






前言
随着多模态大语言模型逐渐走进大众的视野,比如像通义千问和DeepSeek这样的项目,已经在HuggingFace和ModelScope这些平台上开源了它们的模型权重,这让更多的开发者和爱好者能够轻松地接触和使用这些前沿技术。
此外,由于部署大语言模型通常需要较高的配置,若运行7B参数的模型,建议预留20G存储空间和20G显存空间,显卡推荐T4以上。但是对于仅仅想练手,例如学生党,来说往往很难拥有这样的硬件要求。因此,这篇文章采用的做法是租服务器。如果自己有本地服务器,也可以按照这篇教程部署。
本文将带着大家一步一步地实现不用框架,只用Python,在服务器上部署属于自己的多模态大语言模型。
租服务器(本地部署可跳过)
小编是在AutoDL平台租服务器,在算力市场按量计费大概2块钱1小时。选择基础镜像PyTorch框架即可。注意需要的配置,建议大于20G的存储空间和20G的显存空间。
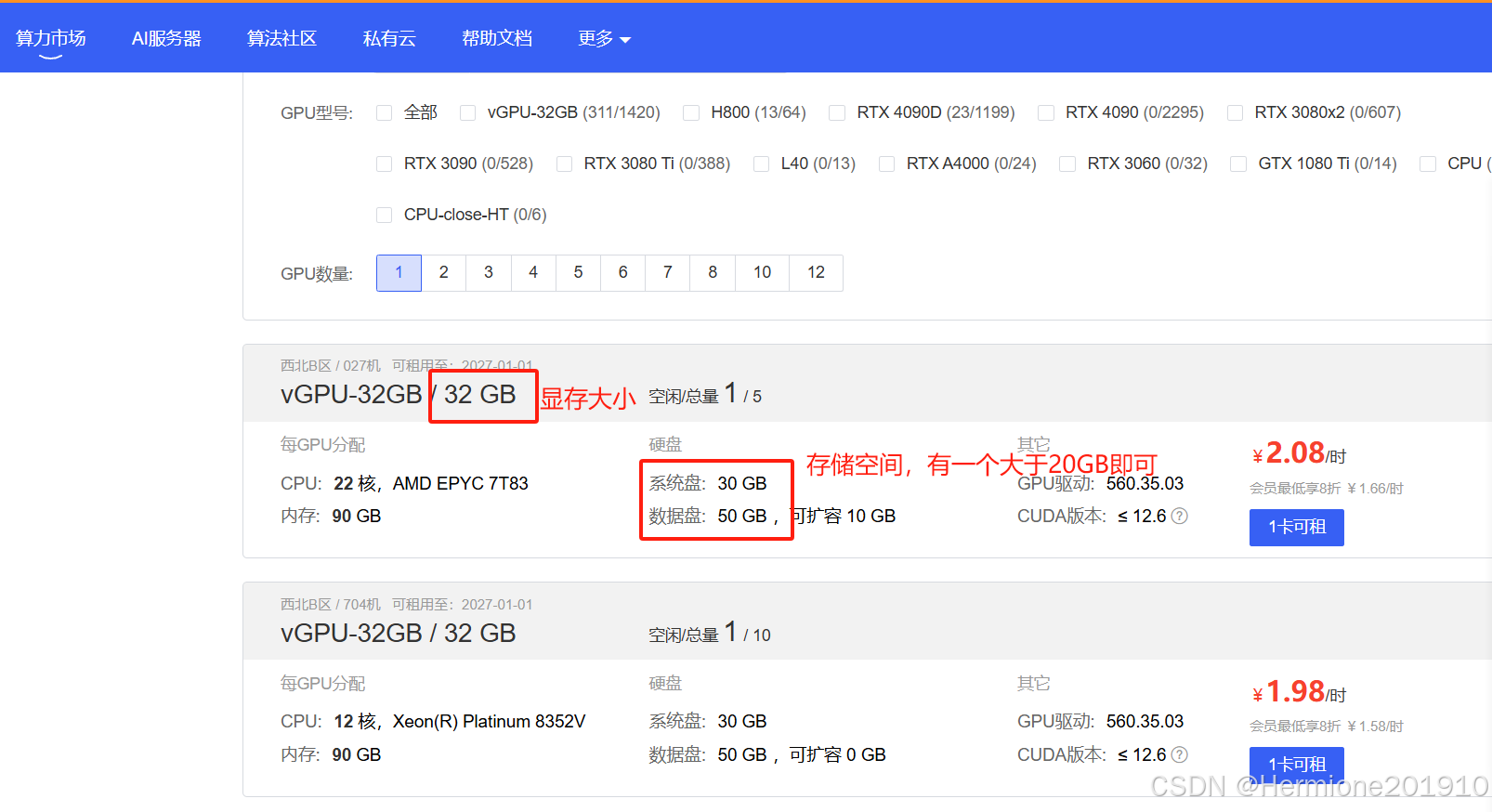
如果有python还没装的小白,可以选择直接使用租用平台的JupyterLab。小编也使用JupyterLab做演示。

另一个选择(可以直接跳过)则是参考以下免费教程,按照Anaconda和VS Code配置环境,利于之后本地跑其他代码。再根据平台的帮助文档(例如AutoDL就是在帮助文档–>最佳实例–>VSCode)中学习如何使用VSCode使用租用的服务器。
Anaconda + VScode配置:https://blog.youkuaiyun.com/Hermione201910/article/details/145981138?spm=1001.2014.3001.5501
环境配置
step 1:创建并激活conda虚拟环境(租服务器可跳过)
对于在本地服务器部署多模态大语言模型时,推荐创造一个新的虚拟环境,your_env是你给虚拟环境取的名字。
conda create -n your_env
部署多模态大模型,均在conda虚拟环境中实现,因此使用的时候记得选择对应的虚拟环境哦。先激活虚拟环境,代码如下:
conda activate your_env
step 2:安装模型依赖包
在租好服务器后,打开JupyterLab,打开终端,如下所示:
输入以下命令,其中 pip install 包名,代表按照这个包,-i 以及后面的网址代表使用镜像。直接复制粘贴即可。
pip install modelscope -i https://mirrors.aliyun.com/pypi/simple/
pip install transformers -i https://mirrors.aliyun.com/pypi/simple/
pip install qwen-vl-utils -i https://mirrors.aliyun.com/pypi/simple/
pip install fastapi -i https://mirrors.aliyun.com/pypi/simple/
pip install accelerate -i https://mirrors.aliyun.com/pypi/simple/
注意,安装flash-attn包时,建议从github(https://github.com/Dao-AILab/flash-attention/releases )或者镜像仓库下载whl包到本地,再进行安装。打开github需要挂梯子,打开后如下图所示,根据自己的cuda版本、torch版本以及python版本下载对应的包。由于租服务器没有办法访问外网,因此需要下载到本地,再上传至服务器。
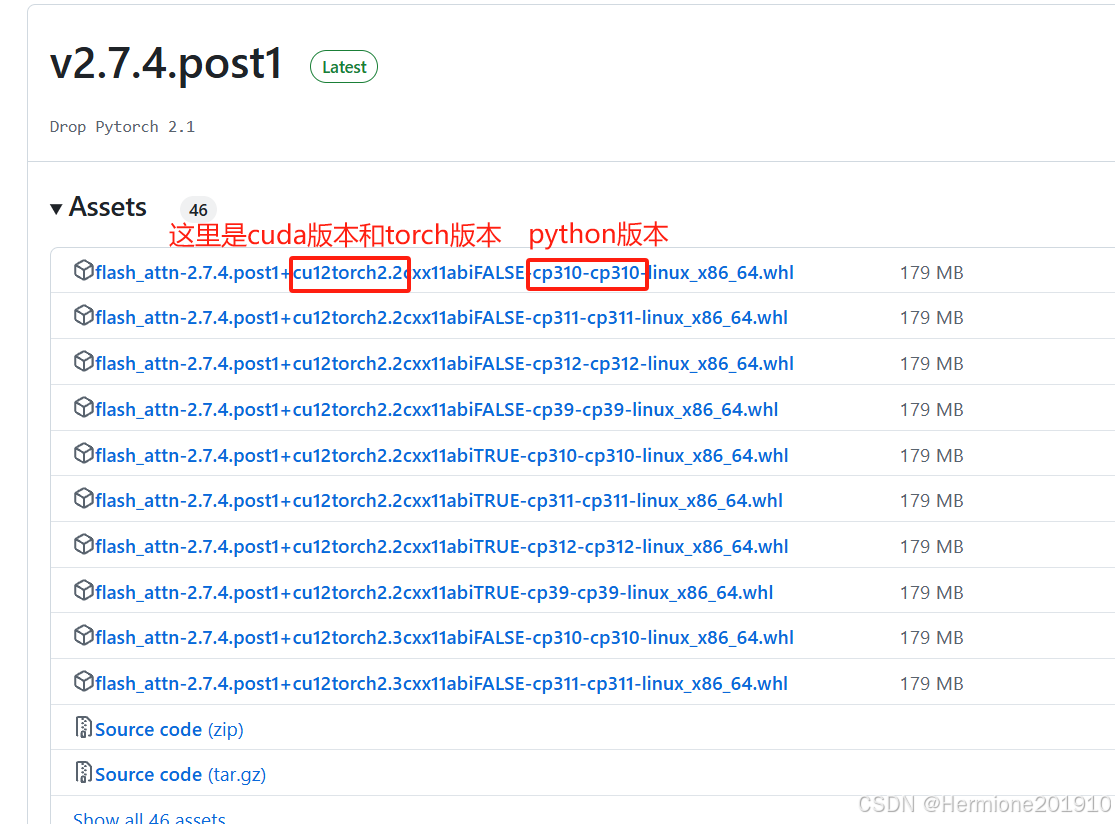
直接将下载好的文件拖入JupyterLab左侧,如图所示:
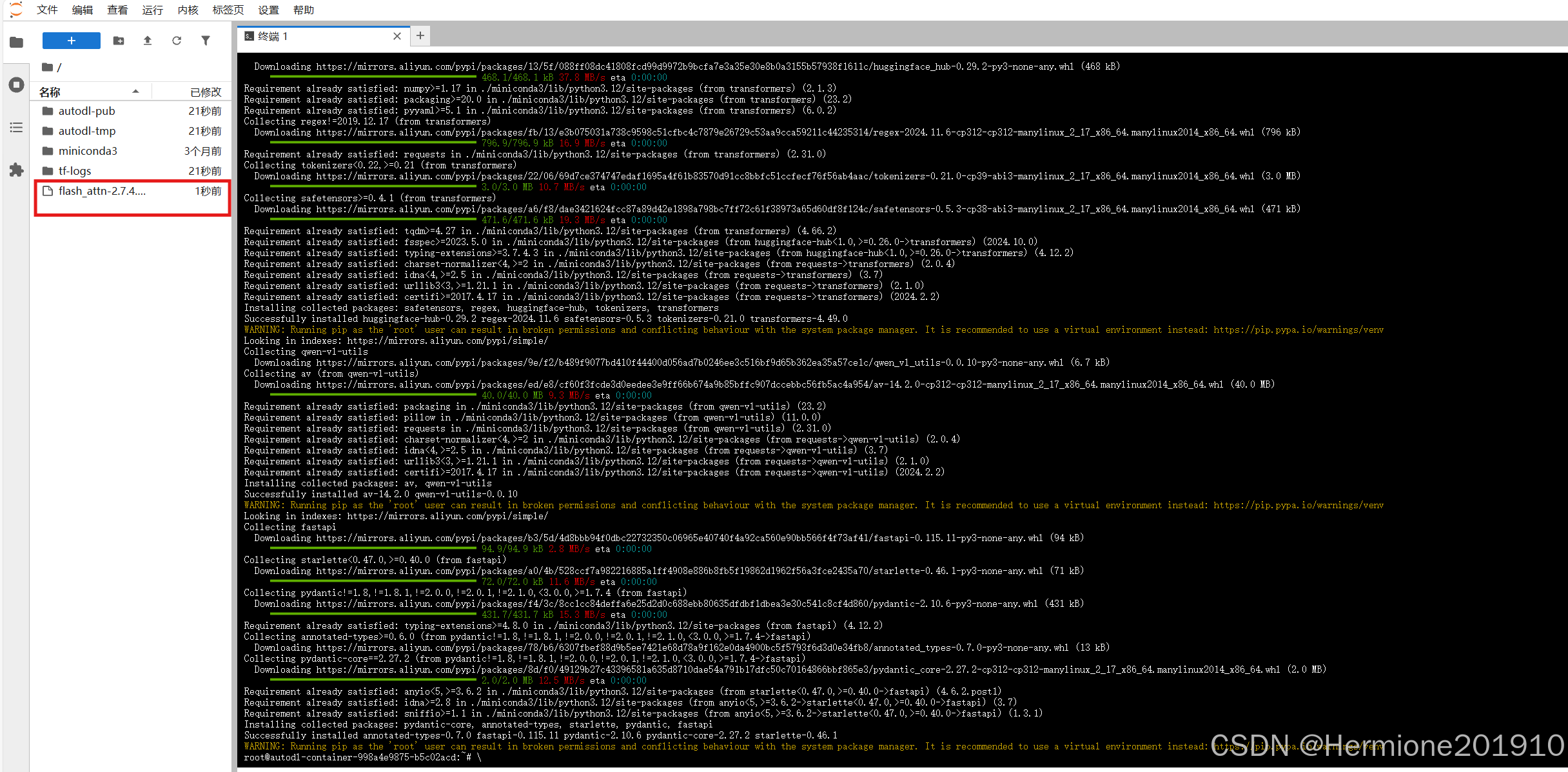
在终端运行以下代码,install后面跟的是下载文件的路径,可以直接单击右键文件选择复制路径。
pip install flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp312-cp312-linux_x86_64.whl
step 3:使用代码下载模型文件至指定位置
创建一个python文件,如下图:
复制以下代码,然后运行(同时直接按下 shift+enter 运行),如图所示:
from modelscope.hub.snapshot_download import snapshot_download
