



 博客介绍了在VMware中克隆虚拟机,设置网卡,对data1、data2和master虚机进行hostname、hosts文件等配置。之后,master连接到data1、data2创建HDFS目录,创建并格式化NameNone HDFS,启动Hadoop多节点集群,还可查看进程、打开Web界面及创建查看HDFS目录。
博客介绍了在VMware中克隆虚拟机,设置网卡,对data1、data2和master虚机进行hostname、hosts文件等配置。之后,master连接到data1、data2创建HDFS目录,创建并格式化NameNone HDFS,启动Hadoop多节点集群,还可查看进程、打开Web界面及创建查看HDFS目录。
VMware部署Spark集群
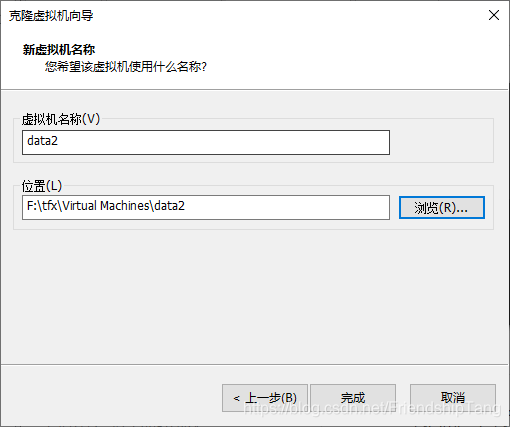
VMware克隆虚拟机
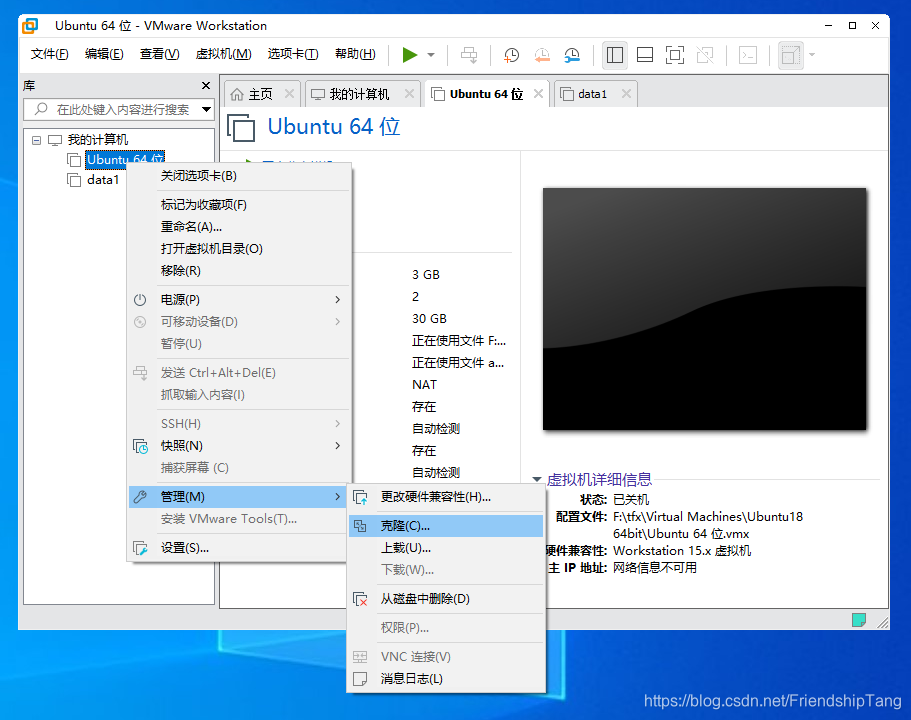
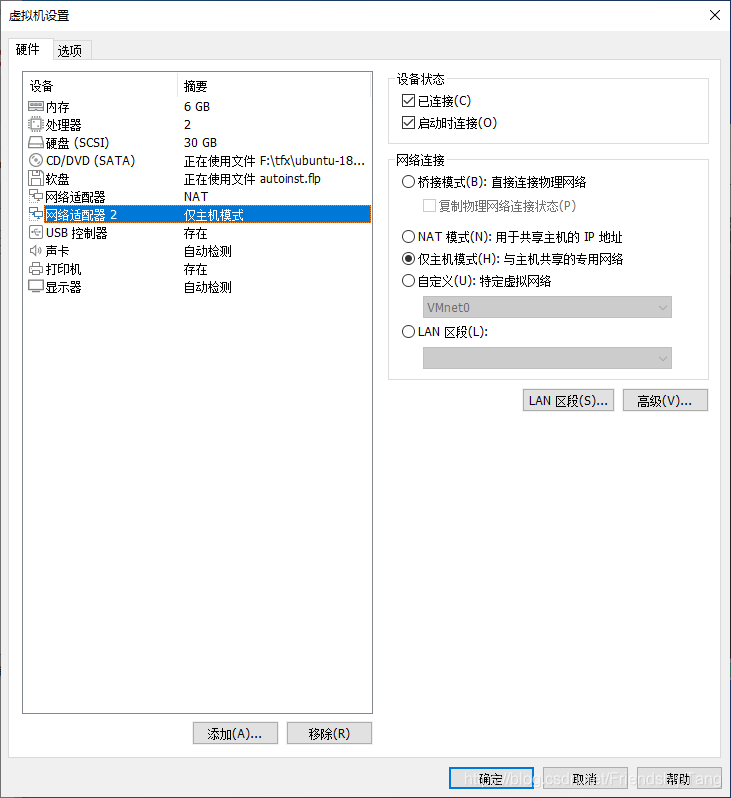
设置网卡
| HostName | ip |
|---|---|
