道写入数据时,内核会向写进程发送
SIGPIPE信号,默认行为是终止进程。为了避免进程意外退出,可以通过signal()或sigaction()函数捕获该信号:#include <signal.h> void sigpipe_handler(int signum) { printf("Received SIGPIPE signal, read end closed\n"); } int main() { // 注册SIGPIPE信号处理函数 signal(SIGPIPE, sigpipe_handler); // ... 后续代码 ... }
6.1 无亲缘关系进程通信
这是命名管道最核心的应用场景,例如:
- 后台服务进程与前台命令行工具的通信。
- 不同用户的进程之间的数据传输(需保证管道文件的权限正确)。
6.2 日志收集与处理
通过命名管道实现日志的解耦:
- 业务进程将日志写入命名管道。
- 专门的日志处理进程(如日志过滤、归档、上传)从管道读取日志并处理。
- 优势:业务进程无需关心日志的存储和上传,提高性能和可维护性。
6.3 命令行工具协作
通过命名管道连接多个命令行工具,实现数据流式处理:
# 将ls的输出通过命名管道传递给grep过滤 mkfifo pipe ls -l > pipe & grep ".c" < pipe rm pipe6.4 服务端 - 客户端模型
服务端创建命名管道,客户端通过该管道向服务端发送请求,服务端处理后返回结果(需另一个管道用于响应):
- 优点:实现简单,无需复杂的网络编程。
- 缺点:仅适用于本地进程通信,不支持跨机器。
IPC 机制 优点 缺点 适用场景 命名管道 实现简单,文件系统可见,跨进程 半双工,无数据边界,速度一般 本地任意进程间的简单数据传输 匿名管道 轻量,性能高 仅适用于亲缘进程,无文件实体 父子进程间的临时通信 消息队列 有数据边界,支持多消息类型 数据量有限,内核资源消耗较大 结构化数据的进程间通信 共享内存 速度最快(无数据拷贝) 需同步机制(信号量),实现复杂 大数据量、高性能需求的通信 套接字(UDS) 支持全双工,可跨网络 实现复杂,性能开销较大 本地 / 跨网络的进程通信
3. 信号(Signal)
核心原理
- 内核向进程发送的异步通知(中断当前执行流程),用于告知进程 “发生了某个事件”(如 Ctrl+C 触发
SIGINT);- Linux 定义了 64 种信号(
kill -l查看),分为:
- 可靠信号(34~64):支持排队,不会丢失;
- 不可靠信号(1~31):不排队,可能丢失;
- 进程对信号的处理方式:默认处理(如
SIGTERM终止进程)、忽略、自定义捕获。常用 API
函数 作用 signal()注册信号处理函数(简单) sigaction()注册信号处理函数(推荐,支持更多配置) kill()向指定进程 / 进程组发信号 raise()向自身进程发信号 sigqueue()发送带参数的可靠信号 示例代码(捕获 SIGINT 信号)
#include <stdio.h> #include <signal.h> #include <unistd.h> // 自定义信号处理函数 void sigint_handler(int signum) { printf("\n捕获到信号 %d(SIGINT),拒绝退出!\n", signum); } int main() { // 注册 SIGINT(Ctrl+C)的处理函数 struct sigaction sa; sa.sa_handler = sigint_handler; sigemptyset(&sa.sa_mask); // 处理信号时屏蔽的信号集(空=不屏蔽) sa.sa_flags = 0; // 默认行为 if (sigaction(SIGINT, &sa, NULL) == -1) { perror("sigaction failed"); return 1; } printf("进程运行中,按 Ctrl+C 测试...\n"); while (1) { sleep(1); // 阻塞等待信号 } return 0; }优缺点 & 适用场景
- ✅ 优点:轻量、异步、无需主动轮询;
- ❌ 缺点:仅能传递 “事件标识”(最多带少量参数)、不可靠信号易丢失;
- 📌 适用:进程间的异步通知(如终止进程、触发刷 新、异常通知)。
二、System V IPC(高性能、面向内核对象)
System V 是 Unix 系统的标准,设计了三类内核级 IPC 对象(消息队列、共享内存、信号量),特点是:
- 由键值(key) 标识(通过
ftok()生成),而非文件路径;- 存在于内核中,进程退出后不会自动销毁(需手动删除,否则占用资源);
- 可通过
ipcs命令查看,ipcrm命令删除。
1. System V 共享内存(Shared Memory)
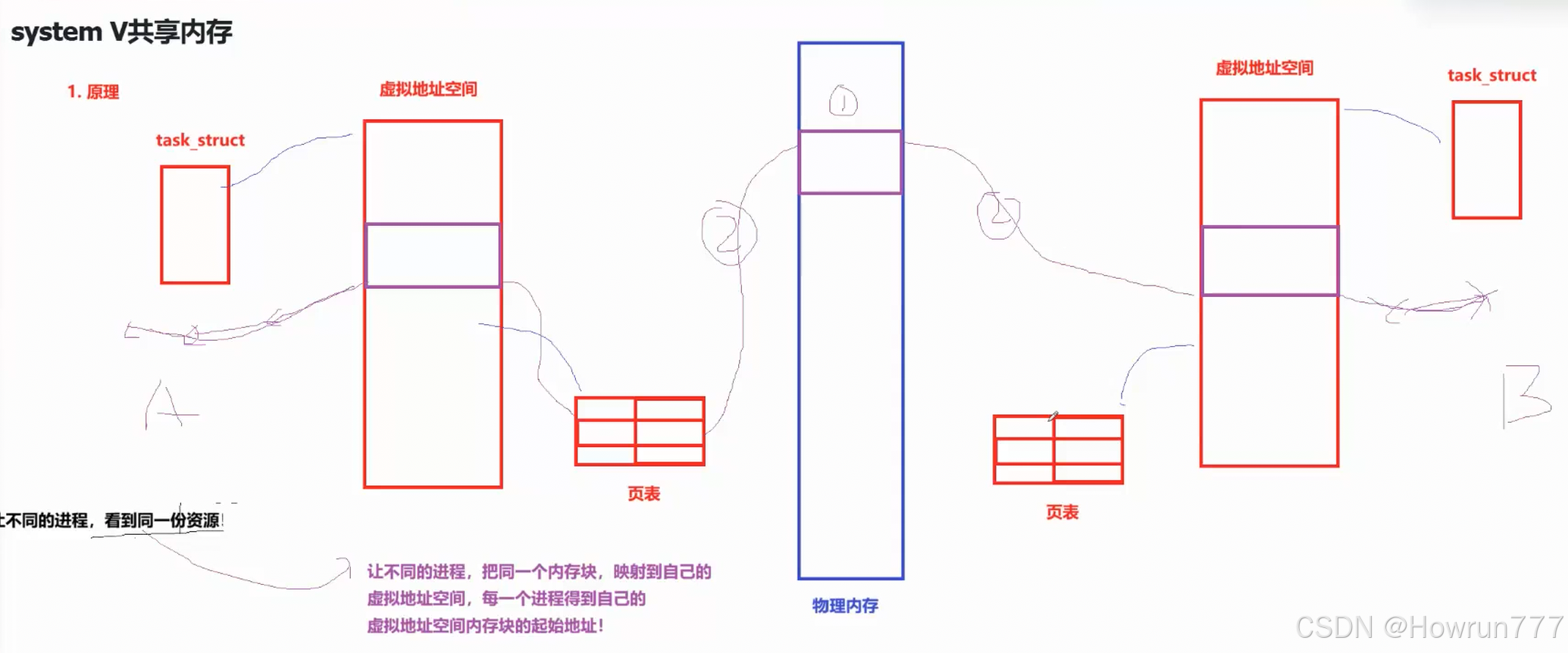
核心原理
- 最快的 IPC 机制:内核开辟一块连续的内存区域,映射到多个进程的虚拟地址空间(共享区),进程直接读写该内存(无需内核中转);
- 无数据拷贝(其他 IPC 需多次拷贝:用户态→内核态→用户态),性能极致;
- 无同步机制:需配合信号量 / 互斥锁防止 “读写冲突”(如进程 A 写时进程 B 读)。
使用流程
- 用
ftok()生成唯一键值;- 用
shmget()创建 / 获取共享内存段;- 用
shmat()将共享内存映射到进程的虚拟地址空间;- 进程直接读写映射后的内存;
- 用
shmdt()解除映射;- 用
shmctl()删除共享内存段(释放内核资源)。1. ftok ():生成 IPC 唯一键值
将「文件路径」和「项目 ID」转换为
key_t类型的整数键值,用于标识 System V IPC 对象(共享内存、消息队列、信号量)。不同进程使用相同的路径和项目 ID,可生成相同的键值,从而访问同一个 IPC 对象。#include <sys/ipc.h> key_t ftok(const char *pathname, int proj_id);
参数 说明 pathname必须是存在且可访问的文件路径(如 /tmp/test),文件仅作为标识,无需读写。proj_id项目标识(低 8 位有效,通常取 1-255),仅用于区分同一文件下的不同 IPC 对象。 返回值
- 成功:返回唯一的
key_t类型整数(通常是 int 别名);- 失败:返回
-1,并设置errno(如ENOENT路径不存在、EACCES权限不足)。注意事项
- 若文件被删除后重建,即使路径和 ID 相同,生成的键值也会变化;
- 若无需跨进程共享,可直接用
IPC_PRIVATE替代 ftok 生成的键值(仅当前进程 / 子进程可用)。
2. shmget ():创建 / 获取共享内存段
在内核中创建或获取共享内存段,返回唯一的
shmid(共享内存标识符),内核会为每个共享内存段维护一个shmid_ds结构体(存储大小、权限、映射数等信息)。#include <sys/ipc.h> #include <sys/shm.h> int shmget(key_t key, size_t size, int shmflg);