from transformers import AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# 模型ID,以Qwen2-VL-7B-Instruct为例
model_id = 'Qwen/Qwen2-VL-7B-Instruct'
# 目标目录,修改为本地需要下载的地址
target_directory = './model_hub'
# 下载模型
model_dir = snapshot_download(model_id, cache_dir=target_directory)
print(f"模型已下载至: {model_dir}")
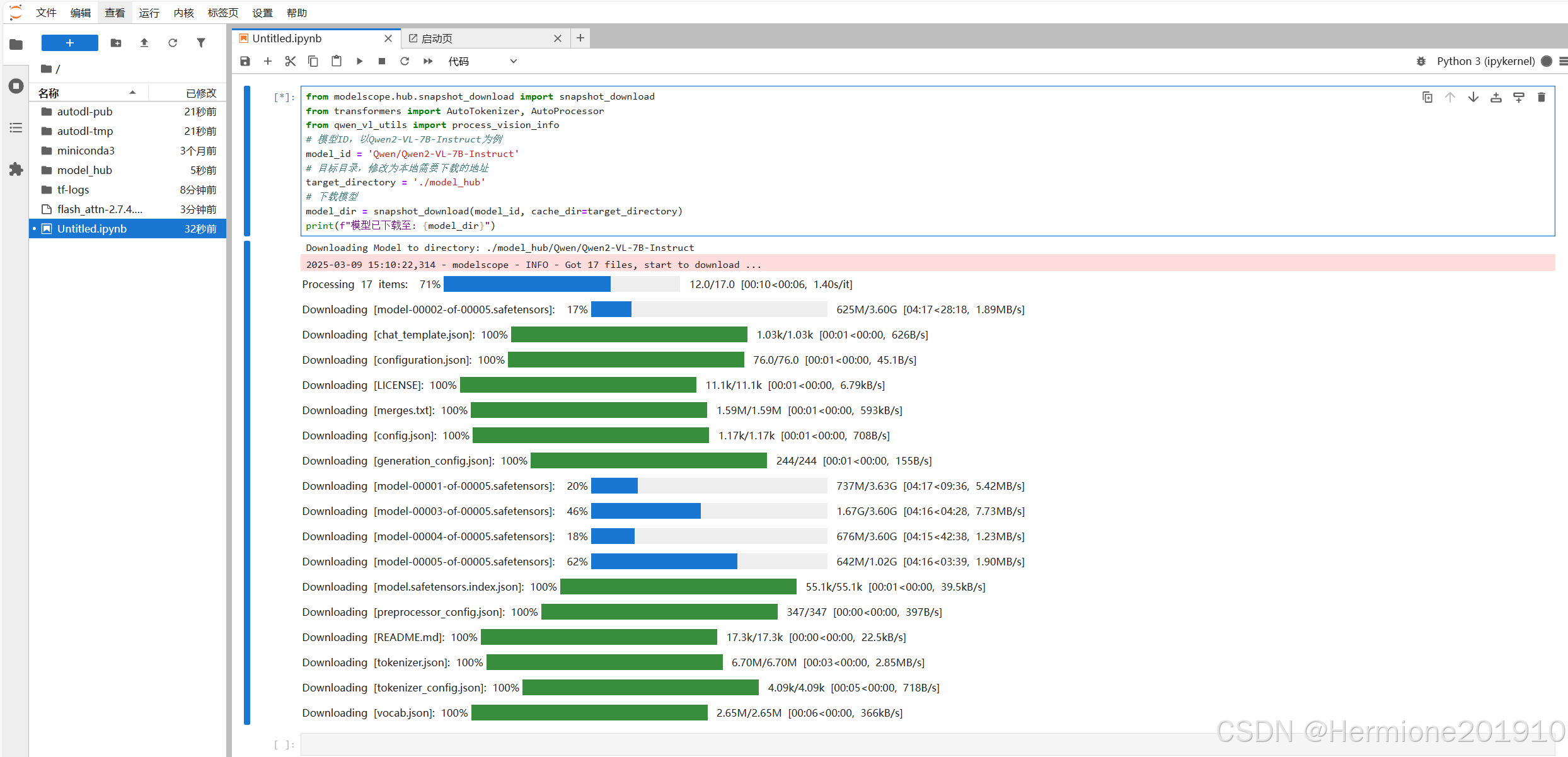
文件较大,请耐心等待~
step 4:测试推理
Qwen/Qwen2-VL-7B-Instruct 模型需要占用20G左右显存,若需多卡推理或部署,请在运行前加上环境变量,代码如下(这一步多卡部署小白也可以跳过,不影响后面的运行)。
CUDA_VISIBLE_DEVICES=0,1 python3 deploy.py
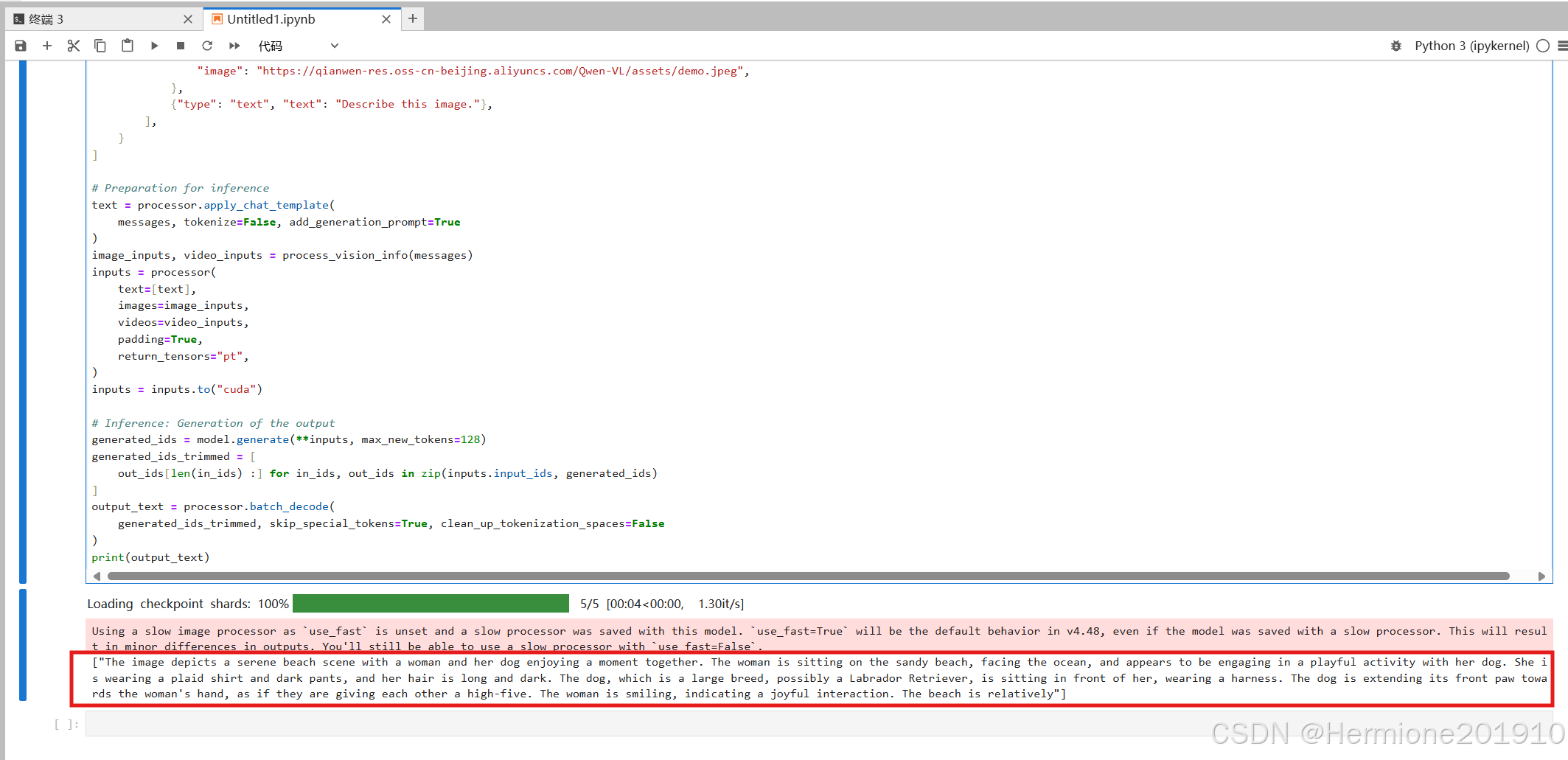
测试一下我们的多模态大语言模型是否可以跑通,下面给出一个多模态任务的例子(根据我们输入的图片和文字,输出文字回答)。
注意:model_dir这个路径是我们在step3中下载Qwen2-VL-7B-Instruct的路径。
注意:如果报错out of memory,则是显存不够。
from modelscope import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
model_dir =("/root/model_hub/Qwen/Qwen2-VL-7B-Instruct")
