




 本文介绍了如何在Elasticsearch中使用query关键字的match子关键字进行查询,特别是在处理中文内容时。通过引入IK分词器,包括ik_smart简易分词和ik_max_word尽最大可能分词,来实现对中文的分词处理,从而提高查询效率和准确性。文章详细阐述了分词器的安装和使用,并展示了在实际操作中插入和查询中文数据的过程。
本文介绍了如何在Elasticsearch中使用query关键字的match子关键字进行查询,特别是在处理中文内容时。通过引入IK分词器,包括ik_smart简易分词和ik_max_word尽最大可能分词,来实现对中文的分词处理,从而提高查询效率和准确性。文章详细阐述了分词器的安装和使用,并展示了在实际操作中插入和查询中文数据的过程。
1、先了解一下es的语法语句关键字

2、最常用的,query关键字查询,query下还有match子关键字(匹配的意思)

GET movie_index/movie/_search
{
"query": {
"match": {
"name": "red"
}
}
}
查询name字段带有red的,查到总共2条结果!
3、上面插入和查询的都是英文,那么要让es识别我们的中文,怎么办?
就是要让他做到分词处理,比如:红海行动,要让他分成:红海、行动才行的。
这里可以让他先分析一下:

es不能识别中文,它不知道这是什么意思,这里直接分析词,是很失败的分词。
4、故要加入一个中文分词器,创建索引,方便匹配,提高查询效率!
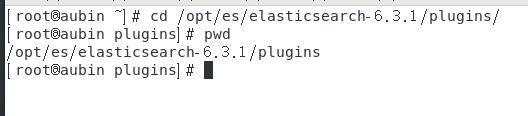
es启动的时候,会扫描这个插件目录/opt/es/elasticsearch-6.3.1/plugins。
注意:这个目录下的一个子目录为一个独立的插件。而且只扫描一层子目录!不能把插件的文件分散解压!
因为这里打包的rar文件,linux系统没有这个命令解压,所以在widow上直接解压出来,直接上传到这个文件夹使用即可了。
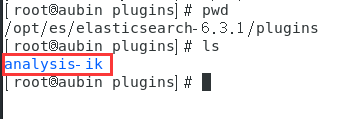
这个ik是一个中英文分词器,有两种:
(1)ik_smart 简易分词,在电商项目中,一般对商品的规格描述(数据比较大)进行分词,使搜索规格描述的词也能显示出来。
(2)ik_max_word 尽最大可能分词,在电商项目中,对商品标题(比较短的一句标题)的分词
5、cd到bin目录运行命令./elasticsearch重启es
再在kibana输入命令:
GET _analyze
{
"analyzer": "ik_smart",
"text": "红海行动"
}
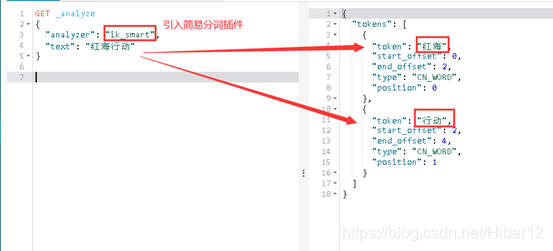
这是“红海行动”,不是很明显的分词效果,
6、换成“我是中国人”
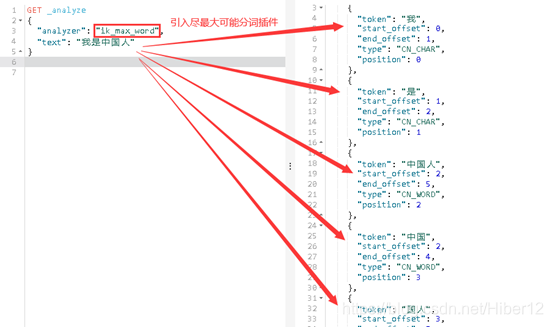
引入尽最大可能分词插件:
GET _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
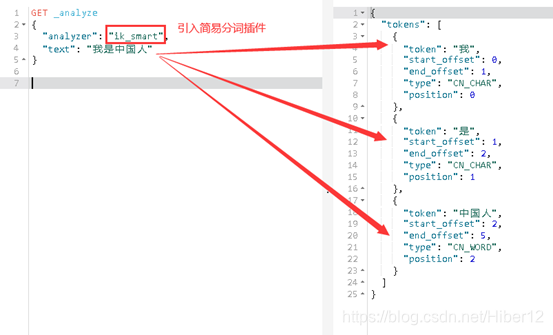
引入简易分词插件:
GET _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}

7、测试,插入三条中文的数据:
PUT /movie_chn/movie/1
{ "id":1,
"name":"红海行动",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"张译"},
{"id":2,"name":"海清"},
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn/movie/2
{
"id":2,
"name":"湄公河行动",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"张涵予"}
]
}
PUT /movie_chn/movie/3
{
"id":3,
"name":"红海事件",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"张晨"}
]
}
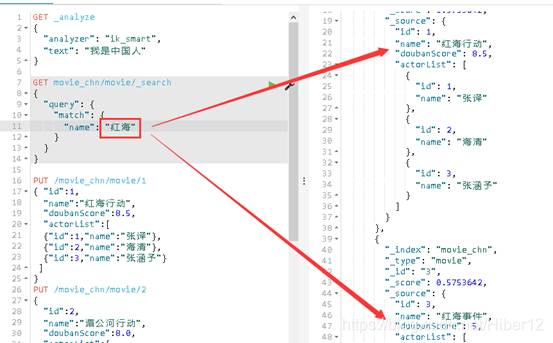
查询name字段为红海的结果:
GET movie_chn/movie/_search
{
"query": {
"match": {
"name": "红海"
}
}
}
返回关于name字符为“红海”的两条结果,测试成功!

















 5256
5256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









