



终于等到了,信息量非常之大!
这份技术报告值得每个做大模型相关工作的同学们反复阅读、认真研究,一定能节省大量的探索时间和算力浪费。
**我们不妨挑重点先分析一下。**实际上在四月底Qwen3系列模型开源后,我第一时间就在知乎上锐评过(见注释[1]):最核心的技术亮点,其实就是类似于Claude 3.7 sonnet的混合思考模式Hybrid Thinking Modes
注意看,在技术报告中Figure 1的Post-training架构图,Stage 3 + Stage 4是实现混合推理的关键阶段,我把Stage 3 Thinking Mode Fusion和Stage 4 General RL用圆圈圈了出来,并加上了五角星⭐️标注。
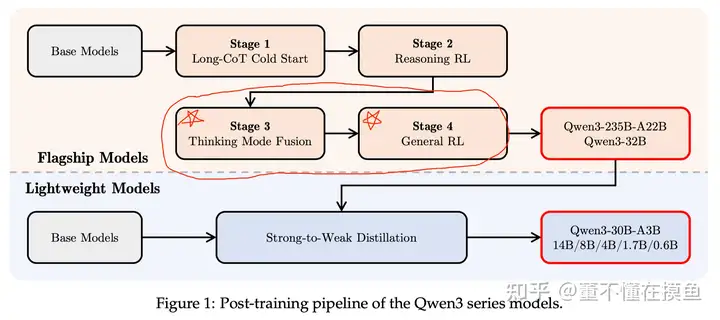
这次技术报告,实际上把我们应该怎么实现基于一个模型的混合思考模式Hybrid Thinking Modes,即将快思考和慢思考两种方式融合的训练方式,完全公开了,
非常坦诚,一点也没藏着掖着,而其中很多关键信息,在四月底的Blog中并没有揭露出来。
具体来说,在Stage 3混合推理训练阶段,实现的方式是SFT(Supervised Fine-Tuning),这时候基座模型已经是推理模型Reasoning model了!——因为已经经过了Stage 1的Long-CoT 冷启动训练和 Stage 2 的强化学习训练。
技术报告中给出了典型的STF训练中的chat template模板,如下:

最终效果其实很简单,通过上述chat template模版训练,用户可以在Prompt里,随时手动切换(现在还不是通过router自动切换,因为是主要是SFT聊天模板训进去的),控制是否需要思考,随便拿我在本地通过Ollama部署的Qwen3 0.6B来举个例子:
- 这是在Prompt里面,手动添加“/no_think”,输出结果包含和 token,但把中间过程全部省略,为空,这跟上图中的Non-Thinking Mode完全一致:

Non-Think Mode
- 这是默认情况,开启Think Mode,大模型会有思维链CoT包含在和 token之间:

默认开启Think模式
注意!我们需要特别注意的是,在实现上述混合思考模式的训练时,因为基座模型已经是推理模型Reasoning model,因此应该关注模型性能是否有下降的问题。
众所周知的是,推理模型Reasoning model,再基于上述聊天模版进行混合思考模式切换的SFT训练,极容易训崩。为确保性能不被损坏,SFT数据集设计就非常关键,这部分在技术报告中有详细介绍:
- “思考Thinking”数据设计:通过Stage 2训练得到的推理reasoning模型,利用Stage 1的query进行rejection sampling ,确保数据质量与模型能力匹配,避免性能下降。
- “非思考Non-Thinking”数据:精心挑选,覆盖多样化任务(编码、数学、指令跟随、多语言、创意写作、问答、角色扮演),保证任务全面性。
- 质量控制:使用自动生成的清单评估“非思考Non-Thinking”数据响应质量,确保数据可靠性。
- 低资源语言优化:增加翻译任务比例,提升低资源语言任务的性能。
然而,这还没完。
Stage 4 的通用强化学习(General RL)阶段,可以通过通用RL训练,来广泛提升模型在多样化场景下的能力和稳定性。
所以仅仅利用上述构造的数据,通过Stage 3进行SFT实现混合思考还不够,在Stage 4进行的通用强化学习(General RL)中,设计的奖励函数Reward function,有很重要的一项控制混合思考模式切换,即Format Following。
里面对混合思考模式能否正确在thinking 和 non-thinking modes中进行切换,利用reward信号反馈监督,进一步保证格式遵循。
当然,还有很多其他可以分析的重点内容,这里篇幅所限,就不多赘述了,等将来有时间再单独在专栏里面更新吧。比如很多人讨论的,不到4K samples 用于Stage 2的RL 训练阶段;再比如,Qwen3的强化学习RL训练仍采用的是GRPO等等
总之,Qwen3这份非常坦诚的技术报告,本质上跟DeepSeek 系列模型的技术报告类似,都是咱们国产大模型努力向开源社区贡献的典范,**常坦诚的技术报告,本质上跟DeepSeek 系列模型的技术报告类似,都是咱们国产大模型努力向开源社区贡献的典范,至少从开源精神这点上,比老是藏着掖着、等人家开源后才着急事后追认的某些美国硅谷闭源大厂们,“不知道高到哪里去啦!”
如何高效转型AI大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的AI大模型开发领域。为什么精准学习如此关键?
•**系统的技术路线图:**帮助你从入门到精通,明确所需掌握的知识点。
•**高效有序的学习路径:**避免无效学习,节省时间,提升效率。
•**完整的知识体系:**建立系统的知识框架,为职业发展打下坚实基础。
适用人群广泛无论是初学者还是资深开发者,这份学习路线图都能助你事半功倍,快速提升技能,推动职业生涯的发展。免费领取完整版学习资料扫描下方二维码,免费领取【保证100%免费】!

AI大模型知识脑图

AI大模型精选书籍

AI大模型视频教程

AI大模型面试场景题


最后说一下
当前,AI大模型技术正推动各行业智能化转型。该教程通过"应用-开发-算法"三位一体的学习路径,帮助学习者系统掌握大模型核心技能。从工具使用到模型调优,七天集训聚焦真实业务场景的解决方案,完成从理论到实战的能力跨越。把握技术变革窗口期,这场高效学习将为你打开AI工程师的职业通道,赋能未来技术生涯的持续发展。


















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