参数 说明 keyftok 生成的键值,或 IPC_PRIVATE(创建私有共享内存)。size共享内存大小(字节):- 创建时:必须指定(按系统页大小 4K 对齐,不足则向上取整);- 获取时:设为 0。 shmflg标志位(按位或组合):- IPC_CREAT:不存在则创建,存在则获取;-IPC_EXCL:与IPC_CREAT联用,若已存在则失败(确保创建新段);- 权限位:如0664(同文件权限,八进制)。返回值
- 成功:返回非负整数
shmid(共享内存标识符);- 失败:返回
-1,设置errno(如EEXIST已存在、ENOMEM内存不足、EINVALsize 无效)。注意事项
- 共享内存创建后,即使创建进程退出,也会一直存在于内核,直到被
shmctl删除或系统重启;- 权限位需与后续
shmat的读写权限匹配(如SHM_RDONLY需 shmget 设置读权限)。
3. shmat ():映射共享内存到进程地址空间
将内核中的共享内存段附加(映射) 到进程的虚拟地址空间,返回映射后的地址,进程可直接读写该地址(等同于操作普通内存)。
#include <sys/shm.h> void *shmat(int shmid, const void *shmaddr, int shmflg);
参数 说明 shmidshmget 返回的共享内存标识符。 shmaddr指定映射到进程的虚拟地址:- 设 NULL(推荐):由系统自动分配;- 非 NULL:需对齐页大小,通常不推荐。shmflg映射标志:- 0:默认,读写权限;-SHM_RDONLY:只读权限(需 shmget 设置读权限)。返回值
- 成功:返回映射后的虚拟地址(
void*);- 失败:返回
(void*)-1,设置errno(如EINVALshmid 无效、EACCES权限不足)。注意事项
- 多个进程可映射同一个共享内存段,读写操作直接同步;
- 映射后进程退出,共享内存不会自动删除,仅解除映射。
4. shmdt ():解除共享内存映射
将共享内存段与进程的虚拟地址空间分离(解除映射),仅断开关联,不删除内核中的共享内存。
#include <sys/shm.h> int shmdt(const void *shmaddr);
参数 说明 shmaddrshmat 返回的映射地址。 返回值
- 成功:返回
0;- 失败:返回
-1,设置errno(如EINVAL地址不是映射地址)。注意事项
- 解除映射后,进程不可再访问该地址,否则触发段错误;
- 若所有进程都解除映射,共享内存仍存在于内核,需
shmctl主动删除。
5. shmctl ():控制共享内存段(核心:删除)
System V 共享内存的控制接口,支持获取状态、设置属性、删除共享内存(最常用
IPC_RMID命令)。#include <sys/ipc.h> #include <sys/shm.h> int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数 说明 shmidshmget 返回的共享内存标识符。 cmd操作命令(核心):- IPC_STAT:读取共享内存状态,存入buf;-IPC_SET:修改共享内存属性(从buf读取);-IPC_RMID:删除共享内存段(内核释放资源)。bufstruct shmid_ds结构体指针:-IPC_STAT/IPC_SET:存储 / 读取状态;-IPC_RMID:设NULL即可。核心结构体(简化版)
struct shmid_ds { struct ipc_perm shm_perm; // 权限结构体(含所有者、权限位等) size_t shm_segsz; // 共享内存大小(字节) pid_t shm_lpid; // 最后操作的进程ID pid_t shm_cpid; // 创建进程ID shmatt_t shm_nattch; // 当前映射的进程数 time_t shm_atime; // 最后映射时间 time_t shm_dtime; // 最后解除映射时间 };返回值
- 成功:返回
0(IPC_STAT/IPC_SET/IPC_RMID);- 失败:返回
-1,设置errno(如EINVALshmid 无效、EPERM权限不足)。注意事项
- 执行
IPC_RMID后,内核标记共享内存为「待删除」:- 若仍有进程映射,新进程无法再映射该段;- 当所有进程解除映射后,内核才真正释放资源;- 普通用户仅能删除自己创建的共享内存,root 可删除所有。
二、完整示例(创建→写入→读取→删除)
1. 写进程(shm_write.c)
#include <stdio.h> // 提供printf、perror等输入输出函数 #include <stdlib.h> // 提供exit()退出函数(进程出错时终止) #include <string.h> // 提供strncpy字符串拷贝函数 #include <sys/ipc.h> // 提供ftok()函数(生成IPC键值) #include <sys/shm.h> // 提供shmget/shmat/shmdt/shmctl等共享内存核心函数 #include <unistd.h> // 提供getchar()(等待用户输入)、系统调用基础功能 // 2. 宏定义:把固定值抽出来,方便修改和理解 #define PATHNAME "/tmp/shm_test" // ftok需要的文件路径(必须存在!小白要先touch这个文件) #define PROJ_ID 100 // 项目ID(仅低8位有效,随便设1-255之间的数即可) #define SHM_SIZE 4096 // 共享内存大小(字节),4096是系统页大小(对齐要求,不能随便设小) int main() { // -------------------------- 步骤1:生成唯一的IPC键值 -------------------------- // key_t是专门存IPC键值的类型(本质是整数) // ftok作用:把"文件路径+项目ID"转换成唯一整数,让读写进程能找到同一个共享内存 key_t key = ftok(PATHNAME, PROJ_ID); // 检查ftok是否失败(返回-1就是失败) if (key == -1) { // perror:自动打印"xxx failed: 具体错误原因"(比如文件不存在会提示No such file) perror("ftok failed"); exit(1); // 1表示异常退出(0是正常退出),终止进程 } // -------------------------- 步骤2:创建共享内存段 -------------------------- // shmget作用:向内核申请一块共享内存,返回"共享内存ID(shmid)"(类似文件句柄) // 参数1:ftok生成的键值(标识共享内存) // 参数2:共享内存大小(必须是系统页大小的整数倍,4096是最常用的) // 