






一、词频统计案例
1.需求分析
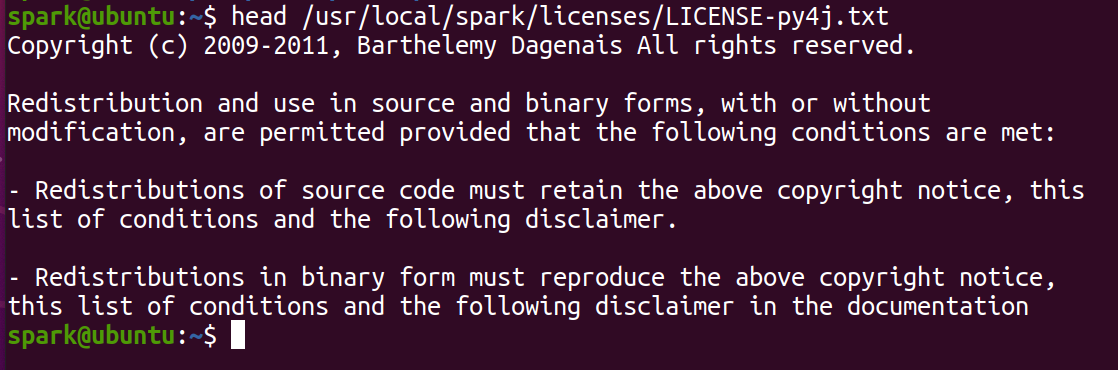 这个文件的数据是非结构化的,每行的单词个数是不固定的,也没有具体的含义。为了使用Spark SQL来处理它,第1步工作就是要将这个文件的数据转换成结构化的形式,由于我们真正关注的是各个单词,因此可以像以往那样将文件数据转换为RDD,然后经过一定的处理后将其转变为DataFrame,这样就可以由SparkSQL来处理
这个文件的数据是非结构化的,每行的单词个数是不固定的,也没有具体的含义。为了使用Spark SQL来处理它,第1步工作就是要将这个文件的数据转换成结构化的形式,由于我们真正关注的是各个单词,因此可以像以往那样将文件数据转换为RDD,然后经过一定的处理后将其转变为DataFrame,这样就可以由SparkSQL来处理
2.SparkSQL编程实现
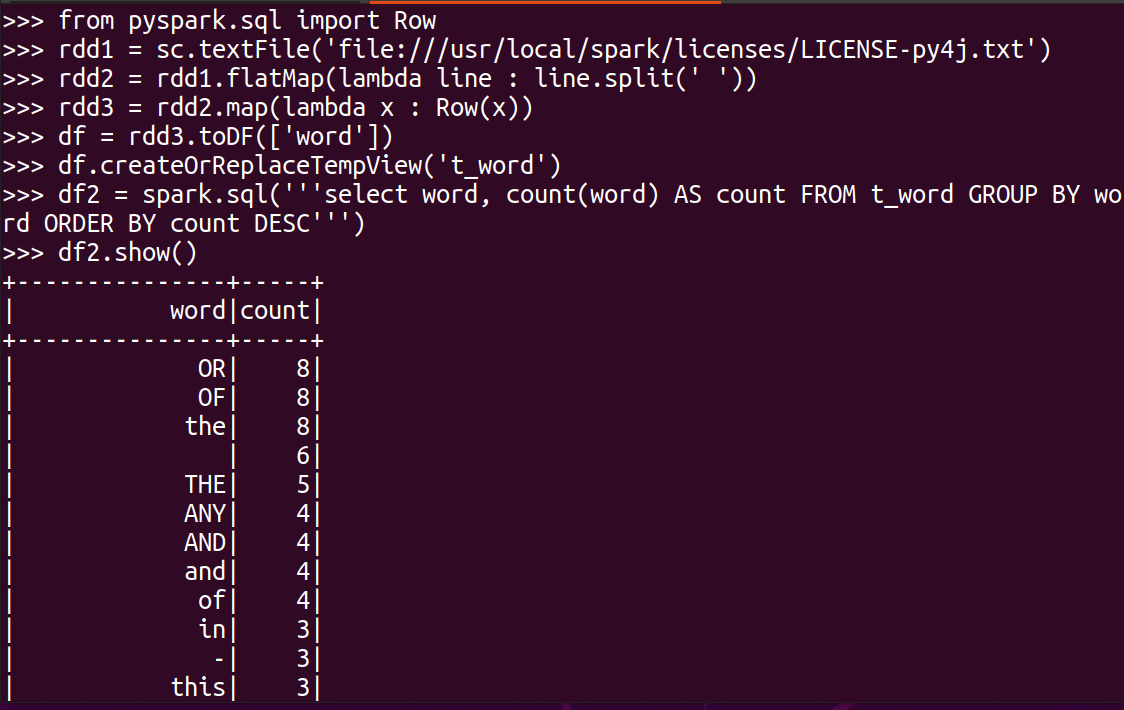 首先将文件数据转换为rdd1,由于它是非结构化的数据,因此同样需要把每行包含的单词切解出来。为了能使用Spark SQL进行处理,这里还把每个单词变成一个结构化的Row对象(代表一条表数据记录),并将RDD转换为DataFrame,后续就是常规的Spark SQL操作了。
