







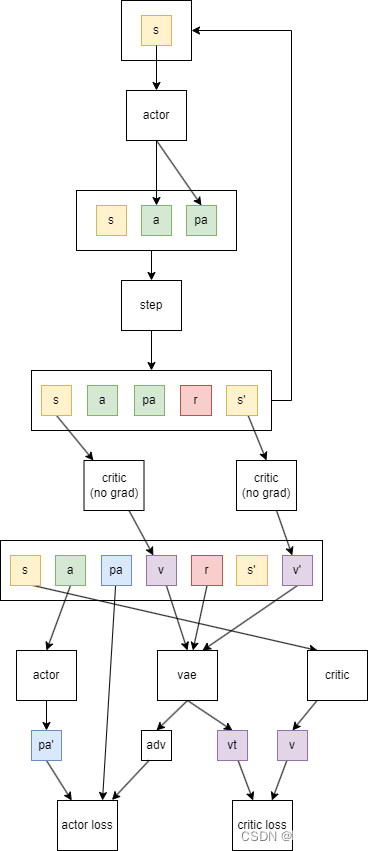
1 采集数据阶段
上面这个循环是用来采集数据,并且加入到replay buffer中。最终获取的数据是
- s: 当前状态,或者observation
- a: 当前动作,后面重要性采样需要用到
- pa: 选择当前动作的概率,后面重要性采样用到
- r: 当前的奖励值
- s’: 下一个状态
有些算法可能会直接在这里估计state value,即这步的下面一步合并到这步中,那么就会增加state value, 和next state value
这里也可以采集多步,再加入到replay buffer中。
2 训练阶段
一般是采集一步数据,加入replay buffer,然后采样若干数据训练多次。也有是采集多步数据,然后训练多次。
2.1 critic损失计算
- 计算target value需要通过advatage+state value计算。
- advatage具体的计算方式是:
adv = r + γ v ′ − v \text{adv} = r+\gamma v'-v adv=r+γv′−v
这里的v和v’是当前value和下一步value,adv间接表示了动作的价值。
当多步的adv加权求和之后,可以获得vae,它表示了更加优秀的动作价值估计,在计算actor loss时使用。
adv+v就是当前状态价值了,或者说 v t = r + γ v ′ v_t=r+\gamma v' vt=r+γv′,这个值就是critic的目标。
2.2 actor损失的计算
- 首先通过当前的actor网络,估计出了动作action的概率pa
- 损失就是-vae(pa-pa’),这里pa’是之前选择动作action的概率。
- 对于PPO来说,可以对损失进行进一步裁剪。
以上的训练阶段的两个损失,均是通过PPOLoss计算的。具体可以看:https://github.com/pytorch/rl/blob/main/torchrl/objectives/ppo.py
问题
1 在收集之后马上计算state value,和从replay buffer取出来后再计算state value,两者有什么区别?
下面是gpt回答:
- 将状态值加入到Replay Buffer中
优点:
- 稳定性:由于状态值是与状态和动作对应的估计值,这样存储在replay buffer中的值是基于当时的critic网络计算的,避免了因critic网络更新而引起的估计不稳定。
减少计算开销:在每次使用replay buffer中的样本进行训练时,直接读取存储的状态值,可以减少重新计算的开销。
缺点:
- 过时的估计:随着训练的进行,critic网络不断更新,存储在replay buffer中的状态值可能变得过时,不再准确反映当前的网络状态。
- 存储空间:需要额外的存储空间来保存这些状态值,增加了内存的需求。
- 通过当前的Critic网络重新估计
优点:
- 最新的估计:每次使用replay buffer中的样本时,使用当前的critic网络重新估计状态值,保证了状态值反映的是最新的网络状态。
- 避免过时信息:由于每次都重新计算,可以避免使用过时的信息进行更新,提高了训练的有效性。
缺点:
- 计算开销增加:每次从replay buffer中取样本时都需要通过当前的critic网络重新估计状态值,增加了计算开销。
- 可能的估计不稳定:由于critic网络在训练过程中不断更新,状态值的估计可能会有较大的波动,导致训练的不稳定性。
两者应该都可以,在torchrl中也会在vae计算时候检查是否已经估计了state value,没有的话会自动帮你调用critic估计一下。
2 在网络前加上RNN是否破坏了马尔可夫性
如果只能获取有限状态,应该是不影响。如果是所有状态,则影响。
3 replay buffer应该存储什么
如果采集到数据,马上就计算state value,那么其实不需要保存state,也就是critic(no grad)这一步可以放在step之前,然后在replay buffer中不再存储state,而是state value。这两种方式都可以,看自己选择了。

















 1020
1020

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