参数3:标志位组合(IPC_CREAT=创建新的 | IPC_EXCL=如果已存在则报错 | 0664=权限,和文件权限一样) int shmid = shmget(key, SHM_SIZE, IPC_CREAT | IPC_EXCL | 0664); // 检查shmget是否失败(比如内存不足、键值已存在) if (shmid == -1) { perror("shmget failed"); exit(1); } // 打印shmid,方便调试(比如用ipcs -m命令查看时能对应上) printf("共享内存ID(shmid):%d\n", shmid); // -------------------------- 步骤3:把共享内存映射到进程地址空间 -------------------------- // shmat作用:把内核里的共享内存,"挂到"当前进程的内存地址上,进程才能直接读写 // 参数1:shmget返回的共享内存ID // 参数2:指定映射的地址(设NULL让系统自动分配,小白千万别改) // 参数3:映射权限(0=读写,SHM_RDONLY=只读) // 返回值:映射后的内存地址(进程直接操作这个地址就等于操作共享内存) char *shm_addr = (char *)shmat(shmid, NULL, 0); // 检查映射是否失败(返回(void*)-1就是失败,注意强制类型转换) if (shm_addr == (void *)-1) { perror("shmat failed"); exit(1); } // -------------------------- 步骤4:向共享内存写入数据 -------------------------- // 要写入的字符串(小白注意:C语言字符串末尾有个隐藏的'\0',表示结束) const char *msg = "Hello, Shared Memory!"; // strncpy:把msg拷贝到共享内存地址shm_addr // 第三个参数:strlen(msg)+1 是为了把末尾的'\0'也拷贝过去(否则读的时候会乱码) strncpy(shm_addr, msg, strlen(msg) + 1); // 打印写入的内容,确认写成功 printf("已向共享内存写入:%s\n", shm_addr); // -------------------------- 等待读进程读取数据 -------------------------- // 暂停进程,等用户按回车再继续(给读进程留时间读取,否则写进程直接删了共享内存,读进程就读不到了) printf("请按回车键继续(此时可以启动读进程读取数据)...\n"); getchar(); // 阻塞等待用户输入回车 // -------------------------- 步骤5:解除共享内存映射 -------------------------- // shmdt作用:把共享内存和当前进程"解绑"(进程不再能访问这个地址,但共享内存还在内核里) // 参数:shmat返回的映射地址 if (shmdt(shm_addr) == -1) { perror("shmdt failed"); exit(1); } // -------------------------- 步骤6:删除共享内存(释放内核资源) -------------------------- // shmctl作用:控制共享内存(这里用IPC_RMID命令删除) // 参数1:共享内存ID // 参数2:操作命令(IPC_RMID=删除共享内存) // 参数3:共享内存的状态结构体(删除时设NULL即可) if (shmctl(shmid, IPC_RMID, NULL) == -1) { perror("shmctl failed"); exit(1); } // 正常退出进程(0表示无错误) return 0; }2. 读进程(shm_read.c)
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/ipc.h> #include <sys/shm.h> #include <unistd.h> #define PATHNAME "/tmp/shm_test" #define PROJ_ID 100 #define SHM_SIZE 4096 int main() { // 1. 生成相同键值 key_t key = ftok(PATHNAME, PROJ_ID); if (key == -1) { perror("ftok failed"); exit(1); } // 2. 获取已存在的共享内存(size设0,仅获取) int shmid = shmget(key, 0, 0); if (shmid == -1) { perror("shmget failed"); exit(1); } printf("shmid: %d\n", shmid); // 3. 映射(只读权限) char *shm_addr = (char *)shmat(shmid, NULL, SHM_RDONLY); if (shm_addr == (void *)-1) { perror("shmat failed"); exit(1); } // 4. 读取数据 printf("Read from shm: %s\n", shm_addr); // 5. 解除映射 if (shmdt(shm_addr) == -1) { perror("shmdt failed"); exit(1); } return 0; }编译与运行
# 先创建标识文件 touch /tmp/shm_test # 编译 gcc shm_write.c -o shm_write gcc shm_read.c -o shm_read # 先运行写进程 ./shm_write # 再新开终端运行读进程 ./shm_read
三、常用辅助命令
命令 说明 ipcs -m查看所有共享内存段 ipcrm -m <shmid>命令行删除指定共享内存 cat /proc/sys/kernel/shmmax查看共享内存最大限制 优缺点 & 适用场景
- ✅ 优点:无数据拷贝、性能极致、支持大数据传输;
- ❌ 缺点:无内置同步、需手动管理内核资源;
- 📌 适用:高吞吐的大数据交换(如视频流、游戏场景数据)。
2. System V 消息队列(Message Queue)
System V 消息队列是 Linux/Unix 系统中核心的进程间通信(IPC)机制,属于 System V IPC 家族(还包括共享内存、信号量)。它的核心是内核维护的带类型的消息链表,与命名管道(FIFO)的流式字节传输不同,消息队列以 “结构化消息” 为单位传输,支持按类型读取,且数据持久化在内核中,是更灵活的 IPC 方案。
1.1 定义与核心特征
System V 消息队列是内核中的一个消息容器,允许进程发送 / 接收 “类型 + 数据” 的结构化消息,核心特征:
- 消息类型化:每个消息有唯一的整数类型,接收方可按需读取指定类型(而非仅 FIFO 顺序);
- 内核持久化:队列和消息存在于内核中,即使所有使用进程退出,也不会消失(需显式删除);
- 结构化传输:消息由 “类型字段 + 自定义数据” 组成,适合复杂数据通信;
- 全双工通信:单个队列可传输不同类型的消息,实现双向通信(无需像 FIFO 那样创建两个管道);
- 原子操作:单个消息的发送 / 接收是原子的,不会被拆分或打断。
1.2 与命名管道(FIFO)的核心区别
特性 System V 消息队列 命名管道(FIFO) 数据单位 带类型的结构化消息 无结构的流式字节数据 读取方式 可按类型读取(精准 / 优先级) 仅按 FIFO 顺序读取 数据持久化 内核持久化(直到显式删除) 仅在缓冲区(读走即消失) 生命周期 随内核(需手动删除) 随文件系统(需手动 rm) 通信模式 全双工(单队列双向) 半双工(需两个管道) 数据边界 内置消息边界(自动拆分) 无边界(需自定义协议)
2.1 内核核心数据结构
内核为每个消息队列维护两套关键结构:
struct msqid_ds:队列元数据(类似文件的 inode),包含:
- 队列权限(UID/GID/ 访问权限);
- 队列状态(创建时间、最后读写时间);
- 队列容量限制(最大字节数、最大消息数);
- 指向消息链表的指针、引用计数。
struct msg:单个消息结构,包含:
- 消息类型(
mtype,长整型,≥1);- 消息数据长度(
mlen);- 数据指针、下一个消息的指针(构成链表)。
2.2 键值(key)与标识符(msqid)
- 键值(
key_t):全局唯一整数,是进程间 “找到” 同一个队列的凭证(通常通过ftok()生成);- 标识符(
msqid):内核分配的本地唯一整数(类似文件描述符),是进程操作队列的句柄。2.3 数据传输流程
- 发送进程:构造 “类型 + 数据” 的消息,通过
msgsnd()将数据拷贝到内核队列缓冲区;- 内核:将消息按类型插入链表,更新队列元数据;
- 接收进程:通过
msgrcv()指定类型,内核取出对应消息并拷贝到用户空间。
核心操作函数
所有操作需包含以下头文件:
#include <sys/types.h> #include <sys/ipc.h> #include <sys/msg.h>3.1 ftok () - 生成唯一键值(辅助函数)
用于生成全局唯一的
key_t,避免手动指定键值冲突。key_t ftok(const char *pathname, int proj_id);
- 参数:
pathname:存在且可访问的文件路径(如./msg_file);proj_id:1-255 的非零整数(项目标识,不同值生成不同 key)。- 返回值:成功返回
key_t;失败返回 - 1(需确保文件存在)。3.2 msgget () - 创建 / 获取队列
int msgget(key_t key, int msgflg);
- 核心作用:创建新队列,或获取已存在队列的标识符。
- 参数:
key:ftok()生成的键值,或IPC_PRIVATE(创建私有队列,仅亲缘进程可用);msgflg:组合标志(权限位 + 控制位):
- 权限位:如
0666(所有用户可读可写);- 控制位:
IPC_CREAT(不存在则创建)、IPC_EXCL(与IPC_CREAT组合,已存在则失败)。- 返回值:成功返回
msqid(≥0);失败返回 - 1(常见错误:EEXIST(队列已存在)、EACCES(权限不足))。3.3 msgsnd () - 发送消息
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
- 核心作用:将消息发送到指定队列。
- 参数:
msqid:msgget()返回的队列标识符;msgp:指向自定义消息结构体的指针(必须以long mtype开头):struct msg_buf { long mtype; // 消息类型(≥1) char mtext[1024]; // 自定义数据(可替换为任意结构体) };msgsz:消息数据部分长度(不包含mtype);msgflg:0(阻塞)、IPC_NOWAIT(非阻塞,队列满时返回EAGAIN)。- 返回值:成功返回 0;失败返回 - 1(常见错误:
EINVAL(mtype<1)、EAGAIN(队列满))。3.4 msgrcv () - 接收消息
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
- 核心作用:从队列读取指定类型的消息。
- 关键参数:
msgtyp:指定读取规则:
msgtyp=0:读取队列第一个消息(FIFO);msgtyp>0:读取第一个类型为msgtyp的消息;msgtyp<0:读取类型≤|msgtyp | 的最小类型消息(优先级);msgflg:0(阻塞)、IPC_NOWAIT(非阻塞,无消息返回ENOMSG)、MSG_NOERROR(数据过长时截断不报错)。- 返回值:成功返回读取的字节数;失败返回 - 1。
3.5 msgctl () - 控制 / 删除队列
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
- 核心作用:查询状态、修改权限、删除队列(最常用)。
- 参数:
cmd:操作命令:
IPC_STAT:读取队列元数据到buf;IPC_SET:修改队列权限;IPC_RMID:删除队列(最常用,buf可设为 NULL)。- 返回值:成功返回 0;失败返回 - 1(删除失败会导致资源泄漏)。
实战代码示例
4.1 发送端(msg_sender.c)
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <sys/ipc.h> #include <sys/msg.h> // 自定义消息结构(必须以long mtype开头) struct msg_buf { long mtype; char mtext[1024]; }; #define MSG_PATH "./msg_file" // ftok所需文件(必须存在) #define PROJ_ID 123 // 项目标识 #define MSG_TYPE_1 1 // 普通消息类型 #define MSG_TYPE_2 2 // 紧急消息类型 int main() { // 1. 生成唯一key key_t key = ftok(MSG_PATH, PROJ_ID); if (key == -1) { perror("ftok"); exit(1); } // 2. 创建/获取队列(权限0666) int msqid = msgget(key, IPC_CREAT | 0666); if (msqid == -1) { perror("msgget"); exit(1); } // 3. 发送普通消息(类型1) struct msg_buf msg; msg.mtype = MSG_TYPE_1; strcpy(msg.mtext, "普通消息:Hello System V Msg Queue!"); if (msgsnd(msqid, &msg, strlen(msg.mtext)+1, 0) == -1) { perror("msgsnd type1"); msgctl(msqid, IPC_RMID, NULL); // 失败时删除队列 exit(1); } // 4. 发送紧急消息(类型2) msg.mtype = MSG_TYPE_2; strcpy(msg.mtext, "紧急消息:System Alert!"); if (msgsnd(msqid, &msg, strlen(msg.mtext)+1, 0) == -1) { perror("msgsnd type2"); msgctl(msqid, IPC_RMID, NULL); exit(1); } printf("消息发送完成,队列保留在内核中\n"); return 0; }4.2 接收端(msg_receiver.c)
