






distinct去重数据
1)下面给出一个简单的应用例子:
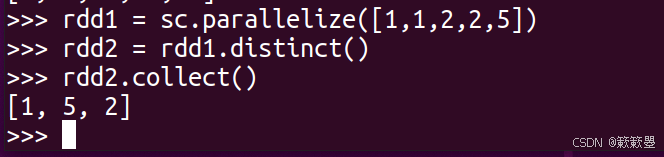
2)Spark官方对distinct()方法的功能定义如下:


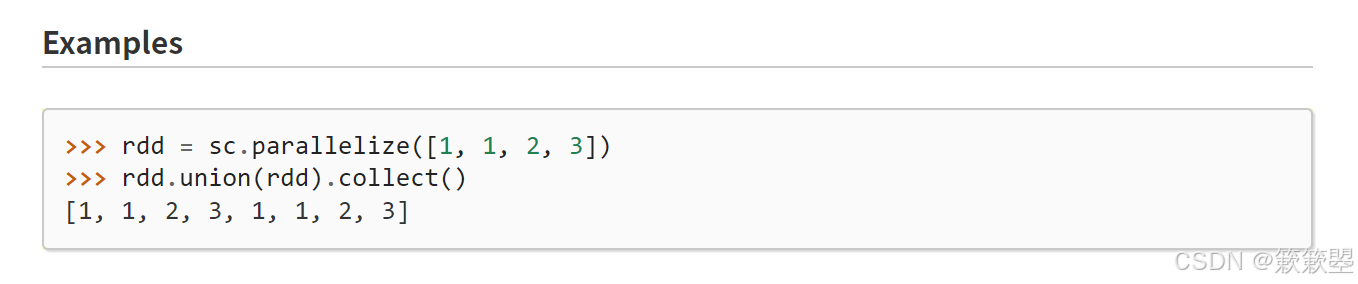
union合并数据
1)下面给出一个简单的应用例子:
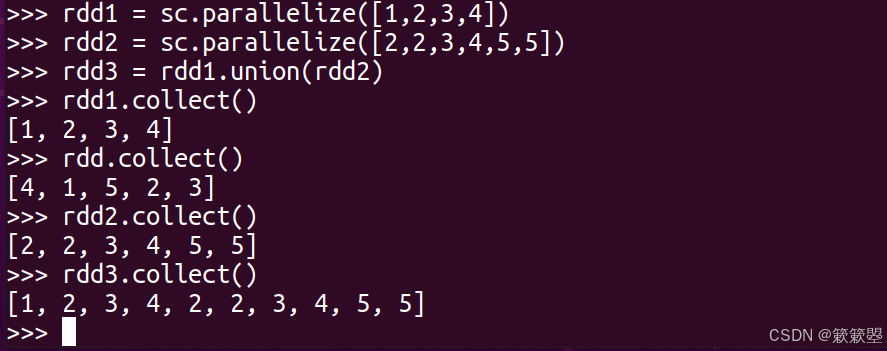
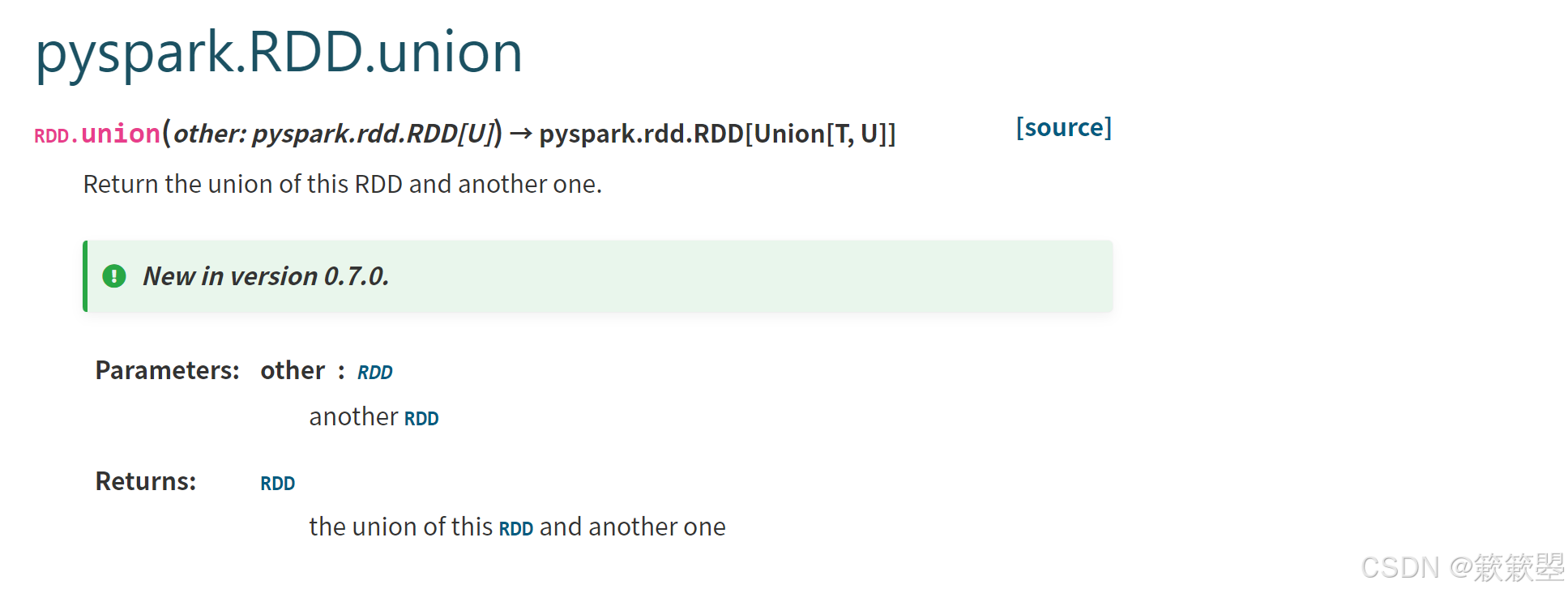
2)Spark官方对union()方法的功能定义如下:
