




目录
引子
在实际工程中,我们经常能看到这样一种局面:只要业务功能能跑,后端性能就被默认当成“够用”;只要 QPS 没飙到瓶颈,大家就习惯把优化交给编译器、语言运行时,甚至云厂商。与此同时,框架的选择往往停留在“大家都用 net/http”“官方默认应该最稳”,而很少有人真正去拆解一套 HTTP 服务器为什么快、为什么慢。
直到你认真研究 fasthttp,你才会意识到:性能并不是靠运气,也不是靠“Go 足够快”这种错觉,而是一套套具体的技术手段堆出来的。fasthttp 并不是一个为了让你日常使用更舒服的框架,它从设计之初就带着明确目的——牺牲易用性、牺牲优雅、牺牲标准化,换取极致的吞吐能力和尽可能低的 GC 开销。它像一个把血气全加在攻击力上的“邪修”,但它体内蕴藏的技巧,却是每一个工程师在构建高性能系统时都值得学习的。
这篇文章并不是教你“使用 fasthttp”,也不是比较各框架的优劣。我更想做的是借助 fasthttp 这个极端范例,拆解它背后真正有价值的东西:零拷贝、对象池化、轻量事件循环、手写协议解析、无接口调用链、按字节处理 header、避免 goroutine per request 模型……这些技巧才是支撑它性能的根本,也是任何语言、任何服务器框架都可以借鉴的通用武学。
换句话说,我们不是学习 fasthttp,我们是借着 fasthttp 的“狠活”,来理解高性能背后的硬道理。弄懂这些,你再回过头构建自己的系统,不管是写网关、RPC 服务器、代理、日志管道,还是高并发面向连接的服务,都能做得更快、更稳、更省资源。
接下来,我们不讨论 API,不讨论使用方式,只讨论 fasthttp 之所以快的那些关键技术。真正的价值,就藏在这些底层细节里。
轻量事件循环
一个典型的 HTTP 服务应该如图所示:
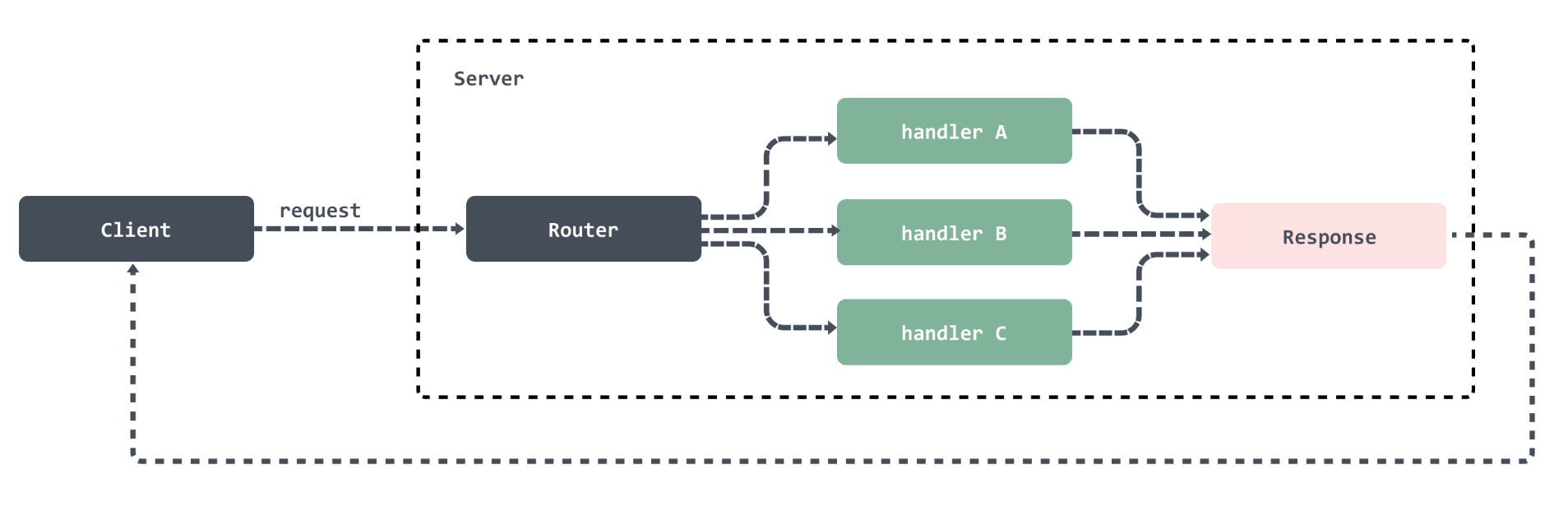
基于HTTP构建的服务标准模型包括两个端,客户端(Client)和服务端(Server)。HTTP 请求从客户端发出,服务端接受到请求后进行处理然后将响应返回给客户端。所以http服务器的工作就在于如何接受来自客户端的请求,并向客户端返回响应。
golang内置的net/http对http请求的处理流程大概是这样的:
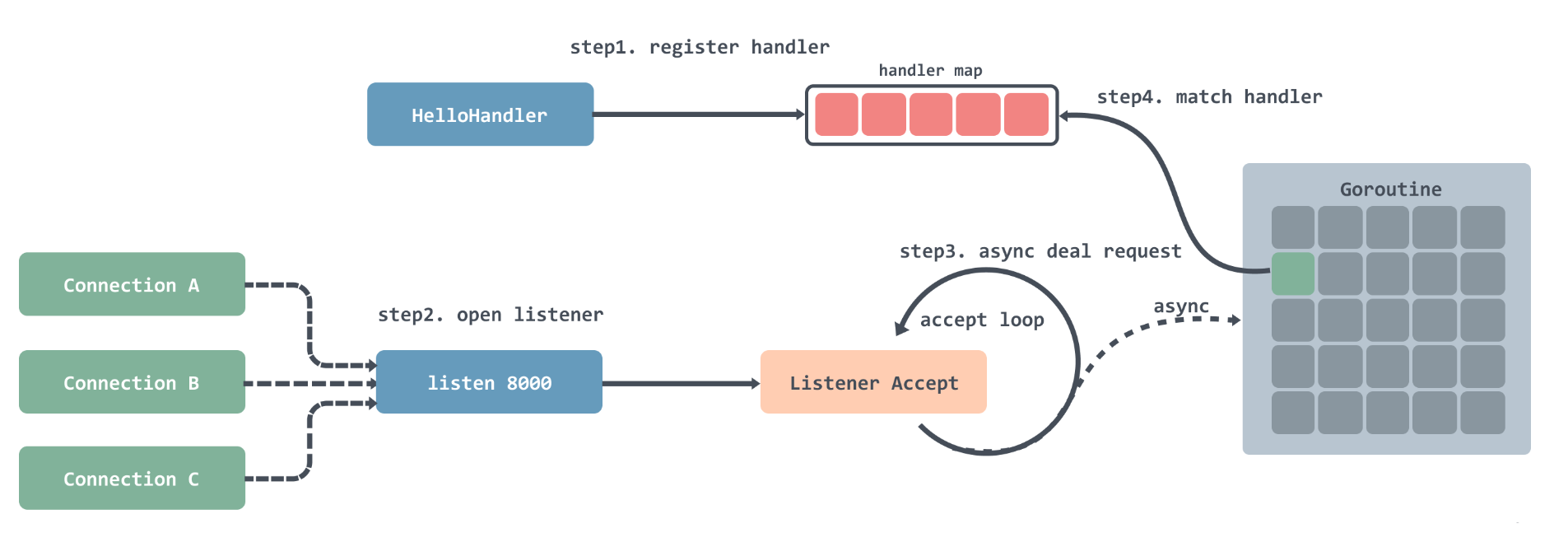
- 注册处理器到一个 hash 表中,可以通过键值路由匹配;
- 注册完之后就是开启循环监听,每监听到一个连接就会创建一个 Goroutine;
- 在创建好的 Goroutine 里面会循环的等待接收请求数据,然后根据请求的地址去处理器路由表中匹配对应的处理器,然后将请求交给处理器处理;
这样做在连接数比较少的时候是没什么问题的,但是在连接数非常多的时候,每个连接都会创建一个 Goroutine 就会给系统带来一定的压力。这也就造成了 net/http在处理高并发时的瓶颈。
从 Go 1.22 起,官方对 ServeMux 进行了大规模升级,引入了分段路径匹配、通配符、方法路由、主机路由等现代特性,并重构为基于路由树(routingNode)的结构。不过,即便路由器本身更现代,整体处理模型依然遵循“连接即 goroutine”的传统设计:每个连接由独立 goroutine 驱动,goroutine 内阻塞式收发、阻塞式 handler 执行、阻塞式写回。调度、栈扩张、GC 压力、handler 之间无法共享 cache locality 等问题依旧存在。
正是因为这一整套“线程式”的抽象在高负载场景下的系统开销不可避免,也就是为什么更追求极致性能的实现开始走向完全不同的方向——fasthttp 的轻量事件循环模型。
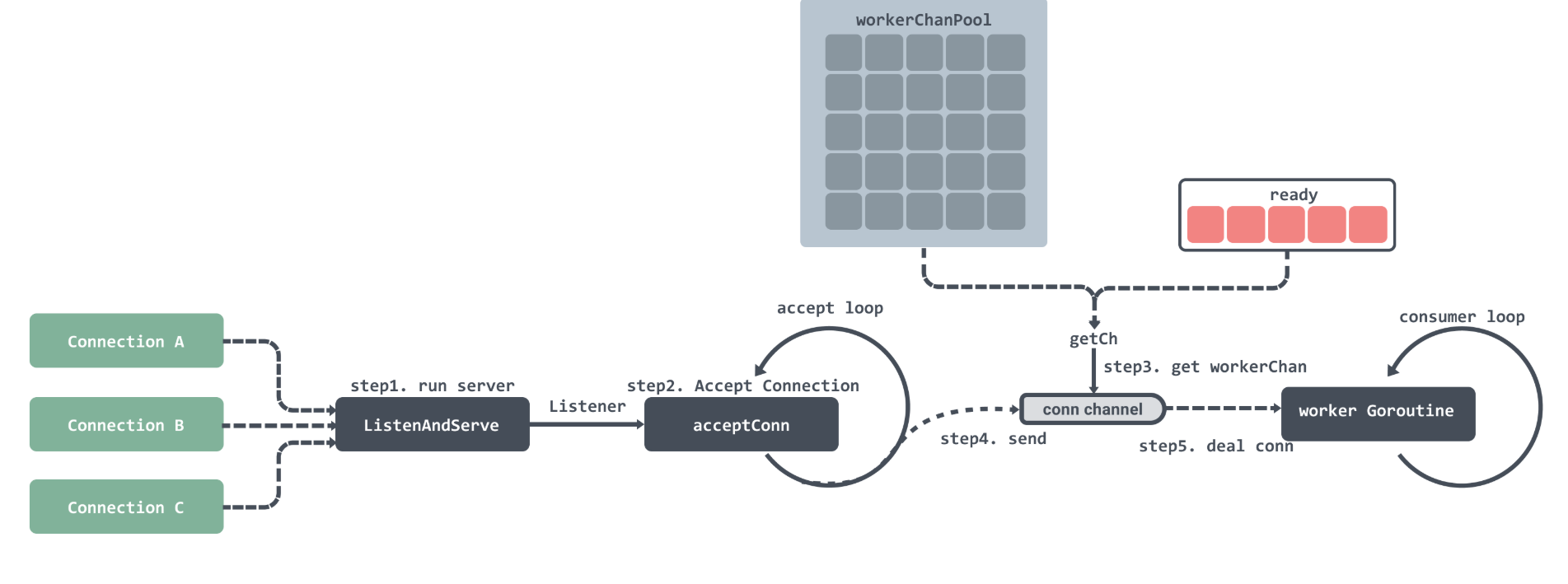
fasthttp 的服务端启动后,会进入一个持续 Accept 的循环,不断从监听 socket 中取出新连接。每当有请求到来时,fasthttp 不会像 net/http 那样为每个连接创建一个新的 goroutine,而是将请求以任务的形式投递到内部的 workerPool 中。
workerPool 内部维护着一组可复用的 worker,每个 worker 都对应一个独立的 goroutine,并拥有一个专属的 workerChan 用于接收任务。当有请求到达时,server 会优先尝试从 ready 队列中取出一个空闲 worker,将任务投递到它的 workerChan;如果 ready 队列为空且当前 worker 数尚未达到 MaxWorkersCount,则会按需创建新的 worker;若 worker 数已达上限,则请求会被直接拒绝。
每个 worker 的 goroutine 会持续从自己的 workerChan 中读取任务,对请求进行解析、处理、写回,再将自身放回 ready 队列以便复用。因此 workerChan 本质上是“worker 的输入队列”,而不是连接的生命周期对象。默认情况下,fasthttp 允许最多 256×1024 个 worker 并发处理任务,使其在极高并发负载下依然能够维持稳定的吞吐与延迟表现。
我们可以前往github去下载fasthttp的代码看到workerPool/Chan的具体实现:https://github.com/valyala/fasthttp
首先梳理下这些组件之间的关系:
┌──────────────────────────────────────┐
│ Server Loop │
│ (Accept + netpoll) │
└──────────────────────────────────────┘
|
| new request (task)
v
┌──────────────────────────────────────────────┐
│ workerPool │
│ │
│ ┌──────────────────────────────────────┐ │
│ │ readyQueue │ │
│ │ (queue of idle workerChans) │ │
│ └──────────────────────────────────────┘ │
│ ^ │
│ │ worker finishes │
│ │ and returns to ready │
│ │ │
└──────────────┬──────┴─────────────────────────┘
│ get/allocate workerChan
v
┌─────────────────────────────────────────────────────┐
│ workerChan │
│ (chan *workerTask, each worker owns one) │
└─────────────────────────────────────────────────────┘
│ task pushed into workerChan
v
┌───────────────────────────────────────────────────┐
│ worker goroutine │
│ ──────────────────────────────────────────────── │
│ for { │
│ task := <- workerChan │
│ handleRequest(task.ctx) │
│ recycle buffers │
│ put workerChan back to readyQueue │
│ } │
└───────────────────────────────────────────────────┘
- Server Loop / netpoll:统一处理 Accept 和 IO 事件,但不会为每个连接创建 goroutine,而是将“请求任务”投递到 workerPool。
- workerPool:维护一组可复用 worker,每个 worker 一个 goroutine。