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <sys/ipc.h> #include <sys/msg.h> struct msg_buf { long mtype; char mtext[1024]; }; #define MSG_PATH "./msg_file" #define PROJ_ID 123 int main() { // 1. 生成相同key(与发送端一致) key_t key = ftok(MSG_PATH, PROJ_ID); if (key == -1) { perror("ftok"); exit(1); } // 2. 获取已存在的队列 int msqid = msgget(key, 0666); if (msqid == -1) { perror("msgget"); exit(1); } // 3. 优先读取紧急消息(类型2) struct msg_buf msg; memset(&msg, 0, sizeof(msg)); ssize_t len = msgrcv(msqid, &msg, sizeof(msg.mtext), 2, 0); if (len == -1) { perror("msgrcv type2"); exit(1); } printf("接收紧急消息:%s\n", msg.mtext); // 4. 读取普通消息(类型1) memset(&msg, 0, sizeof(msg)); len = msgrcv(msqid, &msg, sizeof(msg.mtext), 1, 0); if (len == -1) { perror("msgrcv type1"); exit(1); } printf("接收普通消息:%s\n", msg.mtext); // 5. 删除队列(释放内核资源) if (msgctl(msqid, IPC_RMID, NULL) == -1) { perror("msgctl IPC_RMID"); exit(1); } printf("队列已删除\n"); return 0; }4.3 编译与运行
# 1. 创建ftok所需文件 touch msg_file # 2. 编译 gcc msg_sender.c -o sender gcc msg_receiver.c -o receiver # 3. 先运行发送端(创建队列并发送消息) ./sender # 4. 再运行接收端(读取并删除队列) ./receiver # 备用:手动查看/删除队列 ipcs -q # 查看所有消息队列 ipcrm -q <msqid> # 手动删除队列
5.1 队列容量限制
内核默认限制(可通过
/proc/sys/kernel/msg*调整):
msgmax:单个消息最大字节数(默认 8192);msgmnb:单个队列最大总字节数(默认 16384);- 调整方式:
echo 16384 > /proc/sys/kernel/msgmax(临时生效)。5.2 资源泄漏问题
- 若未调用
msgctl(IPC_RMID),队列会永久占用内核资源;- 解决:注册信号处理函数(如
SIGINT),进程退出前删除队列。5.3 权限问题
- 队列权限通过
msgget()的msgflg设置(如0666);- 无权限时会返回
EACCES,需确保进程 UID/GID 匹配。
总结
- System V 消息队列是内核维护的带类型结构化消息链表,支持按类型灵活读取,适合结构化 / 优先级数据通信;
- 核心操作依赖
msgget()(创建 / 获取)、msgsnd()(发送)、msgrcv()(接收)、msgctl()(删除)4 个函数,ftok()用于生成唯一键值;- 队列具有内核持久化特性,使用后必须通过
msgctl(IPC_RMID)删除,否则会导致资源泄漏;- 相比命名管道,消息队列支持全双工、结构化数据和优先级读取,但实现稍复杂,容量受内核限制。
3. System V 信号量(Semaphore)
System V 信号量并非 “单个信号量”,而是内核维护的信号量集(Semaphore Set) —— 一组计数型信号量的集合,核心作用是解决多个进程 / 线程访问共享资源时的竞态条件,实现进程间的同步(有序执行)和互斥(独占资源)。与消息队列(数据传输)、共享内存(数据共享)不同,信号量本身不传输任何数据,仅作为 “资源锁” 或 “执行信号” 使用。
核心概念与本质
1.1 基础定义
- 信号量:一个整数变量(
semval),仅能通过原子操作修改,核心操作是:
- P 操作(Wait / 申请资源):信号量值减 1(
semval -= 1),若减后≤0,进程阻塞,直到值 > 0;- V 操作(Post / 释放资源):信号量值加 1(
semval += 1),唤醒阻塞的等待进程。- 信号量集:System V 信号量以 “集合” 为单位管理,一个集合可包含 1~ 多个信号量(例如:用 1 个信号量控制打印机,另 1 个控制磁盘 IO),适合多资源同步场景。
- 临界区:需要互斥访问的共享资源代码段(如打印、写文件、操作共享内存),信号量的核心作用是保证临界区 “同一时刻只有一个进程执行”。
1.2 核心特征
特性 说明 信号量集 以集合为单位创建 / 操作,支持多资源同步 内核持久化 存在于内核中,进程退出后不消失,需显式删除 原子操作 P/V 操作由内核保证原子性,避免多进程同时修改信号量值 阻塞机制 信号量值不足时,进程自动阻塞,无需手动轮询 撤销机制(SEM_UNDO) 进程异常退出时,内核自动撤销其对信号量的操作,避免死锁 1.3 同步 vs 互斥(核心应用场景)
- 互斥:用 1 个信号量(初始值 = 1)实现 “独占资源”,例如:多个进程打印时,只有拿到信号量的进程能输出(二进制信号量 / 互斥锁);
- 同步:用 1 个或多个信号量(初始值 = 0)实现 “进程有序执行”,例如:进程 A 完成数据写入后,通过 V 操作唤醒进程 B 读取数据。
- System V 信号量是内核维护的信号量集,核心用于进程间的同步(有序执行)和互斥(独占资源),本身不传输数据;
