







一、 嵌入模型 Embedding Models
嵌入模型是将复杂数据(如文本、图像、音频等)转换为向量表示的机器学习模型
1. 核心概念
-
嵌入(Embedding):将高维、非结构化的数据映射到低维、稠密的向量空间
-
向量表示:输出固定长度的数值向量(如256维、768维等)
-
语义保留:相似的数据在向量空间中距离相近
2. 嵌入模型案例
将狗向量化,每一个比较标准即是一个向量维度,例如下图是一个二维向量

当比较标准越多,对向量的比较(相似度、区分度)也就越高,例如下图是一个高维向量

3. 常见嵌入模型类型
依此标准,万物皆可向量化,例如文字、图片、音频、视频、多模态数据,均可以有自己的标准实现向量化。

嵌入模型将万物向量化,而向量数据库就用于存储、比较这些向量数据。
4. 向量存储案例



二、 常见的向量类型
| 类型(Type) | 定义(Definition) | 存储格式(Storage Format) | 元素位宽(Element Width) | 特点(Characteristics) | 用途(Use Cases) | 优点(Pros) | 缺点(Cons) |
|---|---|---|---|---|---|---|---|
| Single-precision (单精度浮点向量) | 每个元素为32位单精度浮点数 | 数组形式:[0.12, -1.34, ..., 0.56] | 32-bit (4字节) | 高精度(约7位有效数字),通用性强 | 通用AI模型输出(如BERT, OpenAI embeddings) | 计算精度高,兼容所有距离度量 | 内存占用较大,不适合超大规模数据集 |
| Half-precision (半精度浮点向量) | 每个元素为16位半精度浮点数(IEEE 754标准) | 二进制压缩存储(解码后同单精度) | 16-bit (2字节) | 内存减半,可能存在微小量化误差 | 大规模向量库/内存敏感场景 | 内存效率提升50%,适合GPU计算 | 精度损失(约3-4位有效数字),不适用高精度场景 |
