






基本 TopN 问题
1)请在 PySpark 编程环境中输入下面的代码:
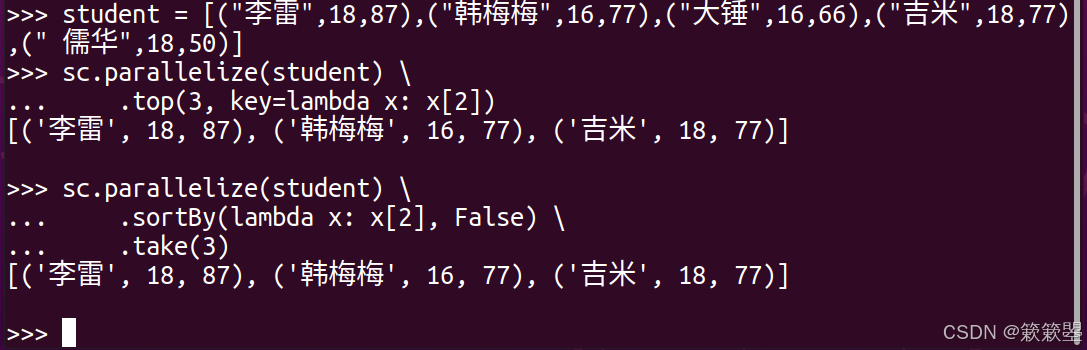
2)要找出分数最高的前 3 名学生,可以先仅对分数进行排序得到最高的三个分数,再以这三个分数中的最低分为基准对学生信息进行筛选,最后将筛选出来的学生排序: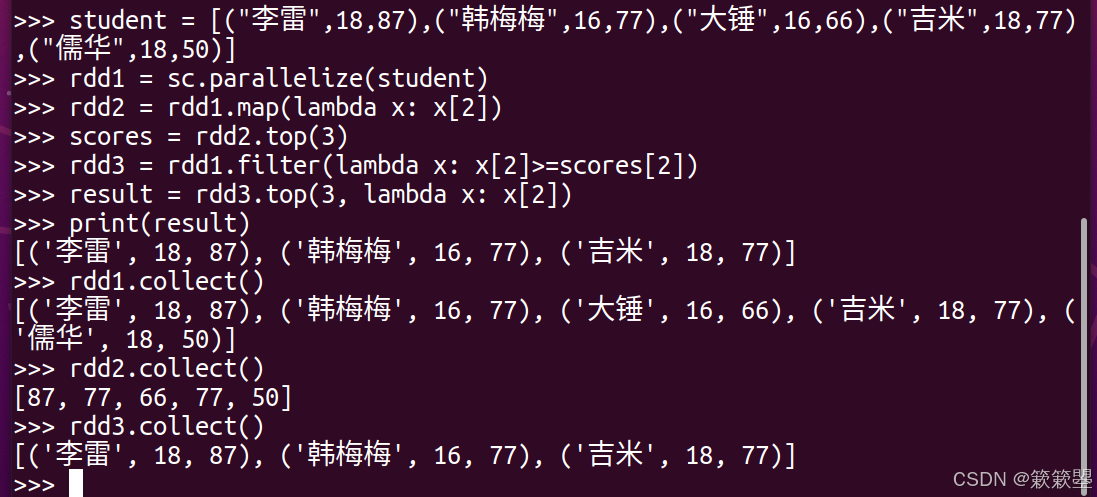
RDD 问题实践
1.元组转换
问题:有一个元组 (1,2,3,4,5),请使用 Spark 的 map() 将其转换为一系列元组的集合:(0,1,1), (0,4,2), (0,9,3), (0,16,4), (0,25,5)。
答:

2. 文件内容转换
问题:使用 mydata 目录中的 a.txt 文件,将其转换为一个由数字为元素构成的 RDD,转换规则为:若文件中的行内容是一个偶数则除以 2,奇数则不变。
答:
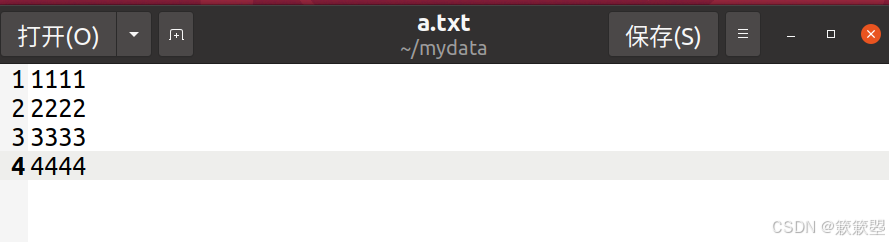