- 核心操作流程:
ftok()生成键值 →semget()创建 / 获取集 →semctl()初始化值 →semop()执行 P/V →semctl(IPC_RMID)删除集;- 关键要点:初始化只做一次、
SEM_UNDO避免死锁、用完必须删除集(防止内核资源泄漏);- 相比 POSIX 信号量,System V 信号量更适合传统多资源同步场景,但接口较繁琐,现代开发可优先选择 POSIX 信号量。
底层实现原理
内核核心数据结构
内核为每个信号量集维护两套关键结构:
struct semid_ds(信号量集元数据):
- 权限信息(UID/GID、访问权限);
- 状态信息(创建时间、最后操作时间);
- 信号量数量(
sem_nsems);- 引用计数(使用该集合的进程数)。
struct sem(单个信号量结构):
semval:信号量当前值(核心);sempid:最后执行 P/V 操作的进程 ID;semncnt:等待信号量值增加的进程数(等待 V 操作);semzcnt:等待信号量值变为 0 的进程数。键值(key)与标识符(semid)
- 键值(
key_t):全局唯一整数,通过ftok()生成,是进程间 “找到同一个信号量集” 的凭证;- 标识符(
semid):内核分配的本地唯一整数(类似文件描述符),是进程操作信号量集的句柄。原子操作原理
semop()(P/V 操作)的原子性由内核通过自旋锁 / 互斥锁保证:
- 进程调用
semop()时,内核先加锁,禁止其他进程修改信号量;- 执行指定的 P/V 操作(修改
semval);- 若操作后需要阻塞,将进程加入等待队列,释放锁;
- 若操作后需要唤醒进程,从等待队列取出进程并唤醒,释放锁。
核心操作函数
所有操作需包含以下头文件:
#include <sys/types.h> #include <sys/ipc.h> #include <sys/sem.h>1 ftok () - 生成唯一键值(辅助函数)
与消息队列完全一致,用于生成全局唯一的
key_t,避免手动指定键值冲突。key_t ftok(const char *pathname, int proj_id);参数:
pathname(存在的文件路径)、proj_id(1-255 的非零整数);返回值:成功返回
key_t,失败返回 - 1。2 semget () - 创建 / 获取信号量集
int semget(key_t key, int nsems, int semflg);核心作用:创建新的信号量集,或获取已存在的信号量集标识符。
关键参数:
key:ftok()生成的键值,或IPC_PRIVATE(创建私有集,仅亲缘进程可用);
nsems:信号量集中的信号量数量(创建时必须指定≥1,获取时可设 0);
semflg:组合标志:
- 权限位:如
0666(所有用户可读可写);- 控制位:
IPC_CREAT(不存在则创建)、IPC_EXCL(与IPC_CREAT组合,已存在则失败)。返回值:成功返回
semid(≥0),失败返回 - 1(常见错误:EEXIST(集已存在)、EACCES(权限不足))。3 semctl () - 控制信号量集(初始化 / 删除 / 查值)
int semctl(int semid, int semnum, int cmd, .../* union semun arg */);核心作用:初始化信号量值、获取信号量值、删除信号量集(最核心的控制函数)
关键说明:
union semun(必须手动定义,系统不默认提供):// 手动定义semun联合体(System V标准要求) union semun { int val; // SETVAL:设置单个信号量的初始值 struct semid_ds *buf; // IPC_STAT/IPC_SET:获取/修改集元数据 unsigned short *array; // SETALL/GETALL:设置/获取所有信号量的值 struct seminfo *__buf; // IPC_INFO:获取系统级信息(少用) };- 核心
cmd参数:
cmd 作用 配套 arg SETVAL设置单个信号量的初始值 arg.val = 初始值GETVAL获取单个信号量的当前值 无需 arg(返回值为 semval) SETALL设置所有信号量的初始值 arg.array = 数组GETALL获取所有信号量的当前值 arg.array = 数组IPC_RMID删除整个信号量集(最常用) arg 设为 NULL 返回值:
SETVAL/SETALL/IPC_RMID:成功返回 0,失败返回 - 1;GETVAL:成功返回信号量当前值,失败返回 - 1。3.4 semop () - 执行 P/V 操作(核心)
int semop(int semid, struct sembuf *sops, size_t nsops);核心作用:执行原子的 P/V 操作(修改信号量值,实现同步 / 互斥)。
关键参数:
struct sembuf(操作结构体):struct sembuf { unsigned short sem_num; // 信号量编号(从0开始,对应集中的第N个信号量) short sem_op; // 操作类型:-1(P)、+1(V)、0(等待值为0) short sem_flg; // 标志:0(阻塞)、IPC_NOWAIT(非阻塞)、SEM_UNDO(进程退出撤销操作) };sops:操作数组(可一次执行多个 P/V 操作,原子性);nsops:操作数组的长度(通常为 1)。返回值:成功返回 0,失败返回 - 1(常见错误:
EAGAIN(非阻塞时操作失败)、EINTR(被信号中断))。核心操作示例:
P 操作(申请资源):
sem_op = -1,sem_flg = SEM_UNDO;V 操作(释放资源):
sem_op = +1,sem_flg = SEM_UNDO。
实战代码示例
场景说明: 两个进程(进程 1、进程 2)竞争访问 “标准输出”(临界区),用 1 个 System V 信号量(初始值 = 1)实现互斥,保证同一时刻只有一个进程打印内容。
4.1 公共头文件(sem_common.h)
