




llama.cpp 是 Ollama、LMStudio 和其他很多热门项目的底层实现,也是 GPUStack 所支持的推理引擎之一,它提供了 GGUF 模型文件格式。GGUF (General Gaussian U-Net Format) 是一种用于存储模型以进行推理的文件格式,旨在针对推理进行优化,可以快速加载和运行模型。
llama.cpp 还支持量化模型,在保持较高的模型精度的同时,减少模型的存储和计算需求,使大模型能够在桌面端、嵌入式设备和资源受限的环境中高效部署,并提高推理速度。
今天带来一篇介绍如何制作并量化 GGUF 模型,将模型上传到 HuggingFace 和 ModelScope 模型仓库的操作教程。
注册与配置 HuggingFace 和 ModelScope
- 注册 HuggingFace
访问 https://huggingface.co/join 注册 HuggingFace 账号(需要某上网条件)
- 配置 HuggingFace SSH 公钥
将本地环境的 SSH 公钥添加到 HuggingFace,查看本地环境的 SSH 公钥(如果没有可以用 ssh-keygen -t rsa -b 4096 命令生成):
cat ~/.ssh/id_rsa.pub
在 HuggingFace 的右上角点击头像,选择 Settings - SSH and GPG Keys,添加上面的公钥,用于后面上传模型时的认证。
- 注册 ModelScope
访问 https://www.modelscope.cn/register?back=%2Fhome 注册 ModelScope 账号
- 获取 ModelScope Token
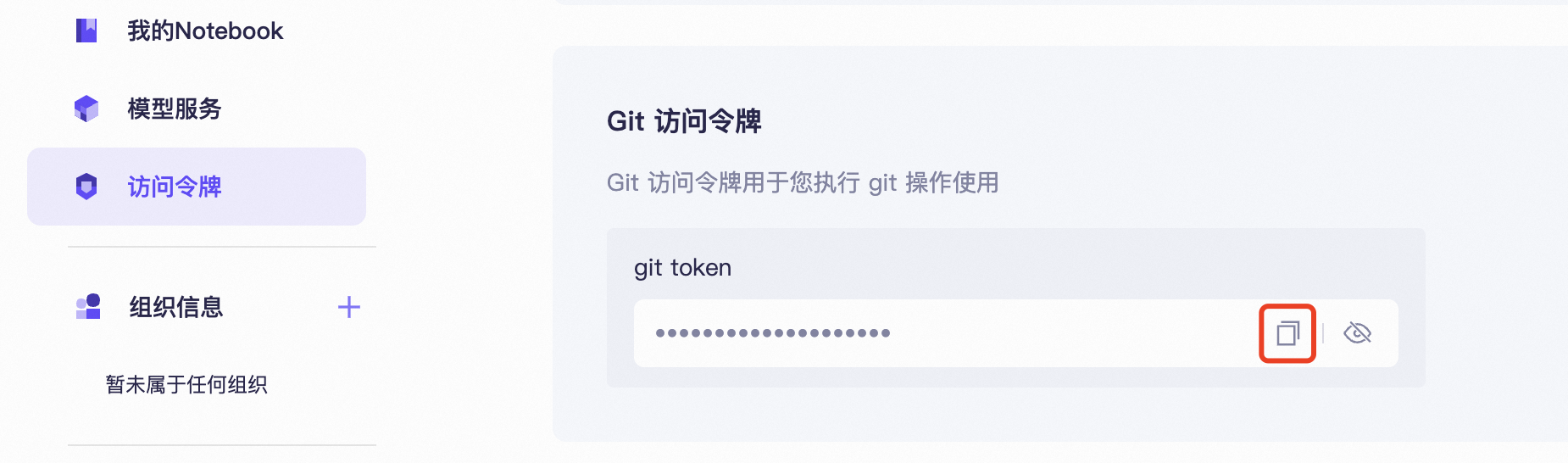
访问 https://www.modelscope.cn/my/myaccesstoken,将 Git 访问令牌复制保存,用于后面上传模型时的认证。
准备 llama.cpp 环境
创建并激活 Conda 环境(没有安装的参考 Miniconda 安装:https://docs.anaconda.com/miniconda/):
conda create -n llama-cpp python=3.12 -y
conda activate llama-cpp
which python
pip -V
克隆 llama.cpp 的最新分支代码,编译量化所需的二进制文件:
cd ~
