






—从环境配置到微调实战,解锁企业级AI私有化部署
一、为什么选择DeepSeek-R1本地化?
1. 企业级大模型的痛点
- API 依赖问题:ChatGPT等闭源模型无法深度定制,企业数据需上传第三方
- 推理成本高:云端API按Token计费,长期使用成本爆炸(如GPT-4 Turbo每百万Token 10 10 30)
- 延迟不可控:网络波动导致响应不稳定,影响高并发业务
2. DeepSeek-R1 本地化核心优势
✅ 完全开源可商用(Apache 2.0协议)
✅ 支持私有化部署,数据100%留在内网
✅ 千亿参数级模型,性能对标GPT-4
✅ 低成本推理:支持消费级GPU(如RTX 4090)
二、5分钟极速部署指南
1. 硬件要求
| 配置项 | 最低要求 | 推荐配置 |
| GPU | NVIDIA 16GB | A100 80GB |
| RAM | 64GB | 128GB+ |
| 存储 | 500GB SSD | 1TB NVMe |
2. 一键安装(Linux/Windows WSL2)
bash
复制
# 克隆DeepSeek-R1官方仓库
git clone https://github.com/deepseek-ai/DeepSeek-R1
cd DeepSeek-R1
# 使用Docker快速部署(自动下载模型权重)
docker-compose up -d --build 3. 验证部署成功
python
复制
import requests
API_URL = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"}
data = {
"model": "deepseek-r1",
"messages": [{"role": "user", "content": "用Python写一个快速排序算法"}]
}
response = requests.post(API_URL, json=data, headers=headers)
print(response.json()) 预期输出:返回格式化代码+详细注释
三、高级二次开发实战
1. 模型微调(LoRA/P-Tuning)
场景:让模型掌握企业内部知识(如医疗/法律专业术语)
python
复制
from transformers import AutoModelForCausalLM, TrainingArguments
