




Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。
Ollama 支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。
Ollama 提供对模型量化的支持,可以显著降低显存要求,使得在普通家用计算机上运行大型模型成为可能。
Ollama简介
Ollama 是一个开源的大型语言模型(LLM)平台,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。
Ollama 提供了一个简单的方式来加载和使用各种预训练的语言模型,支持文本生成、翻译、代码编写、问答等多种自然语言处理任务。
Ollama 的特点在于它不仅仅提供了现成的模型和工具集,还提供了方便的界面和 API,使得从文本生成、对话系统到语义分析等任务都能快速实现。
与其他 NLP 框架不同,Ollama 旨在简化用户的工作流程,使得机器学习不再是只有深度技术背景的开发者才能触及的领域。
Ollama 支持多种硬件加速选项,包括纯 CPU 推理和各类底层计算架构(如 Apple Silicon),能够更好地利用不同类型的硬件资源。
核心功能与
-
多种预训练语言模型支持
Ollama 提供了多种开箱即用的预训练模型,包括常见的 GPT、BERT 等大型语言模型。用户可以轻松加载并使用这些模型进行文本生成、情感分析、问答等任务。 -
易于集成和使用
Ollama 提供了命令行工具(CLI)和 Python SDK,简化了与其他项目和服务的集成。开发者无需担心复杂的依赖或配置,可以快速将 Ollama 集成到现有的应用中。 -
本地部署与离线使用
不同于一些基于云的 NLP 服务,Ollama 允许开发者在本地计算环境中运行模型。这意味着可以脱离对外部服务器的依赖,保证数据隐私,并且对于高并发的请求,离线部署能提供更低的延迟和更高的可控性。 -
支持模型微调与自定义
用户不仅可以使用 Ollama 提供的预训练模型,还可以在此基础上进行模型微调。根据自己的特定需求,开发者可以使用自己收集的数据对模型进行再训练,从而优化模型的性能和准确度。 -
性能优化
Ollama 关注性能,提供了高效的推理机制,支持批量处理,能够有效管理内存和计算资源。这让它在处理大规模数据时依然保持高效。 -
跨平台支持
Ollama 支持在多个操作系统上运行,包括 Windows、macOS 和 Linux。这样无论是开发者在本地环境调试,还是企业在生产环境部署,都能得到一致的体验。 -
开放源码与社区支持
Ollama 是一个开源项目,这意味着开发者可以查看源代码,进行修改和优化,也可以参与到项目的贡献中。此外,Ollama 有一个活跃的社区,开发者可以从中获取帮助并与其他人交流经验。
模型量化简介
模型量化(Model Quantization)是将深度学习模型的权重和激活值从高精度(通常是32位浮点数)转换为低精度(例如8位整数或更低)的过程。量化旨在减少模型的存储空间、提高推理速度并减少计算资源的消耗,同时尽量保持模型的性能。
主要目标:
- 减少模型大小:通过减少权重和激活值的存储位数,量化可以显著减小模型的存储空间需求。
- 提高推理速度:低精度数值(如8位整数)可以加速硬件的运算,特别是在支持低精度计算的硬件(如量化加速器、专用AI芯片)上。
- 节省计算资源:较低精度的计算可以减少内存带宽消耗,降低功耗,提升处理器的计算效率。
量化的类型:
-
权重量化(Weight Quantization):
- 将模型中的权重从32位浮点数转换为较低位数(如8位或更低)的整数。
- 常见方法包括均匀量化和非均匀量化。
-
激活量化(Activation Quantization):
- 将神经网络中的激活值(中间计算结果)进行量化。这通常与权重量化一起进行,以提高效率。
-
逐层量化与整体量化:
- 逐层量化:每一层的权重和激活使用不同的量化级别。
- 整体量化:整个模型的权重和激活采用相同的量化级别。
常见量化技术:
-
整数化(Integer Quantization):
- 将浮点数转换为整数(通常为8位整数)。这种方法在硬件加速上非常高效。
-
二值化(Binary Quantization):
- 将权重值限制为仅有两种状态(例如 -1 和 +1),极大地减少了存储和计算成本。
-
定点量化(Fixed-Point Quantization):
- 将浮点数转换为具有固定小数点位置的整数,通常在嵌入式系统中使用。
大家关心的量化后的模型会不会变“愚蠢”取决于具体的量化方法、位宽以及是否进行了优化(如量化感知训练)。
回答的连贯性和复杂性,量化后,模型可能会:
-
减少对长句的理解能力:低精度可能导致注意力机制变得不稳定,影响对长句子的建模能力,使得回复变得更短或更简单。
-
降低对复杂逻辑的推理能力:某些复杂问题的回答可能会变得更模糊,模型可能更倾向于选择通用或安全的回答,而不是深入分析问题。
示例(32位浮点 vs 8位量化):
原始模型 (32-bit):
“量子计算是基于量子力学原理的计算方式,它利用量子比特的叠加和纠缠特性,实现传统计算机无法高效完成的任务,如大规模因子分解和模拟量子系统。”8-bit 量化后:
“量子计算使用量子比特进行计算,它比传统计算机更快,适用于复杂问题。”观察: 量化后的模型可能会丢失部分细节,使回答更简略,但仍然能保持基本的可读性。
创造力和语言流畅性,如果量化过于激进(如4-bit),模型可能会:
-
变得更刻板,使用更常见的句式,减少新颖表达;
-
生成的句子可能缺乏多样性,重复较多;
-
某些低概率的词汇或短语可能无法被有效激活,导致表达变得单调。
示例(GPT-3 32-bit vs 4-bit 量化):
32-bit:
“天空中漂浮着一片紫色的云彩,仿佛是大自然用画笔随意点缀的一抹梦幻。”
4-bit:
“天空中有云,颜色很特别。”观察: 4-bit 量化后,模型的表达能力可能会受损,句子变得更短、更简单,甚至失去一些细节。
数学与逻辑推理能力,低精度计算可能会影响数值计算的稳定性,导致数学计算和逻辑推理能力下降。例如:
-
量化可能会影响 数值运算的精确性,导致计算错误;
-
低精度可能会导致 复杂推理能力下降,特别是在多步逻辑推导时。
示例(数学计算对比):
32-bit:
“3.14159265 × 2 约等于 6.283。”
8-bit:
“3.14 × 2 约等于 6.3。”
4-bit:
“3 × 2 = 6。”观察: 低位量化可能导致数值精度下降,使模型在数学计算和复杂推理上变得更容易出错。
事实性与幻觉(Hallucination)
-
量化后的模型可能会更倾向于使用 常见的回答模式,导致一些细节丢失;
-
在极端情况下(如2-bit量化),模型可能会更频繁地产生错误信息(幻觉),因为低精度计算可能会影响知识检索的准确性。
示例(事实性对比):
32-bit:
“爱因斯坦于 1879 年出生于德国乌尔姆,提出了相对论。”
8-bit:
“爱因斯坦 19 世纪出生,提出了相对论。”
4-bit:
“爱因斯坦是个科学家,和物理有关。”观察: 低位量化可能会导致知识模糊化,甚至丢失关键事实。
情感理解和共情能力,如果量化过度,模型可能:
-
无法识别细微的情感变化(如讽刺、幽默);
-
更倾向于给出中立或模板化的回答,而不是个性化回复。
示例(情感分析对比):输入:“我今天真的很不开心,感觉世界都抛弃了我。”
32-bit:
“听起来你遇到了一些困难,希望你能找到合适的支持和帮助。”
8-bit:
“我希望你能开心一点。”
4-bit:
“一切都会好起来的。”观察: 量化后的模型可能变得更刻板,失去对语境的细腻把握。
代码生成能力,对于代码生成任务,低精度可能会导致:
-
代码逻辑变得简单,减少复杂结构的使用;
-
易出现语法错误,特别是更低精度时;
-
更倾向于生成常见代码片段,而不擅长写新颖或优化过的代码。
示例(代码生成对比):
32-bit:
def fibonacci(n): if n <= 1: return n return fibonacci(n-1) + fibonacci(n-2)8-bit:
def fibonacci(n): if n <= 1: return n return n + fibonacci(n-2)4-bit:
def fibonacci(n): return n观察: 低位量化可能会导致逻辑丢失,甚至生成错误代码。
📉 量化后,模型的行为变化趋势
| 影响方面 | 轻度量化 (8-bit) | 强量化 (4-bit) | 极端量化 (2-bit) |
|---|---|---|---|
| 回答连贯性 | 可能略短,但仍流畅 | 句子更简单 | 可能变得刻板 |
| 创造力 | 仍有一定创造力 | 较少创造力 | 句式重复度高 |
| 逻辑推理 | 轻微下降 | 逻辑能力下降 | 可能出现明显错误 |
| 数学计算 | 可能小数精度下降 | 计算错误增加 | 计算能力丧失 |
| 事实性 | 仍能提供准确信息 | 细节丢失 | 可能产生幻觉 |
| 情感理解 | 仍能理解情绪 | 可能缺乏共情 | 回复可能过于模板化 |
| 代码生成 | 代码仍可用 | 可能丢失逻辑 | 代码可能错误 |
📝 结论
- 8-bit 量化:通常影响较小,仍然能保证较好的性能,不会显著变“愚蠢”。
- 4-bit 量化:影响较大,可能会降低语言表达能力、数学能力和逻辑推理能力,部分任务上表现较差。
- 2-bit 量化:基本不可用,模型会出现较大的信息丢失,甚至变得“愚蠢”。
如果你希望模型在量化后仍然保持较好的智能,建议:
- 使用量化感知训练(QAT) 来减少精度损失。
- 使用混合精度(如权重 8-bit,激活值 16-bit) 来平衡性能与准确性。
- 在低精度量化前先进行蒸馏(Knowledge Distillation),让小模型学习大模型的行为,减轻“变笨”问题。
所以,只要方法得当,模型量化后不会变“特别愚蠢”,但如果量化过度,确实会出现明显的能力下降。
Ollama 安装
Ollama 支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。
Ollama 对硬件要求不高,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。
- CPU:多核处理器(推荐 4 核或以上)。
- GPU:如果你计划运行大型模型或进行微调,推荐使用具有较高计算能力的 GPU(如 NVIDIA 的 CUDA 支持)。
- 内存:至少 8GB RAM,运行较大模型时推荐 16GB 或更高。
- 存储:需要足够的硬盘空间来存储预训练模型,通常需要 10GB 至数百 GB 的空间,具体取决于模型的大小。
- 软件要求:确保系统上安装了最新版本的 Python(如果打算使用 Python SDK)。
Ollama 官方下载地址:https://ollama.com/download。
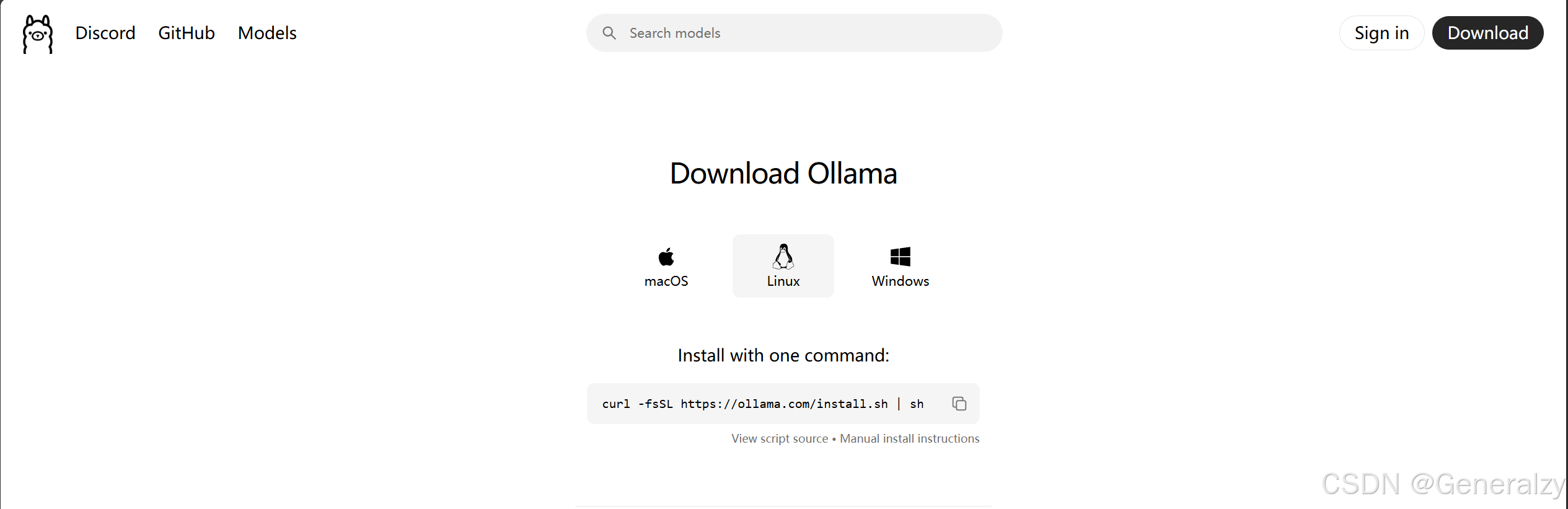
我们可以根据不同的系统下载对应的包。
Windows 安装
下载适用于 Windows 的安装程序,下载完成后,双击安装程序并按照提示完成安装。
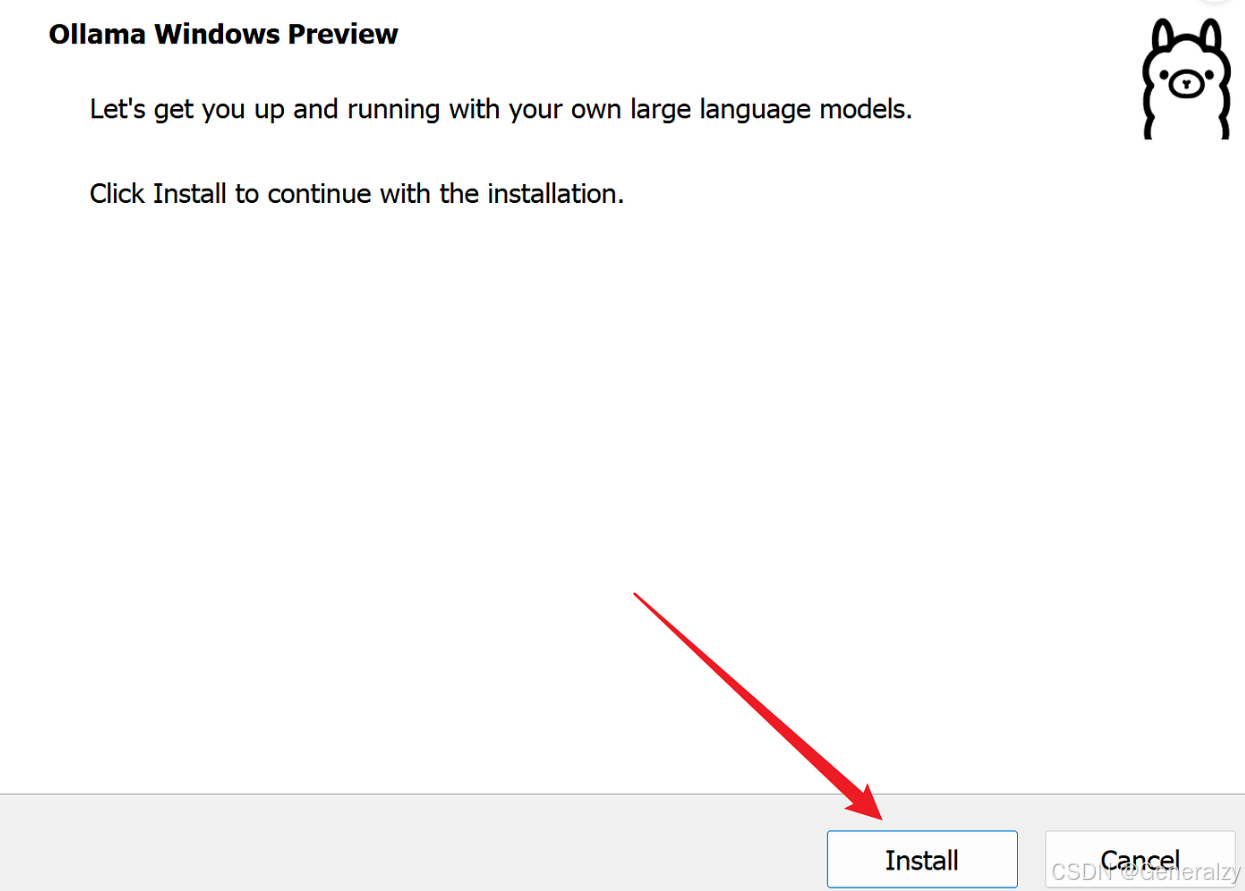
然后,打开命令提示符或 PowerShell,输入以下命令验证安装是否成功:
ollama --version
如果显示版本号,则说明安装成功。
如果需要将 Ollama 安装到非默认路径,可以在安装时通过命令行指定路径(OllamaSetup.exe是安装程序,而不是Ollama应用程序),例如:
OllamaSetup.exe /DIR="d:\some\location"
这样可以将 Ollama 安装到指定的目录。
Linux 安装
Linux 下可以使用一键安装脚本,我们打开终端,运行以下命令:
curl -fsSL https://ollama.com/install.sh | bash
安装完成后,通过以下命令验证:
ollama --version
如果显示版本号,则说明安装成功。
如果你的linux因为不可抗原因无法联网,那么你可以按照如下离线安装:
-
github拉取安装包
-
解压:
tar -xzf ollama-linux-amd64.tgz -
创建ollama.service文件
vi /etc/systemd/system/ollama.service [Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/opt/app/middles/ollama/bin/ollama serve User=root Group=root Restart=always RestartSec=3 Environment="PATH=$PATH" #指定模型存储位置,可以直接在外网下载好模型,打包解压到内网的ollama的模型目录下,就能实现离线安装了 Environment="OLLAMA_MODELS=/opt/app/middles/ollama/models" #解决ollama无法访问的问题 Environment="OLLAMA_HOST=0.0.0.0:11434" [Install] WantedBy=default.target #修改完之后,刷新 systemctl daemon-reload -
ollama启动相关命令
systemctl enable ollama systemctl start ollama systemctl status ollama systemctl stop ollama systemctl restart ollama -
配置全局环境变量
