






 本文介绍了LamaCleaner这款AI图片处理工具,可用于一键去除图片中的水印、人物和背景等内容,支持CPU和GPU模式,通过详细步骤指导用户安装、启动和测试其去水印效果。
本文介绍了LamaCleaner这款AI图片处理工具,可用于一键去除图片中的水印、人物和背景等内容,支持CPU和GPU模式,通过详细步骤指导用户安装、启动和测试其去水印效果。
使用AI工具Lama Cleaner一键去除水印、人物、背景等图片里的内容
前言
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- 基于DETR的人脸伪装检测
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- YOLOv5:TensorRT加速YOLOv5模型推理
前提条件
- 熟悉Python
相关介绍
- Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
- PyTorch 是一个深度学习框架,封装好了很多网络和深度学习相关的工具方便我们调用,而不用我们一个个去单独写了。它分为 CPU 和 GPU 版本,其他框架还有 TensorFlow、Caffe 等。PyTorch 是由 Facebook 人工智能研究院(FAIR)基于 Torch 推出的,它是一个基于 Python 的可续计算包,提供两个高级功能:1、具有强大的 GPU 加速的张量计算(如 NumPy);2、构建深度神经网络时的自动微分机制。
- Lama Cleaner是一款完全免费开源,而且没有人分辨率限制的图片去水印、修复工具:Lama Cleaner,内置了多种AI 模型构建,功能相当的齐全。可用于快速去除图像中各种水印、物品、人物、字体、等图像里的内容。
Lama Cleaner
- 项目地址:https://github.com/Sanster/lama-cleaner.git
环境要求
- torch>=1.9.0
- opencv-python
- flask==2.2.3
- flask-socketio
- simple-websocket
- flask_cors
- flaskwebgui==0.3.5
- pydantic
- rich
