




为了以后在计算机行业的技术学习,了解了很多个方向,发现python爬虫也是一项必不可少的技能,而且实用性和操作性很强,所以蒟蒻开始了学习爬虫的第一天~
前期准备工作:
1.下载好pycharm:用于python编程的一款IDE,感觉挺好用的,免费而且能汉化,可以加插件
2.向pycharm中导入requests库,之后还有别的库需要添加,这里暂时先只用添加requests,具体的操作:打开pycharm---文件---设置---项目:xxx(你创建的项目)---python解释器--搜索requests右边就有官方连接可以下载
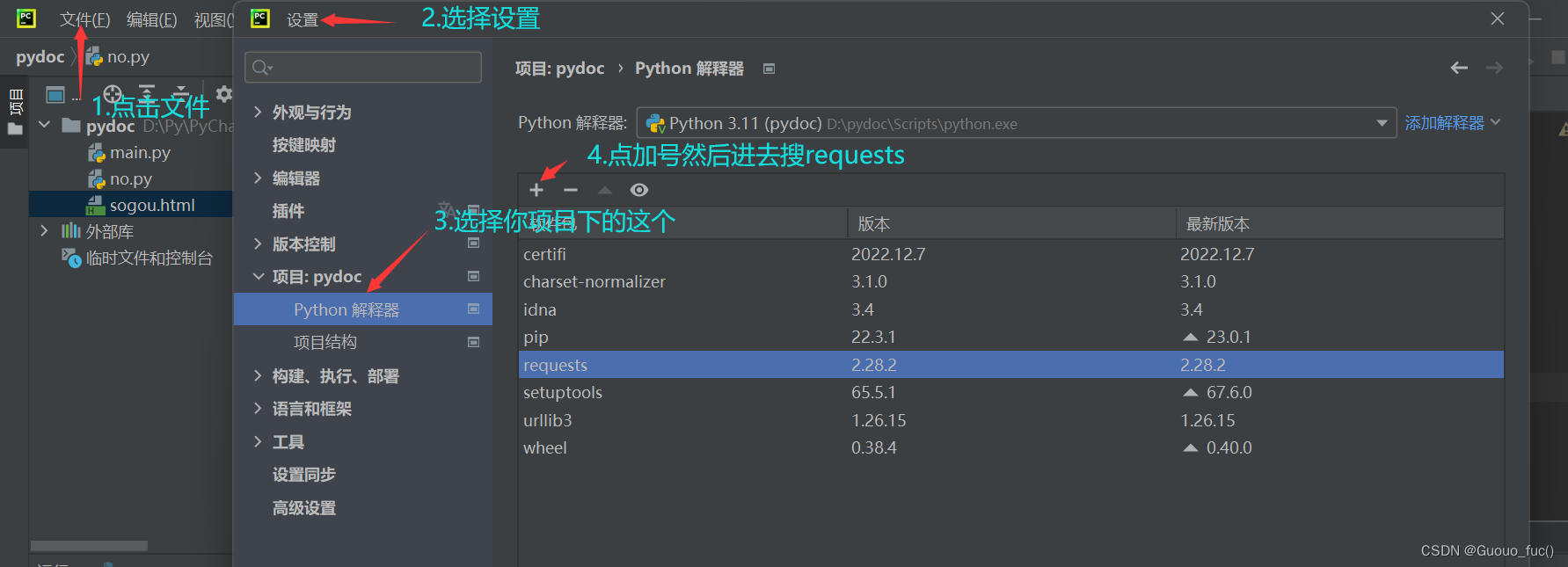
当然有更直接的方法:win+r打开运行窗口---输入cmd按确认----(进入命令行后)直接输入pip install requests就可以直接将库导入到你的pycharm中啦。
最基本的爬虫代码书写:
先上板子,因为任何额外的芝士都没学,我的爬虫”一血“
整体的书写思路:
- 指定url(输入具体网址)
- 发起请求(get/post请求)
- 获取响应数据
- 持久化存储
import requests # 导入requests库,它是一个用于发送HTTP请求的第三方库。
if __name__ =="__main__": # 这一行代码用于判断当前脚本是否作为主程序运行。如果是,则执行下面的代码。
url = "https://www.sogou.com/" # 定义一个字符串变量url,它的值为搜狗首页的URL。
requests.get(url=url) # 使用requests库的get方法向指定的URL发起请求。
response = requests.get(url=url) # 再次使用get方法向指定的URL发起请求,并将返回值赋值给response变量。
page_text = response.text # 从response中提取响应数据,这里使用了response的text属性,它返回字符串形式的响应数据。
print(page_text) # 打印响应数据。
with open('./sogou.html', 'w', encoding="utf-8") as fp: # 使用with语句打开一个文件,文件名为'sogou.html',写入模式为'w',编码方式为'utf-8'。打开的文件对象赋值给fp变量。