vi /etc/profile.d/ollama.sh #ollama.sh内容如下 PATH=$PATH:/opt/app/middles/ollama/bin export PATH #刷新 source /etc/profile
Docker 安装
官方 Docker 镜像 ollama/ollama 可在 Docker Hub 上获取:https://hub.docker.com/r/ollama/ollama。
拉取 Docker 镜像:
docker pull ollama/ollama
运行容器:
docker run -p 11434:11434 ollama/ollama
访问 http://localhost:11434 即可使用 Ollama。
pip 安装
Ollama 提供了 Python SDK,可以让我们能够在 Python 环境中与本地运行的模型进行交互。
通过 Ollama 的 Python SDK 能够轻松地将自然语言处理任务集成到 Python 项目中,执行各种操作,如文本生成、对话生成、模型管理等,且不需要手动调用命令行。
使用 pip 安装Ollama 的 Python SDK,
pip install ollama
在使用 Python SDK 之前,确保 Ollama 本地服务已经启动。
Ollama 模型文件Modelfile
如同Dockerfile一样,Ollama也有自己独属的Modelfile。
- Modelfile 不区分大小写。在示例中,使用大写指令是为了更容易区分它与参数。
- 指令可以按任意顺序排列。在示例中,FROM 指令放在首位是为了保持可读性。
基本格式
Modelfile 的格式:
# comment
INSTRUCTION arguments
| Instruction | Description |
|---|---|
| FROM (required) | Defines the base model to use. |
| PARAMETER | Sets the parameters for how Ollama will run the model. |
| TEMPLATE | The full prompt template to be sent to the model. |
| SYSTEM | Specifies the system message that will be set in the template. |
| ADAPTER | Defines the (Q)LoRA adapters to apply to the model. |
| LICENSE | Specifies the legal license. |
| MESSAGE | Specify message history. |
| 指令 | 描述 |
|---|---|
| FROM (必需) | 定义要使用的基础模型。 |
| PARAMETER | 设置Ollama运行模型时的参数。 |
| TEMPLATE | 要发送给模型的完整提示模板。 |
| SYSTEM | 指定将在模板中设置的系统消息。 |
| ADAPTER | 定义要应用于模型的(Q)LoRA适配器。 |
| LICENSE | 指定法律许可。 |
| MESSAGE | 指定消息历史记录。 |
Modelfile 示例:
# 导入llama3.2模型
FROM llama3.2
# 设置温度为1 [温度越高,创造力越强;温度越低,连贯性越好]
PARAMETER temperature 1
# 设置上下文窗口大小为4096,这控制着LLM可以作为上下文使用多少个token来生成下一个token
PARAMETER num_ctx 4096
# 设置自定义的系统消息,以指定聊天助手的行为
# 你是超级马里奥兄弟中的马里奥,担任助手角色。
SYSTEM You are Mario from super mario bros, acting as an assistant.
要使用这模型只需要:
- 将其保存为文件(例如 Modelfile)
ollama create choose-a-model-name -f Modelfile文件的位置,比如"./Modelfile"。ollama run choose-a-model-name- 开始使用模型!
要查看给定模型的Modelfile,请使用ollama show --modelfile命令。
FROM(必需)
FROM 指令定义了在创建模型时要使用的基础模型。
FROM <model name>:<tag>
基于现有模型构建:
FROM llama3.2
从Safetensors模型构建(huggingface使用Safetensors结构):
FROM <model directory>
模型目录应包含支持架构的 Safetensors 权重。
目前支持的模型架构: * Llama(包括 Llama 2、Llama 3、Llama 3.1 和 Llama 3.2) * Mistral(包括 Mistral 1、Mistral 2 和 Mixtral) * Gemma(包括 Gemma 1 和 Gemma 2) * Phi3
从GGUF文件构建:
FROM ./ollama-model.gguf
GGUF 文件的位置应指定为绝对路径或相对于 Modelfile 的位置。
PARAMETER
PARAMETER 指令定义了一个在运行模型时可以设置的参数。
PARAMETER <parameter> <parametervalue>
当前支持的参数和值:
| Parameter | Description | Value Type | Example Usage |
|---|---|---|---|
| mirostat | Enable Mirostat sampling for controlling perplexity. (default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0) | int | mirostat 0 |
| mirostat_eta | Influences how quickly the algorithm responds to feedback from the generated text. A lower learning rate will result in slower adjustments, while a higher learning rate will make the algorithm more responsive. (Default: 0.1) | float | mirostat_eta 0.1 |