- loguru
- yacs
- diffusers==0.16.1
- transformers==4.27.4
- gradio
- piexif==1.1.3
- safetensors
- omegaconf
- controlnet-aux==0.0.3
安装Lama Cleaner
- pip安装前,需要安装Python环境
pip install lama-cleaner
或者
pip install lama-cleaner -i https://pypi.tuna.tsinghua.edu.cn/simple # 使用国内镜像源,下载速度更快。
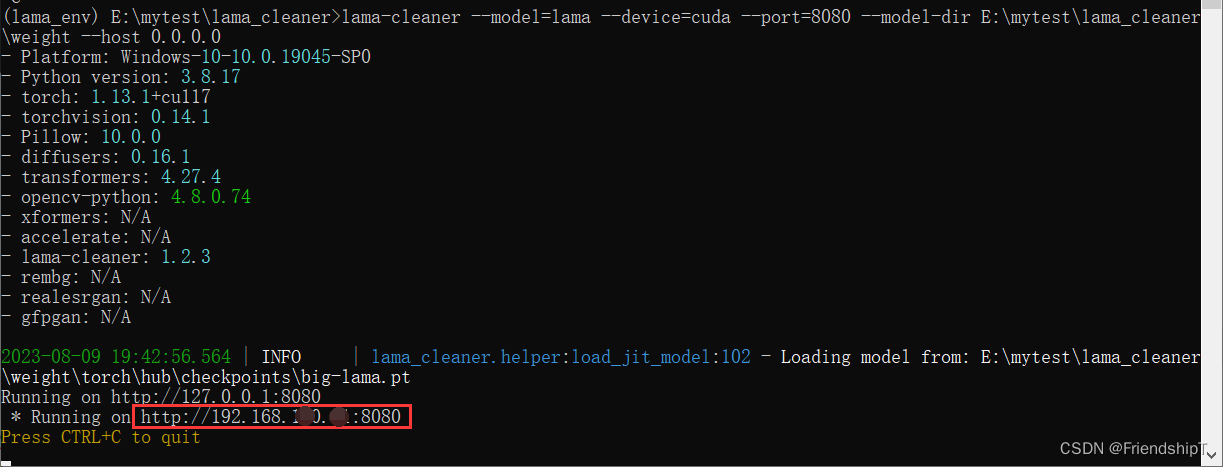
