






数据格式
Excel表格,xlsx格式
代码如下
library(overlap)
library(readxl)
library(activity)
data <- read_excel("data2.xlsx")
View(data)
#将时间转化为小数时间
# 加载lubridate包
library(lubridate)
# 假设你的数据框名为data,时间列的名字为time
# 使用hms()函数来转换时间列
data$Time <- hms(format(data$Time, "%T"))
# 提取时间列中的小时、分钟和秒
hours <- hour(data$Time)
minutes <- minute(data$Time)
seconds <- second(data$Time)
# 将时间转换为小时的小数部分
data$decimal_time <- hours + minutes / 60 + seconds / 3600
# 将时间转换为0-1之间的小数
data$decimal_time <- data$decimal_time / 24
# 查看转换后的数据
View(data)
# 将Period对象转换为秒数
data$Time_seconds <- as.numeric(data$Time, "seconds")
# 然后转换为弧度数据
timeRad <- data$Time_seconds * 2 * pi / (24 * 60 * 60)
#拟合核密度
#我们将提取大熊猫在1区的数据,并绘制一个内核密度曲线
#pan1 <- timeRad[data$Zone == 1 & data$Species == '大熊猫']
#densityPlot(pan1, rug=TRUE)
#图1:使用默认平滑参数拟合区域3中大熊猫的核密度曲线。
#图1显示了从21:00到03:00的活动模式,提醒大家密度是圆形的。
#不同于通常的密度图,使用高斯内核,我们使用一个冯米塞斯内核,对应于圆形分布。
# 更平滑的曲线
#densityPlot(tig2, adjust=2, rug=TRUE)
# 更尖锐的曲线
#densityPlot(tig2, adjust=0.5, rug=TRUE)
#我们将看到如何与data数据集工作。我们将为春季提取大熊猫和家畜的数据,
#计算大熊猫和家畜的重叠,并绘制曲线:
pan1 <- timeRad[data$Season == '春季' & data$Species == '大熊猫']
liv1 <- timeRad[data$Season == '春季' & data$Species == '家畜']
min(length(pan1), length(liv1))
panliv1est <- overlapEst(pan1, liv1, type="Dhat4")
panliv1est
#作重叠图
#cairo_pdf("plot11.pdf")
overlapPlot(pan1, liv1, main="春季")
#添加标签
legend('topright', c("大熊猫", "家畜"), lty=c(1,2), col=c(1,4), bty='n')
#图3:2区大熊猫和人类的活动曲线。重叠系数等于两条曲线下面的面积,在此图中用灰色阴影表示
#小的样本数量小于50时使用Dhat1,大于75时使用Dhat4
#这两个样本都有超过75个观测值,因此我们选择使用R代码中的∆4估计值Dhat4,给出的重叠估计值为0.42。
#下面进行置信区间的检验
panliv1 <- bootstrap(pan1, liv1, 10000, type="Dhat4") # takes a few seconds
#(BSmean <- mean(panliv1))
bootCI(panliv1est, panliv1)
#bootCIlogit(panliv1est, panliv1)
#在这个例子中,bootCI和bootCIlogit函数都返回了五种不同类型的置信区间的上下限,
#分别是"norm"、"norm0"、"basic"、"basic0"和"perc"。
#"norm"和"norm0"是基于正态分布的置信区间,"norm"使用样本均值和标准差,而"norm0"使用0作为中心。