首先将文件数据转换为rdd1,由于它是非结构化的数据,因此同样需要把每行包含的单词切解出来。为了能使用Spark SQL进行处理,这里还把每个单词变成一个结构化的Row对象(代表一条表数据记录),并将RDD转换为DataFrame,后续就是常规的Spark SQL操作了。
二、人口信息统计
1.需求分析
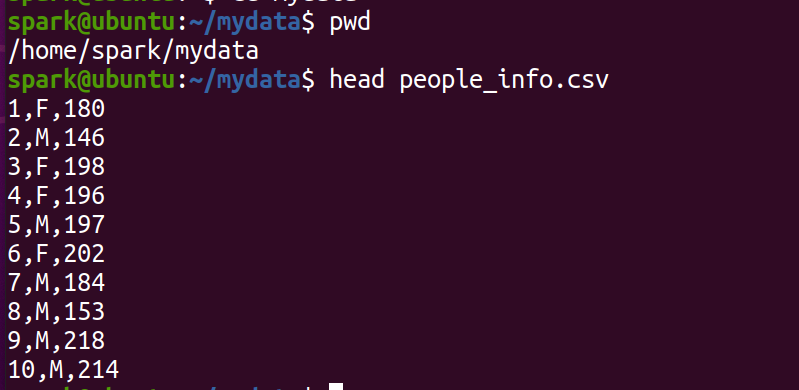
有一个包含600万人口信息的数据存储在当前主目录的people_info.csv文本文件中,其中,每行数据代表一个人的基本信息,3个字段分别是编号、性别(F/M)、身高(单位是cm),现要求使用Spark SQL完成以下数据分析任务:
(1)统计男性身高超过170cm以及女性身高超过165cm的总人数。
(2)按照性别分组统计男性和女性人数。
(3)统计身高大于210cm的前50名男性,并按身高从大到小排序。
(4)统计男性的平均身高。
(5)统计女性身高的最大值。
2.SparkSQL编程实现
(1)从csv数据文件构造出DataFrame数据表
(2)统计男性身高超过170cm以及女性身高超过165cm的总人数 第1个问题,即按照要求的条件统计人数,这需要用到SQL的count()统计函数