启动Lama Cleaner
CPU方式启动
lama-cleaner --model=lama --device=cpu --port=8080
GPU方式启动
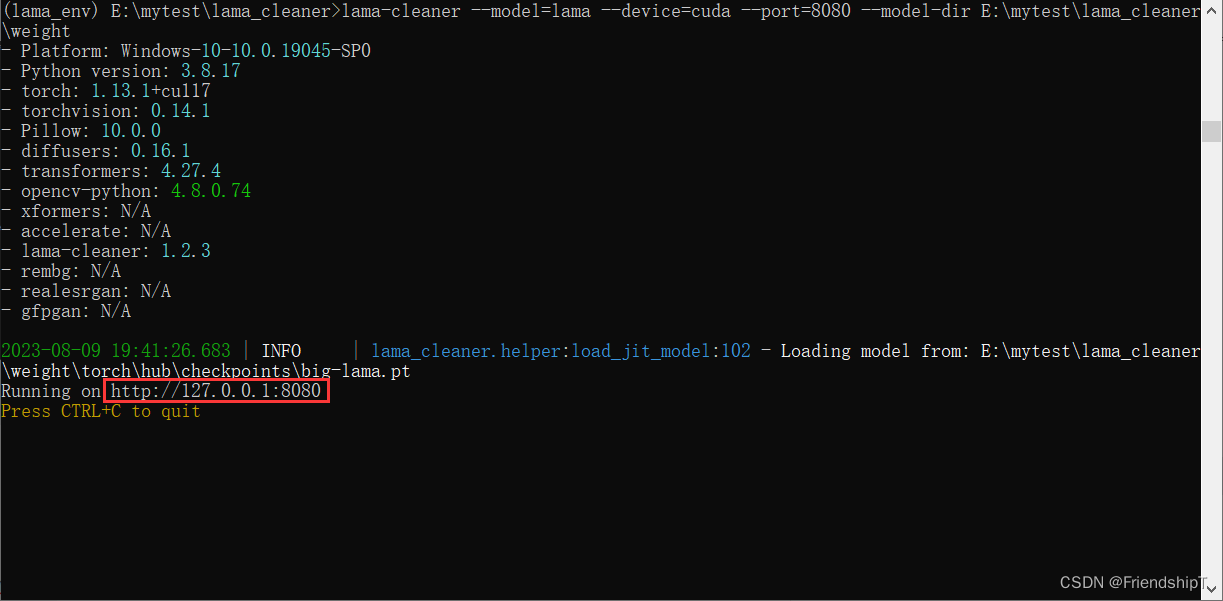
## 本机浏览
lama-cleaner --model=lama --device=cuda --port=8080 --model-dir E:\mytest\lama_cleaner\weight
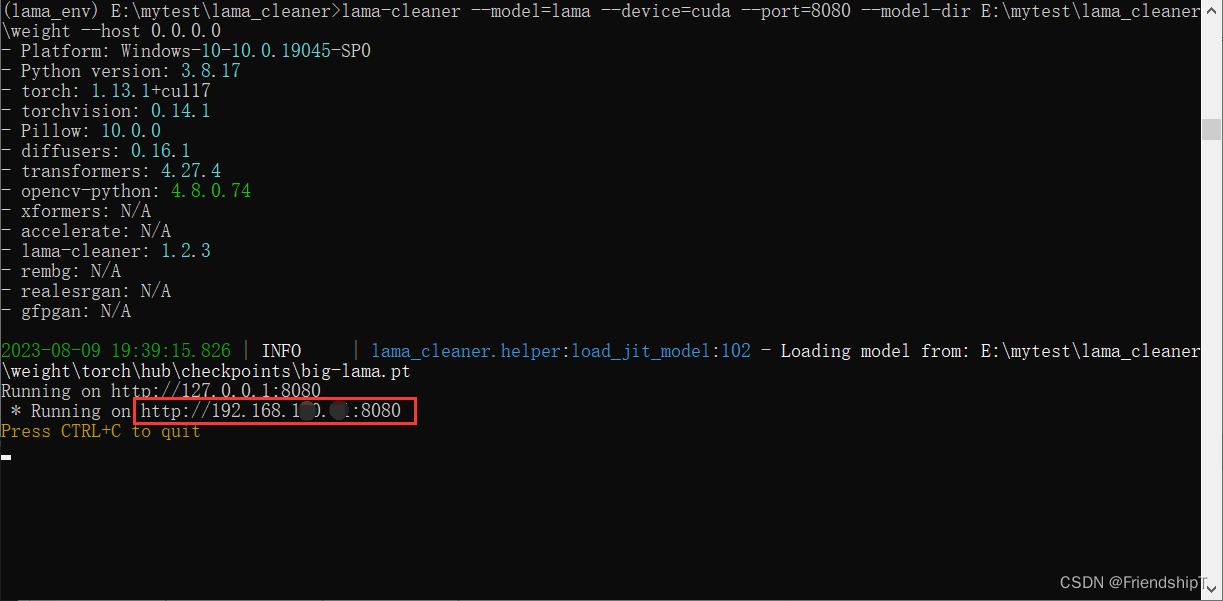
## 局域网内浏览
lama-cleaner --model=lama --device=cuda --port=8080 --model-dir