| mirostat_tau | Controls the balance between coherence and diversity of the output. A lower value will result in more focused and coherent text. (Default: 5.0) | float | mirostat_tau 5.0 |
| num_ctx | Sets the size of the context window used to generate the next token. (Default: 2048) | int | num_ctx 4096 |
| repeat_last_n | Sets how far back for the model to look back to prevent repetition. (Default: 64, 0 = disabled, -1 = num_ctx) | int | repeat_last_n 64 |
| repeat_penalty | Sets how strongly to penalize repetitions. A higher value (e.g., 1.5) will penalize repetitions more strongly, while a lower value (e.g., 0.9) will be more lenient. (Default: 1.1) | float | repeat_penalty 1.1 |
| temperature | The temperature of the model. Increasing the temperature will make the model answer more creatively. (Default: 0.8) | float | temperature 0.7 |
| seed | Sets the random number seed to use for generation. Setting this to a specific number will make the model generate the same text for the same prompt. (Default: 0) | int | seed 42 |
| stop | Sets the stop sequences to use. When this pattern is encountered the LLM will stop generating text and return. Multiple stop patterns may be set by specifying multiple separate stop parameters in a modelfile. | string | stop “AI assistant:” |
| tfs_z | Tail free sampling is used to reduce the impact of less probable tokens from the output. A higher value (e.g., 2.0) will reduce the impact more, while a value of 1.0 disables this setting. (default: 1) | float | tfs_z 1 |
| num_predict | Maximum number of tokens to predict when generating text. (Default: 128, -1 = infinite generation, -2 = fill context) | int | num_predict 42 |
| top_k | Reduces the probability of generating nonsense. A higher value (e.g. 100) will give more diverse answers, while a lower value (e.g. 10) will be more conservative. (Default: 40) | int | top_k 40 |
| top_p | Works together with top-k. A higher value (e.g., 0.95) will lead to more diverse text, while a lower value (e.g., 0.5) will generate more focused and conservative text. (Default: 0.9) | float | top_p 0.9 |
| min_p | Alternative to the top_p, and aims to ensure a balance of quality and variety. The parameter p represents the minimum probability for a token to be considered, relative to the probability of the most likely token. For example, with p=0.05 and the most likely token having a probability of 0.9, logits with a value less than 0.045 are filtered out. (Default: 0.0) | float | min_p 0.05 |
| 参数 | 描述 | 值类型 | 示例用法 |
|---|---|---|---|
| mirostat | 启用Mirostat采样来控制困惑度。(默认: 0, 0 = 禁用, 1 = Mirostat, 2 = Mirostat 2.0) | int | mirostat 0 |
| mirostat_eta | 影响算法对生成文本反馈的响应速度。较低的学习率会导致调整较慢,而较高的学习率会使算法反应更快。(默认: 0.1) | float | mirostat_eta 0.1 |
| mirostat_tau | 控制输出的连贯性和多样性之间的平衡。较低的值会导致更集中的连贯文本。(默认: 5.0) | float | mirostat_tau 5.0 |
| num_ctx | 设置生成下一个token时使用的上下文窗口大小。(默认: 2048) | int | num_ctx 4096 |
| repeat_last_n | 设置模型回溯的范围,以防止重复。(默认: 64, 0 = 禁用, -1 = num_ctx) | int | repeat_last_n 64 |
| repeat_penalty | 设置惩罚重复内容的强度。较高的值(例如1.5)会更强烈地惩罚重复,较低的值(例如0.9)则更宽容。(默认: 1.1) | float | repeat_penalty 1.1 |