#ifndef SEM_COMMON_H #define SEM_COMMON_H #include <sys/types.h> #include <sys/ipc.h> #include <sys/sem.h> #include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <string.h> // 手动定义semun联合体 union semun { int val; struct semid_ds *buf; unsigned short *array; struct seminfo *__buf; }; // 常量定义 #define SEM_PATH "./sem_file" // ftok所需文件(必须存在) #define PROJ_ID 123 // 项目标识 #define SEM_NUM 0 // 信号量集中的第0个信号量(仅1个) // 封装P操作(申请资源) int sem_p(int semid) { struct sembuf sop; sop.sem_num = SEM_NUM; sop.sem_op = -1; // P操作:减1 sop.sem_flg = SEM_UNDO; // 进程退出时撤销操作,避免死锁 return semop(semid, &sop, 1); } // 封装V操作(释放资源) int sem_v(int semid) { struct sembuf sop; sop.sem_num = SEM_NUM; sop.sem_op = +1; // V操作:加1 sop.sem_flg = SEM_UNDO; return semop(semid, &sop, 1); } // 创建/初始化信号量集 int sem_create_and_init(int init_val) { // 1. 生成key key_t key = ftok(SEM_PATH, PROJ_ID); if (key == -1) { perror("ftok"); exit(1); } // 2. 创建信号量集(1个信号量) int semid = semget(key, 1, IPC_CREAT | IPC_EXCL | 0666); if (semid == -1) { // 若已存在,直接获取 semid = semget(key, 0, 0666); if (semid == -1) { perror("semget"); exit(1); } return semid; } // 3. 初始化信号量值 union semun arg; arg.val = init_val; if (semctl(semid, SEM_NUM, SETVAL, arg) == -1) { perror("semctl SETVAL"); semctl(semid, 0, IPC_RMID); // 失败时删除集 exit(1); } return semid; } #endif // SEM_COMMON_H4.2 进程 1(sem_process1.c)
#include "sem_common.h" int main() { // 1. 创建/获取信号量集(初始值=1,互斥锁) int semid = sem_create_and_init(1); printf("进程1(PID:%d)启动\n", getpid()); // 2. P操作:申请临界区(独占输出) if (sem_p(semid) == -1) { perror("sem_p"); exit(1); } printf("进程1:进入临界区,开始打印...\n"); sleep(2); // 模拟临界区操作(打印耗时) printf("进程1:退出临界区\n"); // 3. V操作:释放临界区 if (sem_v(semid) == -1) { perror("sem_v"); exit(1); } sleep(1); // 等待进程2执行 // 4. 最后执行的进程删除信号量集 if (semctl(semid, 0, IPC_RMID, NULL) == -1) { perror("semctl IPC_RMID"); exit(1); } printf("进程1:信号量集已删除\n"); return 0; }4.3 进程 2(sem_process2.c)
#include "sem_common.h" int main() { // 1. 获取已存在的信号量集 int semid = sem_create_and_init(1); // 复用初始化函数(已存在则直接获取) printf("进程2(PID:%d)启动\n", getpid()); // 2. P操作:申请临界区(会阻塞,直到进程1释放) if (sem_p(semid) == -1) { perror("sem_p"); exit(1); } printf("进程2:进入临界区,开始打印...\n"); sleep(2); // 模拟临界区操作 printf("进程2:退出临界区\n"); // 3. V操作:释放临界区 if (sem_v(semid) == -1) { perror("sem_v"); exit(1); } printf("进程2:执行完成\n"); return 0; }4.4 编译与运行
# 1. 创建ftok所需文件 touch sem_file # 2. 编译 gcc sem_process1.c -o process1 gcc sem_process2.c -o process2 # 3. 同时运行两个进程(模拟竞争) ./process1 & ./process2 # 输出示例(进程2会阻塞到进程1释放信号量): # 进程1(PID:1234)启动 # 进程1:进入临界区,开始打印... # 进程2(PID:1235)启动 # 进程1:退出临界区 # 进程2:进入临界区,开始打印... # 进程2:退出临界区 # 进程2:执行完成 # 进程1:信号量集已删除 # 备用:手动查看/删除信号量集 ipcs -s # 查看所有System V信号量集 ipcrm -s <semid> # 手动删除指定信号量集
关键注意事项
1 初始化只做一次
多个进程中,仅第一个进程执行
semctl(SETVAL)初始化信号量值,重复初始化会覆盖已有值,导致同步逻辑错乱(示例中通过IPC_EXCL避免重复创建)。2 避免死锁
- SEM_UNDO 标志:
semop()的sem_flg设为SEM_UNDO,进程异常退出时,内核会自动撤销其 P/V 操作(例如:进程执行 P 操作后崩溃,内核会将信号量值加 1,避免其他进程永久阻塞);- 信号处理:注册
SIGINT/SIGTERM信号处理函数,进程退出前执行 V 操作并删除信号量集。3 资源泄漏
- System V 信号量集是内核资源,进程退出后不会自动销毁,未调用
semctl(IPC_RMID)会导致资源永久占用;- 解决:确保至少有一个进程执行
IPC_RMID,或通过ipcrm -s <semid>手动删除。4 非阻塞模式
semop()的sem_flg设为IPC_NOWAIT时,若 P 操作无法执行(信号量值≤0),会立即返回 - 1 且errno=EAGAIN,需在代码中处理重试逻辑。5 权限问题
信号量集的权限通过
semget()的semflg设置(如0666),若进程 UID/GID 不匹配,会返回EACCES错误,需确保权限正确。
System V 信号量 vs POSIX 信号量
特性 System V 信号量 POSIX 信号量(无名 / 有名) 管理单位 信号量集(多个信号量) 单个信号量 持久化 内核持久化(需显式删除) 无名:进程 / 线程内;有名:文件系统 操作复杂度 较高(需手动定义 semun) 较低(接口更简洁) 适用场景 进程间同步(传统场景) 线程 / 进程同步(现代场景) 原子操作 支持多操作原子执行 仅支持单操作原子执行