| Binary (二进制向量) | 每个元素为1位二进制值(0或1) | 位数组:[1,0,1,...0] 或 0b101...0(位压缩) | 1-bit (1位) | 极端空间优化,仅支持特定距离度量 | 哈希指纹(如SimHash), 二值化特征 | 极致压缩(比float小32倍),计算速度快 | 仅适用离散场景,表达能力有限 |
| Sparse (稀疏向量) | 仅存储非零值及其位置(适用于大多数元素为0的高维向量) | 键值对:{index1:value1, index2:value2,...} | 非零值:32-bit | 高效存储稀疏结构,距离计算自动忽略零值 | NLP的TF-IDF, 用户行为特征 | 内存效率极高(当稀疏度>95%),支持常规距离计算 | 随机访问性能较低,需要特殊存储格式 |
三、 向量的比较算法
1. 相关概念
- KNN搜索
如果我们要求精确返回最相似的 top k个值,专业术语叫做 k-最近邻搜索 (k-Nearest Neighbors Search, k-NN Search),然而,对于高维向量而言,这不现实也没必要。
- ANN搜索
使用近似算法牺牲少量精度换取显著性能提升,是实际向量数据库中最常用的实现方式,专业术语叫做 近似最近邻搜索(Approximate Nearest Neighbors, ANN)。
- 召回率
用来衡量ANN搜索准确度的算法。以下图为例,假如要求返回10个最近似向量,其中8个是准确的,召回率则是80%。

2. 与普通数据库的差异
与普通数据库的“精确”匹配不同,向量比的是“相似性”。
例如我想搜索“广州”
- 普通数据库查询写法只能是 ='广州' 或者 like '%广州%'