E:\mytest\lama_cleaner\weight --host 0.0.0.0
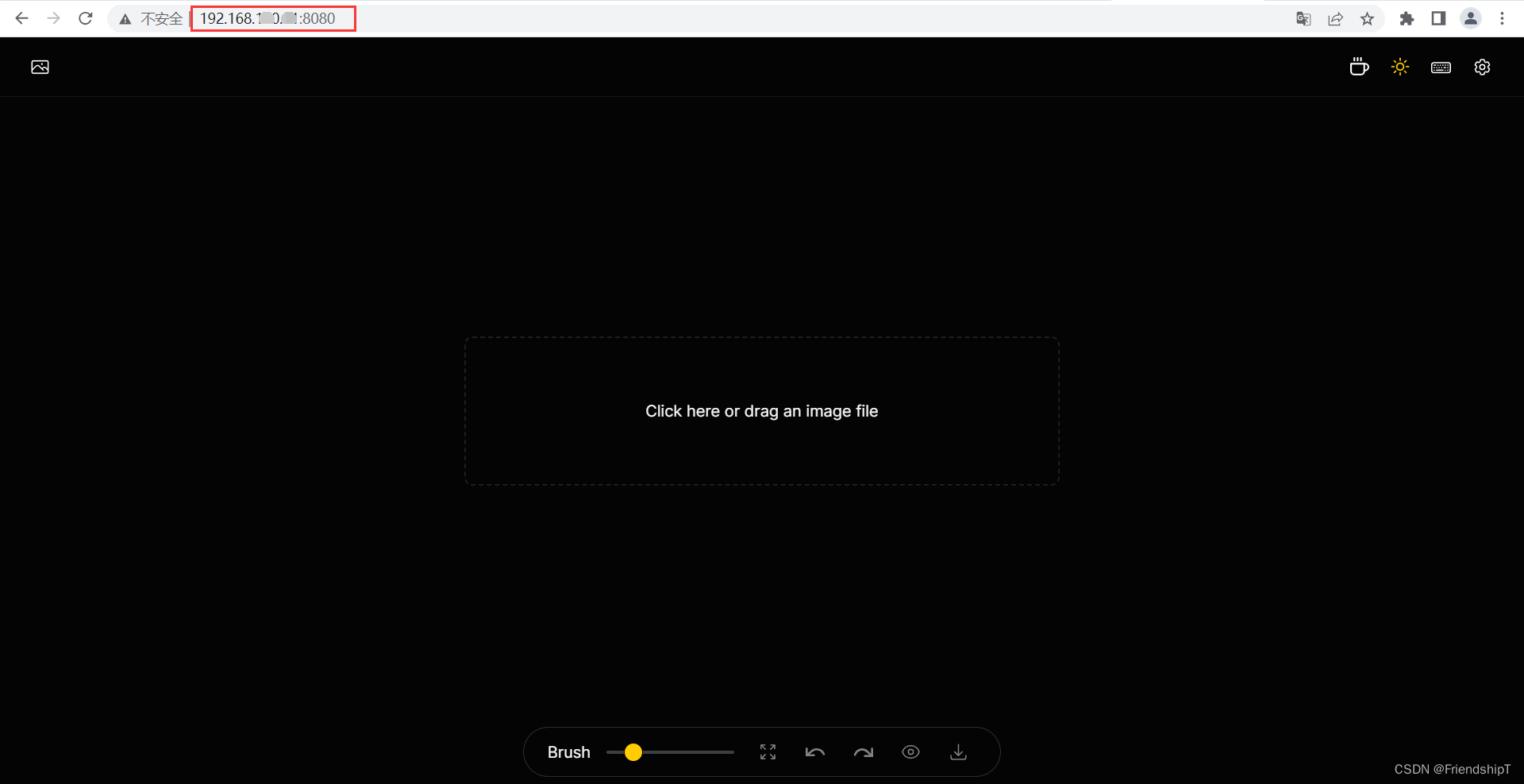
使用Lama Cleaner
- 在浏览器打开网址:
http://IP地址:8080
测试结果
NO.1 检测框
- 打开要原图片
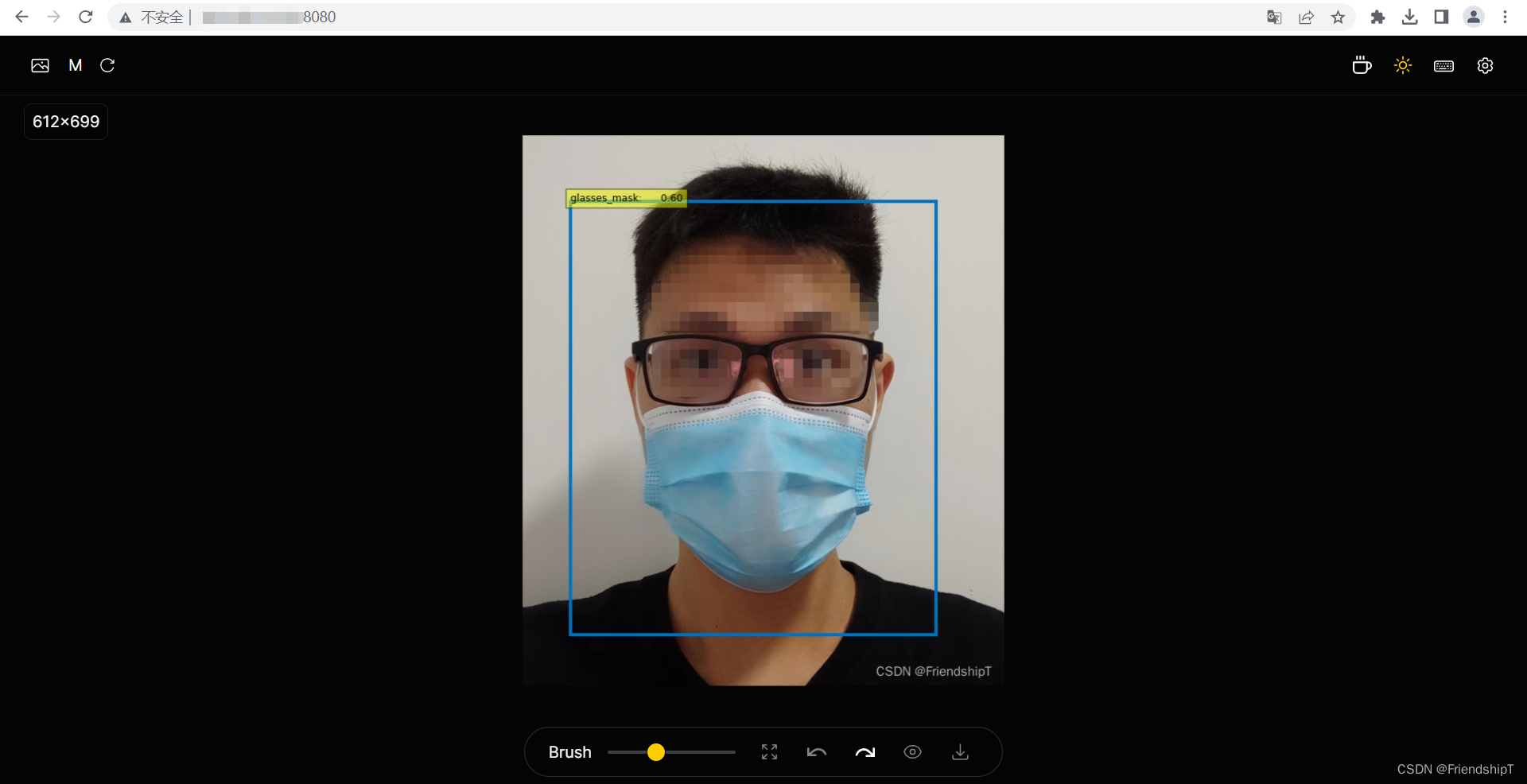
- 按住鼠标,去除图片内的内容(黄色轨迹)

- 效果图
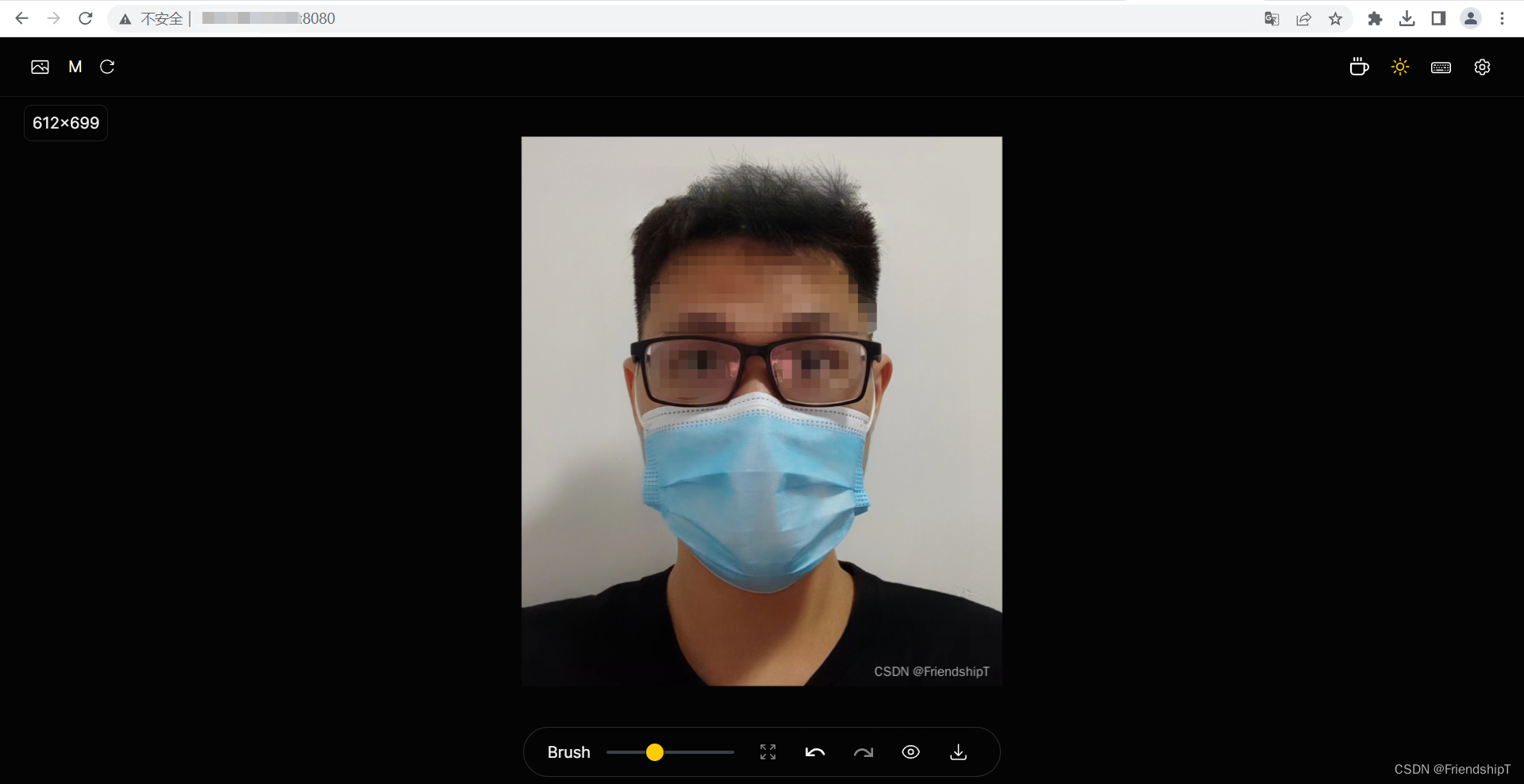
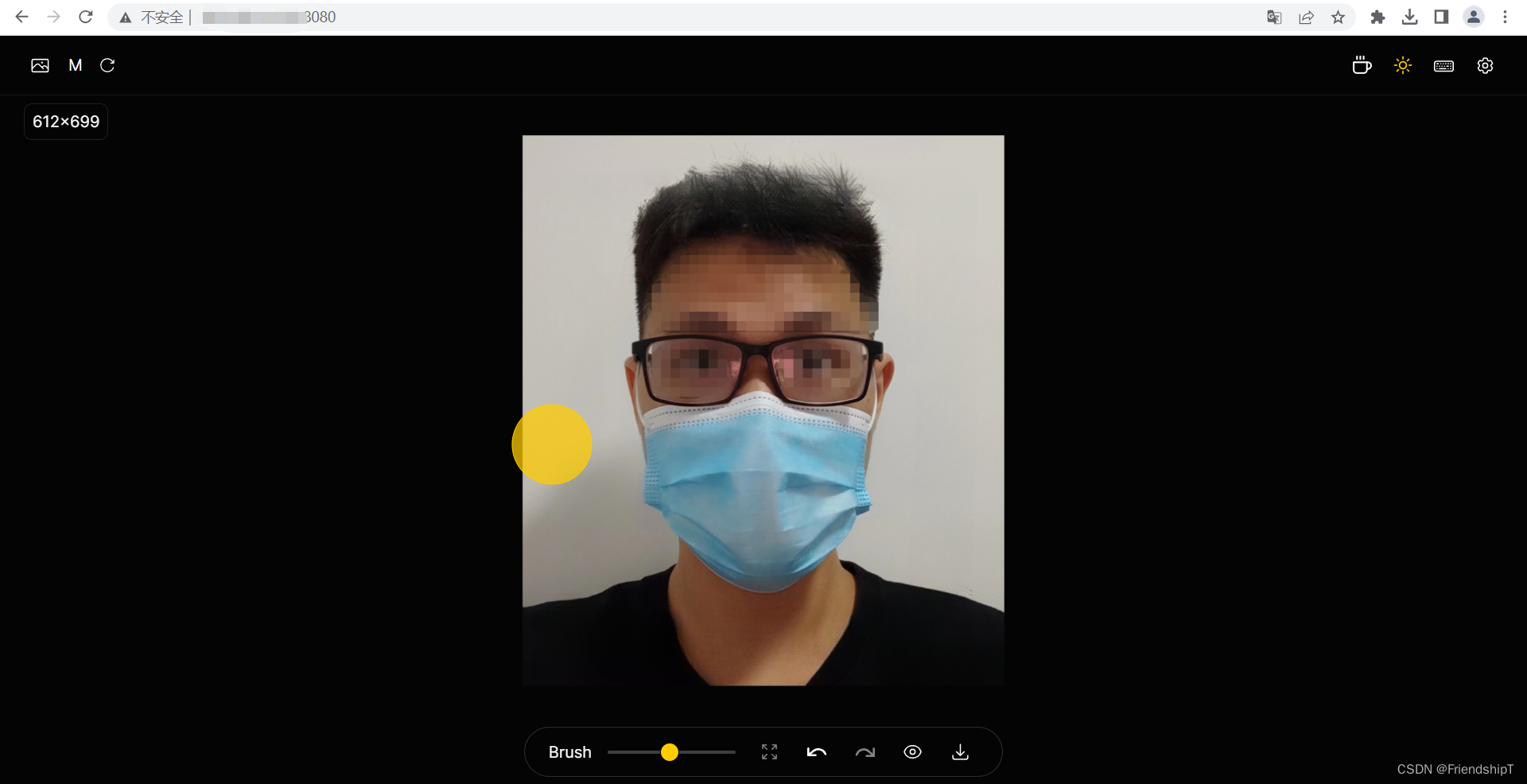
NO.2 水印
- 打开要原图片