- readyQueue:存放空闲 workerChan。
- workerChan:worker 的请求任务队列(chan *workerTask),不是“连接对象”。
- worker goroutine:独立执行任务,处理完返回 readyQueue,形成 worker 复用。
这套模型完美避免了 net/http “连接=goroutine” 的巨大开销。
现在将目光聚焦于两个核心文件:server.go和workerpool.go
下面这段代码展示了 fasthttp 实现高性能的核心组件之一:workerPool。它是整个请求执行模型的中心,通过复用 worker goroutine、限制最大并发数、回收闲置 worker 来构建一个轻量、高 cache locality 的执行管线。
// workerPool 是 fasthttp 的核心事件循环池
// 负责管理 worker goroutine、分发连接、复用 workerChan
type workerPool struct {
workerChanPool sync.Pool // pool 用于复用 workerChan 对象,避免频繁分配内存
Logger Logger // 日志对象
// WorkerFunc 是处理每个连接的函数
// 注意:它必须处理连接但不能关闭连接
WorkerFunc ServeHandler
stopCh chan struct{} // 停止信号 channel,用于优雅关闭 workerPool
connState func(net.Conn, ConnState) // 连接状态回调,可用于监控连接生命周期
ready []*workerChan // 空闲 workerChan 队列,用于复用
MaxWorkersCount int // 最大 worker 数量,避免 goroutine 无限增长
MaxIdleWorkerDuration time.Duration // worker 空闲多久后回收
workersCount int // 当前已创建 worker 数量
lock sync.Mutex // 保护 ready 队列和 workersCount
LogAllErrors bool // 是否打印所有错误
mustStop bool // 标记 pool 是否强制停止
}
// workerChan 是每个 worker 的输入 channel
// 每个 workerChan 都有一个 chan net.Conn,用来接收任务
type workerChan struct {
lastUseTime time.Time // 最近一次使用时间,用于空闲回收
ch chan net.Conn // 传入连接任务的 channel
}
// Start 启动 workerPool
func (wp *workerPool) Start() {
if wp.stopCh != nil { // 如果已经启动,则直接返回
return
}
wp.stopCh = make(chan struct{})
stopCh := wp.stopCh
// 初始化 workerChanPool,按需创建 workerChan
wp.workerChanPool.New = func() any {
return &workerChan{
ch: make(chan net.Conn, workerChanCap), // workerChan 的缓冲大小根据 GOMAXPROCS 决定
}
}
// 后台 goroutine 定期清理空闲 worker
go func() {
var scratch []*workerChan // 临时 slice,减少分配
for {
wp.clean(&scratch) // 清理 idle worker
select {
case <-stopCh: // 收到停止信号则退出
return
default:
time.Sleep(wp.getMaxIdleWorkerDuration()) // sleep 到下次清理
}
}
}()
}
// Serve 分发一个 net.Conn 到 workerPool
func (wp *workerPool) Serve(c net.Conn) bool {
ch := wp.getCh() // 获取一个空闲 workerChan
if ch == nil { // 超过最大 worker 数量,无法获取 workerChan
return false
}
ch.ch <- c // 将连接投递给 workerChan
return true
}
// workerChan 缓冲大小配置
var workerChanCap = func() int {
if runtime.GOMAXPROCS(0) == 1 {
// GOMAXPROCS=1 时使用阻塞 channel,Serve 直接切换到 WorkerFunc,可提升单核性能
return 0
}
// GOMAXPROCS>1 时使用非阻塞 channel,避免 Serve 阻塞影响 Accept
return 1
}()
// getCh 获取或创建一个 workerChan
func (wp *workerPool) getCh() *workerChan {
var ch *workerChan
createWorker := false
// 上锁保护 ready 队列
wp.lock.Lock()
ready := wp.ready
n := len(ready) - 1
if n < 0 {
// 没有空闲 worker
if wp.workersCount < wp.MaxWorkersCount {
// 允许创建新 worker
createWorker = true
wp.workersCount++
}
} else {
// 从 ready 队列中取出空闲 workerChan
ch = ready[n]
ready[n] = nil
wp.ready = ready[:n]
}
wp.lock.Unlock()
if ch == nil {
// 没有可用 worker 且不允许创建新 worker
if !createWorker {
return nil
}
// 从对象池获取 workerChan
vch := wp.workerChanPool.Get()
ch = vch.(*workerChan)
// 启动新的 worker goroutine
go func() {
wp.workerFunc(ch) // 处理 channel 中的连接
wp.workerChanPool.Put(vch) // 归还 workerChan 到 pool
}()
}
return ch
}
现在我们来看看 fasthttp 中 workerPool 的心脏部分——getCh 方法。这个方法非常关键,它决定了一个新到的连接如何被分配给 worker,以及什么时候会创建新的 worker goroutine。
想象一下,workerPool 就像一个“工厂车间”,每个 workerChan 是一个工位。新连接就是需要加工的任务。getCh 的工作,就是帮你找到一个空闲的工位,如果没有空闲的工位,同时还没到最大工位数量,就新开一个工位。
我们看下代码的核心片段:
wp.lock.Lock()
ready := wp.ready
n := len(ready) - 1
if n < 0 {
if wp.workersCount < wp.MaxWorkersCount {
createWorker = true
wp.workersCount++
}
} else {
ch = ready[n]
ready[n] = nil
wp.ready = ready[:n]
}
wp.lock.Unlock()
这里发生了什么呢?