# default: Load the model on the available device(s)
# model = Qwen2VLForConditionalGeneration.from_pretrained(
# model_dir, torch_dtype="auto", device_map="auto"
# )
# 推荐使用flash_attention_2,可以加速推理
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_dir,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto",
)
# default processer
processor = AutoProcessor.from_pretrained(model_dir)
# The default range for the number of visual tokens per image in the model is 4-16384. You can set min_pixels and max_pixels according to your needs, such as a token count range of 256-1280, to balance speed and memory usage.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2-VL-7B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
# 测试案例
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
]
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
step 5:Python代码部署API(进阶教程)
当把Python代码部署成API后,就像是给你的代码装上了一个小天线,让它能通过网络被其他应用轻松调用。这样做的好处是,不管是谁,只要有权限,就能随时随地使用你的代码功能,而不需要重新造轮子。以下是部署API的代码:
import base64
import requests
import io
from PIL import Image
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor, AutoModel
from qwen_vl_utils import process_vision_info
from modelscope import snapshot_download
import torch
from pydantic import BaseModel
from fastapi import FastAPI, HTTPException, File, UploadFile
from fastapi.responses import JSONResponse
model_dir =("model_hub/Qwen2-VL-7B-Instruct")
app = FastAPI()
##无flash-attention
# default: Load the model on the available device(s)
# model = Qwen2VLForConditionalGeneration.from_pretrained(
# model_dir, torch_dtype="auto", device_map="auto"
# )
# 定义请求体字段要求
class ImageRequest(BaseModel):
image_base64: str #请求图片为base_64编码后的图片
prompt: str
# 定义返回体字段要求
class SceneRecognitionResponse(BaseModel):
result: str
##我们使用flash_attention_2以加速推理过程
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_dir,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map="auto"
)
# 定义接收图像范围
min_pixels = 256*28*28
max_pixels = 2048*2048
processor = AutoProcessor.from_pretrained(model_dir, min_pixels=min_pixels, max_pixels=max_pixels)