- 向量搜索 输入可以是 “早茶”、“白云山”、“羊城”,返回结果依然有广州
3. 暴力搜索(平坦搜索)
即逐一比较,这是唯一能真正做到精确比较方法。

4. 聚类搜索 IVFFlat
IVFFlat 即 Inverted File with Flat Compression 是向量数据库中常用的 ANN算法,由Facebook的FAISS团队提出,专门用于高效处理大规模向量相似性搜索。

其核心是将向量分为不同的聚类,找到各个聚类的中心点。这样,只需将向量与各中心点比较,即可大致找到与待查询向量最近的聚类,然后在聚类中搜索,大幅缩小查询范围(个人感觉类似分区)。
5. 图搜索 NSW与HNSW
社交关系中有所谓“6人理论”之说,两个素不相识的人最多通过六个人就能认识(实际平均值大概是3~4)。如果我们把每个向量看做端点,将相邻端点一一连线,实际上这就是一个图,而向量搜索的过程,就是找到这个图近似最短边的过程。
① NSW(Navigable Small World,可导航小世界)算法
-
核心思想:构建一个具有“可导航性”的图,即从任意点出发,通过贪婪算法(每次走向离目标更近的邻居)快速找到近邻。
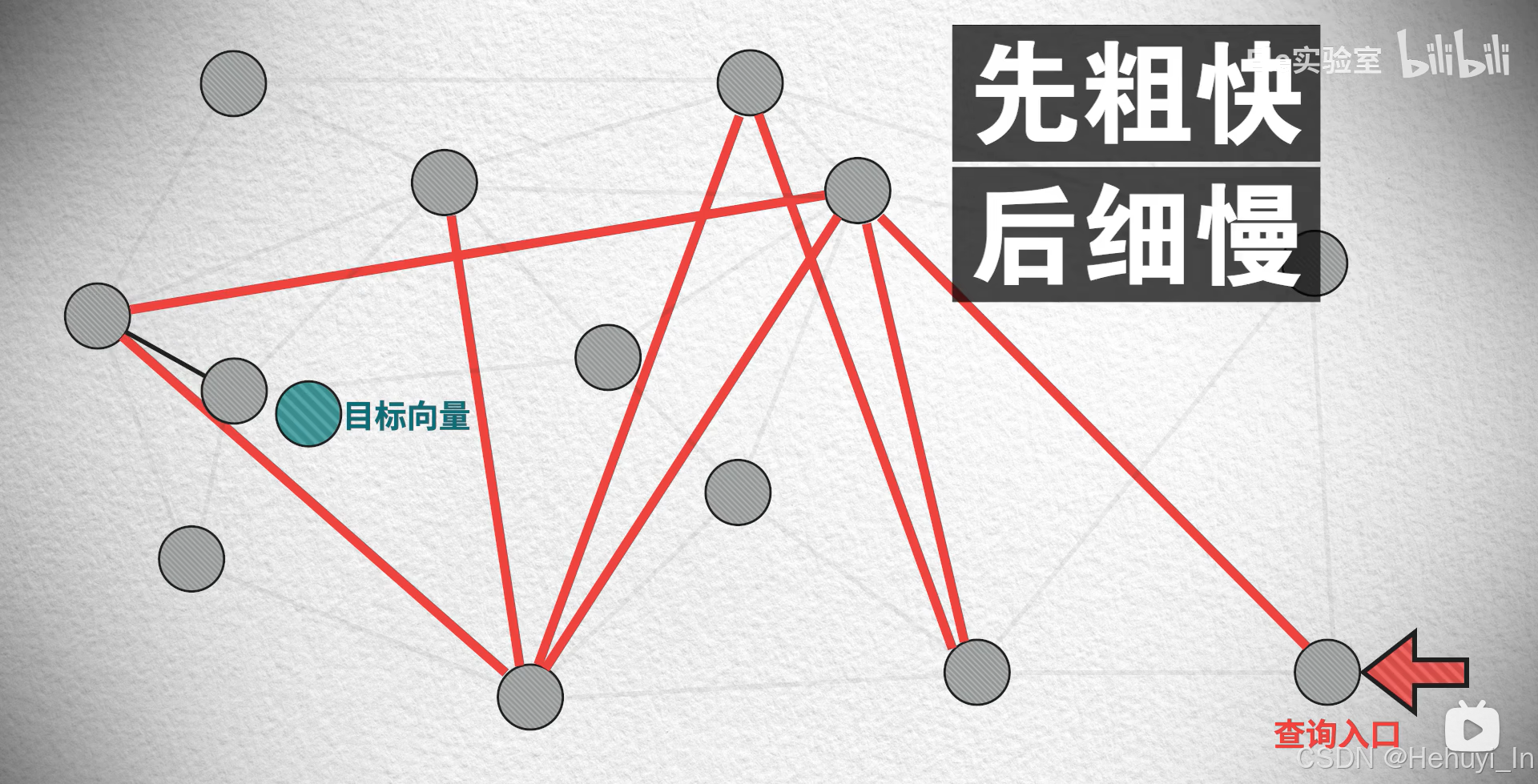
-
关键步骤:
-
随机插入:按顺序插入向量,每个新节点随机连接至已有的少量最近邻(通过贪婪搜索临时找到)。
-
长边与短边共存:随机性保留了一些“长距离边”(类似六度分隔理论),避免局部陷阱,加速远距离导航。
-
-
缺点:搜索路径可能迂回,性能依赖初始构造顺序。
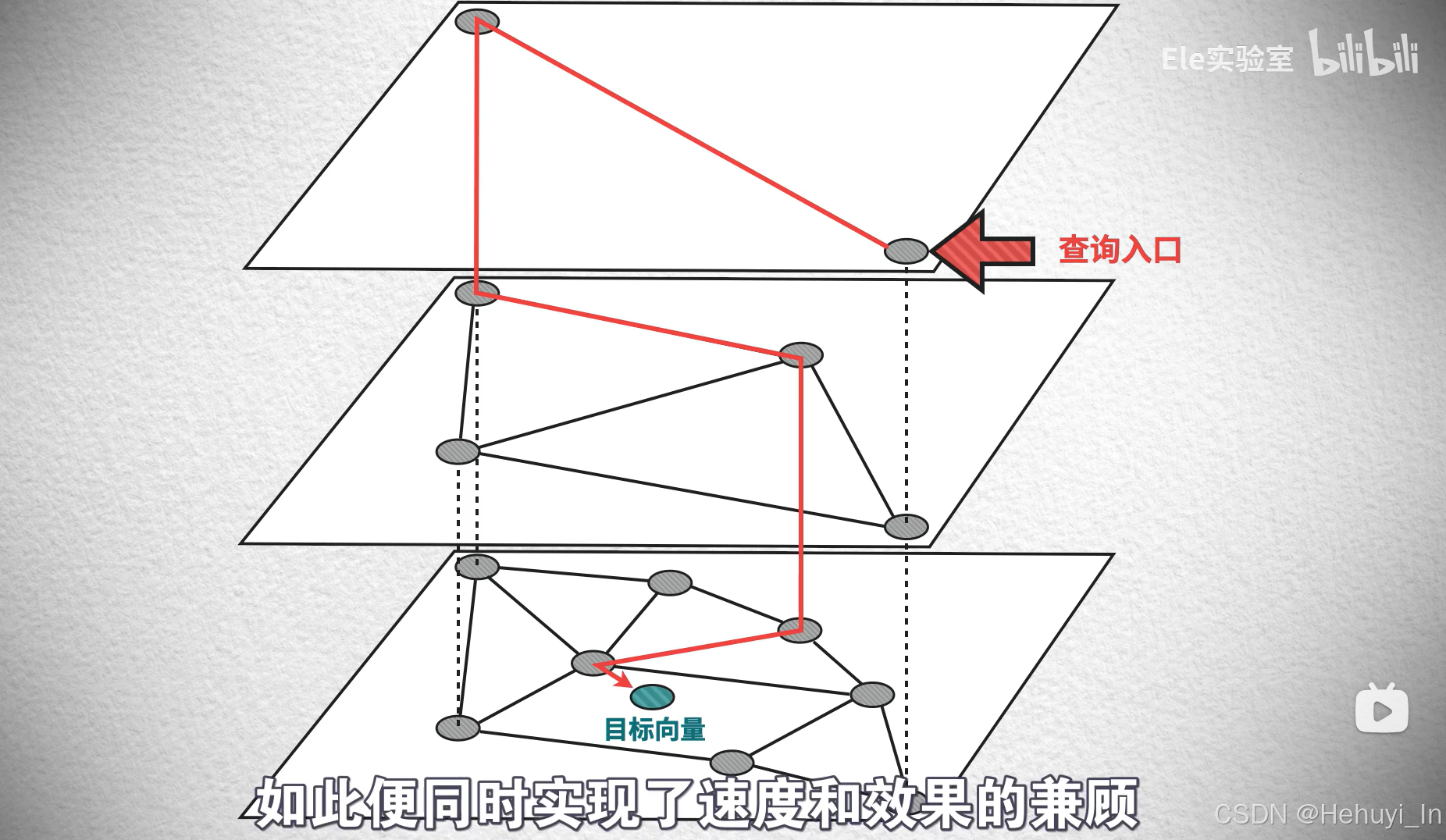
② HNSW(Hierarchical NSW,分层的可导航小世界)算法
-
在NSW基础上引入分层结构(类似跳表SkipList的多层设计)。
-