-
首先,它上锁保护
ready队列,因为可能有多个 goroutine 同时来取 worker。 -
它检查
ready队列是否还有空闲 workerChan:- 如果有,就从队列尾部取出一个工位分配给任务;
- 如果没有空闲的,就判断当前 worker 数量是否小于最大值,如果小于,就允许创建一个新的 worker(开一个新工位)。
-
解锁之后,如果成功取到空闲 workerChan,就直接返回;如果需要新建 worker,就从
workerChanPool里拿一个对象,启动一个 goroutine 来循环处理这个 workerChan 的任务。
接下来的逻辑非常有意思:
if ch == nil {
if !createWorker {
return nil
}
vch := wp.workerChanPool.Get()
ch = vch.(*workerChan)
go func() {
wp.workerFunc(ch)
wp.workerChanPool.Put(vch)
}()
}
可以看到,fasthttp 真正的魔法就在这里:
- 新的 workerChan goroutine 会执行
workerFunc,不停从它的 channel 中读取连接任务,然后处理请求。 - 处理完后,workerChan 被放回对象池,下一轮可以复用。
- 这种机制避免了每个连接都启动一个 goroutine,而是“少量 goroutine 复用大量连接”,极大降低调度开销。
总结一下 getCh 的核心思想:
- 优先复用空闲 workerChan,减少对象分配和 goroutine 启动。
- 动态扩展 worker 数量,但有上限,保证并发能力同时不无限制占用系统资源。
- 结合对象池和 channel,worker goroutine 可以持续循环处理连接,实现高性能、低延迟的事件循环。
你可以把它想象成:fasthttp 的 workerPool 就是一个智能调度器,它既能确保每个任务有工位,又能动态扩容,同时最大限度利用系统资源,形成高并发下的轻量事件循环。
在workerFunc中我们看到:
if err = wp.WorkerFunc(c); err != nil && err != errHijacked
而WorkerFunc即ServeHandler,则定义于server.go
type ServeHandler func(c net.Conn) error
需要注意的是,fasthttp 的 Server 并没有包含标准库的 http.Server 指针,也不是对其封装。它是 完全重写的 HTTP 服务端,从底层开始控制每一个环节:
-
监听端口和接受连接
- 通过
net.Listener获取 TCP 连接,而不是依赖http.Server的Serve方法。
- 通过
-
高性能连接调度
- 每个新连接会被交给内部的
workerPool,利用固定数量的 goroutine + channel 循环处理,实现轻量事件循环。 - 避免了
net/http中“一连接一 goroutine”的模式,从而减少调度开销和内存占用。
- 每个新连接会被交给内部的
-
请求解析与响应生成
- 完全自定义的请求解析器和响应构造器,零反射、零 interface 抽象,最大限度减少内存分配和 CPU 消耗。
- 结合对象池复用
Request、Response和缓冲区,实现低延迟、高吞吐。
-
可控并发与资源管理
- 内置 worker 数量限制、空闲 worker 回收、连接状态回调等机制,使得服务器在高并发下仍能稳定运行,而不依赖标准库的通用实现。
换句话说,fasthttp 的
Server就像是一个 从零构建的高性能 HTTP 引擎,为高并发和低延迟场景量身打造,完全绕过了net/http的调度模式和内存模型。这也正是它能在性能基准测试中胜过标准库的关键原因。
type Server struct {
noCopy noCopy
perIPConnCounter perIPConnCounter
ctxPool sync.Pool
readerPool sync.Pool
writerPool sync.Pool
hijackConnPool sync.Pool
...
}
在 fasthttp 中,Server.Serve 就是整个服务器的起点。它接收一个 net.Listener,从这个 listener 中循环接受连接,然后把每个连接交给内部的 workerPool 去处理。整个方法可以理解为一个 无限循环的“接收-分发-处理”调度器。
初始化 workerPool
wp := &workerPool{
WorkerFunc: s.serveConn,
MaxWorkersCount: maxWorkersCount,
LogAllErrors: s.LogAllErrors,
MaxIdleWorkerDuration: s.MaxIdleWorkerDuration,
Logger: s.logger(),
connState: s.setState,
}
wp.Start()
- 这里创建了一个
workerPool实例,并把s.serveConn设置为WorkerFunc。 - 这个 workerPool 会管理固定数量的 goroutine,每个 goroutine 循环从 channel 获取连接并处理。
MaxWorkersCount根据服务器的并发配置动态计算,保证不会无限创建 goroutine。
也就是说,workerPool 就像一个“高性能的工厂车间”,Serve 方法负责把新到的连接“送进车间”,worker goroutine 则是流水线上的工人,处理每个任务。
循环接受连接
for {
c, err := acceptConn(s, ln, &lastPerIPErrorTime)
if err != nil {
wp.Stop()
if err == io.EOF {
return nil
}
return err
}
acceptConn会从 listener 中接受一个新 TCP 连接。- 如果返回错误(例如 listener 被关闭),就停止 workerPool 并返回。
- 成功获取连接后,马上把连接状态标记为
StateNew,并增加open计数器。
将连接交给 workerPool
if !wp.Serve(c) {
// 处理并发限制超过时的情况
}
wp.Serve(c)内部会调用getCh()获取一个空闲 workerChan,把连接投递给它。- 如果 workerPool 当前没有可用 worker(达到最大并发),会返回
false,这时服务器会拒绝连接,返回503 Service Unavailable。 - 并且 fasthttp 还提供可配置的
SleepWhenConcurrencyLimitsExceeded,在高并发时稍微延迟,避免过度抢占 CPU。
并发控制与连接状态管理
open计数器统计当前活跃连接数,保证 Shutdown 或状态检查时不会出现错误。setState(c, StateNew/StateClosed)管理连接生命周期,配合 workerPool 内部使用。- 日志记录并发溢出情况,方便调优
Server.Concurrency。
用一句话概括:
Server.Serve就是 fasthttp 的 “连接接收与分发引擎”:不断接受连接,把每个连接交给 workerPool,workerPool 再用固定数量的 goroutine 循环处理请求,从而实现高并发下的轻量事件循环。
它和 Go 标准库最大的不同在于:
- 不依赖
net/http.Server,完全自定义处理流程。 - 控制并发粒度和资源占用,避免“一连接一 goroutine”导致的调度开销。
- 结合 workerPool、对象池和 channel,实现低延迟、高吞吐。
细心的小伙伴可能注意到了,在Serve中,Server在WorkerFunc参数中注册了自己的serveConn,由于这个函数篇幅太长,这里只给出核心部分:
func (s *Server) serveConn(c net.Conn) {
var h ServeHandler = s.Handler // s.Handler 就是用户传入的 ServeHandler
h(c) // <-- 最终调用用户的 ServeHandler
}
通过前面的讲解,我们可以看到,fasthttp 的整个请求处理流程是如何紧密耦合、为性能而生的:
Server.Serve循环接受连接,将每个连接投递给内部的workerPool;workerPool利用固定数量的 worker goroutine 和 channel 循环,高效调度连接;- 每个 worker 最终调用
ServeHandler(用户自定义的请求处理函数),完成业务逻辑处理; - 所有连接、请求和响应对象都通过对象池复用,极大减少内存分配和 GC 压力。
整个设计链条环环相扣:从接受连接到处理请求,再到资源回收,都围绕极致性能展开,没有任何冗余层。正因如此,fasthttp 才能在高并发场景下达到非常惊人的吞吐量和低延迟。
然而,这种为了性能而“邪修式”的设计,也决定了它的局限性——不兼容 net/http,不支持 HTTP/2,也牺牲了部分开发便利性。下面,我们就对这些优缺点做一个总结。
优点:
-
极致性能
- 使用固定数量的 worker goroutine + workerChan 循环处理连接,避免了
net/http的“一连接一 goroutine”带来的调度开销。 - 对请求、响应、连接对象进行池化复用,减少内存分配和 GC 压力。