| master | 192.168.94.128 |
| data1 | 192.168.94.129 |
| date2 | 192.168.94.130 |
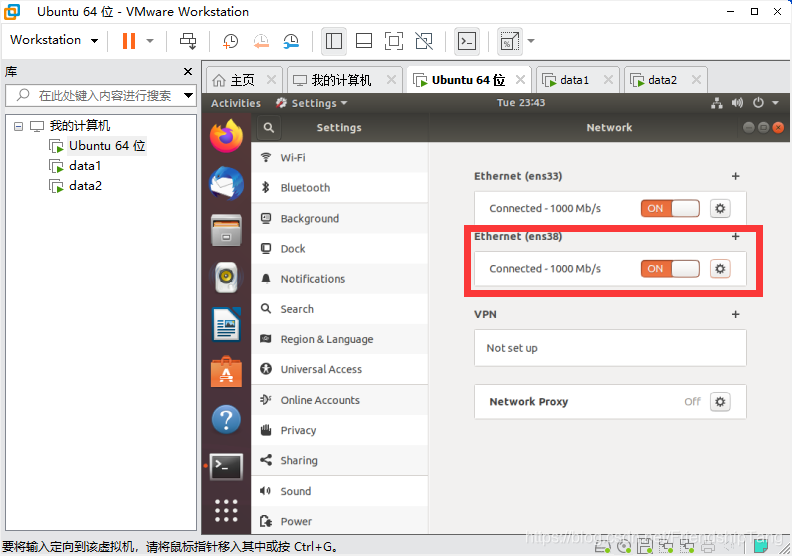
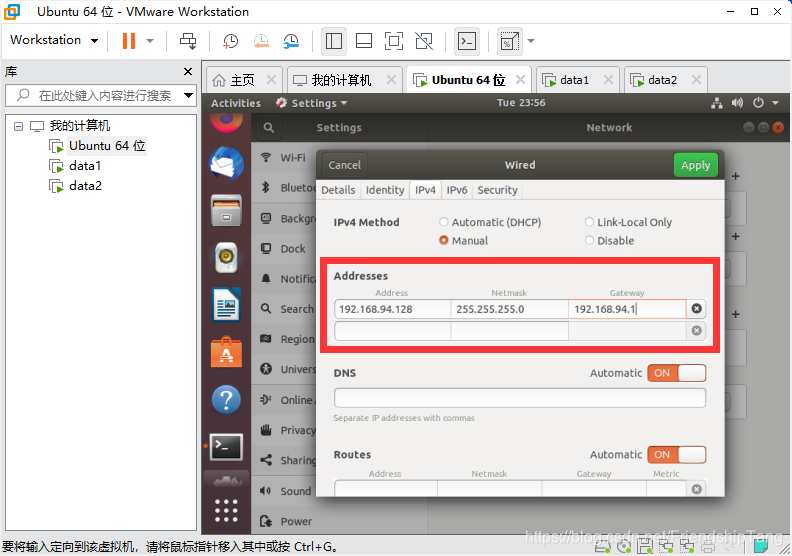
设置data1虚机
设置hostname
sudo gedit /etc/hostname
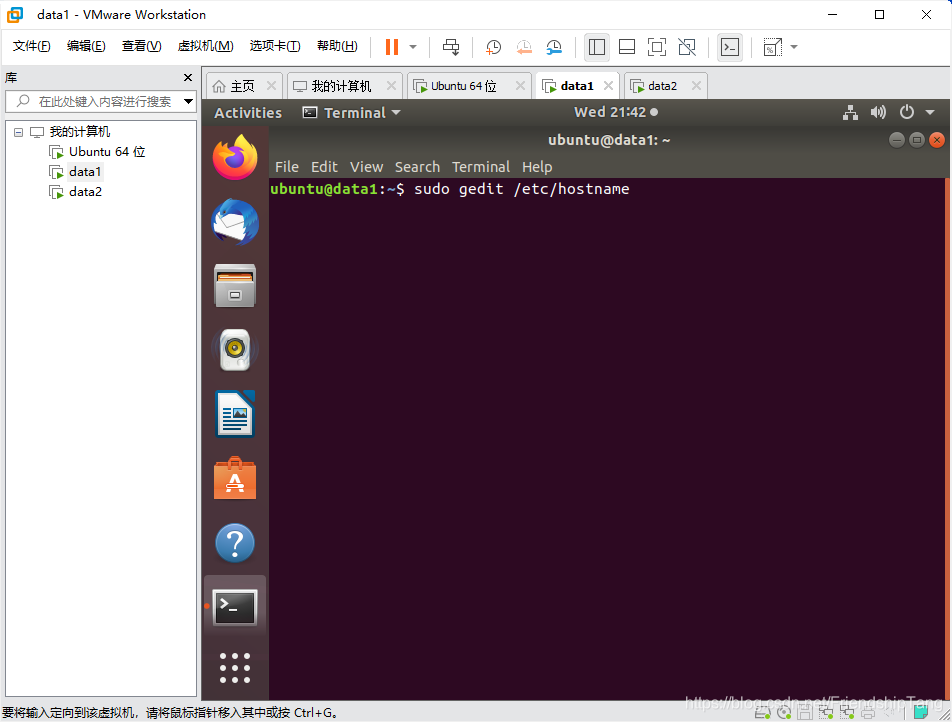
