



 文章介绍了网页抓取中的初级知识,强调了局部刷新信息的抓取和处理。讲解了如何判断信息是否为局部刷新,以及网页局部刷新对爬虫的影响。通过实战示例展示了如何使用Python爬虫抓取百度翻译和豆瓣电影排行信息,涉及到UA标识的使用、POST和GET请求以及处理JSON数据。文章还提到了在面对动态内容时,使用Selenium等工具的重要性。
文章介绍了网页抓取中的初级知识,强调了局部刷新信息的抓取和处理。讲解了如何判断信息是否为局部刷新,以及网页局部刷新对爬虫的影响。通过实战示例展示了如何使用Python爬虫抓取百度翻译和豆瓣电影排行信息,涉及到UA标识的使用、POST和GET请求以及处理JSON数据。文章还提到了在面对动态内容时,使用Selenium等工具的重要性。
目录
为啥是初级?
因为实际运用时我们很少会直接抓取整个网页的情况,而大多数网页都会设置反爬机制,即一般的UA检测,第一天写的爬虫对绝大部分情况都不适用,故除了起到对爬虫的基本架构的了解之外实际用处不大,而今天学习的是比较通用的基础爬虫

UA标识一般情况只要不被识别为爬虫即可,也没有太多要求
——如何查看自己通过某浏览器的UA标识?
首先点进某个网站,右键打开"检查",随便点,乱发一个请求,具体小文件可以随便选择,进入到有请求标头的小文件中,即可查看自己的UA标识
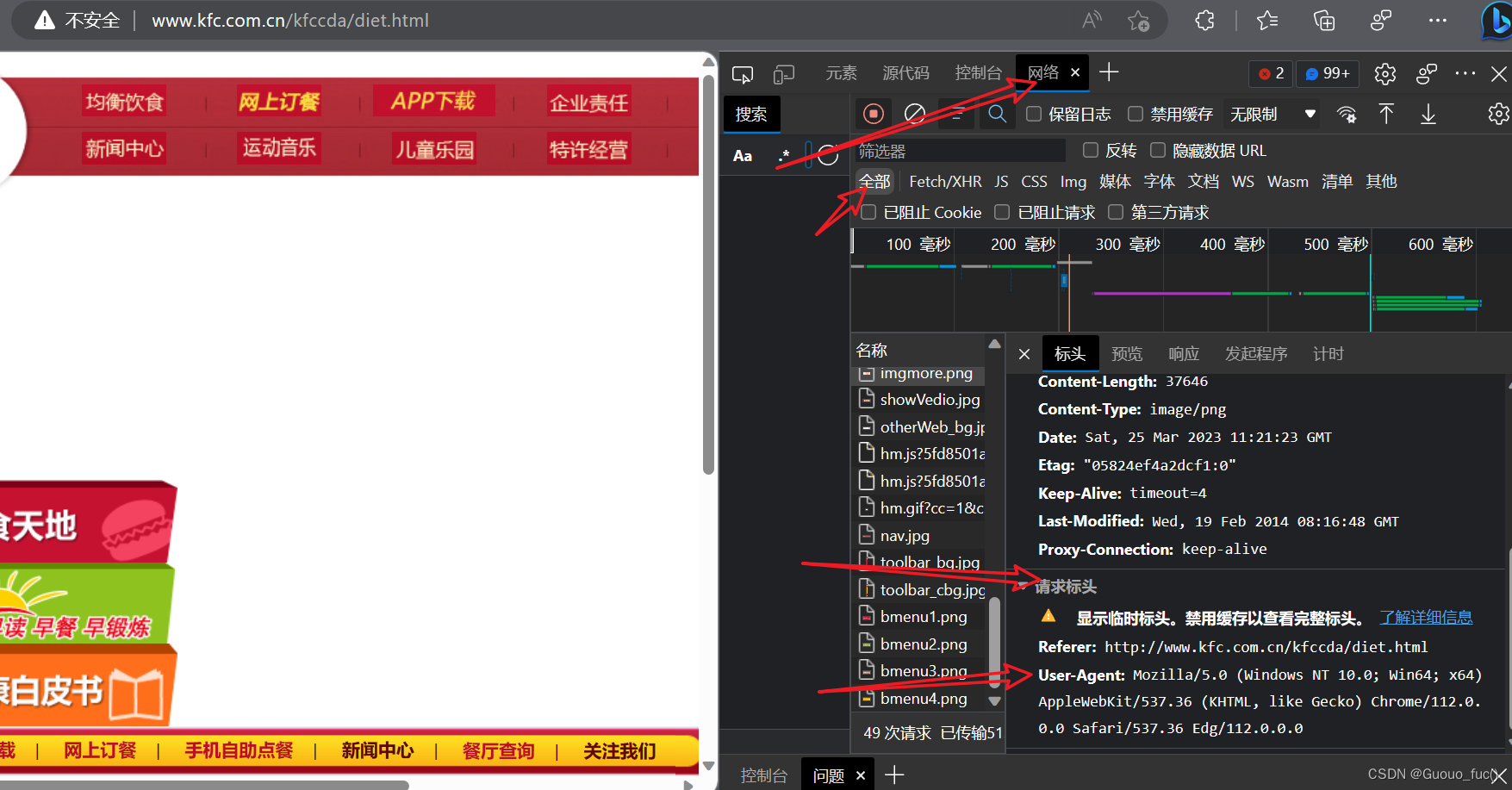
这里提供我的这个浏览器下的UA标识:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.0.0