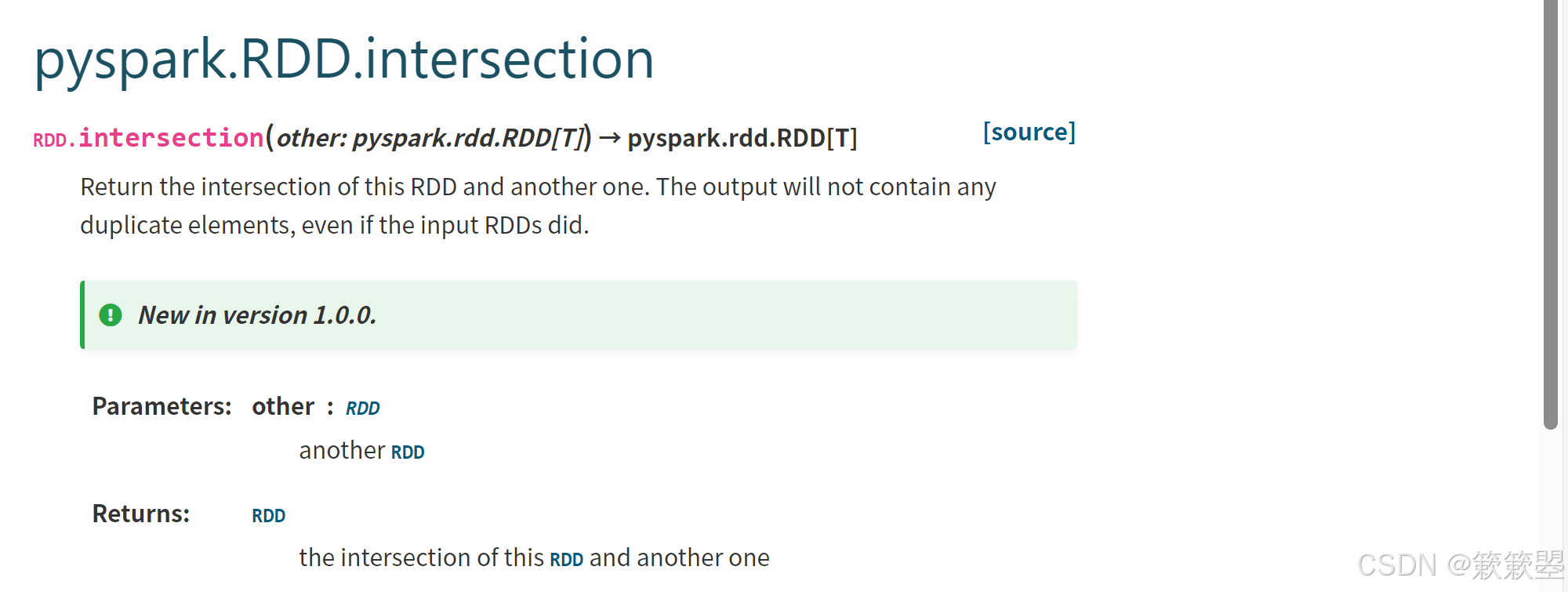
intersection数据交集
1)下面是一个简单的例子:
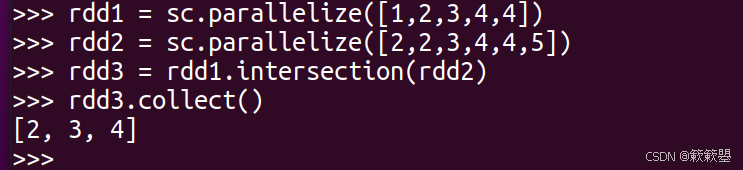
2)Spark官方对intersection()方法的功能定义如下:
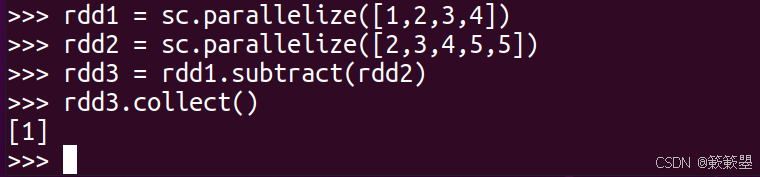
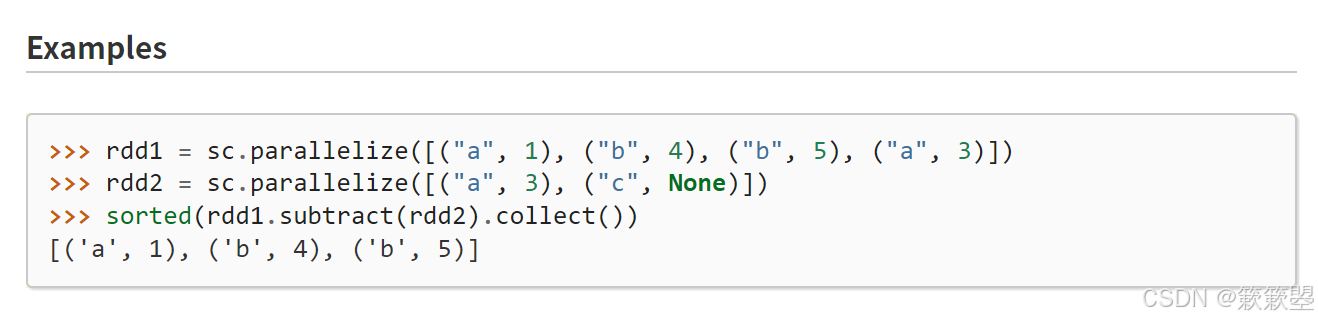
subtract数据减集
1)下面是一个简单的例子:
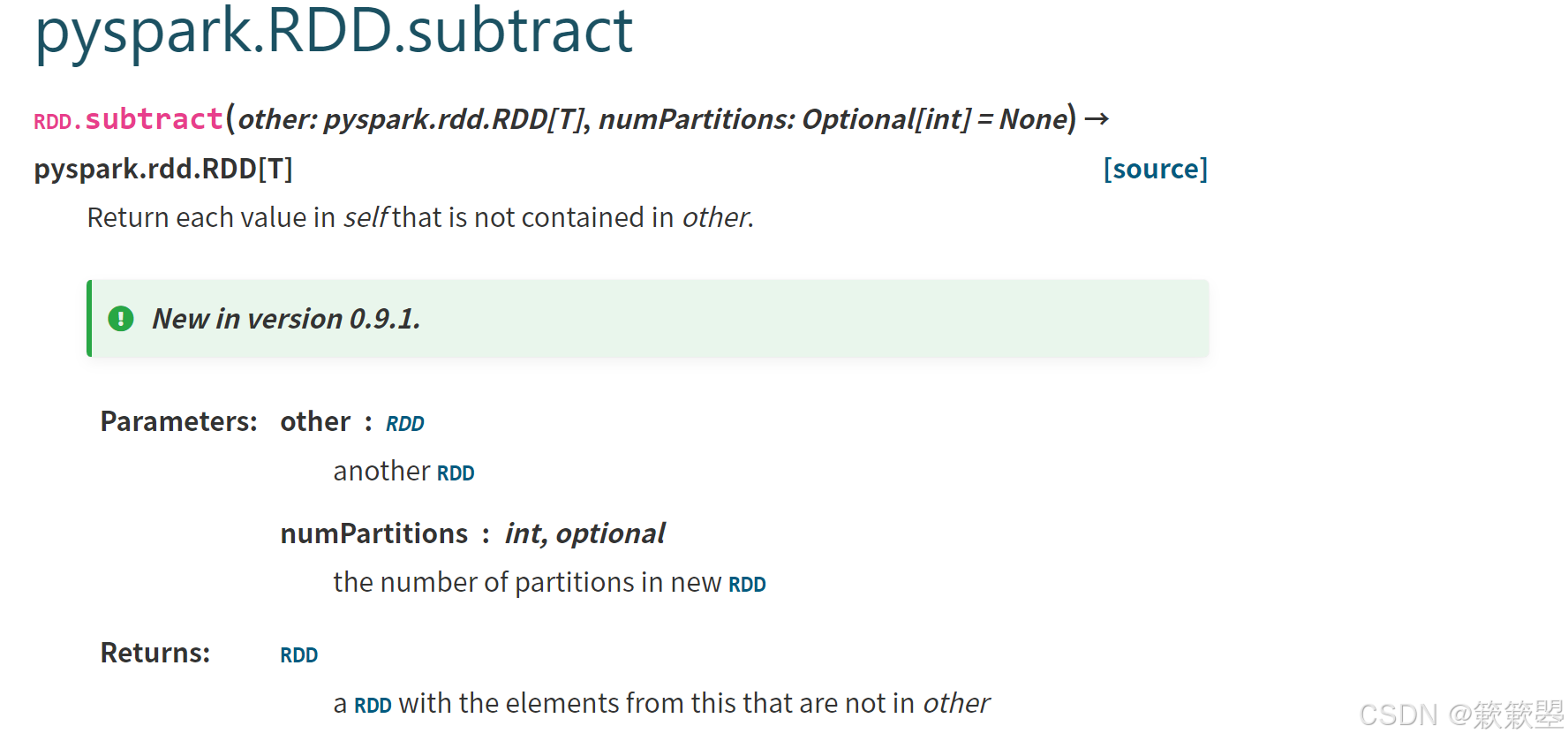