- 零拷贝、轻量事件循环、紧密控制的调度机制,使得它在高并发场景下吞吐和延迟表现优异。
- 使用固定数量的 worker goroutine + workerChan 循环处理连接,避免了
-
低延迟、高并发
- 结合
workerPool并发控制和空闲 worker 回收机制,即使连接数极高,也能保持稳定性能。 - 可通过
MaxWorkersCount、MaxIdleWorkerDuration等参数精细调节资源占用。
- 结合
-
精细可控
- 用户可以直接传入
ServeHandler,完全控制请求处理逻辑。 - 连接状态、错误日志、并发拒绝等都有明确回调和配置,方便高性能场景下的监控和调优。
- 用户可以直接传入
缺点:
-
不兼容
net/http- 由于完全重写了 Server 逻辑,fasthttp 并不能直接替换
net/http.Server,现有基于标准库中间件的生态无法直接使用。
- 由于完全重写了 Server 逻辑,fasthttp 并不能直接替换
-
不支持 HTTP/2
- 轻量事件循环和低级 socket 处理的设计使得原生 HTTP/2 支持很困难。
- 对于需要多路复用和流控制的 HTTP/2 场景,不适合使用 fasthttp。
-
牺牲灵活性
- 为了极致性能,放弃了很多标准库提供的便利特性,例如自动请求解析、标准中间件机制等。
- 对开发者要求较高,需要理解底层连接和对象复用机制,否则容易出问题。
总体来看,fasthttp 是一把“锋利的工具”:如果你追求极致性能、高并发吞吐,它几乎无可替代;但如果你希望快速兼容标准库或者使用 HTTP/2 特性,它就不适合。
对象池化
在高性能 HTTP 框架里,内存分配和垃圾回收是性能杀手。每个请求都会涉及到 Request、Response、[]byte 缓冲区等对象,如果每次都新建,GC 很快就会成为瓶颈。fasthttp 通过 对象池化(object pooling) 的方式来解决这个问题。
核心思路:
-
复用 Request/Response 对象
- 框架内部维护
sync.Pool,存放可复用的Request、Response对象。 - 每次处理新请求时,从池里取对象;处理完后归还池中,而不是让 GC 回收。
- 框架内部维护
-
复用缓冲区
- 读取请求头、body,或者构造响应时所用的 byte slice,也可以通过对象池复用。
- 避免每次都分配新 slice,降低内存分配压力。
-
结合 workerPool 循环使用
- 由于 worker goroutine 会循环处理大量连接,每个 worker 可以连续复用对象池里的资源。
- 在高并发下,GC 压力被大幅削减,延迟更加稳定。
在 Go 语言的世界里,内存管理一直是个既简单又复杂的话题。得益于内置的垃圾回收(GC)机制,开发者无需手动释放内存,但这也带来了性能优化的新挑战——如何减少 GC 的压力,提升程序的运行效率?答案之一便是 Go 标准库中的 sync.Pool,一个轻量级的临时对象池工具。它通过复用对象,减少内存分配和 GC 开销,成为许多高性能服务的秘密武器。
然而,sync.Pool 并非万能钥匙,用得好是性能加速器,用不好则可能是隐藏的“定时炸弹”。想象一下,你在厨房里反复洗碗用盘子,而不是每次吃饭都买新的——这就是 sync.Pool 的核心思想。但如果盘子没洗干净就拿去给下个人用,或者压根儿没搞清楚哪些东西适合反复用,结果可能适得其反。
从初学者到资深开发者,很多人都曾在 sync.Pool 上摔过跟头:有人误以为它能永久保存对象,有人忽略了对象状态的清理,甚至有人把它用在了不该用的地方。
什么是 sync.Pool?
简单来说,sync.Pool 是 Go 标准库提供的一个 线程安全的临时对象池。它的设计初衷是让开发者可以复用频繁创建和销毁的对象,从而减少内存分配和 GC 的开销。就像一个共享的“工具箱”,你可以用完工具后放回去,别人也能接着用。
sync.Pool 的核心机制围绕三个关键点展开:
-
New 函数
- 定义对象池初始化时的生成逻辑。如果池子里没有可用对象,调用
New创建一个新的。
- 定义对象池初始化时的生成逻辑。如果池子里没有可用对象,调用
-
Get 和 Put 方法
Get从池中获取一个对象,Put将用完的对象归还。整个过程是线程安全的。
-
GC 的影响
- 这是理解
sync.Pool的关键——它并非持久化存储。每次 GC 触发时,池中的对象可能会被清空,迫使池子重新填充。
- 这是理解
下图简单展示了 sync.Pool 的生命周期:
+------------------+
| sync.Pool |
| +------------+ |
| | Get() |----> 使用对象
| +------------+ |
| | Put() |<---- 归还对象
| +------------+ |
| GC 清空池 |
+------------------+
sync.Pool 特别适合 高频创建临时对象 的场景,例如:
- JSON 处理:频繁分配的
[]byte切片。 - Web 服务:HTTP 请求处理中的缓冲区。
- 数据库操作:连接池的辅助工具。
下面是一个简单示例,演示如何使用 sync.Pool 缓存 []byte:
package main
import (
"fmt"
"sync"
)
// 定义一个对象池,缓存 []byte
var bufPool = sync.Pool{
New: func() interface{} {
// 当池子为空时,创建一个 1024 字节的切片
return make([]byte, 1024)
},
}
func process() {
// 从池中获取一个缓冲区
buf := bufPool.Get().([]byte)
// 用完后归还
defer bufPool.Put(buf)
// 示例:写入数据
copy(buf, []byte("Hello, Pool!"))
fmt.Println(string(buf[:12]))
}
func main() {
process()
}
sync.Pool 的常见陷阱
尽管 sync.Pool 用法简单,但实践中却容易让人掉进“坑”里。
陷阱 1:误以为对象池是持久化的
很多人以为 sync.Pool 能像数据库一样永久保存对象,但实际上,GC 随时可能清空池子,导致性能波动。
在一个日志系统中,我们用 sync.Pool 缓存大块缓冲区(10MB)。初期性能很好,但随着 GC 频繁触发,池子被清空,新对象的分配让延迟激增。pprof 分析显示,内存分配次数远超预期。
接受 sync.Pool 的临时性本质,用监控工具(如 pprof)观察池化效果,并在必要时结合其他缓存策略(如自定义持久化池)。
时间轴:
| Pool 填充 | 使用 | GC 清空 | 重新填充 |
性能:
高 ---------> 高 -----> 低 -------> 高
陷阱 2:未清理对象状态
归还的对象如果不重置状态,会导致数据污染。
某 Web 服务中,我们池化了 []byte 用于 JSON 解析。某次归还时忘了清零,结果下个请求拿到的缓冲区带着上次的残留数据,引发解析错误。
在 Get 时检查并清理,或在 Put 前重置状态。
func process() {
buf := bufPool.Get().([]byte)
defer func() {
// 清零缓冲区
for i := range buf {
buf[i] = 0
}
bufPool.Put(buf)
}()
// 使用 buf
copy(buf, []byte("New Data"))
}
陷阱 3:不合适的池化对象
并非所有对象都适合池化。如果对象太小或使用频率低,池化的锁竞争和维护成本可能超过收益。
在某个项目中,我们尝试池化一个 16 字节的小结构体,结果发现 goroutine 竞争池的开销比直接分配还高,性能反而下降了 10%。
分析对象生命周期和分配频率。小对象或低频对象直接分配,高频大对象才池化。
| 对象类型 | 池化收益 | 建议 |
|---|---|---|
| 小对象(<64B) | 低(锁竞争高) | 不池化 |
| 大对象(>1KB) | 高(减少 GC) | 池化 |
| 高频使用 | 高 | 池化 |
| 低频使用 | 低 | 不池化 |
陷阱 4:并发安全误解
有人误以为 sync.Pool 能保证池中对象的线程安全,但实际上它只保护 Get 和 Put 操作。一个多 goroutine 共享池中对象的项目中,未加锁导致数据竞争,生产环境出现随机崩溃。
明确 sync.Pool 只负责池的并发安全,对象使用时需自行加锁。
避开了这些陷阱,我们才能真正发挥 sync.Pool 的威力。
sync.Pool 的正确用法与优势
正确用法 1:高频临时对象复用
Web 服务中,bytes.Buffer 是常见的临时对象,每次请求都分配会增加 GC 负担。复用缓冲区能显著减少内存分配,提升吞吐量。
package main
import (
"bytes"
"net/http"
"sync"
)
var bufferPool = sync.Pool{
New: func() interface{} {
return new(bytes.Buffer)
},
}
func handleRequest(w http.ResponseWriter, r *http.Request) {
buf := bufferPool.Get().(*bytes.Buffer)
buf.Reset() // 重置状态
defer bufferPool.Put(buf)
buf.WriteString("Hello, World!")