model = AutoModelForCausalLM.from_pretrained("deepseek-r1-base")
# 加载企业专属数据集(JSON格式)
train_dataset = load_dataset("your_data.json")
# 使用LoRA轻量化微调
training_args = TrainingArguments(
per_device_train_batch_size=4,
learning_rate=5e-5,
num_train_epochs=3,
lora_rank=16 # 显著减少显存占用
)
trainer = Trainer(model, args, train_dataset=train_dataset)
trainer.train() 效果对比:
- 微调前:无法准确回答"我司产品A的核心参数"
- 微调后:自动关联企业知识库,回答精准率提升92%
2. 性能优化技巧
- 量化压缩:8bit量化后模型体积缩小4倍,RTX 3090可流畅运行
- python
- 复制
- model = quantize_model(model, bits=8) # 使用bitsandbytes库
- KV Cache优化:并发请求时内存占用减少70%
- yaml
- 复制
- # 修改config.yml use_flash_attention: true kv_cache_chunk_size: 2048
3. 企业级功能扩展
- 对接知识库:基于RAG实现实时数据检索
- python
- 复制
- retriever = VectorDBRetriever("company_knowledge") model.set_retriever(retriever) # 回答时自动引用最新产品文档
- 敏感词过滤:合规性保障
- python
- 复制
- from safety_checker import SafetyFilter model.add_post_process(SafetyFilter(keywords=["竞品A", "机密"]))
四、性能实测对比
| 任务类型 | GPT-4-API (云端) | DeepSeek-R1 (本地A100) |
| 代码生成 | 2.3秒/请求 | 0.8秒/请求 |