(1)在 Ubuntu 中创建 mydata/a.txt 文件,内容如下
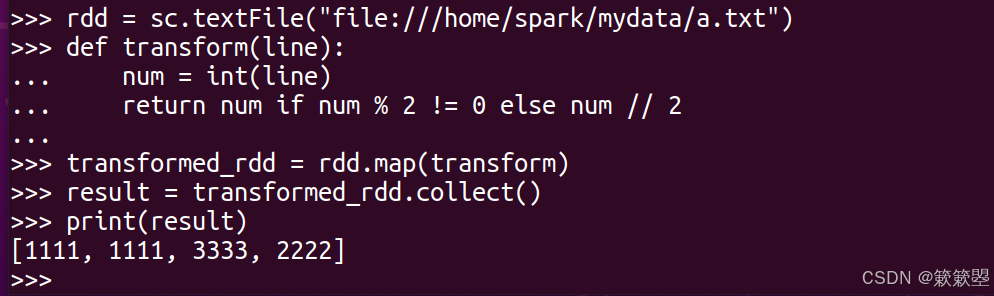
(2)在 PySpark Shell 中运行以下代码:
3. 筛选并转换单词
问题:将 mydata 目录中的 b.txt文件中的所有“长度超过 12”的单词挑选出来,并将其转换为大写形式,然后显示其中的前 5 个单词。
答:
(1)在 Ubuntu 中创建 mydata/b.txt 文件,内容随意
(2)在 PySpark Shell 中运行以下代码:
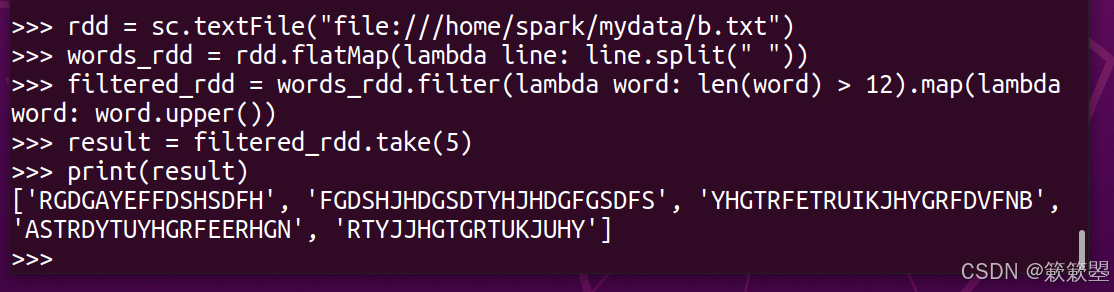
4. 代码分析
问题:分析以下代码为什么看不到期望的结果。
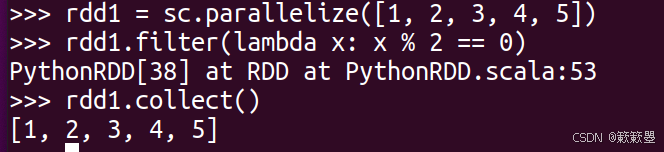
答:
-
问题在于
filter()是一个转换操作,它不会立即执行,而是返回一个新的 RDD。原始 RDDrdd1并没有被修改。 -
应该将过滤后的 RDD 赋值给一个新的变量,然后收集结果。
正确代码:

5. 单词排序与筛选
问题:将 mydata 目录中的 b.txt 文件中的单词进行排序(忽略大小写),然后输出所有以字母“m”和“n”开头的单词。
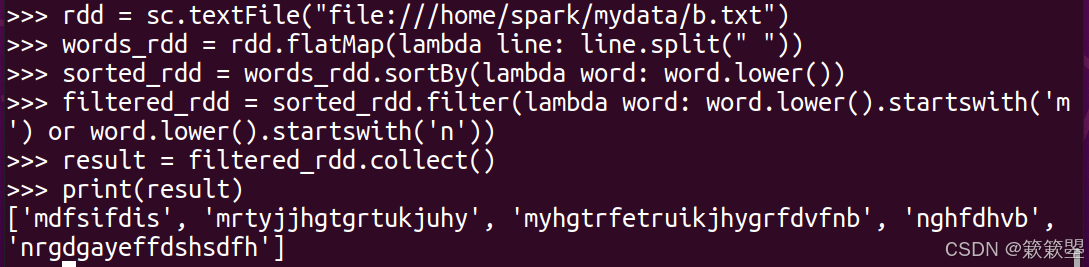
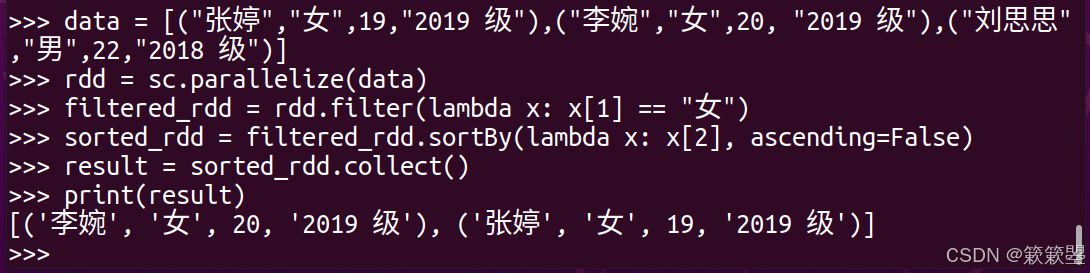
6. 按年龄排序
问题:参考下面集合数据,将其中的女同学按年龄从大到小排序输出。[("张婷","女",19,"2019 级"),("李婉","女",20, "2019 级"),("刘思思","男",22,"2018 级")]
答:
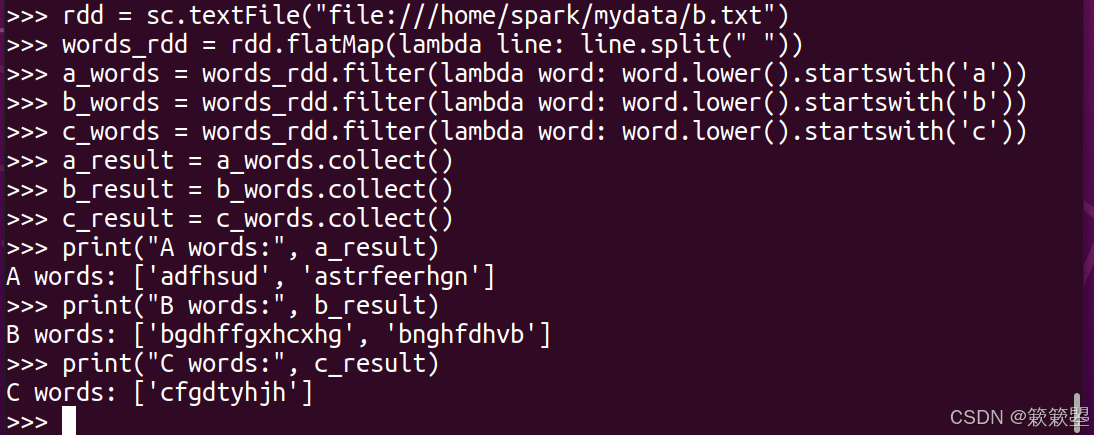
7. 按首字母分类
问题:将 mydata 目录中的 b.txt 文件中包含的所有单词按首字母进行分类(首字母忽略大小写),然后分别输出以 a、b、c 开头的单词。
答:

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