其原理同样是“先粗快,后细慢”,高层为稀疏“高速公路”,底层为密集连接,将搜索复杂度优化至 O(log N),过程更稳定可控
四、 向量距离度量
上面我们知道有哪些算法可以快速找到两个相似的向量,可是实际如何比较两个向量是否相似?答案是计算向量距离度量,度量方法同样有很多,以下是较为常用的:
| 距离度量 | 定义与示例 | 使用场景 | 优点 | 缺点 |
|---|---|---|---|---|
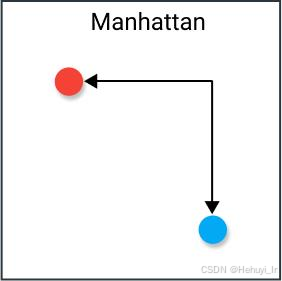
| L1 Distance (曼哈顿距离) | 绝对值之和
| - 图像差异分析 - 异常检测 | - 对异常值鲁棒 - 计算简单 | - 几何意义不如L2直观 - 高维时区分度下降 |
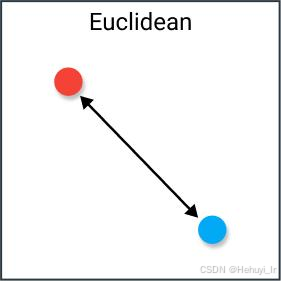
| L2 Distance (欧氏距离) | 向量间的直线距离
| - 图像特征匹配 - 通用嵌入向量相似性 | - 直观易理解 - 对均匀缩放不敏感 | - 对异常值敏感 - 高维时计算成本较高 |
| Inner Product (内积) | 向量点积
| - 推荐系统(用户-物品偏好) - 正交性检测 | - 计算高效(SIMD优化) - 直接反映方向相似性 | - 受向量模长影响 - 需归一化后才有可比性 |
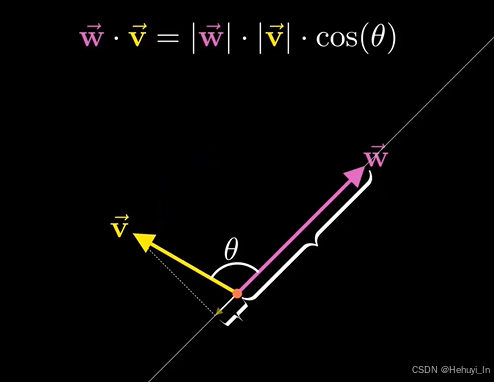
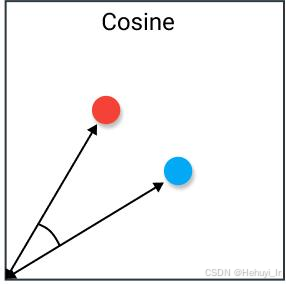
| Cosine Distance (余弦距离) | 1 - 余弦相似度
| - 文本相似度(TF-IDF/词向量) - 人脸识别 | - 忽略向量模长,专注方向 - 适合高维稀疏数据 | - 对零向量无效 - 归一化计算开销 |
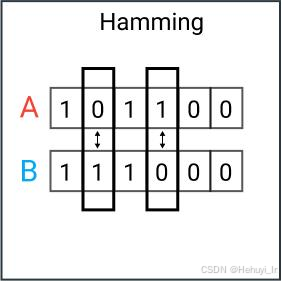