第1个问题,即按照要求的条件统计人数,这需要用到SQL的count()统计函数
(3)按照性别分组统计男女人数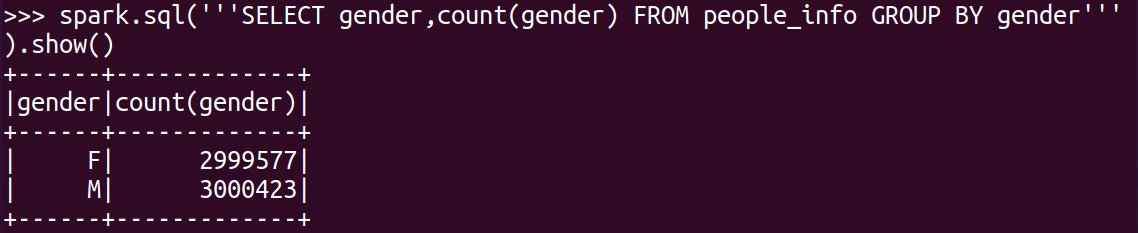
第2个问题实际是一个分组统计操作,可以先通过GROUP BY按指定字段进行分组,然后将分组后的字段应用count()、avg()、max()等聚合函数
(4)统计身高大于210cm的前50名男性,从大到小排序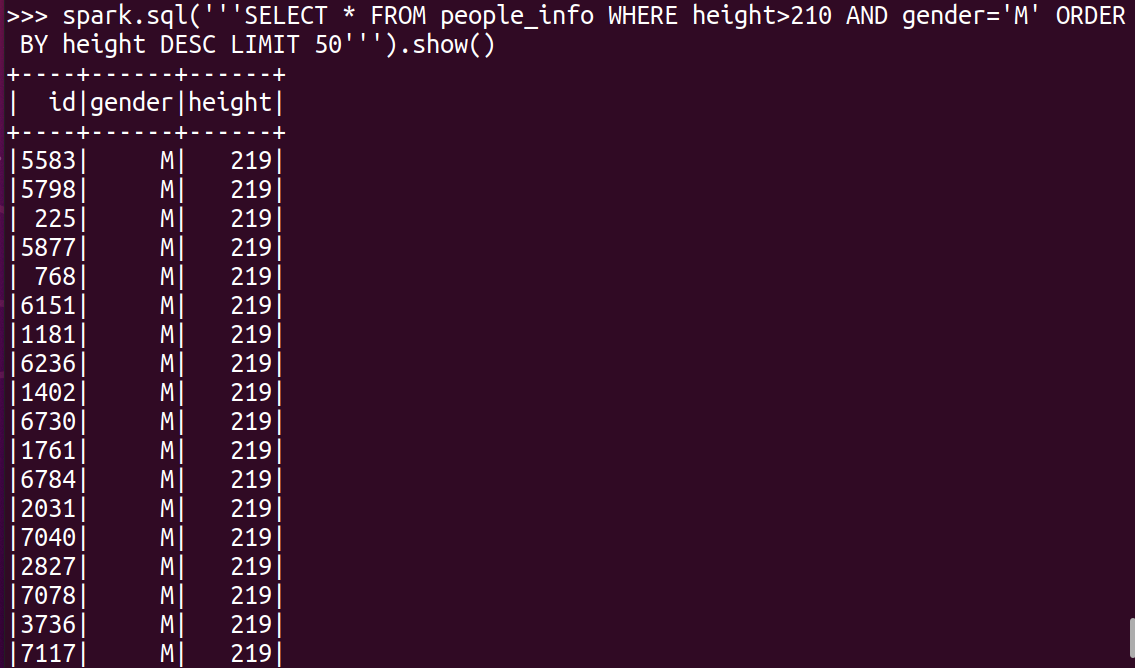
第3个问题是统计身高大于210cm的前50名男性,并按身高从大到小排序,因此需要使用ORDER BY和 LIMIT
(5)统计男性的平均身高
 第4个问题是统计男性的平均身高,需要使用avg()聚合函数
第4个问题是统计男性的平均身高,需要使用avg()聚合函数
(6)统计女性身高的最大值
 第5个问题是统计女性身高的最大值,这个问实现起来题也比较简单
第5个问题是统计女性身高的最大值,这个问实现起来题也比较简单

















 616
616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