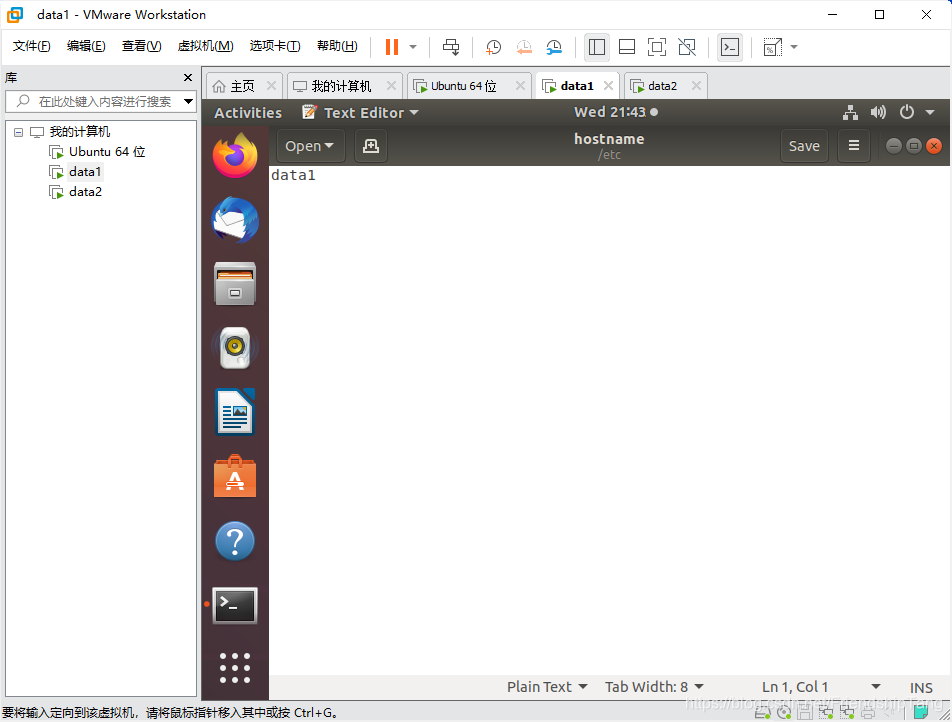
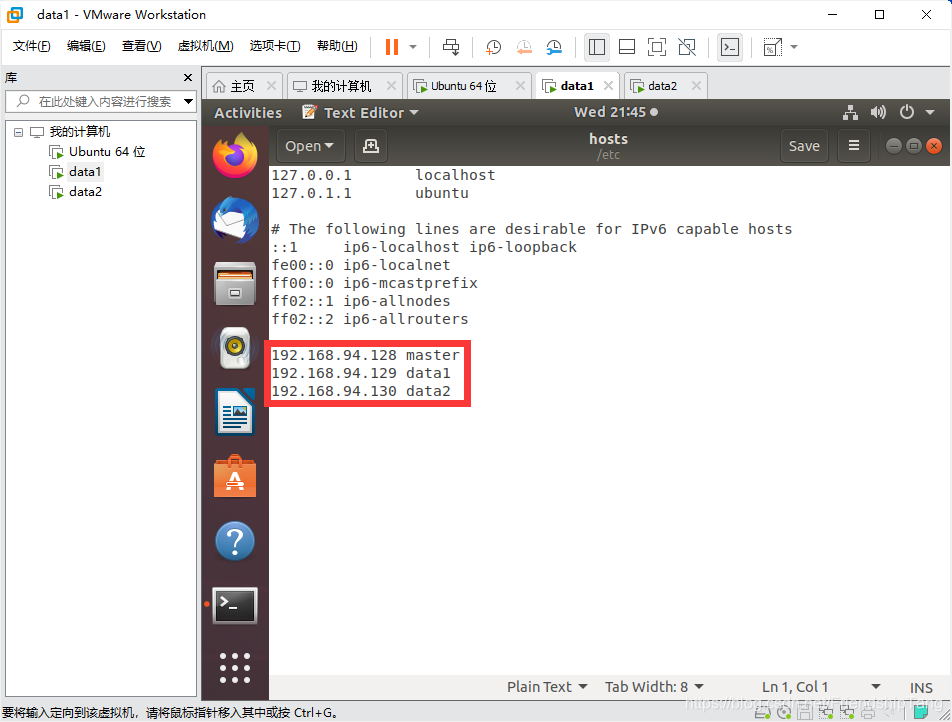
设置hosts文件
sudo gedit /etc/hosts
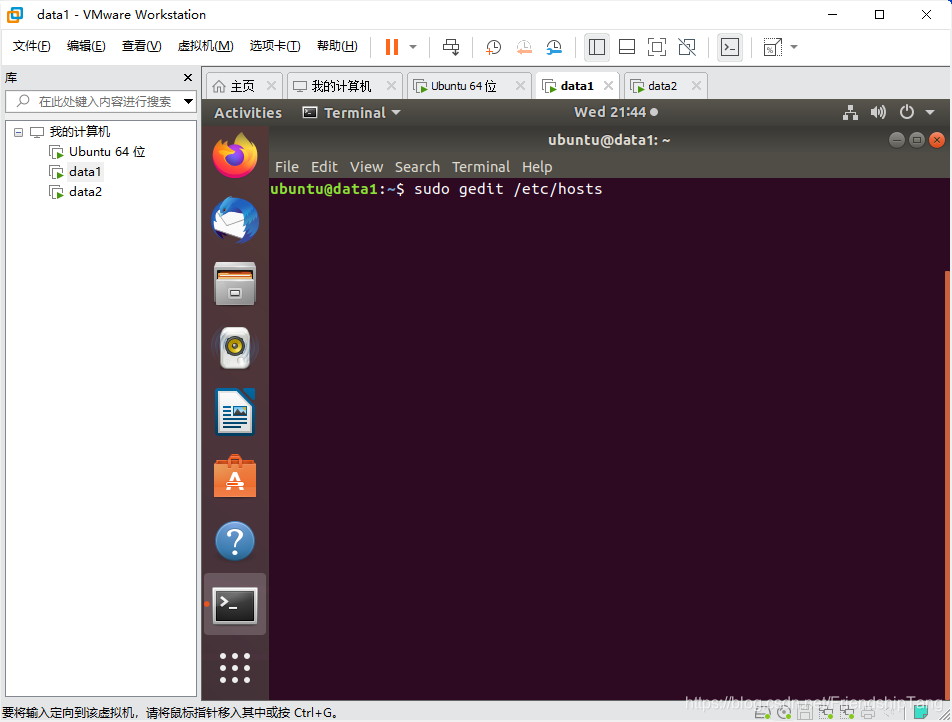
192.168.94.128 master
192.168.94.129 data1
192.168.94.130 data2
设置core-size.xml
sudo gedit /usr/local/hadoop/hadoop-2.9.2/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
设置hdfs-site.xml
sudo gedit /usr/local/hadoop/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
重启设置生效
reboot
设置data2虚机
相关步骤与设置data1一致,不再赘述。注意hostname要与之虚机相对应,相对应即可!
设置master虚机
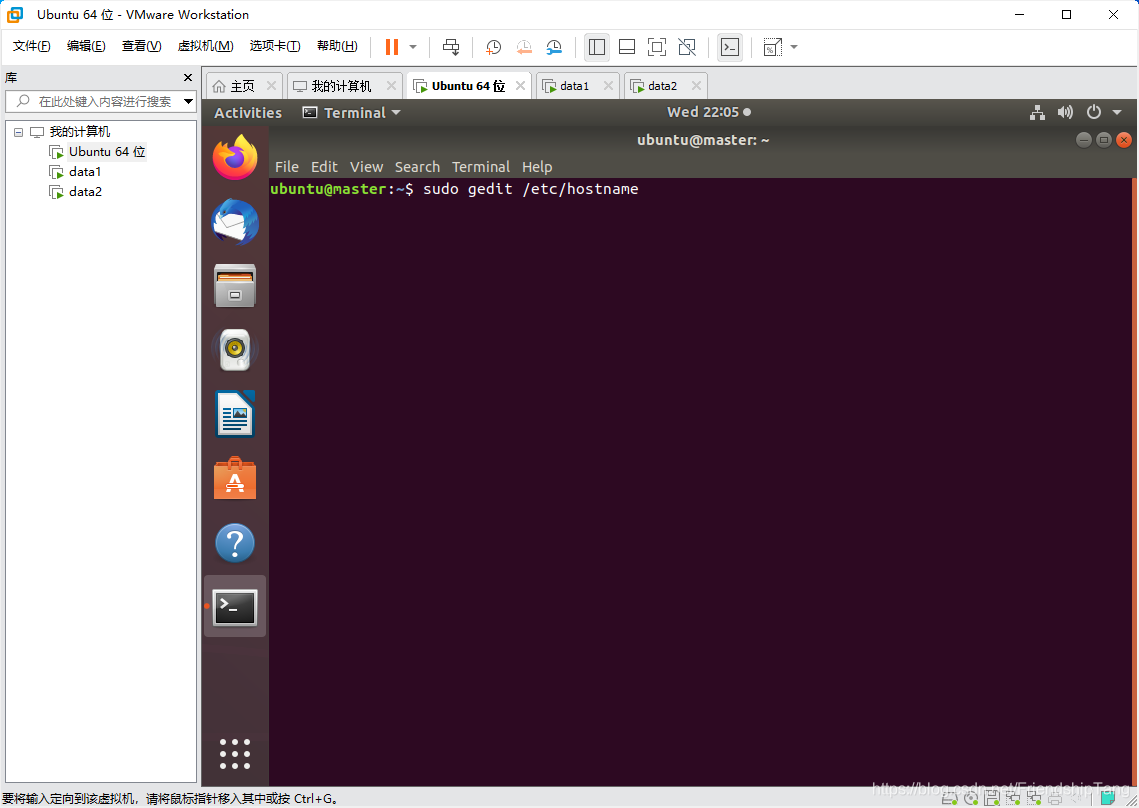