@app.post("/Qw2_vl/")
async def recognize_scene(image_request: ImageRequest):
image_base64 = image_request.image_base64
prompt = image_request.prompt
try:
if len(image_base64) > 0:
imgdata = base64.b64decode(image_base64)
# 使用BytesIO创建一个类似文件的对象
image_stream = io.BytesIO(imgdata)
# 尝试打开图像并获取格式
image = Image.open(image_stream)
image_format = image.format # 获取图像格式
image_name = f"./tmp.{image_format.lower()}"
# 保存图像到本地文件
image.save(image_name, image_format)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image_name,
},
{
"type": "text", "text": prompt
}
],
}
]
else:
messages = [
{
'role': 'user',
'content': [
{
'type': 'text',
'text': prompt,
}
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
qwvl2_response = SceneRecognitionResponse(
result=output_text[0], # 如果scene_id为None,它将作为None返回给客户端
)
return qwvl2_response
except requests.exceptions.HTTPError as errh:
raise HTTPException(status_code=500, detail=f"HTTP error occurred: {errh}")
except requests.exceptions.ConnectionError as errc:
raise HTTPException(status_code=500, detail=f"Error Connecting: {errc}")
except requests.exceptions.Timeout as errt:
raise HTTPException(status_code=500, detail=f"Timeout Error: {errt}")
except requests.exceptions.RequestException as err:
raise HTTPException(status_code=500, detail=f"OOps: Something Else {err}")
if __name__ == "__main__":
import uvicorn
#可以修改port值
uvicorn.run(app, host="0.0.0.0", port=5000)
step 6:测试部署情况
#若在服务器中部署,需将localhost替换为服务器IP地址
curl -X POST http://localhost:5000/Qw2_vl -d '{"prompt": "描述图片内容","image_base64": "/9j/4AAQSkZJRgABAQEASABIAAD2wBDAAgGBgcGBQgHBwcJCQgKDBQNDAsLDBkSEw8UHRofHh0aHBwgJC4nICIsIxwcKDcpLDAxNDQ0Hyc5PTgyPC4zNDL/2wBDAQkJCQwLDBgNDRgyIRwhMjIyMjIyMjIy..."}'
如果正确回答,那么恭喜你,可以愉快使用自己部署的多模态大模型的API了!!
注:鉴于HuggingFace需要链接外网,本文部署的模型全部为ModelScope( https://www.modelscope.cn/models?page=1 )上加载,并默认conda虚拟环境、torch包以及CUDA运行正常

















 4093
4093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