| temperature | 模型的温度。提高温度会使模型的回答更加富有创意。(默认: 0.8) | float | temperature 0.7 |
| seed | 设置生成时使用的随机数种子。将其设置为特定的数字将使模型对相同的提示生成相同的文本。(默认: 0) | int | seed 42 |
| stop | 设置停止序列。当遇到此模式时,LLM将停止生成文本并返回。可以通过在模型文件中指定多个stop参数来设置多个停止模式。 | string | stop “AI assistant:” |
| tfs_z | 尾部自由采样用于减少输出中较不可能的token的影响。较高的值(例如2.0)会减少影响,而1.0禁用此设置。(默认: 1) | float | tfs_z 1 |
| num_predict | 生成文本时预测的最大token数。(默认: 128, -1 = 无限生成, -2 = 填充上下文) | int | num_predict 42 |
| top_k | 降低生成无意义文本的概率。较高的值(例如100)将给出更多样的答案,而较低的值(例如10)则更保守。(默认: 40) | int | top_k 40 |
| top_p | 与top-k一起工作。较高的值(例如0.95)会导致文本更多样化,而较低的值(例如0.5)会生成更集中的保守文本。(默认: 0.9) | float | top_p 0.9 |
| min_p | top_p的替代方法,旨在确保质量和多样性的平衡。参数p表示相对于最可能的token概率,token被考虑的最低概率。例如,若p=0.05且最可能的token概率为0.9,则概率小于0.045的logits将被过滤掉。(默认: 0.0) | float | min_p 0.05 |
TEMPLATE
要传递给模型的完整提示模板 TEMPLATE。它可能包括(可选)系统消息、用户消息和模型的响应。注意:语法可能是模型特定的。模板使用 Go 模板语法。
| Variable | Description |
|---|---|
{{ .System }} | The system message used to specify custom behavior. |
{{ .Prompt }} | The user prompt message. |
{{ .Response }} | The response from the model. When generating a response, text after this variable is omitted. |
举例:
TEMPLATE "你是一个友好的聊天助手。用户输入以下内容,你应该给出帮助和建议:\n{{ .Prompt }}\n请提供简洁明了的回答。"
- {{ .Prompt }}:这个是占位符,它会被实际用户输入的提示替换。例如,用户输入“如何做一个蛋糕?”时,{{ .Prompt }} 会被替换为“如何做一个蛋糕?”。
- 模板会根据用户的输入生成动态的提示内容,这样模型在运行时会根据模板的结构生成回应。
再例如:
TEMPLATE "你是一个编程专家。用户提问如下:\n{{ .Prompt }}\n请提供尽可能详细的编程解答。"
如果用户的输入是“如何用 Python 实现一个快速排序算法?”,模型将接收到的完整提示是:
你是一个编程专家。用户提问如下:
如何用 Python 实现一个快速排序算法?
请提供尽可能详细的编程解答。
SYSTEM
SYSTEM 指令指定了模板中要使用的系统消息(如果适用)。
SYSTEM """<system message>"""
SYSTEM 用于设置一个系统级别的消息,该消息在生成模型回答时对模型的行为起到指导作用。这个指令的主要目标是告知模型它的角色、语气、目标或其他行为特征。通常,SYSTEM 设定的是模型的整体角色或背景,并影响模型的行为和生成风格。
- 作用:用于设定模型的“角色”或“行为方式”,通常是全局的。
- 范围:作用于整个对话的上下文,并在每次模型生成之前被设置好。
SYSTEM 你是一个友好的编程助手,能够帮助用户解决编程问题。你的回答应该简洁且清晰。
使用场景对比:
-
SYSTEM:假设你希望模型在整个对话过程中保持一致的角色行为,SYSTEM 就非常适用。例如,你想要模型扮演一个编程助手,帮助用户解决问题,系统消息就会指定模型的整体行为。
SYSTEM 你是一个编程助手,帮助用户解决各种编程问题。请保持耐心和友善。 -
TEMPLATE:假设你希望模型根据每个用户的不同问题生成不同风格的回答,TEMPLATE 就适合用于在每次对话时构建一个带有用户问题的输入模板。例如,TEMPLATE 让你在每个问题后附加特定的说明或结构,动态填充用户输入。
TEMPLATE 你是一个编程专家。用户提问如下:\n{{ .Prompt }}\n请提供尽可能详细的编程解答。
ADAPTER
ADAPTER 指令指定了一个应应用于基础模型的微调 LoRA 适配器。适配器的值应为绝对路径或相对于 Modelfile 的路径。基础模型应使用 FROM 指令指定。如果基础模型与适配器微调时所用的基础模型不同,行为将不可预测。
Safetensor 适配器:
ADAPTER <path to safetensor adapter>
目前支持的 Safetensor 适配器: * Llama(包括 Llama 2、Llama 3 和 Llama 3.1) * Mistral(包括 Mistral 1、Mistral 2 和 Mixtral) * Gemma(包括 Gemma 1 和 Gemma 2)
GGUF 适配器:
ADAPTER ./ollama-lora.gguf
LICENSE
LICENSE 指令允许你指定与此 Modelfile 一起使用的模型的共享或分发所依据的法律许可证。
LICENSE """
<license text>
"""
MESSAGE
MESSAGE 指令允许你为模型指定消息历史,以便模型在响应时使用。通过多次使用 MESSAGE 命令来构建对话,可以引导模型以类似的方式回答。
MESSAGE <role> <message>
| Role | Description |
|---|---|
| system | Alternate way of providing the SYSTEM message for the model. |
| user | An example message of what the user could have asked. |
| assistant | An example message of how the model should respond. |
MESSAGE user Is Toronto in Canada?