| Hamming Distance (汉明距离) | 二进制向量不同位的数量
| - 哈希指纹比对 - 错误检测(CRC校验) | - 位运算极快 - 适合硬件加速 | - 仅适用于二进制数据 - 信息损失严重 |
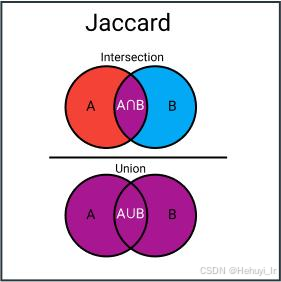
| Jaccard Distance (杰卡德距离) | 1 - Jaccard相似系数
| - 集合相似度(用户兴趣标签) - 文档去重 | - 适合稀疏布尔数据 - 忽略重复元素影响 | - 需数据预处理为集合 - 计算复杂度高(需求交集) |
还找到些其他距离算法,可以参考 数据科学中常见的9种距离度量方法,内含欧氏距离、切比雪夫距离等
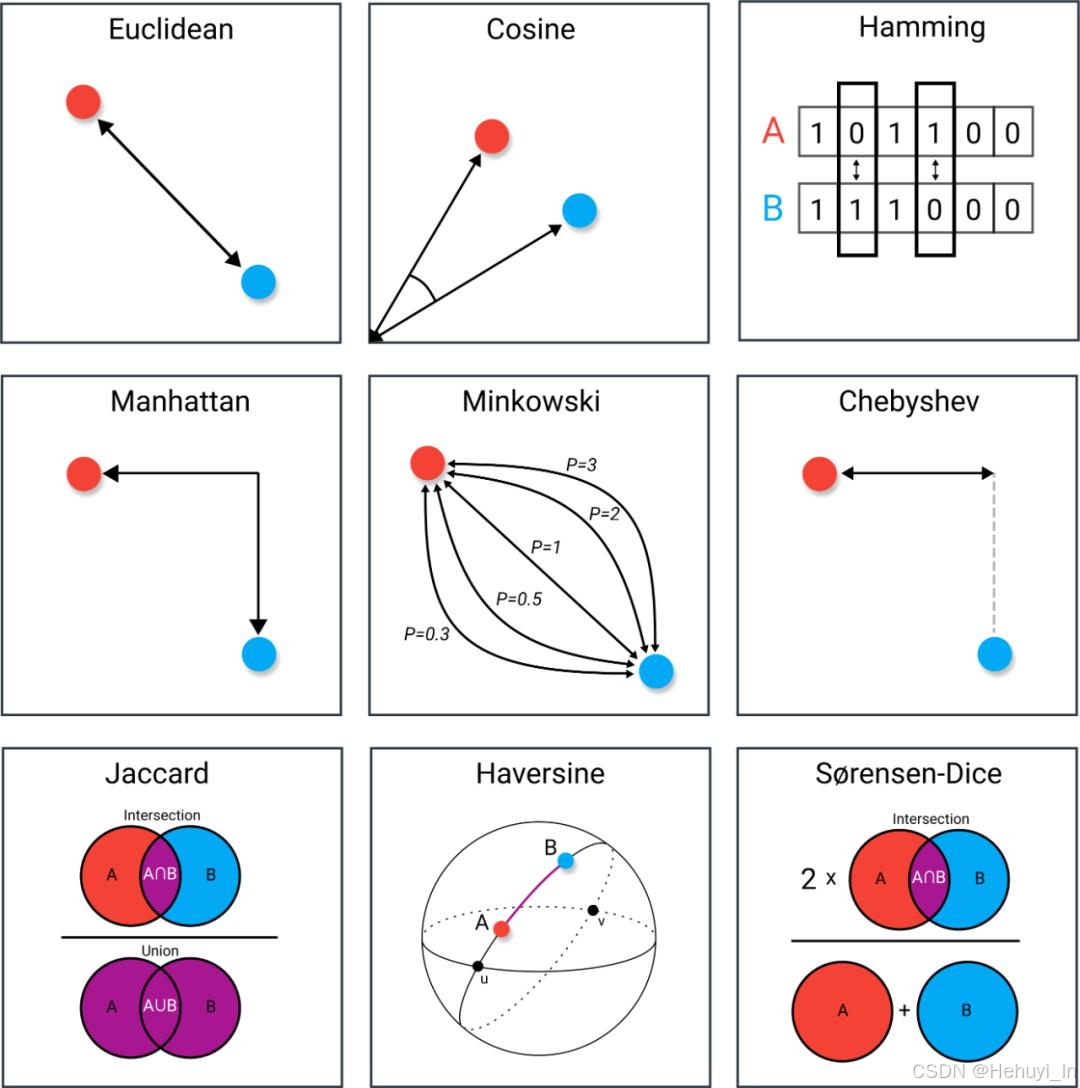
五、 主流向量数据库对比
| 数据库名称 | 开发/运营公司 | 类型 | 特点 | 优点 | 缺点 | 流行度 |
|---|---|---|---|---|---|---|
| Milvus | Zilliz (中国/美国) | 原生向量数据库 | - 专为向量搜索优化 - 支持分布式、多索引(HNSW/IVF) - 开源+商业版 | - 社区生态丰富(如Towhee集成) - 云服务(Zilliz Cloud)可用 | - 依赖外部组件(etcd等) - 运维成本较高 | ⭐⭐⭐⭐⭐ |
| Pinecone | Pinecone Systems (美国) | 原生向量数据库(云服务) | - 全托管服务 - 自动优化索引和规模 | - 企业级SLA保障 - 无缝扩展 | - 闭源 - 费用较高($0.1/百万向量/月起) | ⭐⭐⭐⭐(企业级) |
| Weaviate | SeMI Technologies (荷兰) | 原生向量数据库 | - 多模态+混合搜索 - 内置ML模型(如CLIP) | - 开源(Apache 2.0) - 支持数据对象管理 | - 内存消耗大 - 商业版功能限制 | ⭐⭐⭐ |