#"basic"和"basic0"是基于样本分布的置信区间,"basic"使用样本均值,而"basic0"使用0作为中心。
#"perc"是基于百分位数的置信区间。
# 计算置信区间
ci <- bootCI(panliv1est, panliv1)
# Assuming ci is the output of bootCI or bootCIlogit。
#ci[]可自行选择,比如ci[1]就是第一行第一列,ci[6]就是第一行第二列
#将CI检验结果添加进结果图
lower_bound = ci[3]
upper_bound = ci[8]
#text(3, 0.08, paste("CI: [", round(lower_bound, 2), ", ", round(upper_bound, 2), "]", sep=""))
#计算物种活动节律差异是否显著
# Fit activity models to your data
fitpan1 <- fitact(pan1)
fitliv1 <- fitact(liv1)
# Compare the fitted models
ppanliv1 <- compareCkern(fitpan1, fitliv1, reps = 1000)
#将重叠值panliv1est和p值加到图里
text(3, 0.08, labels = paste("Δ=", round(panliv1est, 2),", p=", ifelse(ppanliv1["pNull"] < 0.01, sprintf("%.2f", ppanliv1["pNull"]), round(ppanliv1["pNull"], 2)), sep=""))
#dev.off()
####################################################################################################
#夏季
pan2 <- timeRad[data$Season == '夏季' & data$Species == '大熊猫']
liv2 <- timeRad[data$Season == '夏季' & data$Species == '家畜']
min(length(pan2), length(liv2))
panliv2est <- overlapEst(pan2, liv2, type="Dhat4")
panliv2est
#作重叠图
overlapPlot(pan2, liv2, main="夏季")
#添加标签
legend('topright', c("大熊猫", "家畜"), lty=c(1,2), col=c(1,4), bty='n')
#计算物种活动节律差异是否显著
# Fit activity models to your data
fitpan2 <- fitact(pan2)
fitliv2 <- fitact(liv2)
# Compare the fitted models
ppanliv2 <- compareCkern(fitpan2, fitliv2, reps = 1000)
#将重叠值panliv1est和p值加到图里
text(3, 0.10, labels = paste("Δ=", round(panliv2est, 2),", p=", ifelse(ppanliv2["pNull"] < 0.01, sprintf("%.2f", ppanliv2["pNull"]), round(ppanliv2["pNull"], 2)), sep=""))
############################################################################
#秋季
pan3 <- timeRad[data$Season == '秋季' & data$Species == '大熊猫']
liv3 <- timeRad[data$Season == '秋季' & data$Species == '家畜']
min(length(pan3), length(liv3))
panliv3est <- overlapEst(pan3, liv3, type="Dhat4")
panliv3est
#作重叠图