MESSAGE assistant yes
MESSAGE user Is Sacramento in Canada?
MESSAGE assistant no
MESSAGE user Is Ontario in Canada?
MESSAGE assistant yes
在 Ollama 的 modelfile 中,MESSAGE 指令并不会自动添加历史对话。你需要 手动指定消息历史。也就是说,模型不会自动记住先前的对话,你需要在每次调用模型时将历史对话传递给它。
假设你和模型进行多轮对话,以下是如何手动管理消息历史的一个例子:
MESSAGE
- User: "你好!"
- Bot: "你好!请问有什么我可以帮您的吗?"
- User: "今天天气怎么样?"
这是一个对话历史,它包括了用户的提问和模型的回答。在进行下一轮对话时,你需要继续更新 MESSAGE,将新的对话加入其中:
MESSAGE
- User: "你好!"
- Bot: "你好!请问有什么我可以帮您的吗?"
- User: "今天天气怎么样?"
- Bot: "今天的天气很不错,气温大约是22°C。"
- User: "那明天呢?"
在这里,你手动将每一轮的对话(包括用户的输入和模型的输出)保留在 MESSAGE 中。每次你调用模型生成新的回复时,都将更新这个对话历史。
也可以在代码中管理对话历史,每次用户输入后,模型的响应都会被添加到消息历史中,并在下一次请求时一起传递。这样,你不需要手动修改文件,而是通过程序逻辑动态地维护消息历史。
# 初始化对话历史
message_history = []
# 用户输入
user_input = "你好!"
message_history.append(f"User: {user_input}")
# 模型回复
model_response = "你好!请问有什么我可以帮您的吗?"
message_history.append(f"Bot: {model_response}")
# 假设这是下一个用户输入
user_input = "今天天气怎么样?"
message_history.append(f"User: {user_input}")
# 在每次模型调用时将完整的消息历史传给模型
model_input = "\n".join(message_history)
response = ollama.run(model_input)
# 获取并输出模型响应
print(response)
另一种方法是为每个用户对话分配一个 会话 ID(session ID)。通过会话 ID,你可以动态地保存对话历史,并在每次请求时使用该会话历史作为上下文。这种方法适合多轮对话,并能够确保消息历史不丢失。
你可以将历史对话存储在 内存、数据库 或 缓存中,并根据每次对话动态传递历史消息。
# 会话 ID 用于标识不同用户的对话
session_id = "user_123"
# 假设你有一个保存历史对话的字典
session_history = {}
# 每个用户的历史对话保存在 session_history 中
if session_id not in session_history:
session_history[session_id] = []
# 添加用户输入到历史中
user_input = "你好!"
session_history[session_id].append(f"User: {user_input}")
# 模型回复
model_response = "你好!请问有什么我可以帮您的吗?"
session_history[session_id].append(f"Bot: {model_response}")
# 获取历史消息并传递给模型
model_input = "\n".join(session_history[session_id])
response = ollama.run(model_input)
# 获取并输出模型响应
print(response)
# 下一轮对话
user_input = "今天天气怎么样?"
session_history[session_id].append(f"User: {user_input}")
模型库
Ollama 支持在 ollama.com/library 上提供的模型列表。
以下是一些可以下载的示例模型:
| Model | Parameters | Size | Download |
|---|---|---|---|
| Llama 3.2 | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| Llama 3.1 | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | 70B | 40GB | ollama run llama3.1:70b |
| Llama 3.1 | 405B | 231GB | ollama run llama3.1:405b |
| Phi 3 Mini | 3.8B | 2.3GB | ollama run phi3 |
| Phi 3 Medium | 14B | 7.9GB | ollama run phi3:medium |
| Gemma 2 | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | 27B | 16GB | ollama run gemma2:27b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Solar | 10.7B | 6.1GB | ollama run solar |
你应该至少有 8 GB 的 RAM 来运行 7B 模型,16 GB 的 RAM 来运行 13B 模型,以及 32 GB 的 RAM 来运行 33B 模型。
自定义模型
导入基于 GGUF 的模型或适配器
如果你有一个基于 GGUF 的模型或适配器,可以将其导入 Ollama。你可以通过以下方式获取 GGUF 模型或适配器:
- 使用 Llama.cpp 中的 convert_hf_to_gguf.py 脚本将 Safetensors 模型转换为 GGUF 模型;
- 使用 Llama.cpp 中的 convert_lora_to_gguf.py 脚本将 Safetensors 适配器转换为 GGUF 适配器;或
- 从 HuggingFace 等地方下载模型或适配器
要导入 GGUF 模型,创建一个 Modelfile,内容包括:
FROM /path/to/file.gguf
对于 GGUF 适配器,创建 Modelfile,内容如下:
FROM <model name>
ADAPTER /path/to/file.gguf
在导入 GGUF 适配器时,重要的是使用与创建适配器时所用的相同基础模型。你可以使用:
- Ollama 中的模型
- GGUF 文件
- 基于 Safetensors 的模型
一旦你创建了 Modelfile,请使用 ollama create 命令来构建模型。
ollama create my-model
从 Safetensors 权重导入模型
首先,创建一个 Modelfile,其中包含一个指向你用于微调的基础模型的 FROM 命令,以及一个指向你的 Safetensors 适配器目录的 ADAPTER 命令:
FROM <base model name>
ADAPTER /path/to/safetensors/adapter/directory
确保你在 FROM 命令中使用与创建适配器时相同的基模型,否则你会得到不一致的结果。大多数框架使用不同的量化方法,因此最好使用非量化(即非 QLoRA)适配器。如果适配器与你的 Modelfile 在同一目录中,使用 ADAPTER . 来指定适配器路径。
现在从创建 Modelfile 的目录中运行 ollama create:
ollama create my-model
最后,测试模型:
ollama run my-model
Ollama 支持基于几种不同的模型架构导入适配器,包括:
- Llama(包括 Llama 2、Llama 3、Llama 3.1 和 Llama 3.2);
- Mistral(包括 Mistral 1、Mistral 2 和 Mixtral);和
- Gemma(包括 Gemma 1 和 Gemma 2)
你可以使用能够输出 Safetensors 格式适配器的微调框架或工具来创建适配器,例如:
- Hugging Face 微调框架
- Unsloth
- MLX
量化模型
量化模型可以让你以更快的速度和更少的内存消耗运行模型,但精度会有所降低。这使得你可以在更 modest 的硬件上运行模型。
Ollama 可以使用 -q/–quantize 标志与 ollama create 命令将基于 FP16 和 FP32 的模型量化为不同的量化级别。
首先,创建一个包含你希望量化的 FP16 或 FP32 基础模型的 Modelfile。
FROM /path/to/my/gemma/f16/model
使用 ollama create 来创建量化模型。
$ ollama create --quantize q4_K_M mymodel
transferring model data
quantizing F16 model to Q4_K_M
creating new layer sha256:735e246cc1abfd06e9cdcf95504d6789a6cd1ad7577108a70d9902fef503c1bd
creating new layer sha256:0853f0ad24e5865173bbf9ffcc7b0f5d56b66fd690ab1009867e45e7d2c4db0f
writing manifest
success
支持的量化方式:
- q4_0
- q4_1
- q5_0
- q5_1
- q8_0
K-means 量化方式:
- q3_K_S
- q3_K_M
- q3_K_L
- q4_K_S
- q4_K_M
- q5_K_S
- q5_K_M
- q6_K
命令行
Ollama 提供了多种命令行工具(CLI)供用户与本地运行的模型进行交互。
我们可以用 ollama --help 查看包含有哪些命令:
Large language model runner
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
stop Stop a running model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
创建模型
ollama create 用于从 Modelfile 创建模型。
ollama create mymodel -f ./Modelfile
拉取模型
ollama pull 会将ollama库中的模型拉取到本地。
ollama pull llama3.2
此命令也可以用于更新本地模型。只有差异部分会被拉取。
删除模型
ollama rm llama3.2
复制模型
ollama cp llama3.2 my-model
多行输入
对于多行输入,你可以用 “”" 包裹文本:
>>> """Hello,
... world!