| Qdrant | Qdrant (德国) | 原生向量数据库 | - Rust编写,高性能 - 云服务(Qdrant Cloud) | - 轻量级(适合边缘计算) - 强过滤条件支持 | - 社区资源较少 | ⭐⭐⭐ |
| Chroma | Chroma (美国) | 轻量级向量数据库 | - 专注AI开发者(如LangChain集成) | - 极简API设计 - 本地开发友好 | - 无成熟集群方案 | ⭐⭐(早期阶段) |
| Redis with RedisSearch | Redis Ltd. (美国) | 扩展插件(传统DB+向量) | - 基于Redis模块 - 低延迟 | - 复用Redis生态(如缓存+向量) - 企业支持完善 | - 向量功能非核心 | ⭐⭐⭐⭐ |
| PostgreSQL + pgvector | 开源社区 (Andrew Kane主导) | 扩展插件 | - PostgreSQL扩展 - 支持SQL操作向量 | - 无缝兼容现有PG业务 - 低成本迁移 | - 性能瓶颈(>1亿向量) | ⭐⭐⭐⭐(开发者) |
| Elasticsearch + 向量插件 | Elastic NV (美国) | 扩展插件 | - 结合全文检索与向量 - 企业级工具链(Kibana等) | - 适合日志+向量混合场景 - 成熟分布式架构 | - 配置复杂 - 资源占用极高 | ⭐⭐⭐(企业场景) |
参考
部分内容来自AI回答
https://github.com/pgvector/pgvector?tab=readme-ov-file#hnsw


















 428
428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