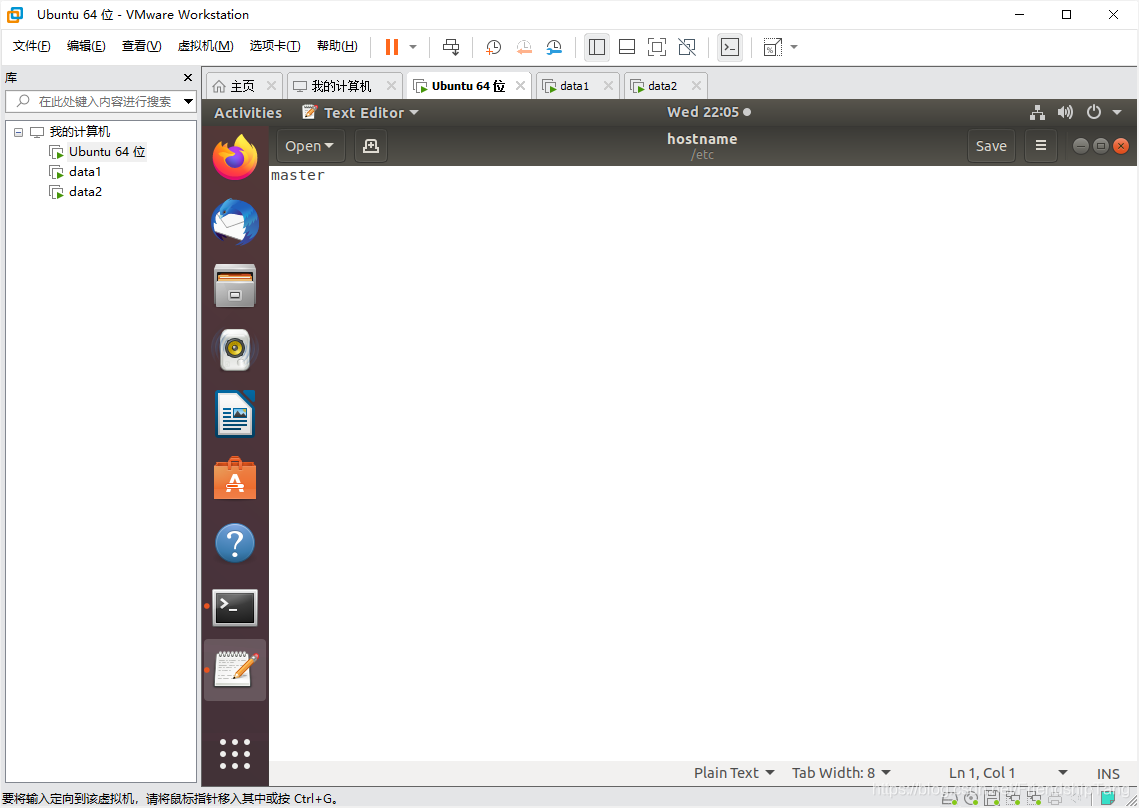
设置hostname
sudo gedit /etc/hostname
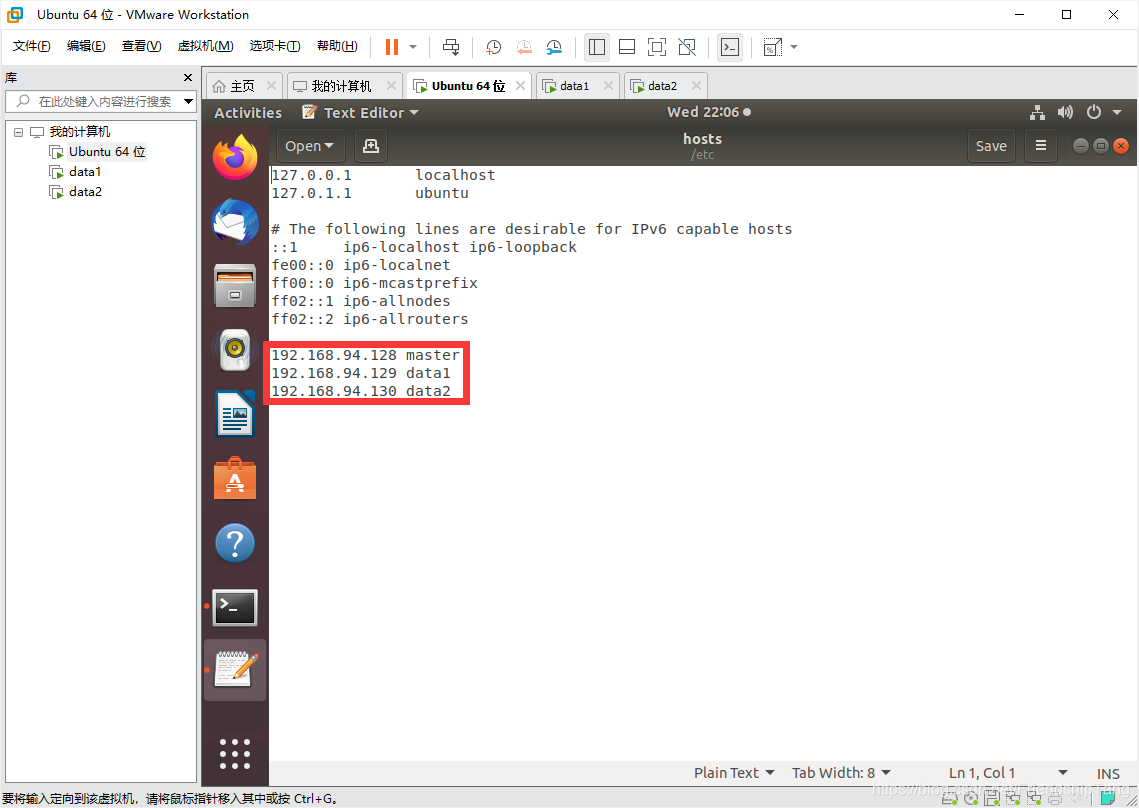
设置hosts文件
sudo gedit /etc/hosts
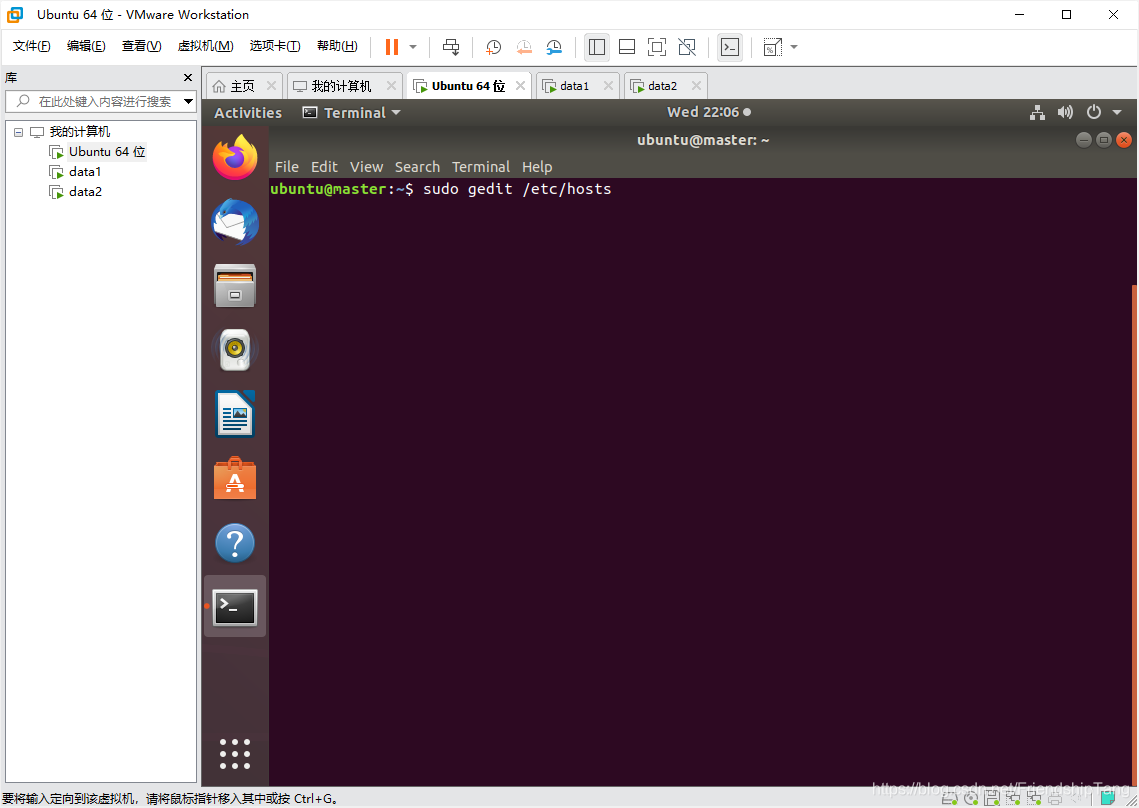
192.168.94.128 master
192.168.94.129 data1