- 按住鼠标,去除图片内的内容(黄色轨迹)
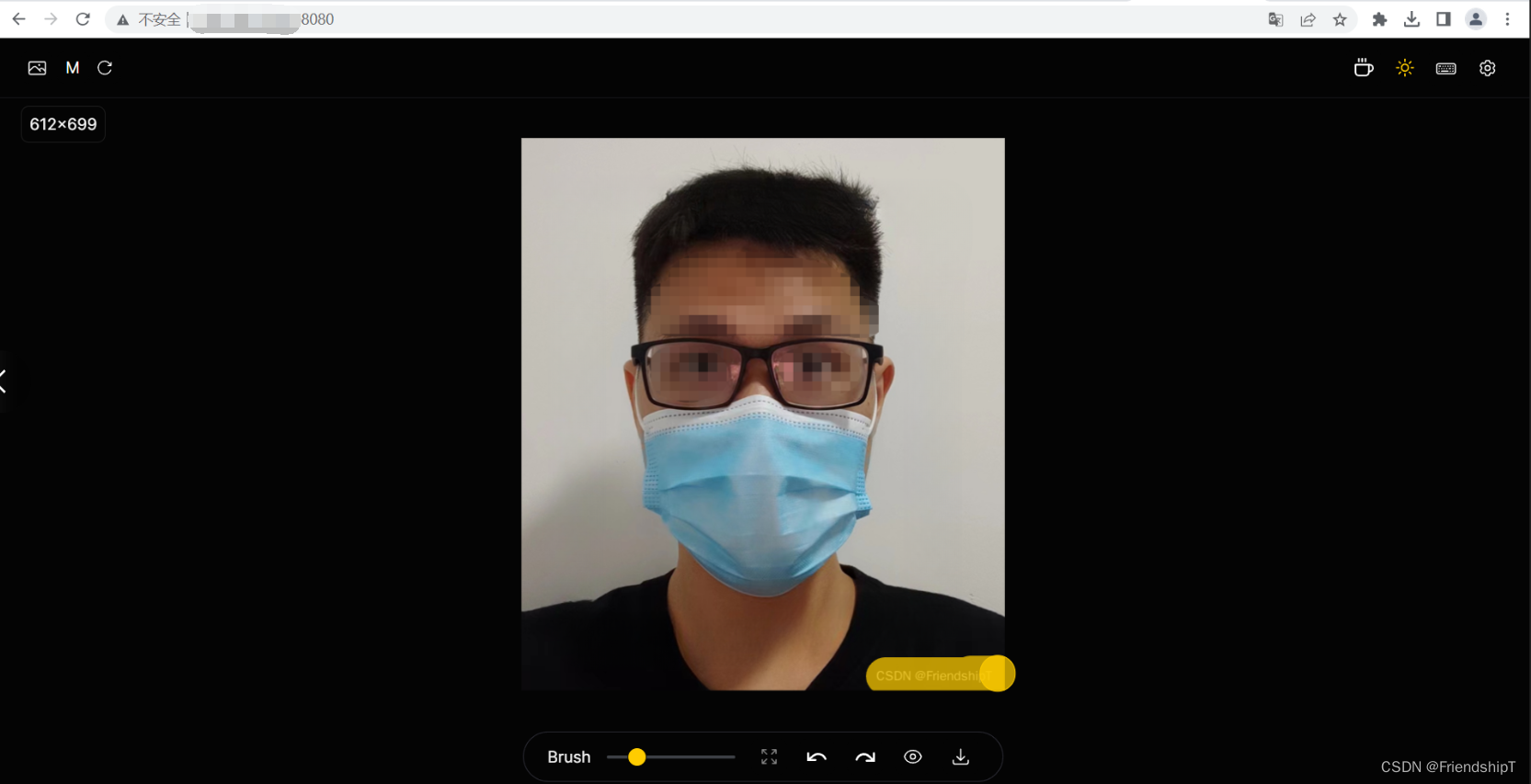
- 效果图
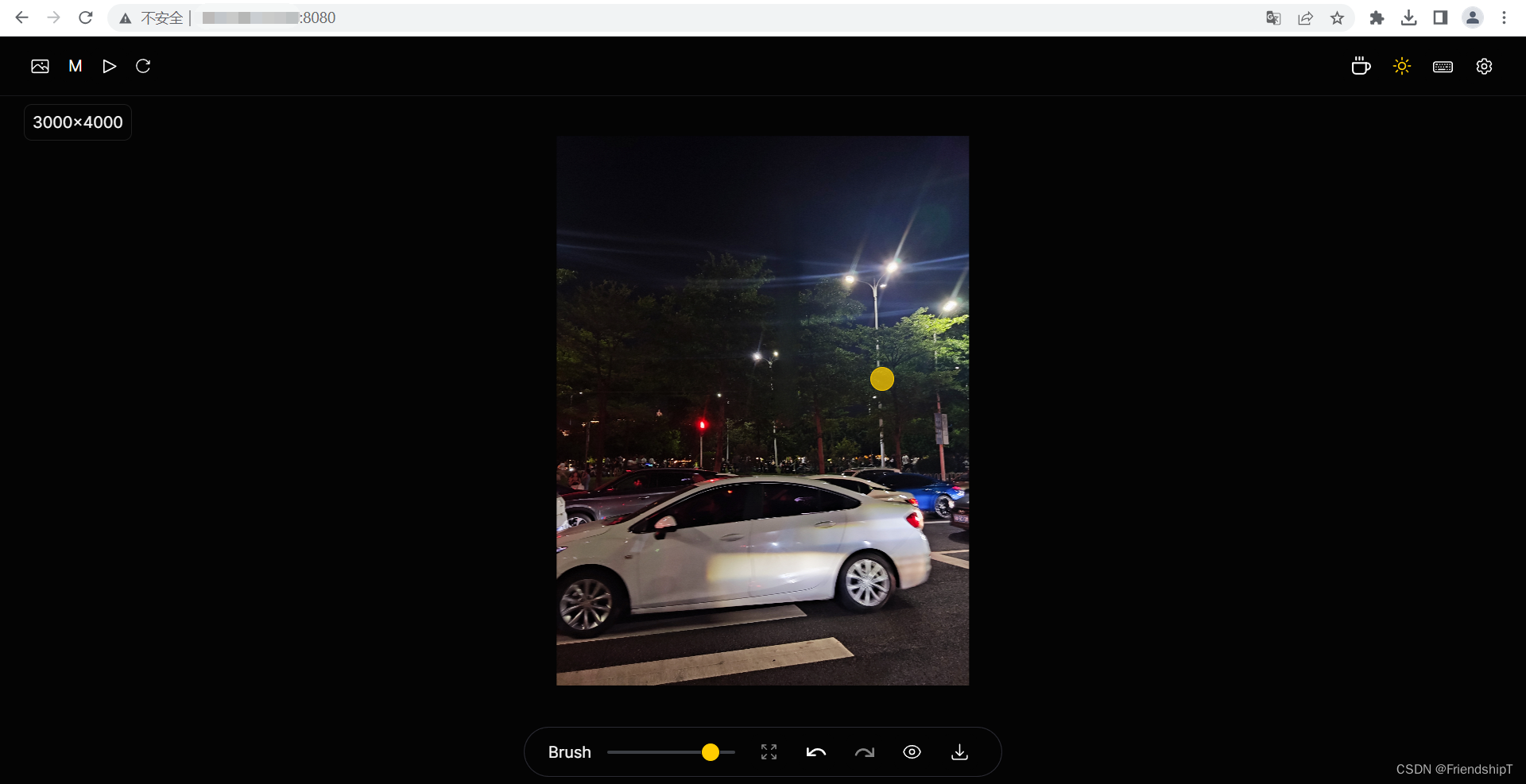
NO.3 广州塔
-
打开要原图片

-
按住鼠标,去除图片内的内容(黄色轨迹)
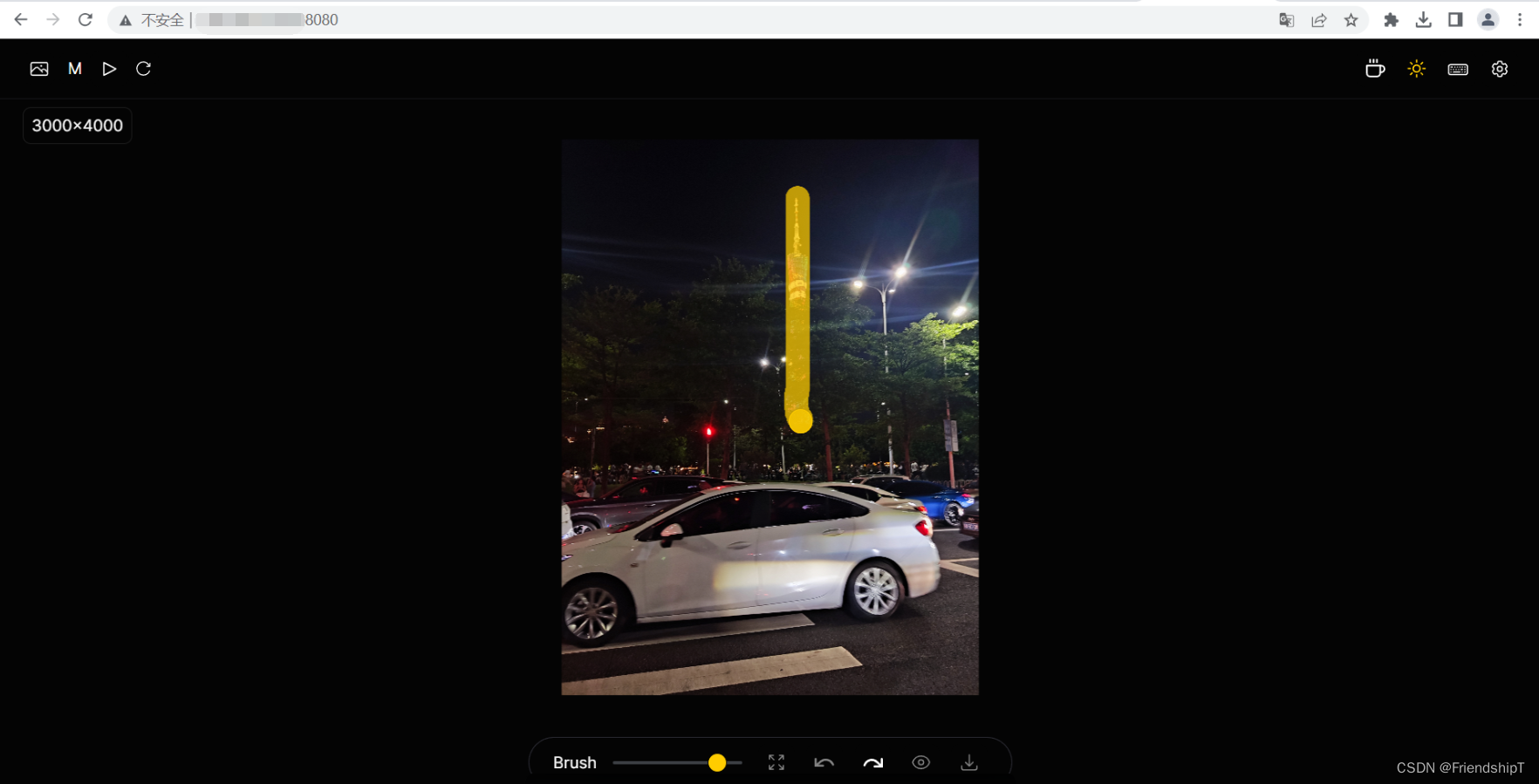
-
效果图
NO.4 人物背景
-
打开要原图片
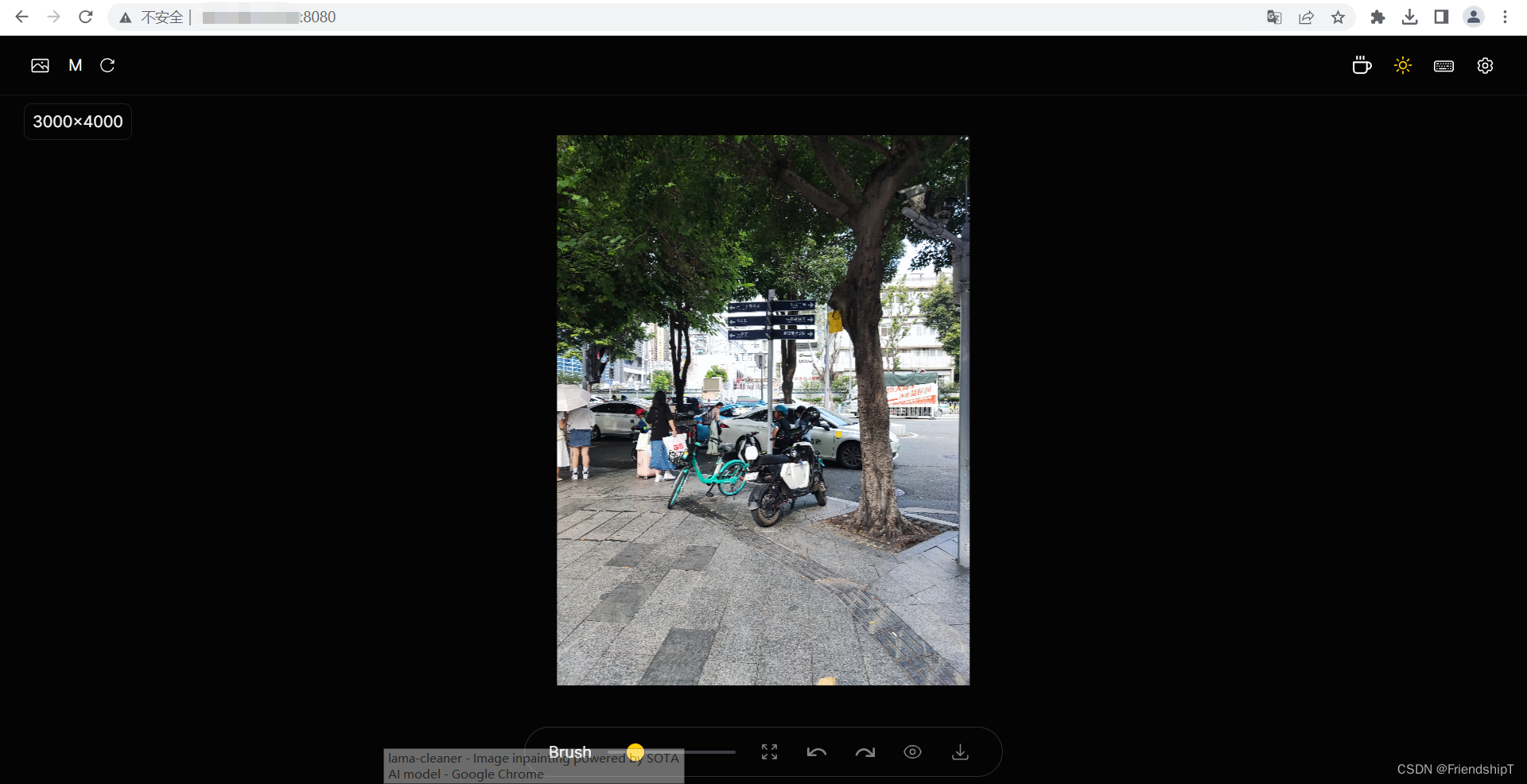
-
按住鼠标,去除图片内的内容(黄色轨迹)
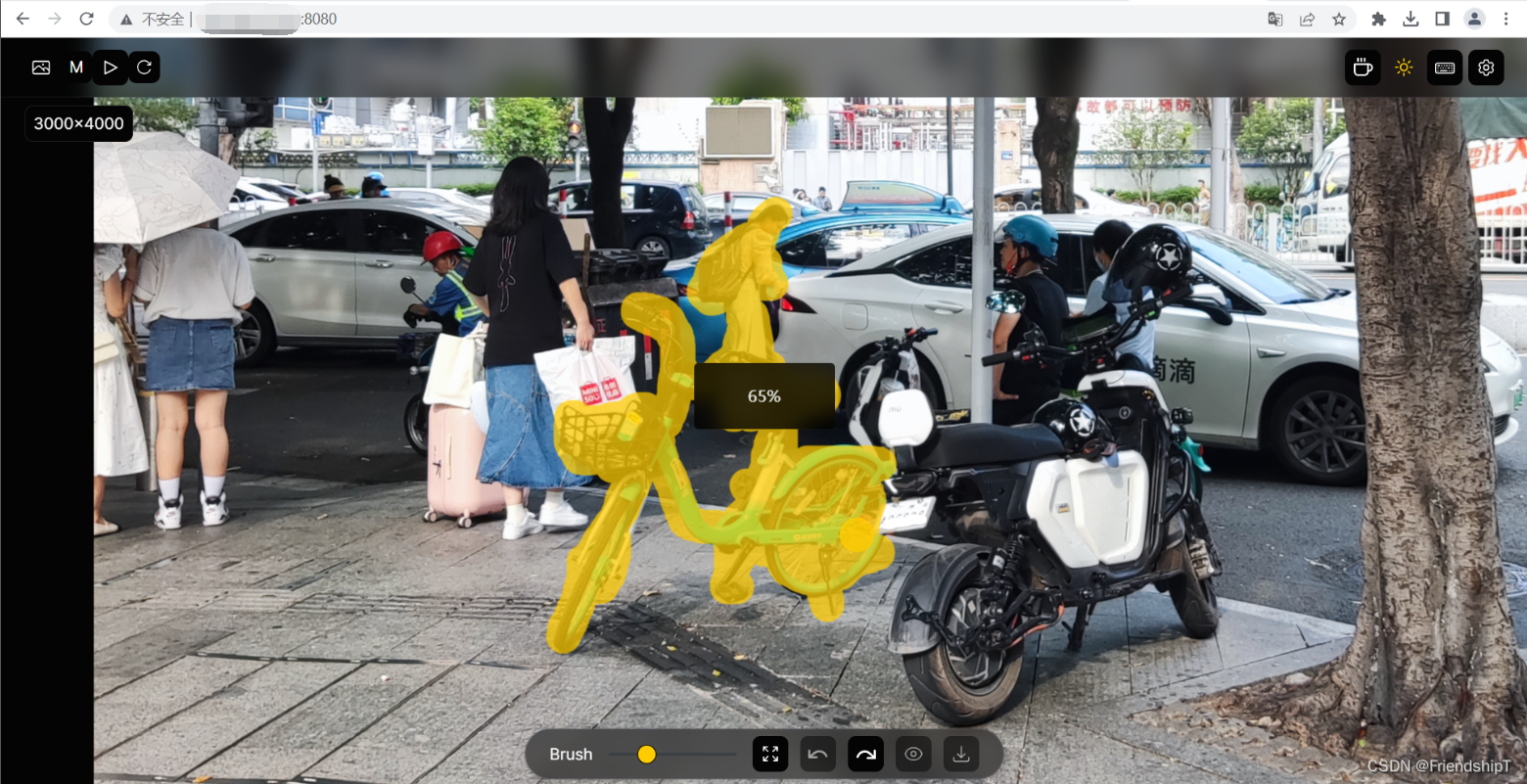
-
效果图