w.Write(buf.Bytes())
}
我们复用 bytes.Buffer 来减少 GC 开销,看起来很美好,但细心的小伙伴可能会发现一个潜在问题:
buf := bufferPool.Get().(*bytes.Buffer)
buf.Reset()
defer bufferPool.Put(buf)
表面上没问题,Reset() 把缓冲区长度清零了,但底层的 []byte slice 容量并没有改变。如果这个 Buffer 在使用过程中曾经增长到非常大,例如处理了一个几 MB 的请求数据,即使 Reset() 之后放回池子,这块大容量内存依然被池子持有。随着时间推移,池子里可能长期存在几个超大 Buffer,导致内存占用偏高,甚至出现类似“内存泄漏”的现象。
要解决这个问题,通常有两种策略:
-
缩容底层 slice
在Reset()之后,如果容量超过阈值,就手动创建一个新的小容量Buffer,保证池子里存的都是合理大小的对象:buf.Reset() if buf.Cap() > 4*1024 { // 超过阈值 buf = bytes.NewBuffer(make([]byte, 0, 1024)) } bufferPool.Put(buf) -
扩容对象不放回池子
另一种方法则更简单:如果使用过程中Buffer扩容超标,就直接丢弃,让 GC 回收:if buf.Cap() > 4*1024 { // 不放回池子,下次重新创建 return } bufferPool.Put(buf)
这两种方式的核心目标都是防止大对象长期占用池,既保证了对象复用带来的性能提升,又避免了潜在的内存膨胀问题。
正确用法 2:结合业务场景优化
在实际项目中,单纯依赖 sync.Pool 的通用功能往往不够。结合具体业务逻辑来优化对象池的使用,能让它的价值发挥到极致。
例如,在一个分布式任务分发系统中,每个任务需要一个临时对象来存储元数据。如果每次都重新分配,内存开销和 GC 压力会显著增加。通过池化任务对象,我们可以减少内存分配次数,稳定任务处理的延迟。
- 原先每个任务对象(约 4KB)在高并发下频繁分配,GC 每秒触发 5-10 次,任务延迟抖动在 50µs 到 200µs。
- 引入
sync.Pool后,分配时间从 50µs 降到 10µs,GC 频率降低到每分钟 1-2 次,延迟抖动稳定在 20µs 以内。
package main
import (
"fmt"
"sync"
)
// Task 表示一个任务的元数据
type Task struct {
ID int
Data []byte
}
// 定义任务对象池
var taskPool = sync.Pool{
New: func() interface{} {
return &Task{
Data: make([]byte, 4096), // 预分配 4KB 缓冲区
}
},
}
// 处理任务的函数
func processTask(id int) {
task := taskPool.Get().(*Task)
defer taskPool.Put(task)
// 重置任务状态
task.ID = id
for i := range task.Data {
task.Data[i] = 0
}
// 模拟任务处理
copy(task.Data, []byte(fmt.Sprintf("Task %d processed", id)))
fmt.Println(string(task.Data[:20]))
}
func main() {
for i := 0; i < 5; i++ {
processTask(i)
}
}
在 Go 高性能服务中,[]byte 经常被用作临时缓冲区,比如处理 HTTP 请求体或 JSON 序列化。如果直接把 []byte 放进 sync.Pool,就会遇到同样的问题:扩容过大的 slice 长期占用池,GC 无法及时回收。
解决方法:
-
限制池化的容量
在Put时检查 slice 的容量,如果超过阈值,就不要放回池里:var bytePool = sync.Pool{ New: func() interface{} { return make([]byte, 1024) // 默认 1KB }, } func getBuffer(size int) []byte { buf := bytePool.Get().([]byte) if cap(buf) < size { buf = make([]byte, size) } return buf[:size] } func putBuffer(buf []byte) { if cap(buf) <= 4*1024 { // 超过 4KB 就丢弃,让 GC 回收 bytePool.Put(buf) } } -
手动缩容
如果希望复用大 slice,也可以在Put前缩容:if cap(buf) > 4*1024 { buf = buf[:1024] // 缩小容量 } bytePool.Put(buf)这样下次取出来的 slice 不会过大,池子里对象容量更可控。
-
按用途分池
对于不同大小的 slice,可以建立多个池:smallPool -> 1KB mediumPool -> 16KB largePool -> 128KB这样既保证复用,又不会让一个池里充斥各种大小的 slice 导致内存膨胀。
正确用法 3:与 GC 协作而非对抗
很多开发者试图用 sync.Pool 完全替代 GC,但这往往适得其反。更好的方式是与 GC 协作,设置合理的池化策略。
- 限制池中对象的最大数量。
- 定期清理不活跃对象,避免内存占用失控。
在性能提升和内存使用之间找到平衡。
- 高吞吐量 API 服务中,最初无限制池化
[]byte,内存占用从 500MB 涨到 2GB。 - 后来在
Put时加入容量检查,只保留最近使用的 1000 个对象,内存占用稳定在 800MB,同时保持性能提升。