之后我们无论爬虫程序发POST请求还是GET请求都要添加我们的UA标识
这里给一个样式
my_header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.0.0'
}
requests.post(....,...,header=my_header)
requests.get(..,...,header=my_header)抓取网站中局部刷新的信息
如何判断该信息是不是局部刷新?
前端ajax框架是一个很好的例子。它可以通过异步请求从服务器获取数据,然后使用JavaScript来更新页面的部分内容,而不需要刷新整个页面。这就是局部刷新。
一种方法是检查网页源代码中是否使用了ajax或其他类似的技术。另一种方法是观察网页在交互时是否有整页刷新的迹象,例如页面闪烁或URL改变。如果没有这些迹象,那么网页很可能使用了局部刷新技术。
<而我所实际做的>:盯着导航栏的那一行字符串,当你页面发生变化(数据刷新之类的)而导航栏不变,则证明该网页是局部刷新的
网页信息局部刷新对于我们的爬虫程序有什么特别的地方?
对于一个Python爬虫程序来说,网页局部刷新可能会带来一些挑战。因为局部刷新是通过JavaScript异步加载数据实现的,而传统的爬虫程序通常只能抓取静态的HTML内容,无法直接获取通过JavaScript动态生成的内容。
为了解决这个问题,您可以使用一些工具来模拟浏览器的行为,例如Selenium。它可以让您的爬虫程序像真实用户一样与网页交互,并获取动态生成的内容。此外,您还可以尝试分析网页中的JavaScript代码,找出数据加载的URL,并直接从服务器获取数据。