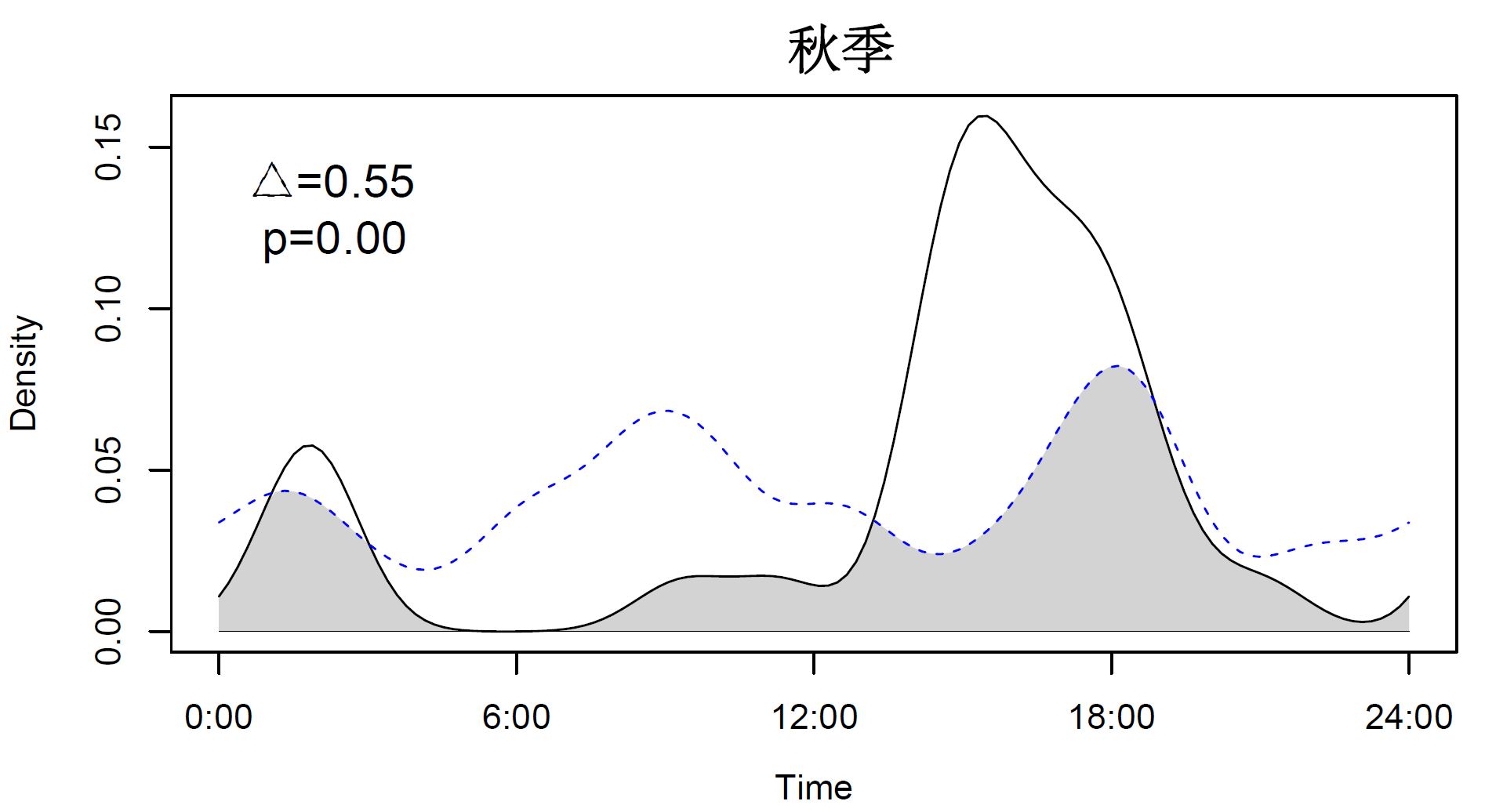
overlapPlot(pan3, liv3, main="秋季")
#添加标签
legend('topright', c("大熊猫", "家畜"), lty=c(1,2), col=c(1,4), bty='n')
#计算物种活动节律差异是否显著
# Fit activity models to your data
fitpan3 <- fitact(pan3)
fitliv3 <- fitact(liv3)
# Compare the fitted models
ppanliv3 <- compareCkern(fitpan3, fitliv3, reps = 1000)
#将重叠值panliv1est和p值加到图里
text(3, 0.14, labels = paste("Δ=", round(panliv3est, 2),", p=", ifelse(ppanliv3["pNull"] < 0.01, sprintf("%.2f", ppanliv3["pNull"]), round(ppanliv3["pNull"], 2)), sep=""))
#################################################################################
#冬季
pan4 <- timeRad[data$Season == '冬季' & data$Species == '大熊猫']
liv4 <- timeRad[data$Season == '冬季' & data$Species == '家畜']
min(length(pan4), length(liv4))
panliv4est <- overlapEst(pan4, liv4, type="Dhat4")
panliv4est
#作重叠图
overlapPlot(pan4, liv4, main="冬季")
#添加标签
legend('topright', c("大熊猫", "家畜"), lty=c(1,2), col=c(1,4), bty='n')
#计算物种活动节律差异是否显著
# Fit activity models to your data
fitpan4 <- fitact(pan4)
fitliv4 <- fitact(liv4)
# Compare the fitted models
ppanliv4 <- compareCkern(fitpan4, fitliv4, reps = 1000)
#将重叠值panliv1est和p值加到图里
text(3, 0.12, labels = paste("Δ=", round(panliv4est, 2),", p=", ifelse(ppanliv4["pNull"] < 0.01, sprintf("%.2f", ppanliv4["pNull"]), round(ppanliv4["pNull"], 2)), sep=""))
上面的代码做的都是单个季节的,如果想要选择多个季节,可以使用操作符%in%
pan5 <- timeRad[data$Season %in% c('冬季', '春季', '夏秋季') & data$Species == '大熊猫']代码里的这一行的text可以根据自己图的横纵坐标的大小进行调整,3对应x轴,0.10对应y轴,自己多尝试一下,调整到合适的位置
text(3, 0.10, labels = paste("Δ=", round(panliv2est, 2),", p=", ifelse(ppanliv2["pNull"] < 0.01, sprintf("%.2f", ppanliv2["pNull"]), round(ppanliv2["pNull"], 2)), sep=""))
图片输出
使用代码输出PDF非常容易出问题,因此建议跑完图后用R自带的输出功能输出图,在右下角的窗口选择Plots—Export—Save as PDF 输出矢量图,后续可将PDF转为PPT,方便调整
结果如下
上面的代码输出结果是四个季节四幅图,按照自己需求可以调整

















 164
164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