package main
import (
"sync"
"sync/atomic"
)
type LimitedPool struct {
pool sync.Pool
count int32 // 当前池中对象数
maxCount int32 // 最大容量
}
func NewLimitedPool(maxCount int32) *LimitedPool {
return &LimitedPool{
pool: sync.Pool{
New: func() interface{} {
return make([]byte, 1024)
},
},
maxCount: maxCount,
}
}
func (p *LimitedPool) Get() []byte {
return p.pool.Get().([]byte)
}
func (p *LimitedPool) Put(buf []byte) {
if atomic.LoadInt32(&p.count) < p.maxCount {
atomic.AddInt32(&p.count, 1)
p.pool.Put(buf)
} // 超出容量时丢弃
}
func (p *LimitedPool) Release(buf []byte) {
atomic.AddInt32(&p.count, -1)
}
- 使用
atomic追踪池中对象数。 Put时检查容量,超出则丢弃对象。Release可选,用于手动释放(视业务需要)。
池化与 GC 形成良性协作,GC 负责清理长期不用的对象,而池子专注于高频复用。
零拷贝
在高性能网络服务里,每一份内存拷贝都会带来额外开销。尤其是在处理 HTTP 请求和响应时,如果每次都把数据从 socket 拷贝到缓冲区,再从缓冲区拷贝到应用层,性能会被吞掉大部分。Go 的标准 net/http 就是一个典型例子:每个请求都有多次内存拷贝,尤其是 io.ReadAll 或 ioutil.ReadAll 的调用,会把整个请求体复制到新的 slice。
而 fasthttp 的“零拷贝”策略就是为了 最大限度减少内存拷贝。它的核心思路是:
-
直接操作底层缓冲区
fasthttp 不把请求体复制到新 slice,而是直接在底层缓冲区上操作。应用层拿到的是对原始缓冲区的引用,而不是一份拷贝的数据。 -
对象池结合零拷贝
请求和响应缓冲区都来源于sync.Pool,所以每次处理请求时,都是复用已有内存块,不会重复分配。
这样,既减少 GC 压力,又避免了不必要的内存拷贝。 -
按需切片而不复制
比如在处理 URL、Header、Body 时,fasthttp 通过 slice 分片的方式提取所需数据,而不是复制一份新的 slice。即便你在业务代码里修改这些 slice,底层池化机制也能保证不会污染其他请求。
零拷贝就是一种避免 CPU 将数据从一块存储拷贝到另外一块存储的技术。每一次拷贝都会造成不必要的开销。
我们以http连接中的数据拷贝分析。该场景就是创建一个http服务器,服务端从本地的文件读取内容并返回给客户端。
package main
import (
"net/http"
"os"
)
func main() {
http.HandleFunc("/hello", func(writer http.ResponseWriter, request *http.Request) {
f, _ := os.Open("./hello.txt")
buf := make([]byte, 1024)
// 内核拷贝到buf
n, _ := f.Read(buf)
// buf拷贝到内核
writer.Write(buf[:n])
})
http.ListenAndServe(":8080", http.DefaultServeMux)
}
普通模式数据交互
Linux系统中一切皆文件,仔细想一下Linux系统的很多活动无外乎读操作和写操作,零拷贝就是为了提高读写性能而出现的。
在Linux系统内部缓存和内存容量都是有限的,更多的数据都是存储在磁盘中。对于Web服务器来说,经常需要从磁盘中读取数据到内存,然后再通过网卡传输给用户:
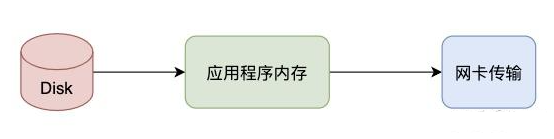
上述数据流转只是大框,接下来看看几种模式。
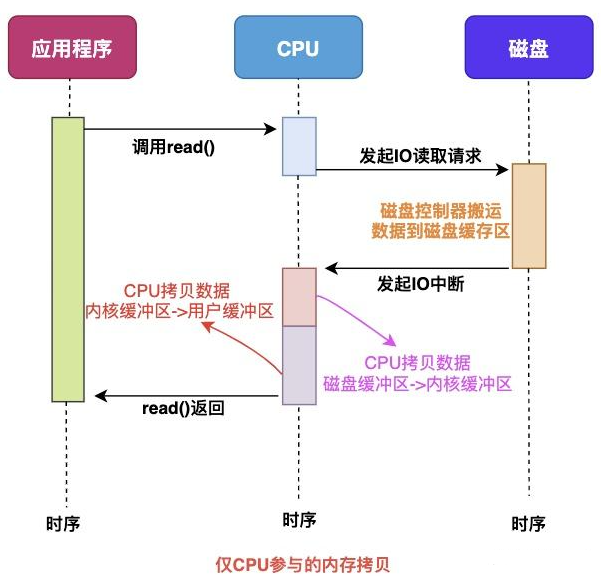
仅 CPU 方式
当应用程序需要读取磁盘数据时,调用 read() 从用户态陷入内核态:
read()系统调用最终由 CPU 来完成;- CPU 向磁盘发起 I/O 请求,磁盘收到请求后开始准备数据;
- 磁盘将数据放到磁盘缓冲区之后,向 CPU 发起 I/O 中断,报告数据已就绪;
- CPU 收到磁盘控制器的 I/O 中断后,开始拷贝数据,完成后
read()返回,并从内核态切换回用户态。
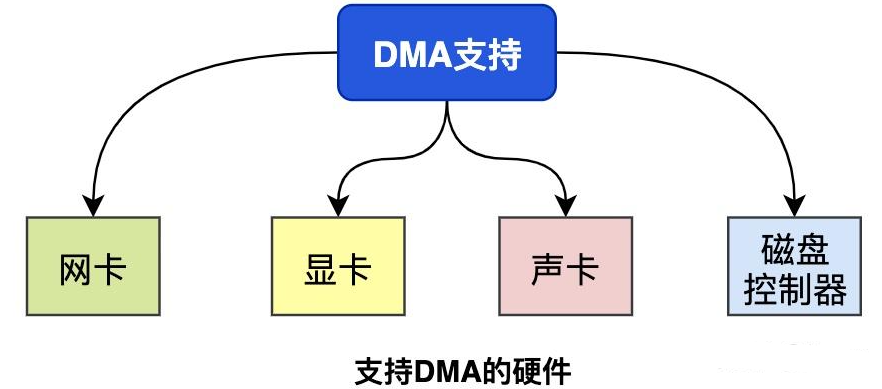
CPU & DMA 方式
CPU 的时间宝贵,让它做大量重复工作是资源浪费。此时引入 直接内存访问(DMA, Direct Memory Access):
- DMA 是一种硬件机制,允许设备绕过 CPU,直接读写内存;
- 通过 DMA,CPU 不再处理数据拷贝的细节,而是专注于计算任务;
- 支持 DMA 的硬件包括网卡、声卡、显卡、磁盘控制器等。
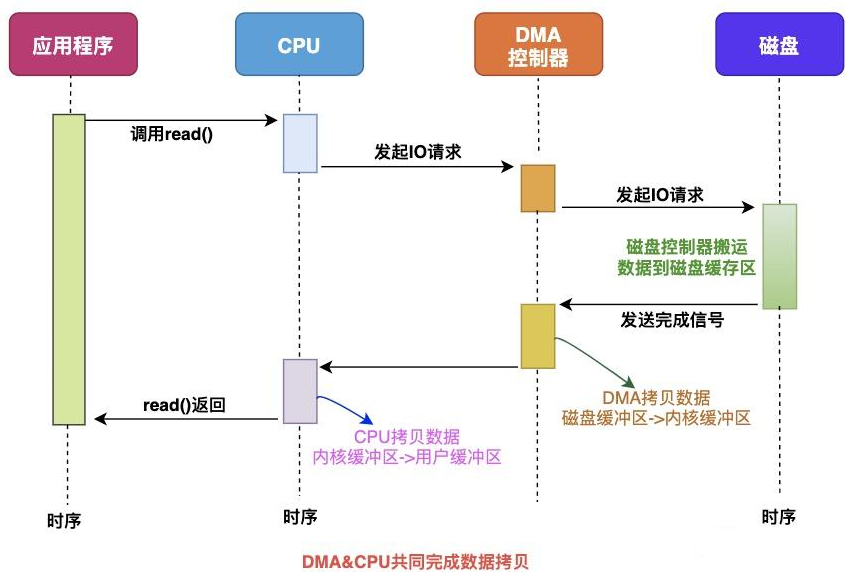
有了 DMA 之后,数据读取流程发生变化:
- CPU 不再直接与磁盘交互;
- DMA 负责从磁盘缓冲区将数据拷贝到内核缓冲区;
- 之后的流程与仅 CPU 方式类似,CPU 只在必要时处理数据或响应中断。
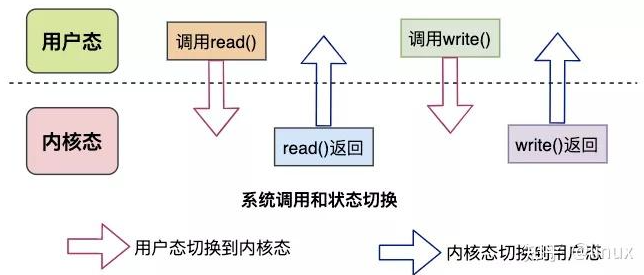
一次完整的数据交互通常包括几个部分:系统调用(syscall)、CPU、DMA、网卡、磁盘 等。
