




 本文介绍了Elasticsearch中对数据的操作,包括使用PUT进行添加和更新,DELETE进行删除,POST用于修改,以及GET用于查询。每个索引(index)仅能包含一个类型(type),数据以JSON字符串形式存储,强调快速查询效率。示例展示了如何插入和删除数据,并提到了在大数据场景下,通过分片提高查询速度的概念。
本文介绍了Elasticsearch中对数据的操作,包括使用PUT进行添加和更新,DELETE进行删除,POST用于修改,以及GET用于查询。每个索引(index)仅能包含一个类型(type),数据以JSON字符串形式存储,强调快速查询效率。示例展示了如何插入和删除数据,并提到了在大数据场景下,通过分片提高查询速度的概念。
1、增PUT 删DELETE 改POST 查GET:

2、插入数据:
格式 PUT /index/type/id
index相当于库,type相当于表,id相当于主键
PUT /movie_index/movie/1
{ "id":1,
"name":"operation red sea",
"doubanScore":8.5,
"actorList":[
{"id":1,"name":"zhang yi"},
{"id":2,"name":"hai qing"},
{"id":3,"name":"zhang han yu"}
]
}
PUT /movie_index/movie/2
{
"id":2,
"name":"operation meigong river",
"doubanScore":8.0,
"actorList":[
{"id":3,"name":"zhang han yu"}
]
}
PUT /movie_index/movie/3
{
"id":3,
"name":"incident red sea",
"doubanScore":5.0,
"actorList":[
{"id":4,"name":"zhang chen"}
]
}
3、一个库只能建立一张type表:
存储在这里的全部都是json字符串,都是文本内容,没有复杂的数据结构,没有表与表,库与表等这些复杂的关系。这些存储的数据都只是文本内容,查询这些数据的时候,都是文本内容的匹配,以高效率查询为主,查询效率才是es最关注的东西。插入成功:
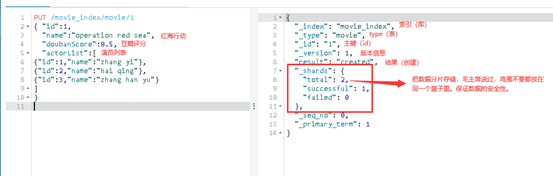
继续把上边剩余两条数据插入
4、把id为1和3的数据删除之后:
查询库里的所有数据:get movie_index/_search
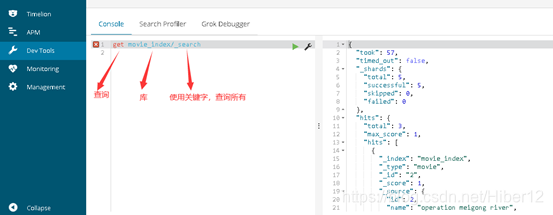
"took": 57,头57,代表总数据量,占用的空间数,57kb
"timed_out": false,是否过期,这里没有过期
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
分片,分成5片了。
这里扯一下大数据领域,例如1吨的水果(有橘子,苹果,西红柿,胡萝卜,西红柿等),现在叫你把里面的苹果分离出来。直接从一吨分出来比较慢。
可以采取分片,把1吨分成1000份(map操作),每份就是1千克。
再从每份水果当中分离苹果,这样是不是比较快,分离之后再合并在一起(reduce操作),最后得到你要的结果,1吨里分出来的苹果。
"hits": {
"total": 3, 命中3条total数据
"max_score": 1, 最大评分max_score为1(100%)
"hits": [ 命中集合
{
"_index": "movie_index", 索引
"_type": "movie", type表
"_id": "2", id注解
"_score": 1, 相关性算分100%(因为还没加查询条件,查的是全部,所以100%)
"_source": { 结果
"id": 2,
"name": "operation meigong river",
"doubanScore": 8,
"actorList": [
{
"id": 3,
"name": "zhang han yu"
}
]
}
}
]

















 2261
2261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