总之,当你使用Python爬虫程序抓取使用局部刷新技术的网页时,需要注意网页中的动态内容,并采取相应措施来获取这些内容。
实战样例之百度翻译
破解百度翻译——获取输入内容对应得到的翻译内容
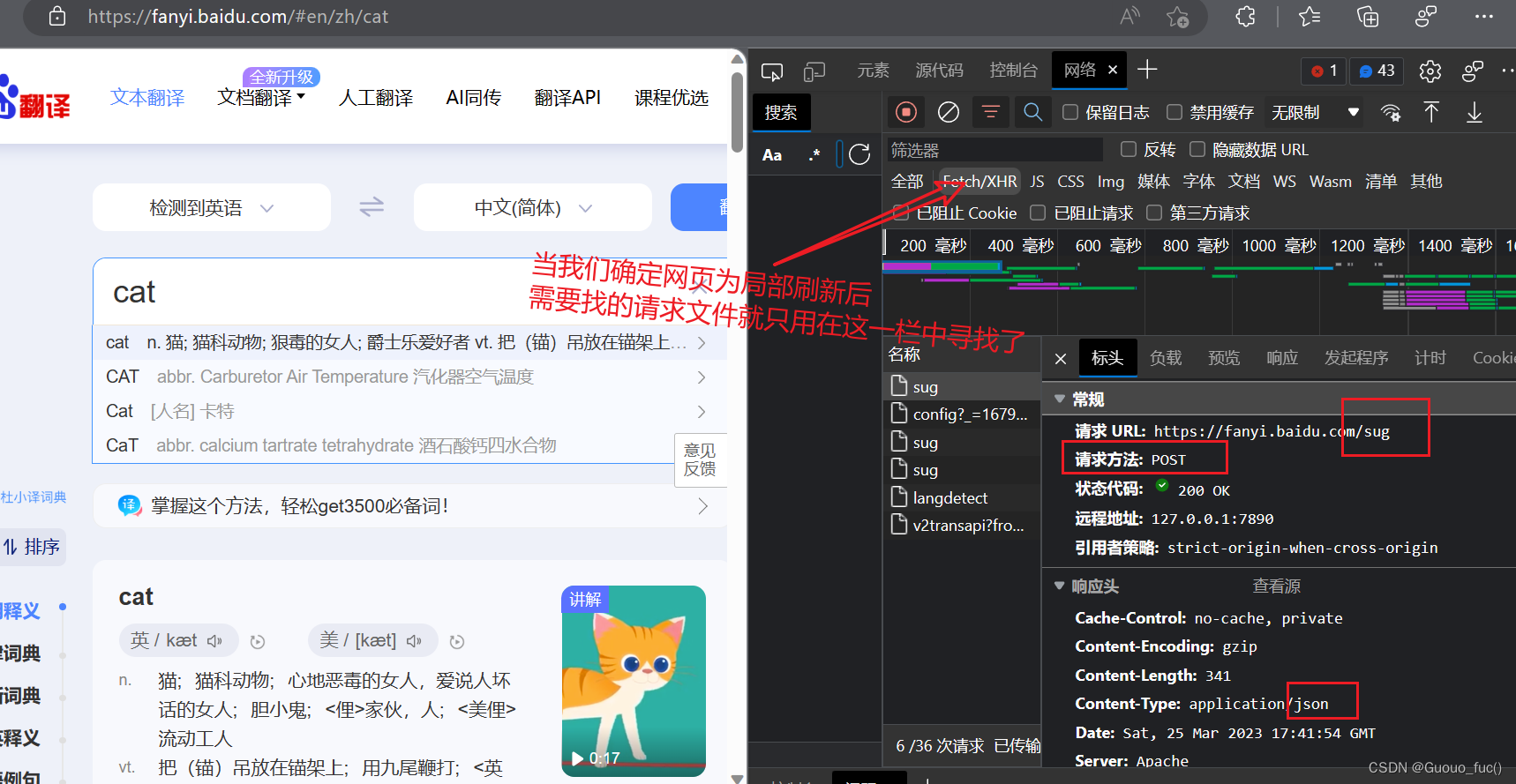
- 该请求为POST请求并且携带参数
- 响应数据为json数据
这里的url需要通过抓包工具获取
json.dump函数用于将Python对象编码为JSON格式的字符串,并将其写入到一个文件中。它的第一个参数是要编码的Python对象,第二个参数是一个文件对象,用于指定要写入的文件,第三个是是否以ascii码进行编码,有中文内容就选择False
设置requests.post内的参数名必须与网站设置相同:(寻找参数名的方法
1.直接打开网页开发工具,发送请求并抓包得到参数信息
2.查看网站的API文件,一键浏览所有的参数名
3.以上两者都无法找到则说明网站刻意隐藏参数名或着需要从其它的请求(如GET寻找信息),这里给出一种寻找data参数名的无奈之举,即前几种方式无果,但通过抓包发现post请求是通过一个sug后缀发出的,而已知该网站的前端框架为ajax框架,所以可以从源代码文件中的js文件索引中查询相关关键字,最终找到参数名为kw
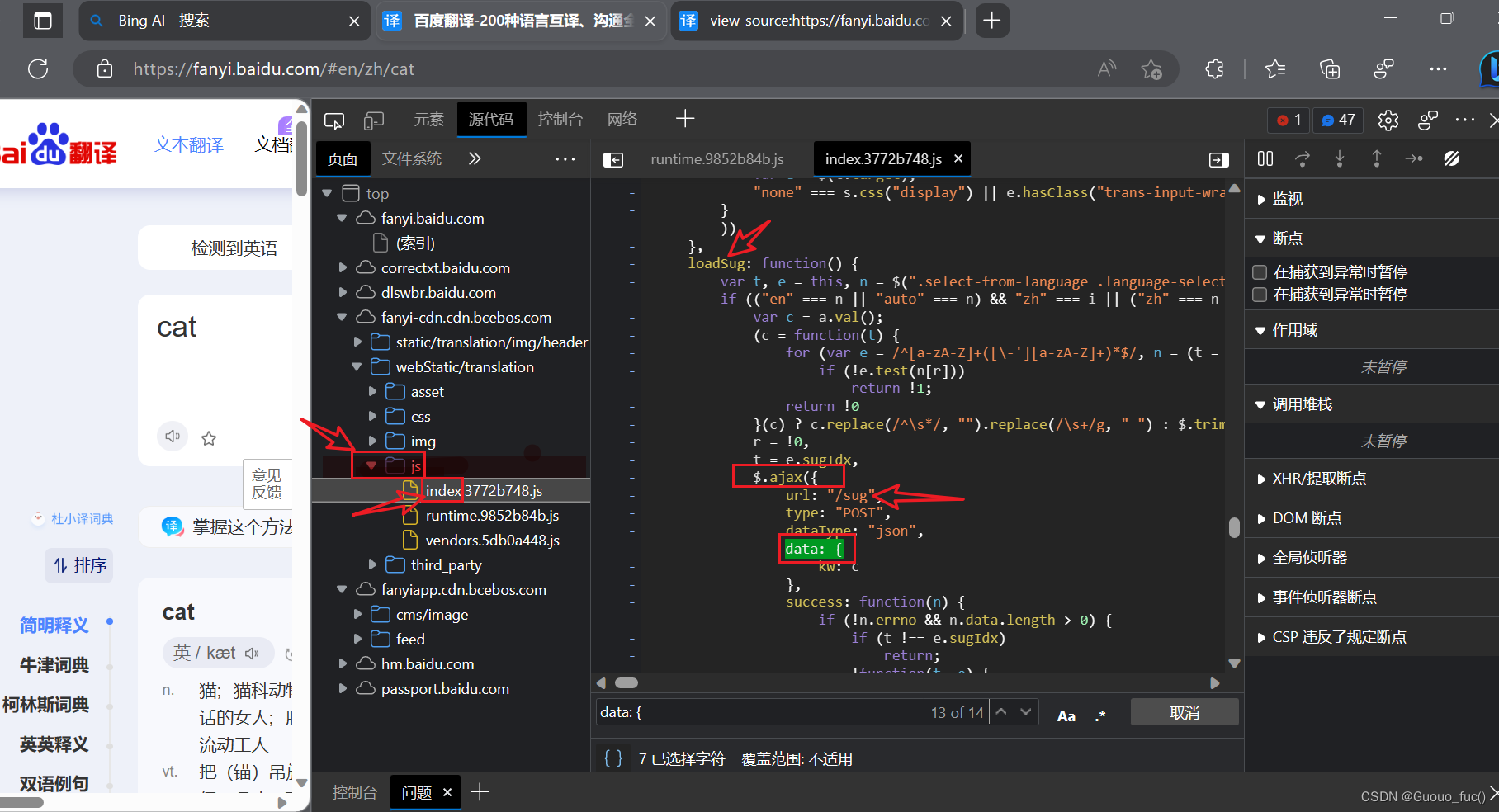
附上我的爬虫代码:
import requests
import json
if __name__ == "__main__":
while True:
post_url = "https://fanyi.baidu.com/sug"
my_ua_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.0.0'
}
my_data_input = input("please enter a word:")
my_data = {
'kw': my_data_input
}
response = requests.post(post_url, data=my_data, headers=my_ua_headers)
my_fileName = './' + my_data_input+'.json'
with open(my_fileName, 'w', encoding='utf-8')as fp:
result_json_dict = response.json()
json.dump(result_json_dict, fp=fp, ensure_ascii=False)
print("over!!!")举一反三之爬取豆瓣分类电影排行中的电影信息
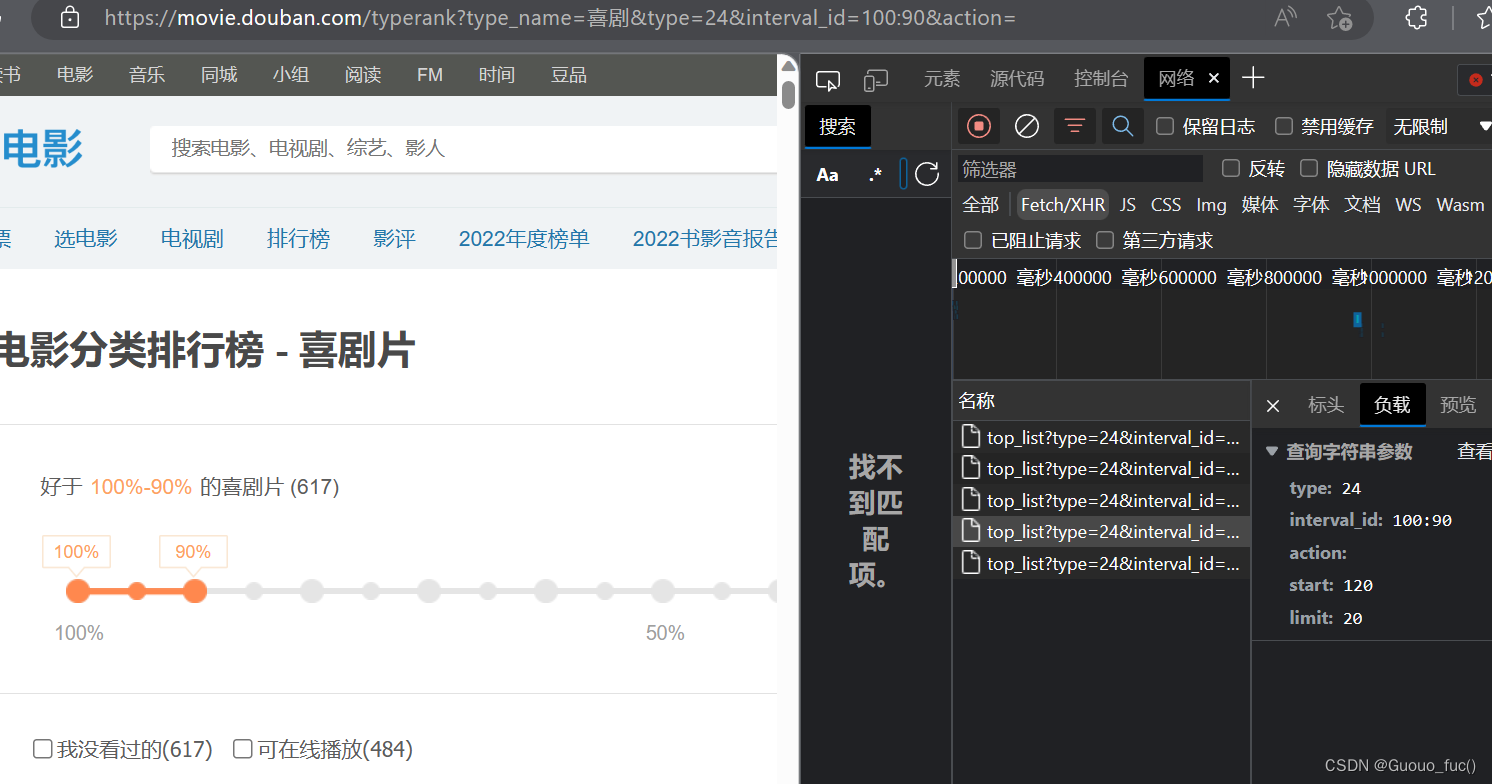
这里有一点点不一样在于查询的参数有多个,每个也有自己的意义,需要通过我们设定的字典传入请求中
下面是我的爬虫代码:
import json
import requests
if __name__ == "__main__":
my_url = 'https://movie.douban.com/j/chart/top_list?'
param = {#跟在url后面用于筛选内容的字典
'type': '24',
'interval_id': '100:90',#筛选评分为90-100分的
'action': '',
'start': '1',#表示从第一个开始(但并不包括第一个,即抓取的第一个实际上是网页显示的第二个)
'limit': '20'#表示一次最多筛选20个
}
my_header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.0.0'
}
response = requests.get(url=my_url, params=param, headers=my_header)
with open('./my_film.json', 'w', encoding='utf-8') as fp:
json_dict = response.json()
json.dump(json_dict, fp, ensure_ascii=False)小结
今天的爬虫学习主要在于添加UA标识,能够抓取动态局部刷新的数据,对爬取到的json文件的处理
但明显发现也有难点:比如在于data参数特定名称的查找对应,多个查询参数的理解与设定
这些都会影响爬虫的结果,甚至会导致爬虫出错,无法正常运行。
"道虽迩 不行不至 事虽小 不为不成" 虽然困难诸多,但一定要努力克服才能学真知,才能真正弄懂

















 65万+
65万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