| 100并发吞吐 | 12请求/秒 | 85请求/秒 |
| 月度成本 | ¥15万+ | ¥2.3万(电费+硬件) |
五、延伸应用场景
- 程序员专属:
- 自动生成API文档 + 单元测试用例
- Git提交信息智能优化
- 企业定制:
- 合同条款自动审查(对接法律数据库)
- 客服对话实时质检
比象一站式AI创作系统源码,凭借全平台支持、独立移动端开发能力、前沿界面设计以及持续迭代更新等核心优势,我们为企业与个人开发者提供高效、灵活、稳定的AI创作解决方案。无论是内容生成、知识管理,还是创意设计,我们的系统都能轻松应对多样化需求,帮助用户大幅提升效率、显著降低成本、快速增强市场竞争力。通过源码交付与深度二次开发支持,客户能够打造专属的AI创作平台,实现技术与业务的双重突破,开启智能化创新的无限可能。
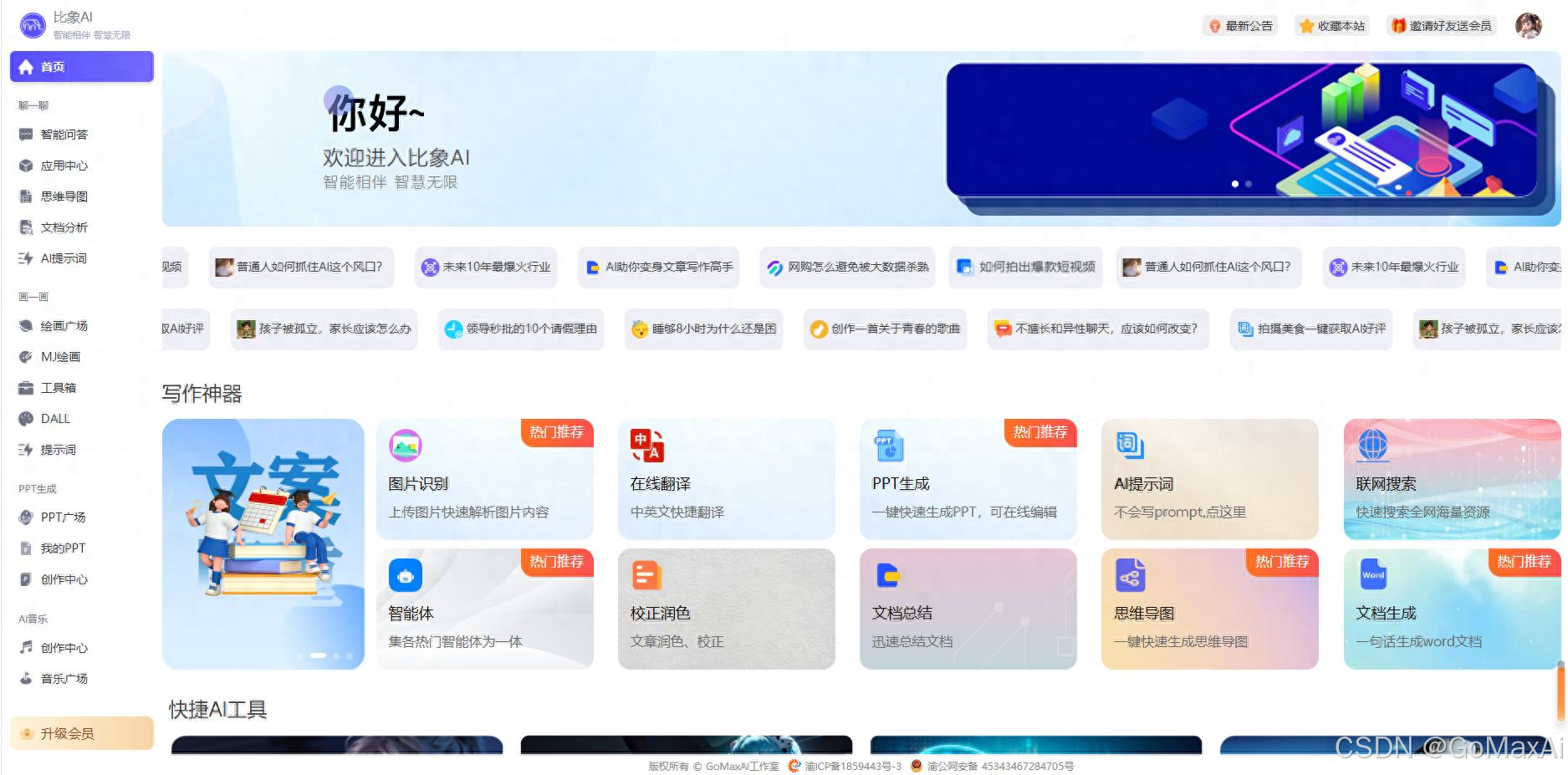
比象AI前端界面
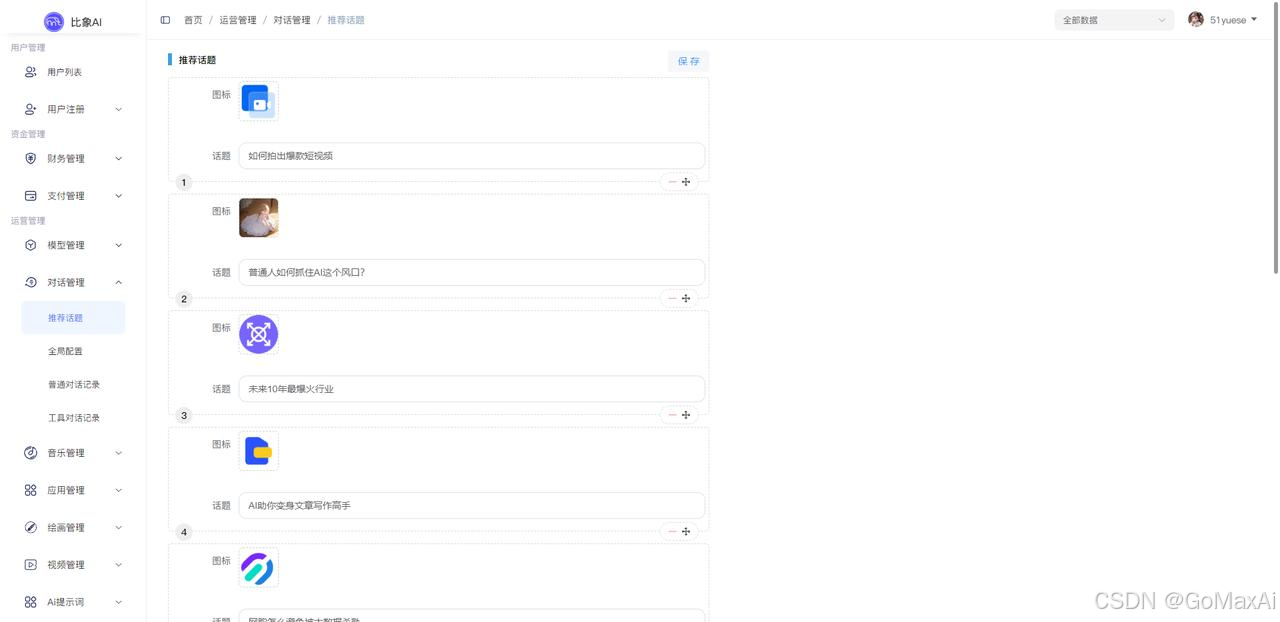
比象AI后台管理界面
《比象AI系统详情及搭建部署文档》:「链接」点击获取
系统优势:
独立移动端:用uniapp单独开发的移动端,非PC端自适应。
支持四个端:PC端、APP端、小程序端、H5端界面风格新颖,更有特点。
功能完善:智能问答、应用对话、文档分析、思维导图、PPT生成、AI音乐、AI绘画、AI视频等长期迭代更新,系统上线1年半时长,一直在迭代更新。
授权方式
独立部署到用户的服务器
域名在线授权
部署准备资料
域名
服务器:最低2h2g即可支持,国内服务器带宽5M(国外服务器对带宽要求高些)对话模型的api(我们有赠送10刀的全模型中转API,支持所有模型包括不限于GPT-4o、suno-v3.5、luma-video、mj-fast、mj-relax等模型)
存储桶:推荐使用腾讯云COS(新用户开通有赠送存储量,也可以直接使用本地存储)
微信已认证服务号:用于微信扫码登录的(如果不需要扫码登录可以不要)
微信商店号:需要开能Native支付和JSapi支付(如果不需要微信官方支付可以不要)
其他:短信,邮箱,百度统计,百度翻译,百度敏感词,四方支付等可选

















 402
402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