2)Spark官方对subtract()方法的功能定义如下:
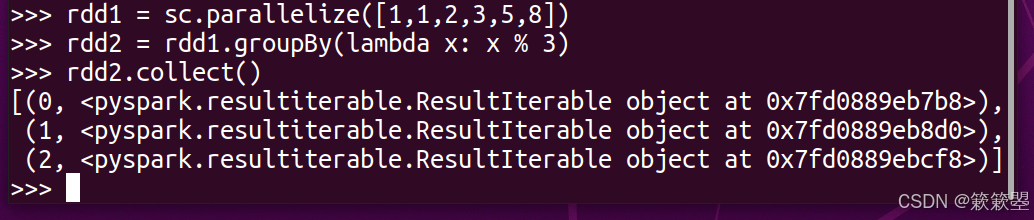
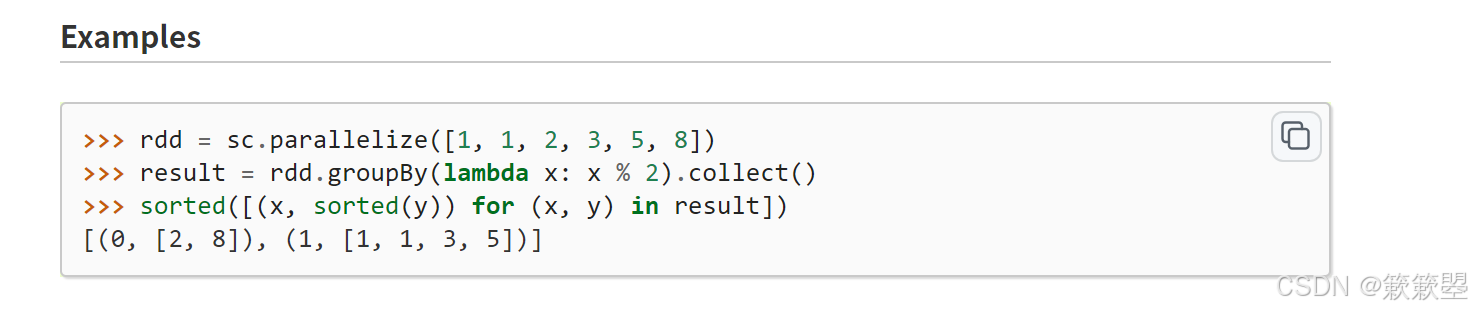
groupBy分组数据
1)下面是一个简单的例子:
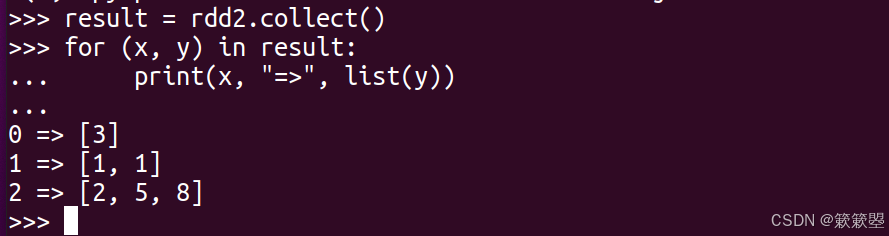
2)通过一个for循环将其打印输出:
3)Spark官方对groupBy()方法的功能定义如下:

groupByKey分组数据
1)这里以一个简单的例子予以说明:

2)Spark官方对groupByKey()方法的功能定义如下:

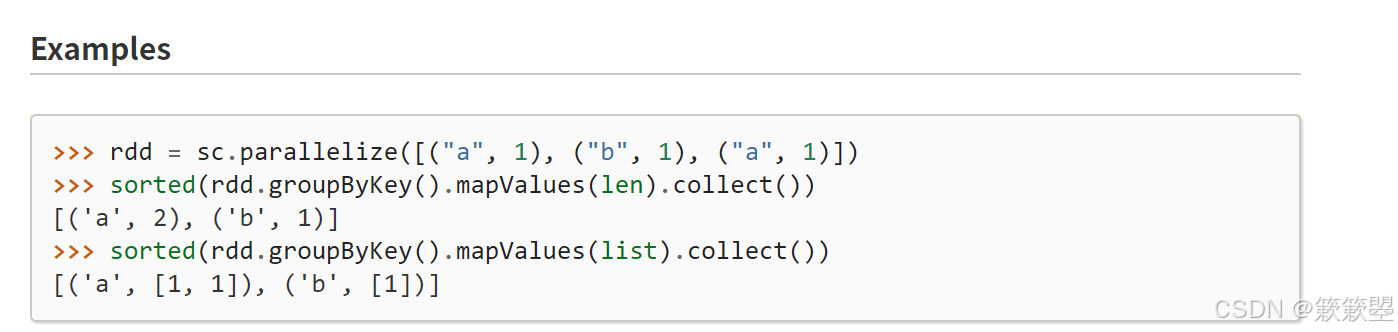
reduceByKey合并数据
1)下面以代码例子来说明:

2)Spark官方对reduceByKey()方法的功能定义如下:


sortByKey排序数据
1)下面以具体的例子代码分别给出sortByKey()方法的几种使用途径:
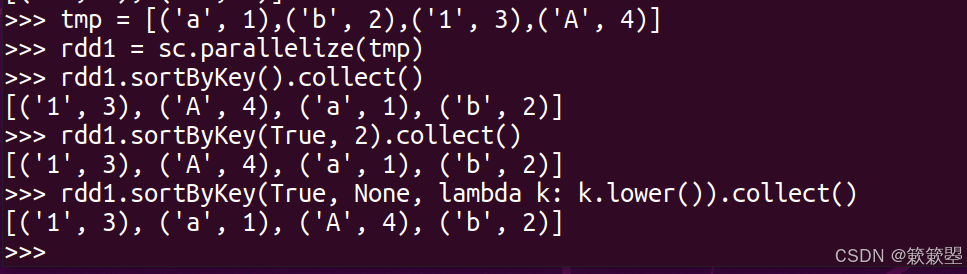
2)Spark官方对sortByKey()方法的功能定义如下:


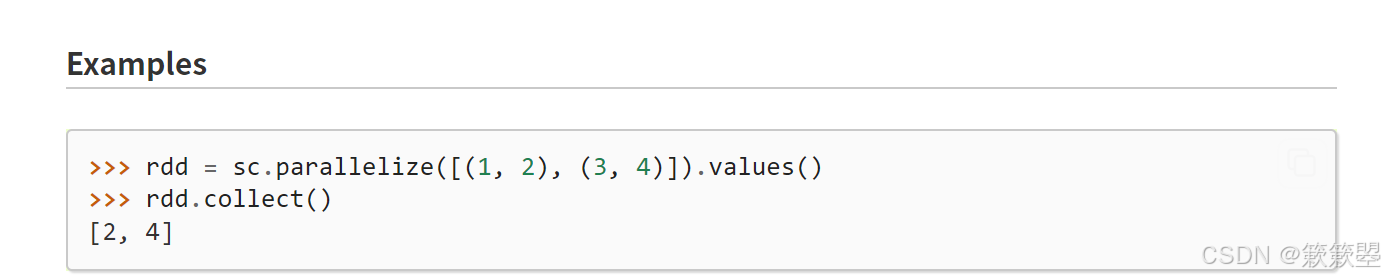
keys和values操作
1)下面给出一个例子代码:
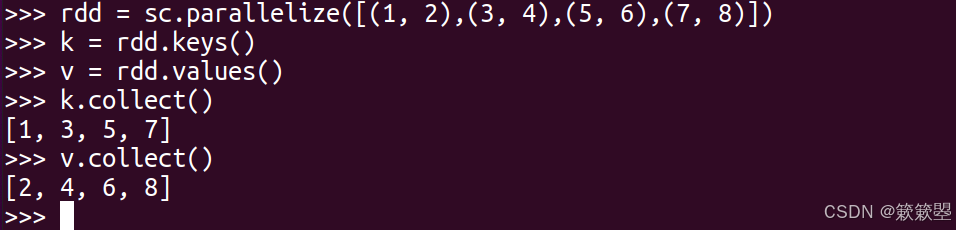
2)Spark官方对keys()和values()方法的功能定义如下:



mapValues和flatMapValues操作
1)下面通过一个使用了mapValues()和flatMapValues()的示例代码进行说明:
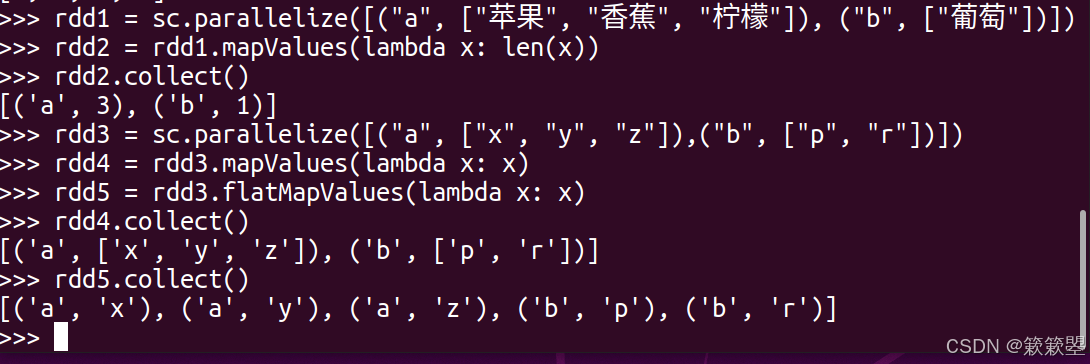
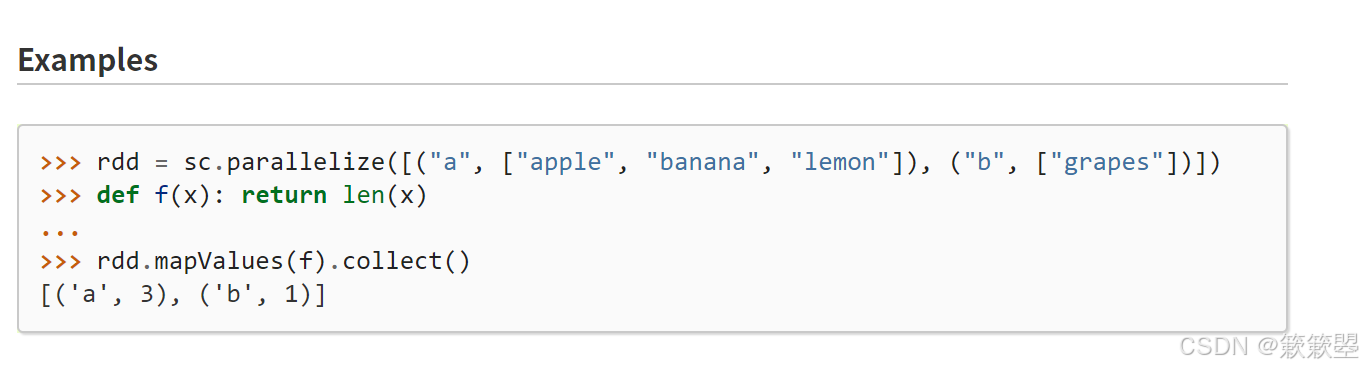