... """
I'm a basic program that prints the famous "Hello, world!" message to the console.
多模态模型
多模态模型(Multimodal Models)是能够同时处理多种类型输入(如文本、图像、音频等)并生成多种类型输出(如文本描述、图像生成等)的模型。在 Ollama 中,llava 是一个典型的多模态模型,它不仅能理解文本,还能理解图像,并基于这些理解生成自然语言的输出。
ollama run llava "What's in this image? /Users/jmorgan/Desktop/smile.png"
>>> The image features a yellow smiley face, which is likely the central focus of the picture.
- 输入文本: “What’s in this image?” 这个问题是模型要回答的内容,询问的是图像中的内容是什么。
- 图像路径: “/Users/jmorgan/Desktop/smile.png” 这个路径指向本地的图像文件,模型会分析这张图像来生成回答。
将提示作为参数传递
$ ollama run llama3.2 "Summarize this file: $(cat README.md)"
Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications.
显示模型信息
查看指定模型的详细信息:
ollama show <model-name>
例如:
ollama show llama2
查看模型的依赖关系:
ollama deps <model-name>
例如:
ollama deps llama2
查看模型的配置文件:
ollama config <model-name>
例如:
ollama config llama2
列出你计算机上的模型
ollama list
列出当前已加载的模型
ollama ps
停止当前正在运行的模型
ollama stop llama3.2
服务管理
启动 Ollama 服务以在后台运行:
ollama serve
停止正在运行的 Ollama 服务:
ollama stop
重启 Ollama 服务:
ollama restart
查看日志
查看 Ollama 的日志信息:
ollama logs
清理缓存
清理 Ollama 的缓存:
ollama clean
系统信息
查看 Ollama 的系统信息:
ollama system
查看模型的资源使用情况:
ollama resources <model-name>
例如:
ollama resources llama2
查看模型的性能指标:
ollama perf <model-name>
例如:
ollama perf llama2
检查模型状态
检查指定模型的状态:
ollama status <model-name>
例如:
ollama status llama2
导入与导出
将模型导出为文件:
ollama export <model-name> <output-file>
例如:
ollama export llama2 llama2.tar
从文件导入模型:
ollama import <input-file>
例如:
ollama import llama2.tar
启动 Ollama
ollama serve 用于在不运行桌面应用程序的情况下启动 Ollama。
REST API
Ollama 拥有一个用于运行和管理模型的 REST API。
在使用 API 之前,需要确保 Ollama 服务正在运行。可以通过以下命令启动服务:
ollama serve
默认情况下,服务会运行在 http://localhost:11434。
API
ollama有如下约定:
-
模型名称遵循
model:tag格式,其中model可以有一个可选的命名空间,例如example/model。一些示例包括orca-mini:3b-q4_1和llama3:70b。标签是可选的,如果未提供,则默认为latest。标签用于标识特定版本。 -
所有持续时间都以纳秒为单位返回。
-
某些端点以 JSON 对象的形式流式传输响应。可以通过为这些端点提供
{"stream": false}来禁用流式传输。
Ollama 提供了以下主要 API !
生成文本(Generate Text)
-
API:POST /api/generate
-
功能:向模型发送提示词(prompt),并获取生成的文本。
-
请求格式:
{ "model": "<model-name>", // 模型名称 "prompt": "<input-text>", // 输入的提示词 "stream": false, // 是否启用流式响应(默认 false) "options": { // 可选参数 "temperature": 0.7, // 温度参数 "max_tokens": 100 // 最大 token 数 } } -
响应格式:
{ "response": "<generated-text>", // 生成的文本 "done": true // 是否完成 }
聊天(Chat)
-
API:POST /api/chat
-
功能:支持多轮对话,模型会记住上下文。
-
请求格式:
{ "model": "<model-name>", // 模型名称 "messages": [ // 消息列表 { "role": "user", // 用户角色 "content": "<input-text>" // 用户输入 } ], "stream": false, // 是否启用流式响应 "options": { // 可选参数 "temperature": 0.7, "max_tokens": 100 } } -
响应格式:
{ "message": { "role": "assistant", // 助手角色 "content": "<generated-text>" // 生成的文本 }, "done": true }
列出本地模型(List Models)
-
API:GET /api/tags
-
功能:列出本地已下载的模型。
-
响应格式:
{ "models": [ { "name": "<model-name>", // 模型名称 "size": "<model-size>", // 模型大小 "modified_at": "<timestamp>" // 修改时间 } ] }
拉取模型(Pull Model)
-
API:POST /api/pull
-
功能:从模型库中拉取模型。
-
请求格式:
{ "name": "<model-name>" // 模型名称 } -
响应格式:
{ "status": "downloading", // 下载状态 "digest": "<model-digest>" // 模型摘要 }
其它接口
其他接口如,词嵌入,流式对话…请参考官方文档:https://ollama.readthedocs.io/api/#generate-a-completion
Ollama Python 使用
Ollama 提供了 Python SDK,可以让我们能够在 Python 环境中与本地运行的模型进行交互。
通过 Ollama 的 Python SDK 能够轻松地将自然语言处理任务集成到 Python 项目中,执行各种操作,如文本生成、对话生成、模型管理等,且不需要手动调用命令行。
在使用 Python SDK 之前,确保 Ollama 本地服务已经启动。
你可以使用命令行工具来启动它:
ollama serve
启动本地服务后,Python SDK 会与本地服务进行通信,执行模型推理等任务。
使用 Ollama 的 Python SDK 进行推理
安装了 SDK 并启动了本地服务后,我们就可以通过 Python 代码与 Ollama 进行交互。
首先,从 ollama 库中导入 chat 和 ChatResponse:
from ollama import chat
from ollama import ChatResponse
通过 Python SDK,你可以向指定的模型发送请求,生成文本或对话:
from ollama import chat
from ollama import ChatResponse
response: ChatResponse = chat(model='deepseek-coder', messages=[
{
'role': 'user',
'content': '你是谁?',
},
])
# 打印响应内容
print(response['message']['content'])
# 或者直接访问响应对象的字段
#print(response.message.content)
执行以上代码,输出结果为:
我是由中国的深度求索(DeepSeek)公司开发的编程智能助手,名为DeepCoder。我可以帮助你解答与计算机科学相关的问题和任务。如果你有任何关于这方面的话题或者需要在某个领域进行学习或查询信息时请随时提问!