系统调用 syscall 是应用程序与内核交互的桥梁,每次调用或返回都会产生 两次状态切换:
- 调用 syscall:从用户态切换到内核态
- syscall 返回:从内核态切换回用户态
来看下完整的数据拷贝过程简图:
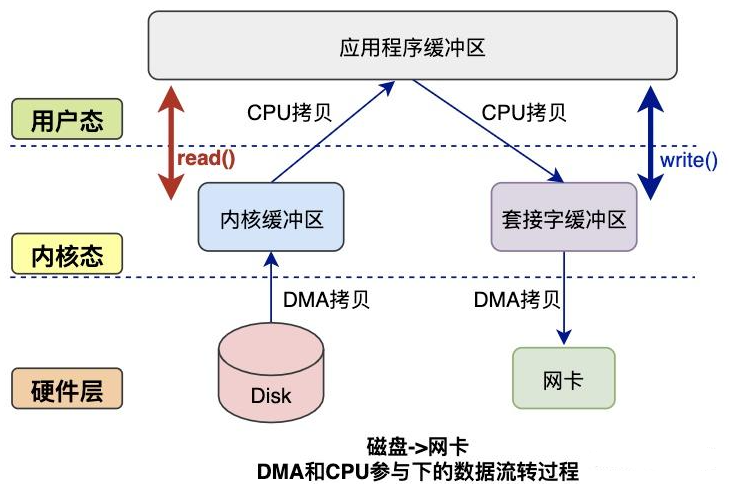
读数据过程:
- 应用程序调用
read()函数读取磁盘数据,实现 用户态切换到内核态(第 1 次状态切换); - DMA 控制器将数据从磁盘拷贝到 内核缓冲区(第 1 次 DMA 拷贝);
- CPU 将数据从内核缓冲区复制到 用户缓冲区(第 1 次 CPU 拷贝);
- CPU 拷贝完成后,
read()返回,实现 内核态切换回用户态(第 2 次状态切换)。
写数据过程:
- 应用程序调用
write()函数向网卡发送数据,实现 用户态切换到内核态(第 1 次状态切换); - CPU 将用户缓冲区数据拷贝到 内核缓冲区(第 1 次 CPU 拷贝);
- DMA 控制器将数据从内核缓冲区复制到 socket 缓冲区(第 1 次 DMA 拷贝);
- 拷贝完成后,
write()返回,实现 内核态切换回用户态(第 2 次状态切换)。
总结
- 读过程:2 次状态切换 + 1 次 DMA 拷贝 + 1 次 CPU 拷贝
- 写过程:2 次状态切换 + 1 次 DMA 拷贝 + 1 次 CPU 拷贝
由此可见,传统模式下的数据传输涉及 多次状态切换 和 冗余数据拷贝,效率并不高。接下来,就轮到 零拷贝技术 出场了,它能显著减少这些不必要的开销。
零拷贝技术
我们可以看到,如果应用程序不对数据做修改,从内核缓冲区到用户缓冲区,再从用户缓冲区到内核缓冲区。两次数据拷贝都需要CPU的参与,并且涉及用户态与内核态的多次切换,加重了CPU负担。
我们需要降低冗余数据拷贝、解放CPU,这也就是零拷贝Zero-Copy技术。
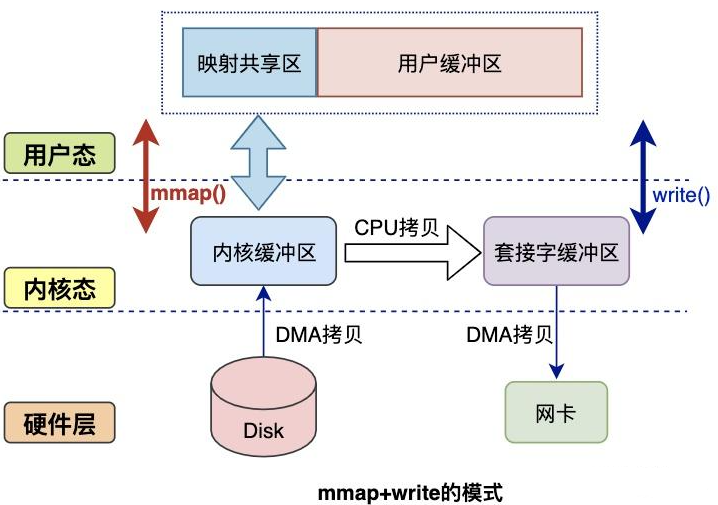
目前来看,零拷贝技术的几个实现手段包括:mmap+write、sendfile、sendfile+DMA收集、splice等。
mmap方式
mmap是Linux提供的一种内存映射文件的机制,它实现了将内核中读缓冲区地址与用户空间缓冲区地址进行映射,从而实现内核缓冲区与用户缓冲区的共享。
这样就减少了一次用户态和内核态的CPU拷贝,但是在内核空间内仍然有一次CPU拷贝。
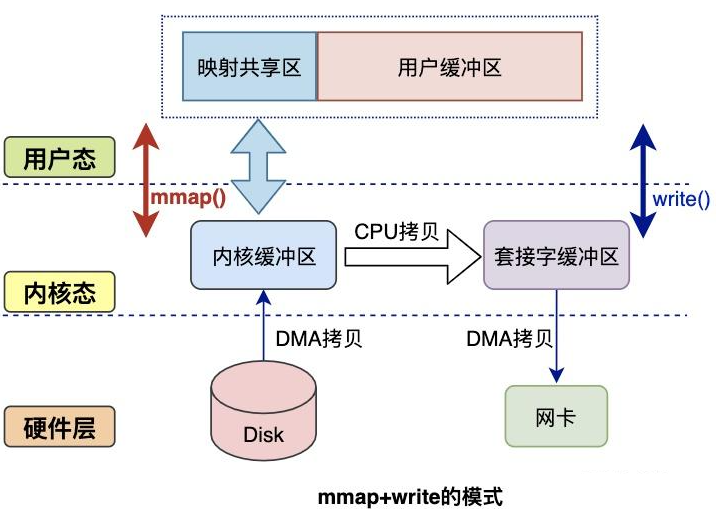
mmap对大文件传输有一定优势,但是小文件可能出现碎片,并且在多个进程同时操作文件时可能产生引发coredump的signal。
sendfile方式
mmap+write方式有一定改进,但是由系统调用引起的状态切换并没有减少。
sendfile系统调用是在 Linux 内核2.1版本中被引入,它建立了两个文件之间的传输通道。
sendfile方式只使用一个函数就可以完成之前的read+write 和 mmap+write的功能,这样就少了2次状态切换,由于数据不经过用户缓冲区,因此该数据无法被修改。
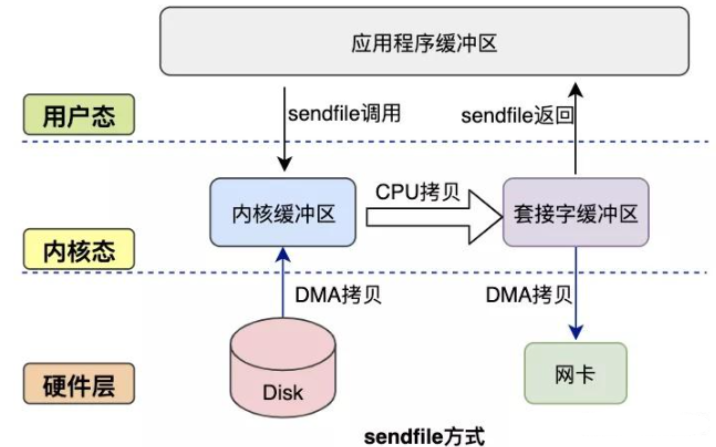
从图中可以看到,应用程序只需要调用sendfile函数即可完成,只有2次状态切换、1次CPU拷贝、2次DMA拷贝。
但是sendfile在内核缓冲区和socket缓冲区仍然存在一次CPU拷贝,或许这个还可以优化。
sendfile+DMA收集
Linux 2.4 内核对 sendfile 系统调用进行优化,但是需要硬件DMA控制器的配合。
升级后的sendfile将内核空间缓冲区中对应的数据描述信息(文件描述符、地址偏移量等信息)记录到socket缓冲区中。
DMA控制器根据socket缓冲区中的地址和偏移量将数据从内核缓冲区拷贝到网卡中,从而省去了内核空间中仅剩1次CPU拷贝。
这种方式有2次状态切换、0次CPU拷贝、2次DMA拷贝,但是仍然无法对数据进行修改,并且需要硬件层面DMA的支持,并且sendfile只能将文件数据拷贝到socket描述符上,有一定的局限性。
splice方式
splice系统调用是Linux 在 2.6 版本引入的,其不需要硬件支持,并且不再限定于socket上,实现两个普通文件之间的数据零拷贝。
splice 系统调用可以在内核缓冲区和socket缓冲区之间建立管道来传输数据,避免了两者之间的 CPU 拷贝操作。
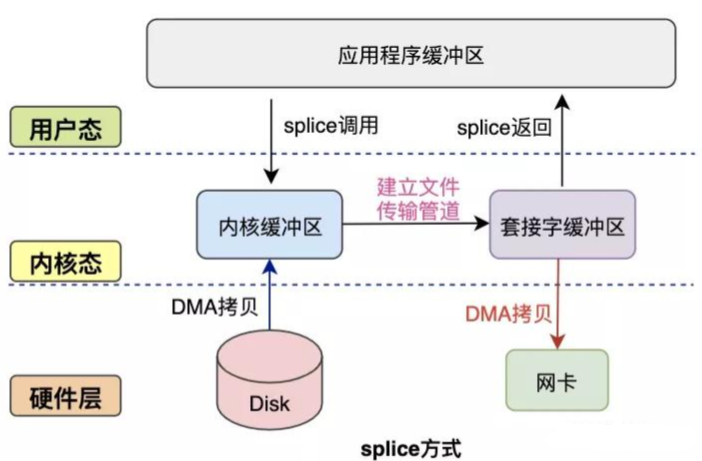
splice也有一些局限,它的两个文件描述符参数中有一个必须是管道设备。
golang标准库中零拷贝应用举例
讲完了零拷贝涉及的技术,我们来看看golang是如何运用这些技术的。拿一个比较常用的方法举例,io.Copy, 其底层调用了copyBuffer方法,copyBuffer会判断copy的目的接口Writer是否实现了ReaderFrom 接口,如果实现了则直接调用ReaderFrom 从src读取数据。
func Copy(dst Writer, src Reader) (written int64, err error) {
return copyBuffer(dst, src, nil)
}
func CopyBuffer(dst Writer, src Reader, buf []byte) (written int64, err error) {
if buf != nil && len(buf) == 0 {
panic("empty buffer in CopyBuffer")
}
return copyBuffer(dst, src, buf)
}
func copyBuffer(dst Writer, src Reader, buf []byte) (written int64, err error) {
// If the reader has a WriteTo method, use it to do the copy.
