




哈喽,老铁们!我最近在接触使用Dify。为了弄懂里面的逻辑和配置,所以我查询了不少资料和说明,所以总结了不少知识跟你们分享,欢迎随时指点进步。
1. Dify 是什么?
Dify 就像是一个智能小助手的训练基地,它能让 AI 变得更懂你,就像是给 AI 装上了一个超级大脑,让它能快速学会你想让它知道的东西,然后帮你解决问题。
2. Dify 的知识库是什么?
知识库就是 AI 的 “学习资料库”,你可以把各种文件,比如公司内部文档、常见问题解答(FAQ)、规范手册等放进去。这些资料就像是 AI 学习的课本,它能从中学习知识,然后在需要的时候,比如回答问题或者执行任务时,把这些知识用起来。
3. Dify 的知识库有什么用?
Dify 的知识库就像是 AI 的 “知识宝典”,能让 AI 掌握最新的信息。比如公司的政策更新了,或者产品有了新功能,你只要把相关文档放进知识库,AI 就能马上学会,这样它就能用最新鲜的知识来回答客户的问题,不会因为知识过时而答错。而且,这还能避免 AI 凭空编造答案,让它更靠谱。
4. Dify 的知识库导入本地文件有哪些配置?
把本地文件导进知识库,就像是给 AI 准备学习资料,有三个关键步骤:分段设置、索引方式和检索设置。
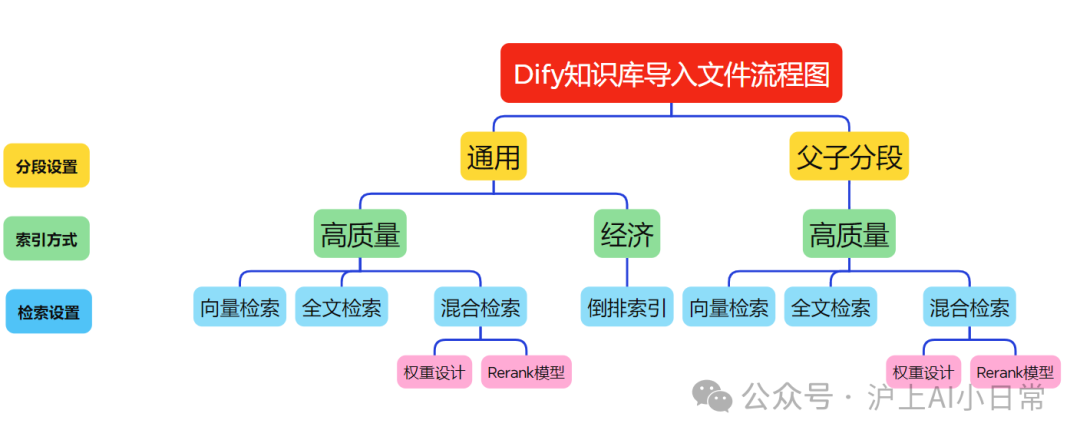
4.1 分段设置
4.1.1 术语解释
分段标识符 : 你可以把它想象成 AI 学习资料的 “段落标记”。比如一篇文章,你用一个空行或者一个特定的符号来分开不同的段落,这样 AI 就知道哪里是一个段落的结束,哪里是另一个段落的开始,方便
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2529
2529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