llama SDK 还支持流式响应,我们可以在发送请求时通过设置 stream=True 来启用响应流式传输。
from ollama import chat
stream = chat(
model='deepseek-coder',
messages=[{'role': 'user', 'content': '你是谁?'}],
stream=True,
)
# 逐块打印响应内容
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
自定义客户端
你还可以创建自定义客户端,来进一步控制请求配置,比如设置自定义的 headers 或指定本地服务的 URL。
通过 Client,你可以自定义请求的设置(如请求头、URL 等),并发送请求。
from ollama import Client
client = Client(
host='http://localhost:11434',
headers={'x-some-header': 'some-value'}
)
response = client.chat(model='deepseek-coder', messages=[
{
'role': 'user',
'content': '你是谁?',
},
])
print(response['message']['content'])
如果你希望异步执行请求,可以使用 AsyncClient 类,适用于需要并发的场景。
import asyncio
from ollama import AsyncClient
async def chat():
message = {'role': 'user', 'content': '你是谁?'}
response = await AsyncClient().chat(model='deepseek-coder', messages=[message])
print(response['message']['content'])
asyncio.run(chat())
异步客户端支持与传统的同步请求一样的功能,唯一的区别是请求是异步执行的,可以提高性能,尤其是在高并发场景下。
如果你需要异步地处理流式响应,可以通过将 stream=True 设置为异步生成器来实现。
import asyncio
from ollama import AsyncClient
async def chat():
message = {'role': 'user', 'content': '你是谁?'}
async for part in await AsyncClient().chat(model='deepseek-coder', messages=[message], stream=True):
print(part['message']['content'], end='', flush=True)
asyncio.run(chat())
这里,响应将逐部分地异步返回,每部分都可以即时处理。
常用 API 方法
Ollama Python SDK 提供了一些常用的 API 方法,用于操作和管理模型。
-
chat方法
与模型进行对话生成,发送用户消息并获取模型响应:ollama.chat(model='llama3.2', messages=[{'role': 'user', 'content': 'Why is the sky blue?'}]) -
generate方法
用于文本生成任务。与chat方法类似,但是它只需要一个prompt参数:ollama.generate(model='llama3.2', prompt='Why is the sky blue?') -
list方法
列出所有可用的模型:ollama.list() -
show方法
显示指定模型的详细信息:ollama.show('llama3.2') -
create方法
从现有模型创建新的模型:ollama.create(model='example', from_='llama3.2', system="You are Mario from Super Mario Bros.") -
copy方法
复制模型到另一个位置:ollama.copy('llama3.2', 'user/llama3.2') -
delete方法
删除指定模型:ollama.delete('llama3.2') -
pull方法
从远程仓库拉取模型:ollama.pull('llama3.2') -
push方法
将本地模型推送到远程仓库:ollama.push('user/llama3.2') -
embed方法
生成文本嵌入:ollama.embed(model='llama3.2', input='The sky is blue because of rayleigh scattering') -
ps方法
查看正在运行的模型列表:ollama.ps()
Ollama SDK 会在请求失败或响应流式传输出现问题时抛出错误。
我们可以使用 try-except 语句来捕获这些错误,并根据需要进行处理。
model = 'does-not-yet-exist'
try:
response = ollama.chat(model)
except ollama.ResponseError as e:
print('Error:', e.error)
if e.status_code == 404:
ollama.pull(model)
Ollama Open WebUI
Open WebUI 用户友好的 AI 界面(支持 Ollama、OpenAI API 等)。
Open WebUI 支持多种语言模型运行器(如 Ollama 和 OpenAI 兼容 API),并内置了用于检索增强生成(RAG)的推理引擎,使其成为强大的 AI 部署解决方案。
Open WebUI 可自定义 OpenAI API URL,连接 LMStudio、GroqCloud、Mistral、OpenRouter 等。
Open WebUI 管理员可创建详细的用户角色和权限,确保安全的用户环境,同时提供定制化的用户体验。
Open WebUI 支持桌面、笔记本电脑和移动设备,并提供移动设备上的渐进式 Web 应用(PWA),支持离线访问。
开源地址:https://github.com/open-webui/open-webui
官方文档:https://docs.openwebui.com/
Open WebUI 提供多种安装方式,包括通过 Python pip 安装、Docker 安装、Docker Compose、Kustomize 和 Helm 等。
最简单的当然还是pip安装,Open WebUI 可以通过 Python 的包安装程序 pip 进行安装,在开始安装之前,请确保您使用的是 Python 3.11,以避免可能出现的兼容性问题。
打开您的终端,运行以下命令以安装 Open WebUI:
pip install open-webui
安装完成后,您可以通过以下命令启动 Open WebUI:
open-webui serve
启动后,Open WebUI 服务器将运行在 http://localhost:8080,您可以通过浏览器访问该地址来使用 Open WebUI。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