// Avoids an allocation and a copy.
// 如果写出支持WriteTo方法,那么就使用WriteTo方法。避免拷贝
if wt, ok := src.(WriterTo); ok {
return wt.WriteTo(dst)
}
// Similarly, if the writer has a ReadFrom method, use it to do the copy.
// 如果读入支持ReaderFrom方法,那么就使用ReaderFrom方法
if rt, ok := dst.(ReaderFrom); ok {
return rt.ReadFrom(src)
}
// 进行传统的文件读取,代码较长,暂时省略了。
.......
return written, err
}
net.TcpConn实现了ReadFrom 接口,拿net.TcpConn举例,看看它的实现。
func (c *TCPConn) readFrom(r io.Reader) (int64, error) {
if n, err, handled := splice(c.fd, r); handled {
return n, err
}
if n, err, handled := sendFile(c.fd, r); handled {
return n, err
}
return genericReadFrom(c, r)
}
最终net.TcpConn 会调用readFrom方法从来源io.Reader读取数据,而readFrom读取数据用到的技术则是刚刚所讲的零拷贝技术,这里用到了splice和sendFile系统调用,如果来源io.Reader是一个tcp连接或者时unix 连接则会调用splice进行数据拷贝,否则就会调用sendFile进行数据拷贝。
splice()、mmap() 和 sendfile() 都是用于处理数据传输的高效方法。它们在功能上有一定重叠,但各自针对不同场景有明显优势。
-
mmap()
-
功能:将文件映射到进程的内存空间中,使进程可以像操作内存一样操作文件。
-
适用场景:
- 需要 随机访问大文件 的场景
- 需要在 多个进程之间共享数据 的情况
-
优点:避免频繁的系统调用,直接通过内存访问数据,提高访问效率
-
-
sendfile()
-
功能:在两个文件描述符之间直接传输数据,无需经过用户空间
-
适用场景:
- 网络应用(如 Web 服务器)
- 将 磁盘文件直接发送到网络套接字
-
优点:减少数据拷贝次数,降低 CPU 占用,提高吞吐量
-
-
splice()
-
功能:将数据从一个文件描述符移动到另一个文件描述符,可与管道一起使用
-
适用场景:
- 流式数据传输任务
- 需要在文件、管道、套接字之间高效传输数据的场景
-
优点:通用性强,避免用户态拷贝,提升传输效率
-
总结:
mmap()、sendfile()和splice()各有优劣,适合不同的数据传输需求- 在 Linux 系统下,它们都是提升 I/O 性能的重要工具,合理使用可以显著减少 内核与用户空间的数据拷贝,降低 CPU 负载,提高吞吐量
fasthttp中的零拷贝
[]byte 本身只是 Go 的 内存切片,它本身并不意味着零拷贝。零拷贝指的是在 数据从网络/磁盘到应用程序 或 应用程序到网络 的整个路径中,尽量避免 多次内核态 ↔ 用户态切换 和 多余的数据拷贝。
在 fasthttp 中,它的“零拷贝”主要体现在以下几个方面:
-
内存复用 + 直接操作
[]bytefasthttp中大量使用[]byte和sync.Pool来复用缓冲区。- 当请求到达时,它 直接在已有缓冲区上解析 HTTP 请求,而不是每次都新分配内存。
- 对响应也是同样,数据写入缓冲区后可以直接发送。
关键:这里减少了内存分配和 GC 压力,但这只是 零拷贝的一个环节,并不等于彻底零拷贝。
-
避免中间
string转换- Go 的
string与[]byte转换通常会产生内存拷贝([]byte -> string会复制数据)。 fasthttp尽量使用[]byte作为请求和响应的存储,解析 HTTP header、URL、body 都直接操作[]byte,避免了不必要的转换拷贝。- 例如:
ctx.URI().Path()返回的是[]byte,内部直接引用原始请求缓冲区。
- Go 的
-
系统调用层面的零拷贝(发送响应)
- 在 Linux 下,
fasthttp可以配合writev/sendfile或直接将缓冲区传给内核 socket,避免应用层再做一次内存拷贝。 - 这是真正意义上的零拷贝:数据从内核缓冲区直接发送到网卡,绕过用户态复制。
- 在 Linux 下,
解为什么 string ↔ []byte 转换可能浪费性能
这是一个 Go 内存模型和字符串设计的问题。
-
string:只包含 指向底层数据的指针 + 长度,是只读的。type stringHeader struct { Data uintptr Len int }- 由于只读,Go 保证字符串不会被修改。
- 底层内存不能被直接修改,否则可能破坏其他引用字符串的地方。
-
[]byte:包含 指针 + 长度 + 容量,是可写的。type sliceHeader struct { Data uintptr Len int Cap int }
转换带来的内存复制
-
string -> []byte:s := "hello" b := []byte(s)- Go 必须在堆上分配新的
[]byte内存,并将字符串的每个字节复制进去。 - 因为
[]byte可写,而原string是只读的,所以不能直接共享内存。
- Go 必须在堆上分配新的
-
[]byte -> string:b := []byte{'h','e','l','l','o'} s := string(b)- Go 同样会创建一个新的
string,把[]byte内容复制过去。 - 因为
string是不可变的,必须保证底层数据不会被修改。
- Go 同样会创建一个新的
总结:每次转换都涉及 内存分配 + 数据拷贝,特别是大字节数组时开销很明显。
fasthttp 避免这种转换,通过:
- 直接在
[]byte上解析 HTTP 请求和响应。 - 返回的数据尽量仍然是
[]byte,避免转成string。 - 如果必须转
string,也提供string(b)轻量方法,但通常只在小片段使用。
s2b(s string) []byte
func s2b(s string) []byte {
return unsafe.Slice(unsafe.StringData(s), len(s))
}
-
unsafe.StringData(s):获取字符串
s底层数据的内存指针(*byte)。 -
unsafe.Slice(ptr, len(s)):基于这个指针创建一个长度为
len(s)的[]byte切片。 -
关键点:
- 没有拷贝数据,返回的
[]byte直接引用字符串底层内存。 - 避免了原生
[]byte(s)的分配 + 拷贝。
- 没有拷贝数据,返回的
-
注意事项:
- 返回的
[]byte是可写的,但原string是只读的。 - 如果修改返回的
[]byte,会破坏原字符串,这是 unsafe 的风险。
- 返回的
b2s(b []byte) string
func b2s(b []byte) string {
return unsafe.String(unsafe.SliceData(b), len(b))
}
-
unsafe.SliceData(b):获取
[]byte底层数组的指针。 -
unsafe.String(ptr, len(b)):用这个指针直接创建
string。 -
关键点:
- 没有拷贝数据,
string直接指向[]byte内存。 - 避免了原生
string(b)的分配 + 拷贝。
- 没有拷贝数据,
-
注意事项:
string是只读的,所以如果原[]byte后续被修改,会影响字符串内容。- 因此使用时要确保
[]byte在字符串生命周期内不被修改。
性能提升原因
| 方法 | 原生转换成本 | unsafe 方法成本 |
|---|---|---|
| string → []byte | 内存分配 + 数据拷贝 | 仅创建 slice header,无拷贝 |
| []byte → string | 内存分配 + 数据拷贝 | 仅创建 string header,无拷贝 |
- 对于大文本或高频转换,unsafe 版本性能提升非常显著。
- 避免了 大量 GC 压力,减少内存分配。
- 要求开发者确保数据不可修改,否则可能引发内存安全问题。
尾声
在阅读 fasthttp 的源码和实践过程中,我们不难发现它的设计哲学:极致性能优先。正如 README 所言:
“fasthttp might not be for you!
fasthttp was designed for some high performance edge cases. Unless your server/client needs to handle thousands of small to medium requests per second and needs a consistent low millisecond response time fasthttp might not be for you. For most cases net/http is much better as it’s easier to use and can handle more cases. For most cases you won’t even notice the performance difference.”
换句话说,fasthttp 并非适合所有场景,它为高并发、低延迟的边缘情况进行了激进优化。如果你的应用不需要处理成千上万的请求,或者对响应时间要求不是严格的毫秒级,net/http 更加稳定易用,并且足够应付大多数业务。
但即便如此,fasthttp 的很多实现细节仍值得借鉴:
- 对象池化 提供了减少 GC 压力的思路;
- 协程复用和轻量事件循环 给高并发处理提供了启发;
- 零拷贝处理 对性能敏感的数据处理同样适用;
- unsafe 转换技巧 则展示了如何在特定场景下最大化吞吐量。
总结来看,fasthttp 不只是一个框架,更是一套高性能设计思路的集合。即使我们最终选择了 net/http,从中学到的理念和技巧仍然可以在自己的项目中灵活运用,实现性能优化的“小技巧积累”,这正是阅读源码最大的价值所在。


















 516
516

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