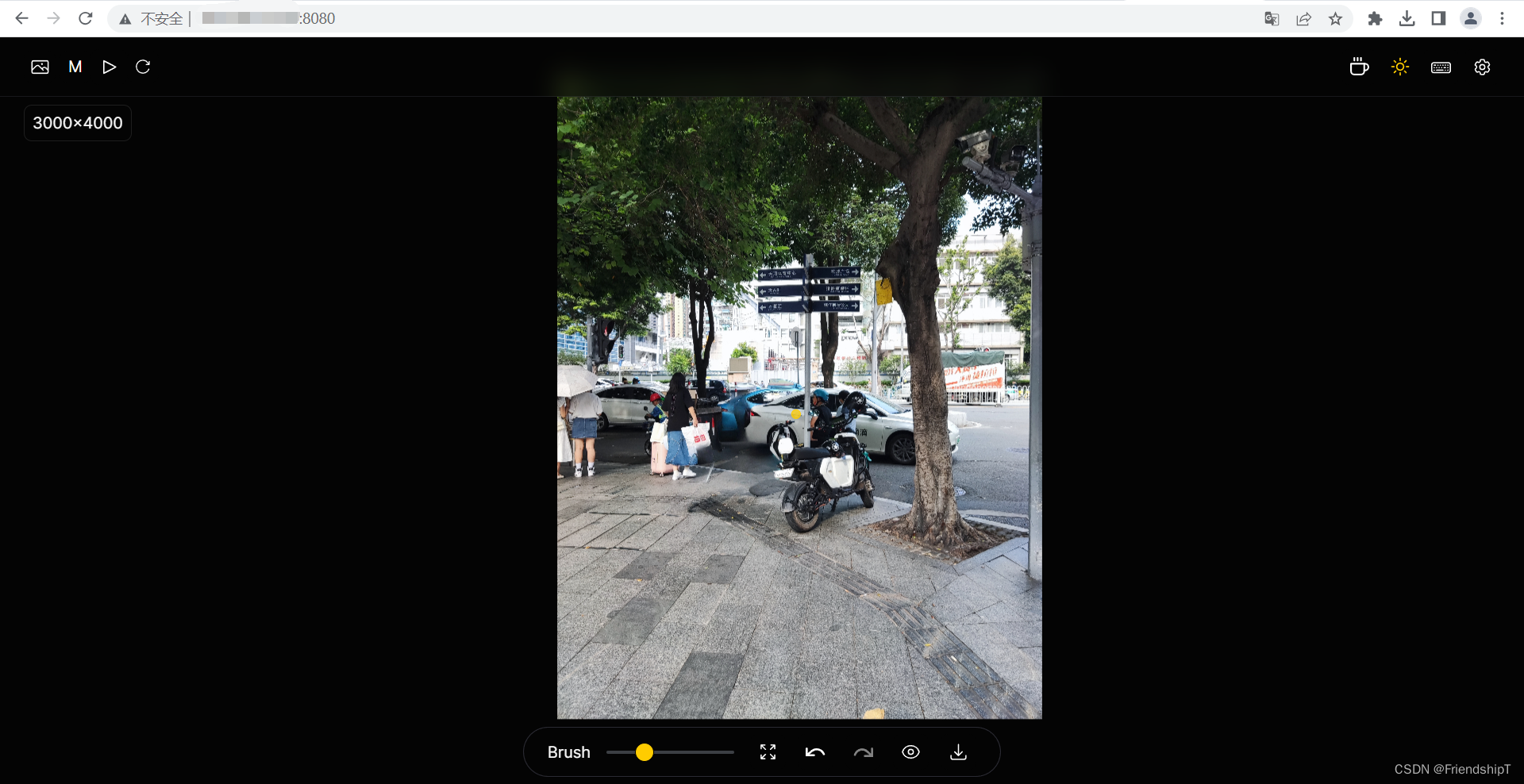
参考
[1] https://github.com/Sanster/lama-cleaner.git
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- 基于DETR的人脸伪装检测
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
- YOLOv5:TensorRT加速YOLOv5模型推理




















 3815
3815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