2)Spark官方对mapValues()和flatMapValues()方法的功能定义如下:


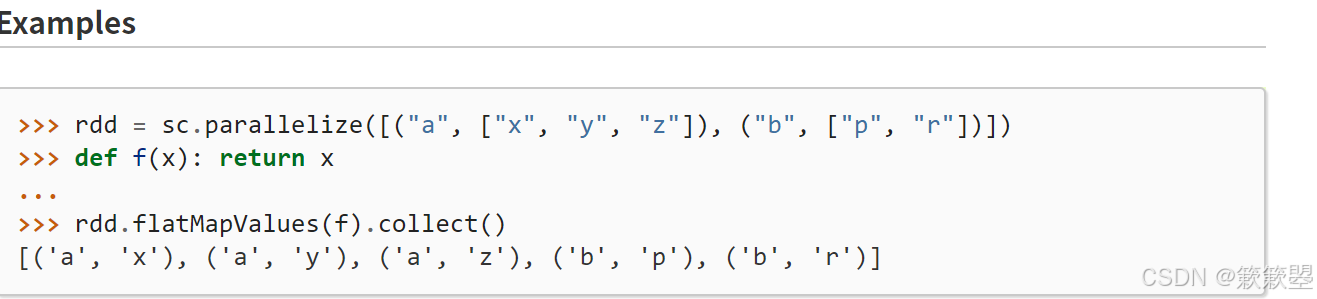
collect操作
1)下面以一个简单的例子来验证一下collect()方法返回的数据类型:
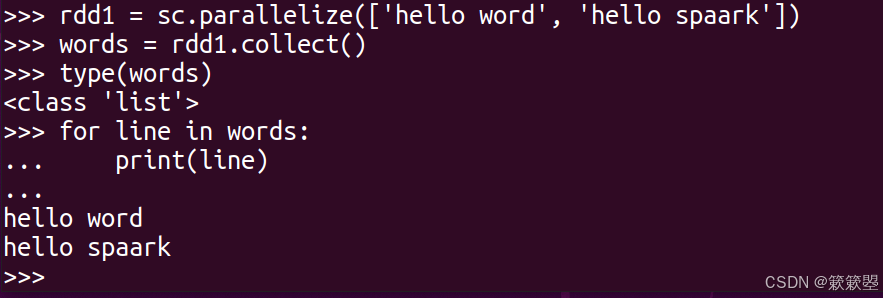
2)collect()返回的是一个List类型的数组。
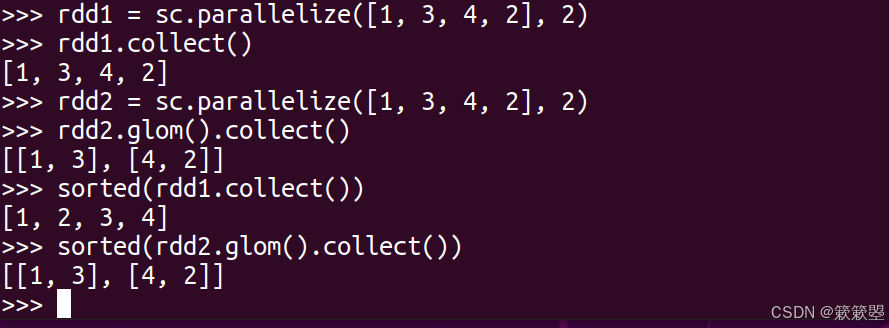
3)Spark官方对collect()方法的功能定义如下:

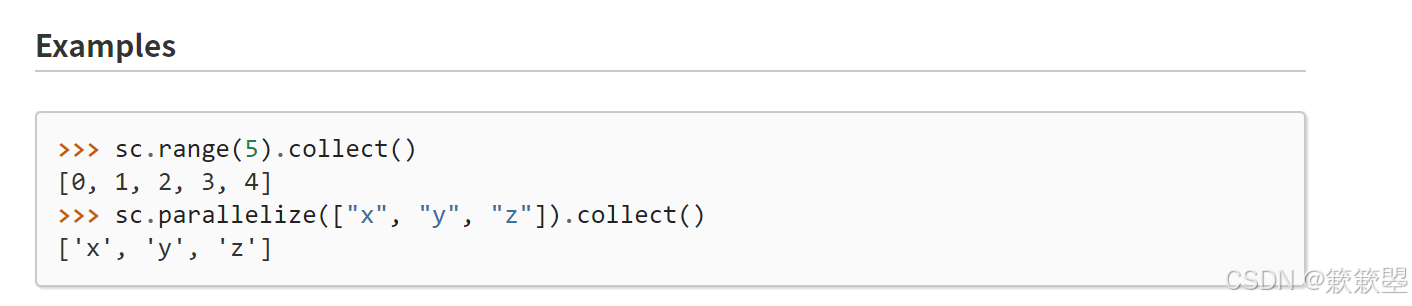
take操作
1)下面给出take()的使用示例代码:
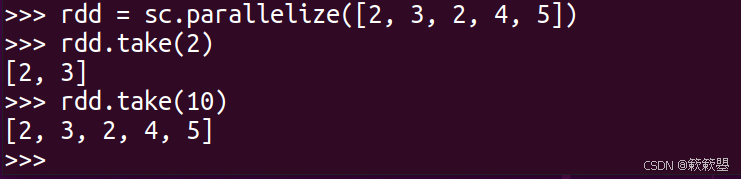
2)take()相比collect()就是可以指定返回的元素个数。
first操作
1)下面是一个最简单的first()例子代码:
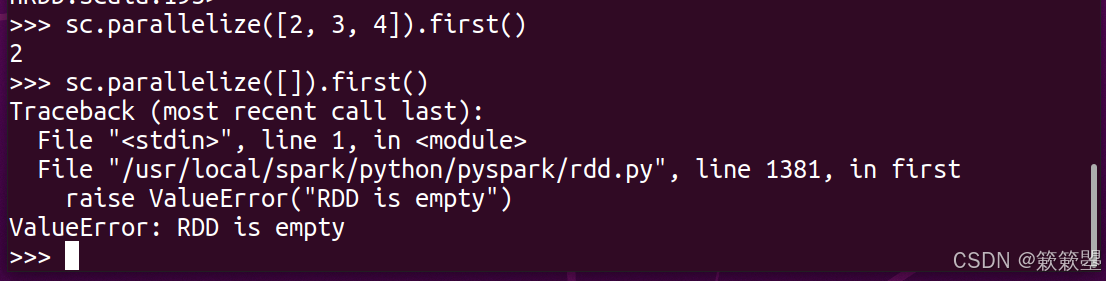
2)如果是对一个空的RDD执行first()方法的话,因为不存在任何元素,此时会提示错误信息。
foreach操作
1)下面是foreach的例子代码:
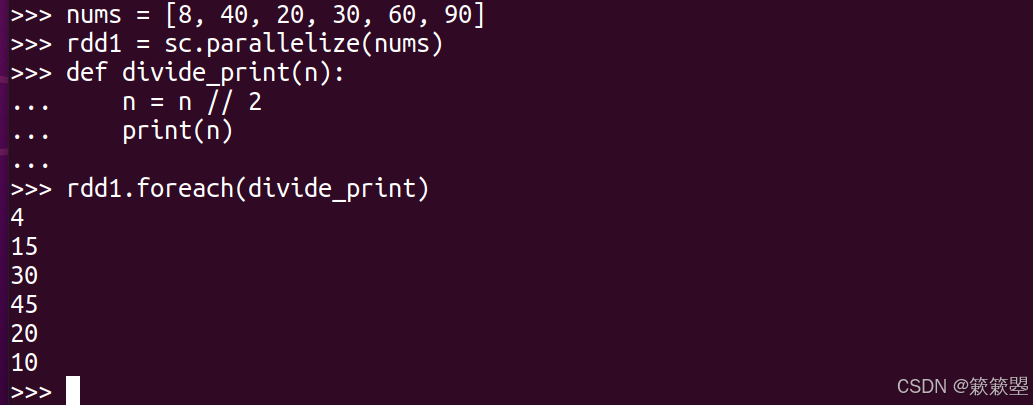
2)Spark将集合数据分配到了多个CPU核上去并行执行,无法保证输出按原有的数字位置顺序。
count操作
1)下面是count()方法的使用的示例:

2)count()返回的是RDD数据集的元素个数。
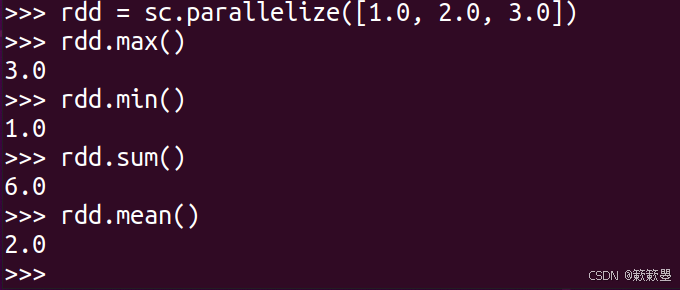
max/min/sum/mean操作
1)下面直接给出示例代码:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