git clone -b b4034 https://github.com/ggerganov/llama.cpp.git
cd llama.cpp/
pip install -r requirements.txt
brew install cmake
make

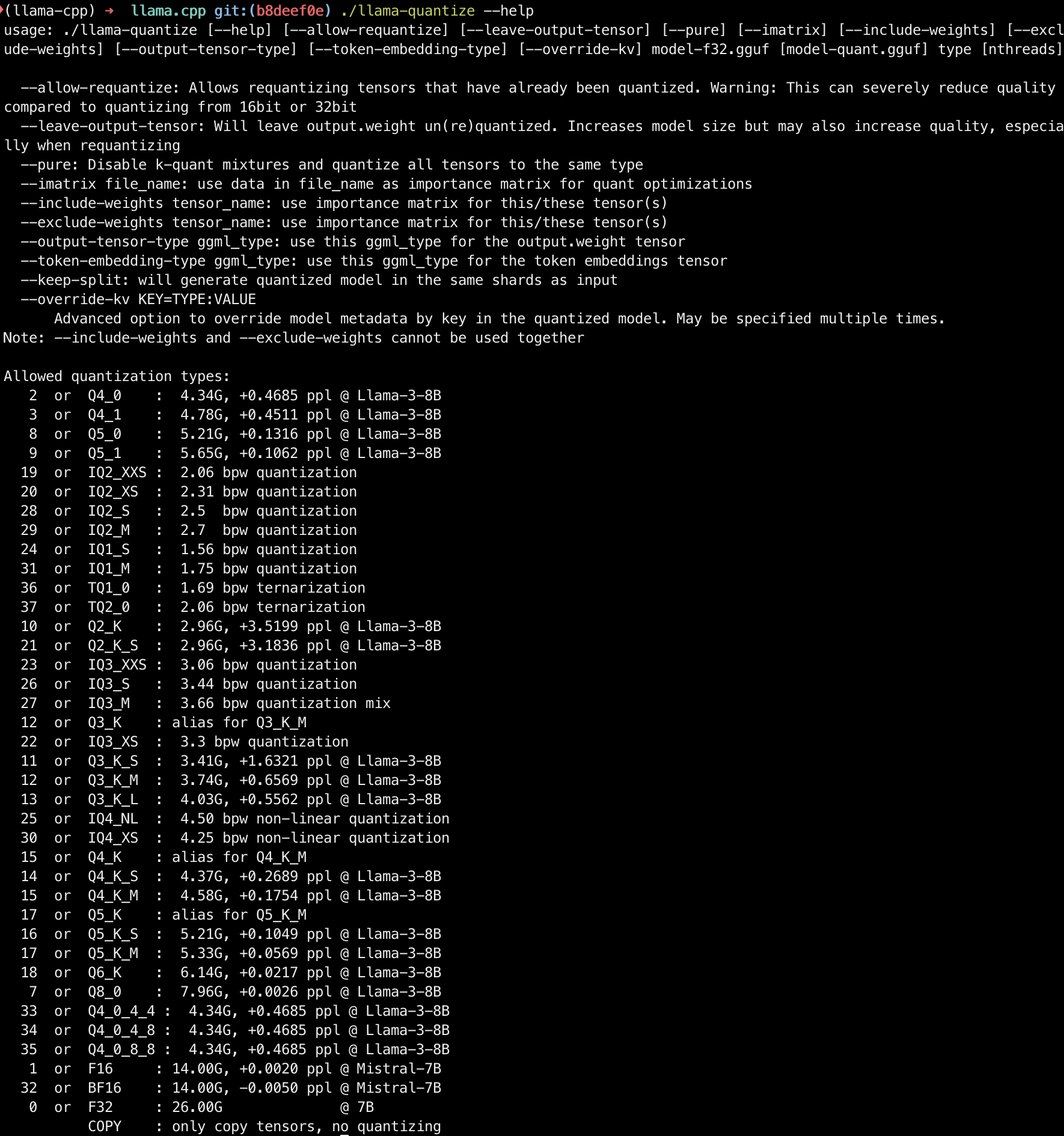
编译完成后,可以运行以下命令确认量化所需要的二进制文件 llama-quantize 是否可用:
./llama-quantize --help
下载原始模型
下载需要转换为 GGUF 格式并量化的原始模型。
从 HuggingFace 下载模型,通过 HuggingFace 提供的 huggingface-cli 命令下载,首先安装依赖:
pip install -U huggingface_hub
国内网络配置下载镜像源:
export HF_ENDPOINT=https://hf-mirror.com
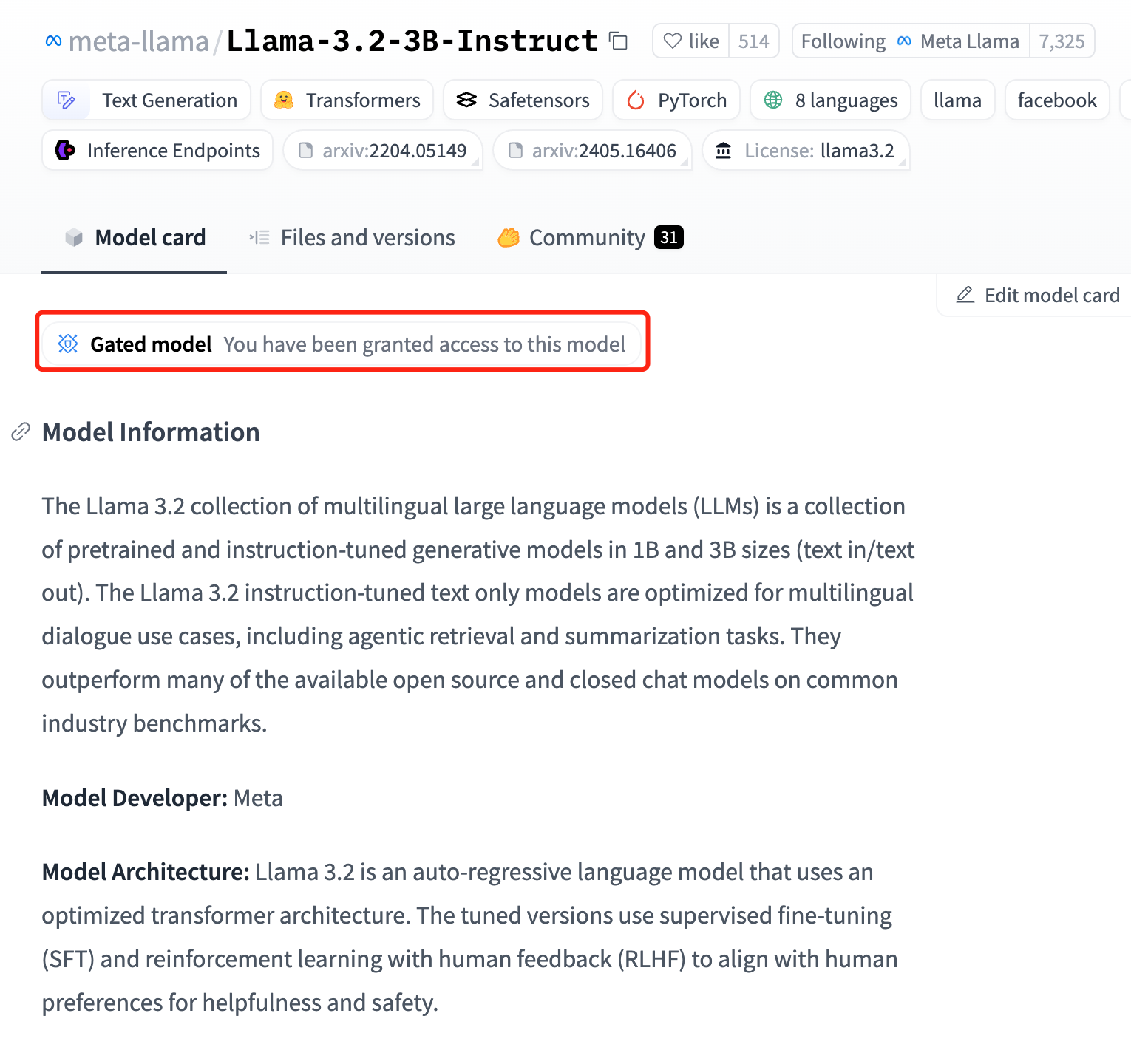
这里下载 meta-llama/Llama-3.2-3B-Instruct 模型,该模型是 Gated model,需要在 HuggingFace 填写申请并确认获得访问授权:
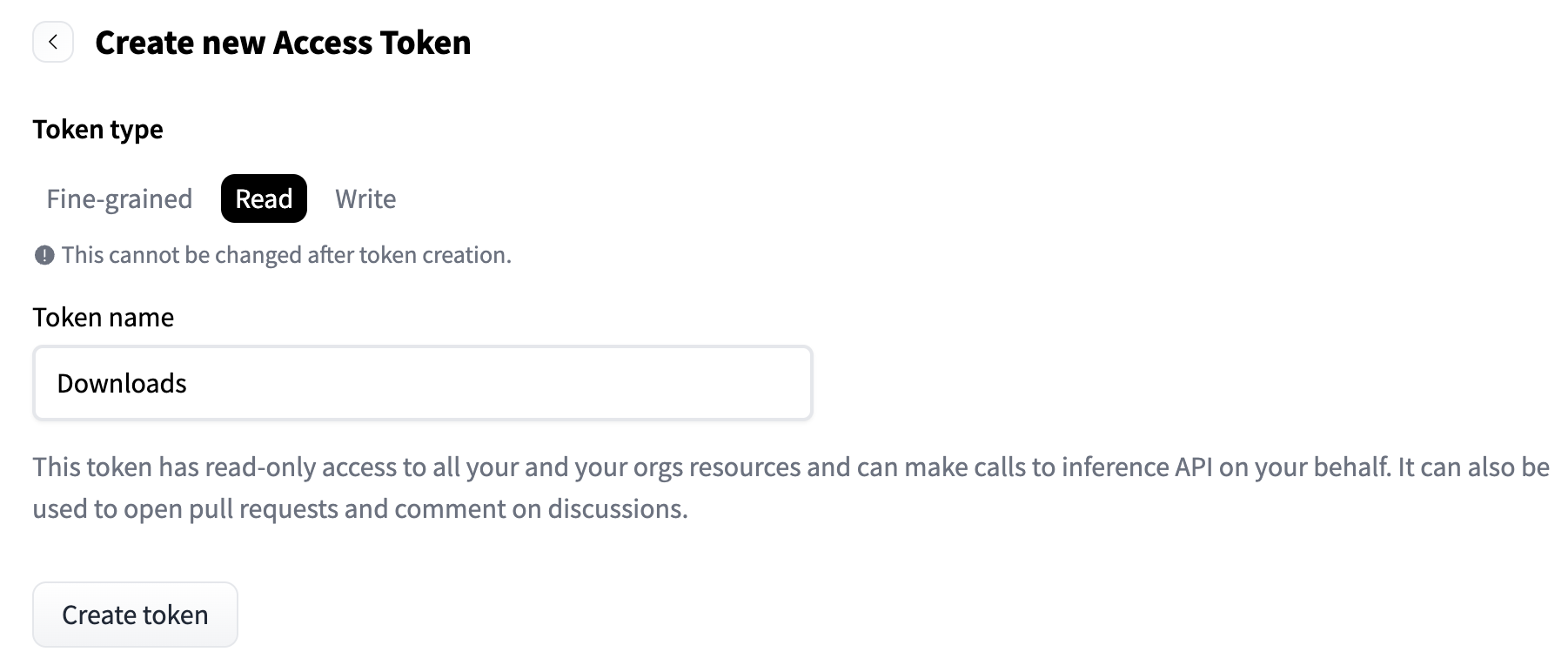
在 HuggingFace 的右上角点击头像,选择 Access Tokens,创建一个 Read 权限的 Token,保存下来:
下载 meta-llama/Llama-3.2-3B-Instruct 模型,--local-dir 指定保存到当前目录,--token 指定上面创建的访问 Token:
mkdir ~/huggingface.co
cd ~/huggingface.co/
huggingface-cli download meta-llama/Llama-3.2-3B-Instruct --local-dir Llama-3.2-3B-Instruct --token hf_abcdefghijklmnopqrstuvwxyz
转换为 GGUF 格式与量化模型
创建 GGUF 格式与量化模型的脚本:
cd ~/huggingface.co/
vim quantize.sh
填入以下脚本内容,并把 llama.cpp 和 huggingface.co
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









