




 本文通过构建一个包含2000个样本、20个特征的数据集,并使用10折交叉验证,对比了朴素贝叶斯、支持向量机及随机森林三种分类算法的性能。结果显示,在多数情况下,随机森林的表现更优。
本文通过构建一个包含2000个样本、20个特征的数据集,并使用10折交叉验证,对比了朴素贝叶斯、支持向量机及随机森林三种分类算法的性能。结果显示,在多数情况下,随机森林的表现更优。
【问题描述】

【解决思路】
第一步:先建立一个样本容量为2000、特征数量为20的数据集。
X,y = datasets.make_classification(n_samples=2000, n_features=20)关于sklearn的数据加载可参看https://blog.youkuaiyun.com/sa14023053/article/details/52086695。
第二步:使用10折交叉检验对数据集进行划分。
kf = cross_validation.KFold(2000, n_folds=10, shuffle=True) 关于交叉检验可以参看https://blog.youkuaiyun.com/u010414589/article/details/51145341。
第三步:训练算法
这里用的的算法有三种:
(1)朴素贝叶斯分类算法(GaussianNB类)
clf1 = GaussianNB()
clf1.fit(X_train, y_train)
pred1 = clf1.predict(X_test) 关于朴素贝叶斯分类算法的介绍可以参看https://www.cnblogs.com/pinard/p/6074222.html。
(2)支持向量机(SVM)分类算法(rbf核,参数C取1e-1)
clf2 = SVC(C=1e-01, kernel='rbf', gamma=0.1)
clf2.fit(X_train, y_train)
pred2 = clf2.predict(X_test) (3)随机森林分类算法
clf3 = RandomForestClassifier(n_estimators=6)
clf3.fit(X_train, y_train)
pred3 = clf3.predict(X_test)第四步:评估性能
acc = metrics.accuracy_score(y_test, pred)
f1 = metrics.f1_score(y_test, pred)
auc = metrics.roc_auc_score(y_test, pred) 【代码实现】
from sklearn import datasets
from sklearn import cross_validation
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn import metrics
# Step1: Create a classification dataset
X,y = datasets.make_classification(n_samples=2000, n_features=20)
print("X:\n", X)
print("y:\n", y)
# Step2: Split the dataset using 10-fold cross validation
kf = cross_validation.KFold(2000, n_folds=10, shuffle=True)
for train_index, test_index in kf:
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
print("X_train:\n", X_train)
print("X_test:\n", X_test)
print("y_train:\n", y_train)
print("y_test:\n", y_test)
# Step3: Train the algorithms
print("\n\nAlgorithm training:")
# GaussianNB
print("Gaussian:")
clf1 = GaussianNB()
clf1.fit(X_train, y_train)
pred1 = clf1.predict(X_test)
print("X_predict:\n", pred1)
print("y_test:\n", y_test)
# SVC
print("\nSVC:")
clf2 = SVC(C=1e-01, kernel='rbf', gamma=0.1)
clf2.fit(X_train, y_train)
pred2 = clf2.predict(X_test)
print("X_predict:\n", pred2)
print("y_test:\n", y_test)
# RandomForestClassifier
print("\nRandomForestClassifier:")
clf3 = RandomForestClassifier(n_estimators=6)
clf3.fit(X_train, y_train)
pred3 = clf3.predict(X_test)
print("X_predict:\n", pred3)
print("y_test:\n", y_test)
# Step4: Evaluate the cross-validated performance
print("\n\nPerformance evaluation:")
# GaussianNB
print("Gaussian:")
acc = metrics.accuracy_score(y_test, pred1)
print("Accuracy: ",acc)
f1 = metrics.f1_score(y_test, pred1)
print("F1-score: ", f1)
auc = metrics.roc_auc_score(y_test, pred1)
print("AUC ROC: ", auc)
# SVC
print("\nSVC:")
acc = metrics.accuracy_score(y_test, pred2)
print("Accuracy: ", acc)
f1 = metrics.f1_score(y_test, pred2)
print("F1-score: ", f1)
auc = metrics.roc_auc_score(y_test, pred2)
print("AUC ROC: ", auc)
# RandomForestClassifier
print("\nRandomForestClassifier:")
acc = metrics.accuracy_score(y_test, pred3)
print("Accuracy: ", acc)
f1 = metrics.f1_score(y_test, pred3)
print("F1-score: ", f1)
auc = metrics.roc_auc_score(y_test, pred3)
print("AUC ROC: ", auc) 【运行结果】
多次采用三种算法对随机生成的数据集进行预测,性能评估如下:
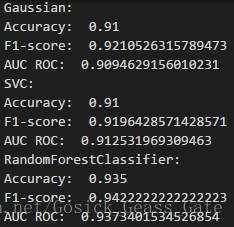
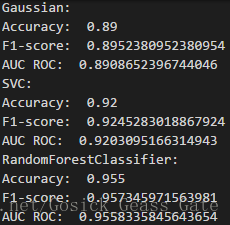
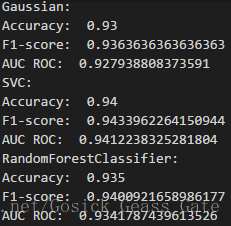
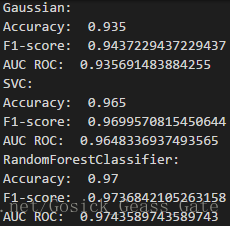
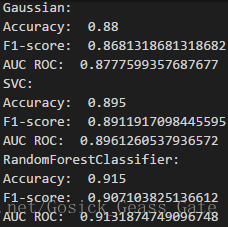
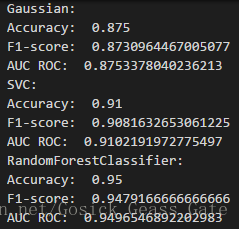
从多次的运行结果可以看出,多数情况下随机森林算法的性能比另外两个要好。

















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