fp.write(page_text) # 调用fp的write方法,将响应数据写入到文件中。
print("爬取数据结束!!!") # 打印“爬取数据结束!!!”表示爬取过程结束。
虽然写好了注释但是还是有几个点详细讲一下叭,毕竟以后都会涉及
open内的第一个字段'./sogou.html'的意思是:在当前python代码执行文件的同一个文件夹下生成一个名字为sogou,文件类型为html的文件。运行后在我的文件夹里效果如图:
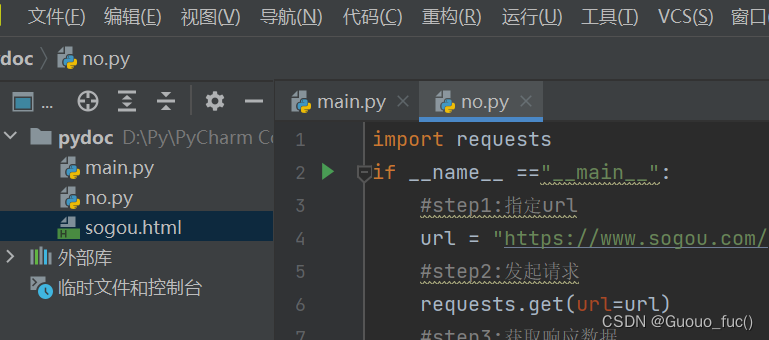
其中open内的'w'表示:我们使用了'w'模式,它表示写入模式。在这种模式下,如果文件不存在,会创建一个新文件;如果文件已存在,会清空文件内容。
除了'w'模式,还有其他几种常用的模式:
'r':读取模式。在这种模式下,只能读取文件内容,不能写入。
'a':追加模式。在这种模式下,如果文件不存在,会创建一个新文件;如果文件已存在,会在文件末尾追加内容。
'x':创建模式。在这种模式下,如果文件不存在,会创建一个新文件;如果文件已存在,则会抛出异常。
'b':二进制模式。可以与其他模式结合使用,如'rb'表示以二进制读取模式打开文件。
requests库的get函数用于向指定的URL发起GET请求。它的完整参数如下:
requests.get(url, params=None, **kwargs)
url:要获取页面的URL链接。params:URL中的额外参数,字典或字节流格式,可选。**kwargs:12个控制访问的参数。
我上面的代码仅使用了url参数,其它的参数是便于我们爬取指定内容而需额外添加的,我们这里是最基本的爬虫,所以没有额外添加其他参数了。
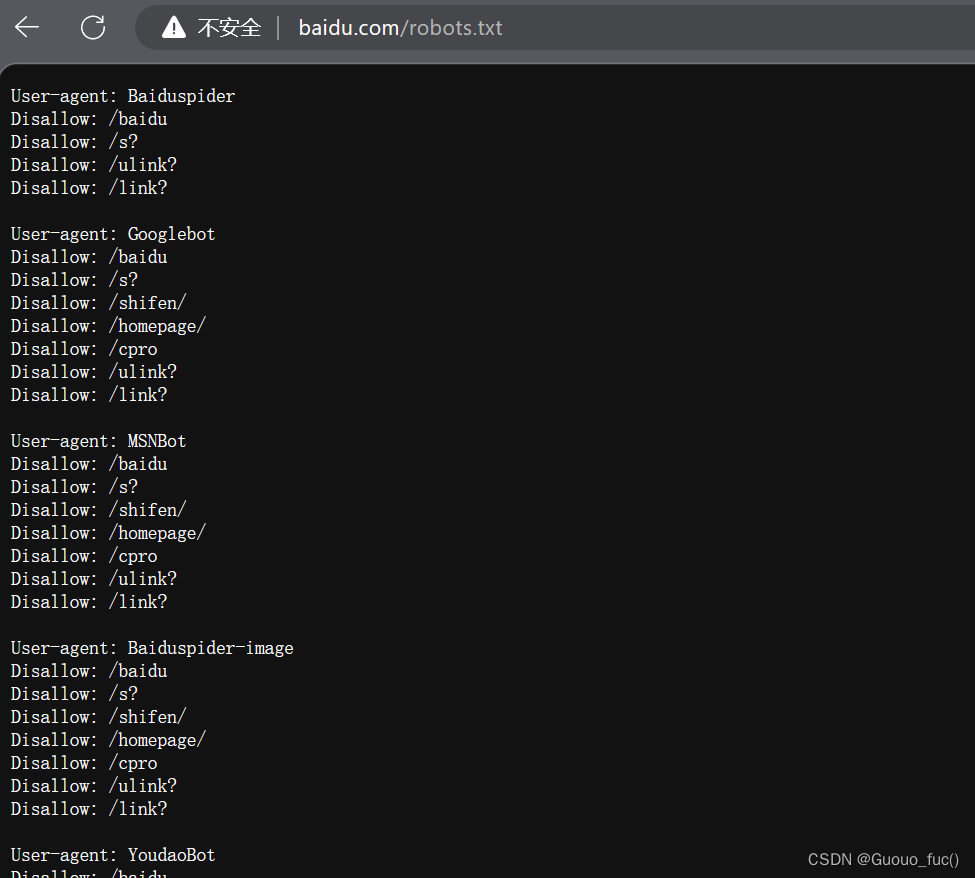
!:一个小tip,由于有些网站是不希望我们通过爬虫来获取特定信息内容的,我们为了不冒犯到网站,可以事先在网站域名后加/robots.txt 来访问到该网站不希望哪些信息被爬,哪些允许被爬,这样我们就可以在合法范围内用我们的爬虫咯
(这是我访问到的百度下的robots君子协议(doge

















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