三、POSIX IPC(现代、易用)
POSIX IPC 是对 System V IPC 的改进,接口更贴近文件操作(如用
open/close管理),支持跨平台,核心包括:
- POSIX 共享内存:用
shm_open()创建 / 打开共享内存文件,mmap()映射到进程空间(替代 System V 的shmget());- POSIX 消息队列:用
mq_open()/mq_send()/mq_receive(),支持消息优先级;- POSIX 信号量:分为命名信号量(跨进程)和无名信号量(线程 / 父子进程),接口更简单。
示例:POSIX 共享内存(更易用)
#include <stdio.h> #include <fcntl.h> #include <sys/mman.h> #include <unistd.h> #define SHM_NAME "/my_posix_shm" #define SHM_SIZE 1024 int main() { // 1. 创建/打开POSIX共享内存 int fd = shm_open(SHM_NAME, O_CREAT | O_RDWR, 0666); ftruncate(fd, SHM_SIZE); // 设置大小 // 2. 映射到进程空间 char *shm_addr = mmap(NULL, SHM_SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); // 3. 读写数据 strcpy(shm_addr, "Hello POSIX Shared Memory!"); printf("写入:%s\n", shm_addr); // 4. 清理 munmap(shm_addr, SHM_SIZE); close(fd); shm_unlink(SHM_NAME); return 0; }
四、套接字(Socket)
核心原理
- 最初为网络通信设计,也支持本地进程通信(AF_UNIX 域套接字),全双工,支持 TCP(可靠、面向连接)/UDP(无连接);
- 本地 AF_UNIX 套接字比网络套接字(AF_INET)快,无需经过网络协议栈。
示例(AF_UNIX 域套接字:服务端 + 客户端)
服务端(unix_server.c):
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/socket.h> #include <sys/un.h> #define SOCK_PATH "./unix_sock" int main() { int sockfd, connfd; struct sockaddr_un addr; char buf[1024]; // 1. 创建套接字(AF_UNIX=本地域,SOCK_STREAM=TCP-like) sockfd = socket(AF_UNIX, SOCK_STREAM, 0); if (sockfd == -1) { perror("socket"); exit(1); } // 2. 绑定地址 addr.sun_family = AF_UNIX; strcpy(addr.sun_path, SOCK_PATH); unlink(SOCK_PATH); // 先删除旧套接字文件 if (bind(sockfd, (struct sockaddr *)&addr, sizeof(addr)) == -1) { perror("bind"); exit(1); } // 3. 监听 listen(sockfd, 5); // 4. 接受连接 connfd = accept(sockfd, NULL, NULL); if (connfd == -1) { perror("accept"); exit(1); } // 5. 读数据 ssize_t n = read(connfd, buf, sizeof(buf)); printf("服务端收到:%s\n", buf); // 6. 清理 close(connfd); close(sockfd); unlink(SOCK_PATH); return 0; }
客户端(unix_client.c):
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/socket.h> #include <sys/un.h> #define SOCK_PATH "./unix_sock" int main() { int sockfd; struct sockaddr_un addr; // 1. 创建套接字 sockfd = socket(AF_UNIX, SOCK_STREAM, 0); if (sockfd == -1) { perror("socket"); exit(1); } // 2. 连接服务端 addr.sun_family = AF_UNIX; strcpy(addr.sun_path, SOCK_PATH); if (connect(sockfd, (struct sockaddr *)&addr, sizeof(addr)) == -1) { perror("connect"); exit(1); } // 3. 写数据 const char *msg = "Hello Unix Domain Socket!"; write(sockfd, msg, strlen(msg) + 1); // 4. 清理 close(sockfd); return 0; }优缺点 & 适用场景
- ✅ 优点:全双工、支持跨网络 / 本地、可靠(TCP);
- ❌ 缺点:接口稍复杂、本地通信比共享内存慢;
- 📌 适用:跨机器通信、本地复杂的双向通信(如进程间的 RPC)。
五、各 IPC 机制对比 & 选型建议
机制 通信范围 性能 核心特点 适用场景 匿名管道 父子 / 兄弟进程 中等 简单、半双工、字节流 父子进程简单单向通信 FIFO 任意本地进程 中等 有名字、半双工、字节流 本地无亲缘进程简单通信 信号 任意本地进程 极高 异步、仅传事件 进程间异步通知(终止、刷新) System V 共享内存 任意本地进程 极致 无拷贝、大数据、需同步 高吞吐大数据交换 System V 消息队列 任意本地进程 中等 异步、按类型收发、有消息边界 按优先级 / 类型收发消息 Socket(AF_UNIX) 任意本地进程 中高 全双工、可靠、接口复杂 本地复杂双向通信 Socket(AF_INET) 跨网络进程 中等 全双工、跨网络 跨机器通信(如客户端 - 服务端) 选型核心原则
- 简单优先:父子进程用管道,无亲缘用 FIFO;
- 性能优先:大数据用共享内存(配合信号量同步);
- 异步通知:用信号;
- 跨网络 / 复杂通信:用 Socket;
- 按类型收发消息:用消息队列。

















 2716
2716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