192.168.94.130 data2
设置hdfs-site.xml
sudo gedit /usr/local/hadoop/hadoop-2.9.2/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
</configuration>
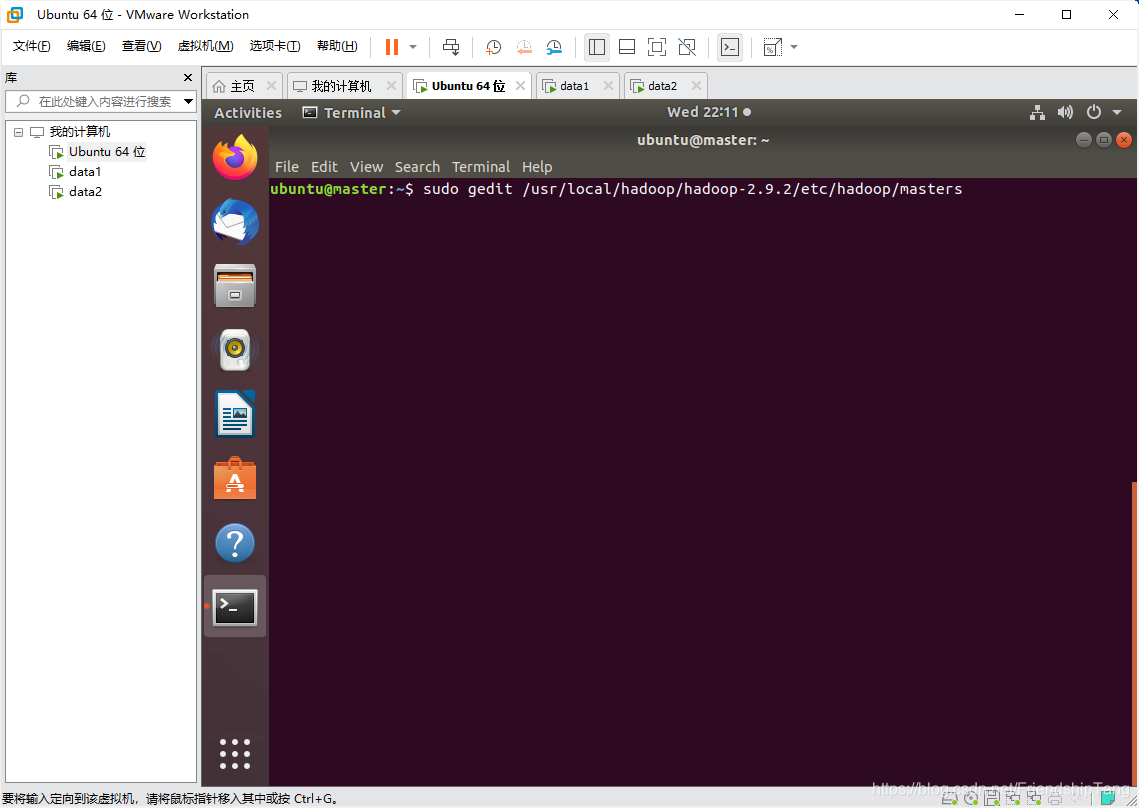
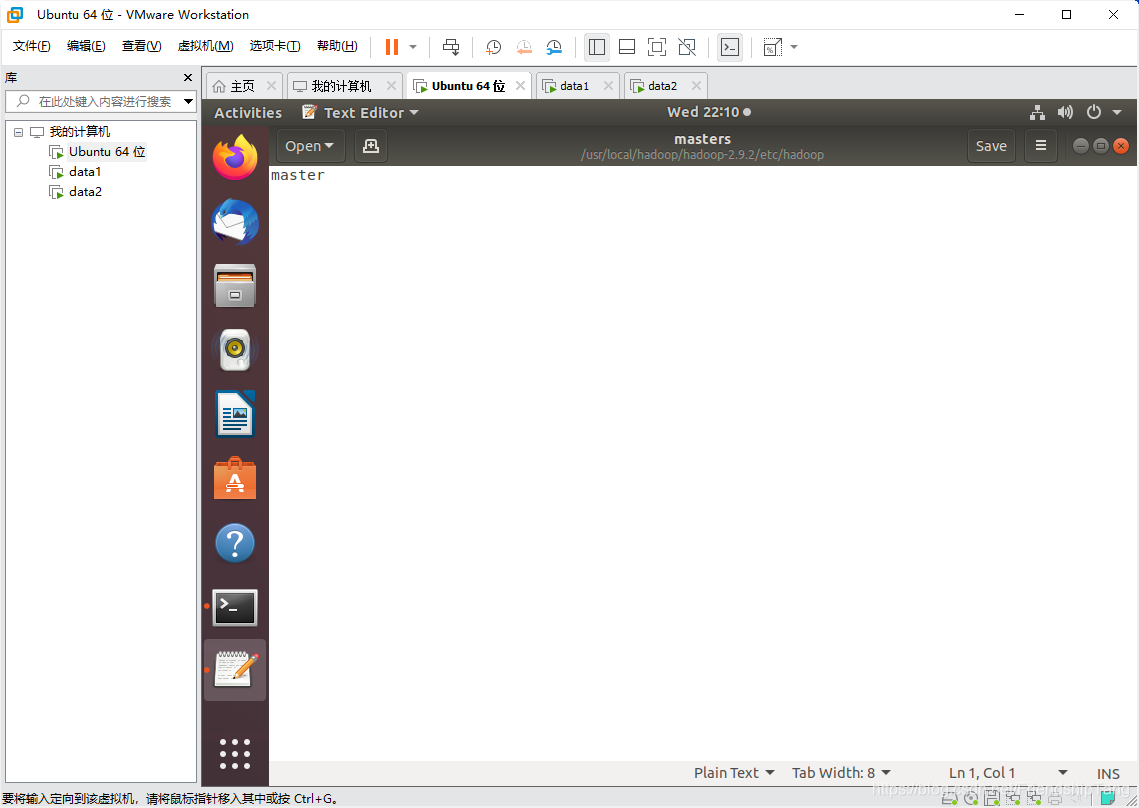
设置master文件
