




 本文介绍在标注数据有限、未标注数据丰富的情况下,如何利用半监督学习提升模型性能。通过伪标签技术,对未标注数据进行预标注,再与真实标注数据结合训练模型。详细讲解了代码实现过程,包括数据加载、标签融合等关键步骤。
本文介绍在标注数据有限、未标注数据丰富的情况下,如何利用半监督学习提升模型性能。通过伪标签技术,对未标注数据进行预标注,再与真实标注数据结合训练模型。详细讲解了代码实现过程,包括数据加载、标签融合等关键步骤。
1. 背景
当标注数据较少,而未标注的数据很多,并且标注成本很高时,可以考虑半监督学习训练。首先,采用伪标签技术把没有标注的的图片打上伪标签,然后用标注数据和伪标签数据混合训练模型。值得注意的是,要保证每个mini-batch中含有真实标签和伪标签,本文带你用代码实现。
2. 实现方法及步骤
首先看看伪标签技术,参考这里,如下图所示:
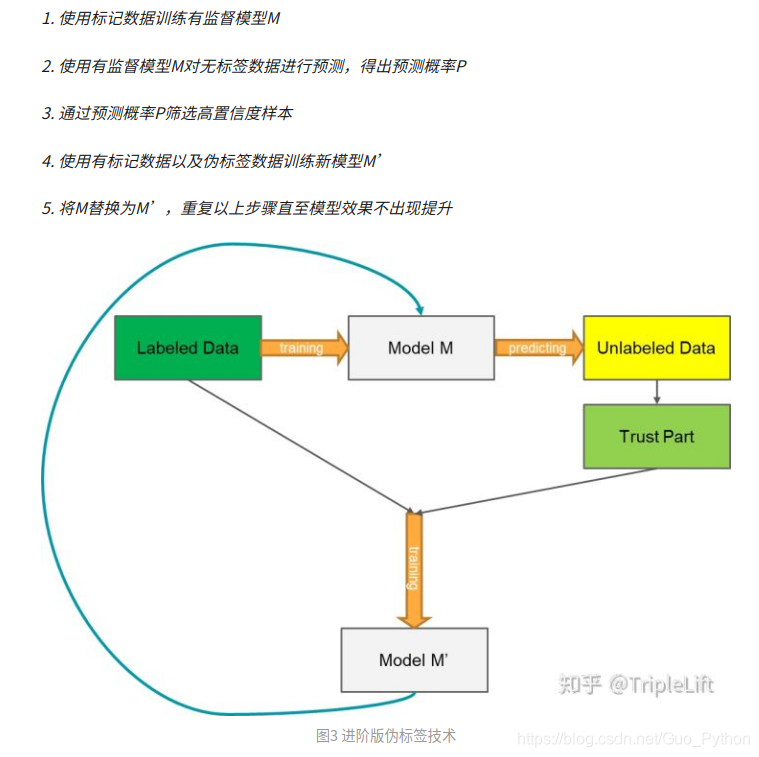
3. 代码实现
首先是生成伪标签,对于分类和目标检测而言都比较简单,这里不赘述。
下面实现的是:如何在每个mini-batch中保证同时存在真实标签和伪标签,并且控制他们的比例,以分类为例进行说明。
第一步,需要修稿数据加载程序,如下:
import os
import torch
from torch.utils import data
import numpy as np
from torchvision import transforms as T
import torchvision
import cv2
import sys
import random
from PIL import Image
from data_augment import gussian_blur, random_crop
class Dataset(data.Dataset):
def __init__(s 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