sudo gedit /usr/local/hadoop/hadoop-2.9.2/etc/hadoop/masters
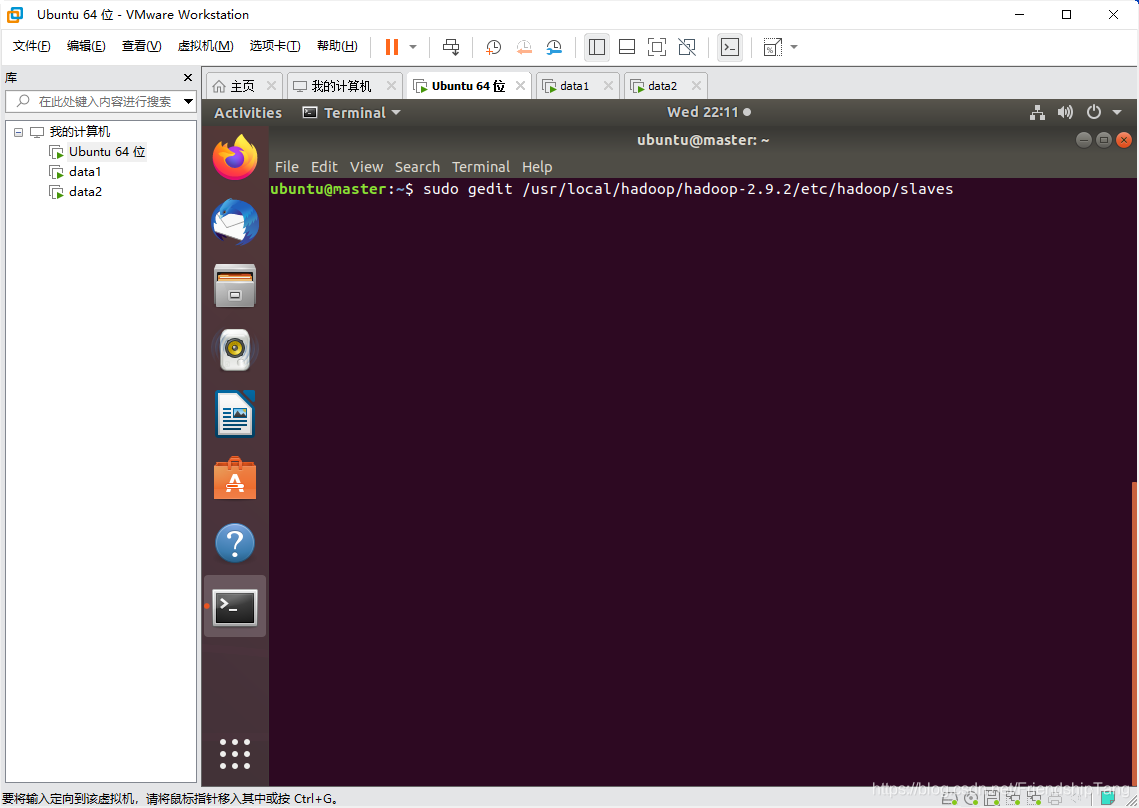
设置slaves文件
sudo gedit /usr/local/hadoop/hadoop-2.9.2/etc/hadoop/slaves
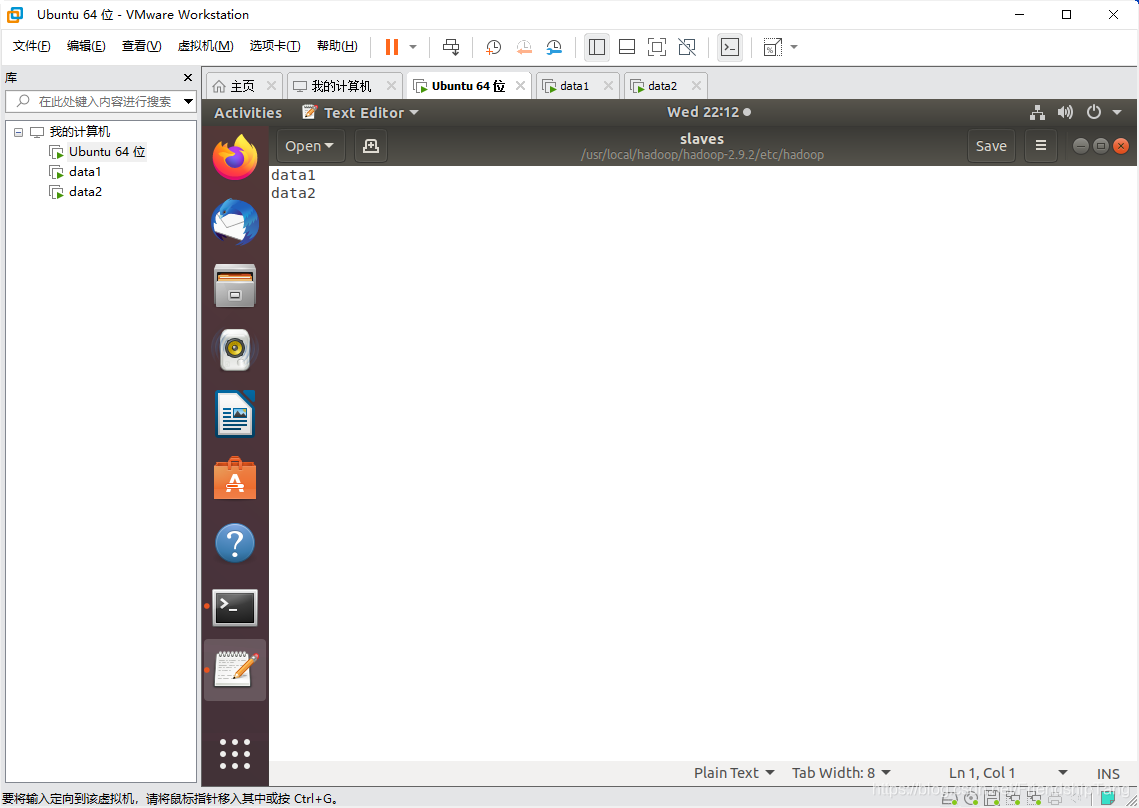
重启设置生效
reboot
master连接到data1、data2创建HDFS目录
启动master、data1、data2服务器
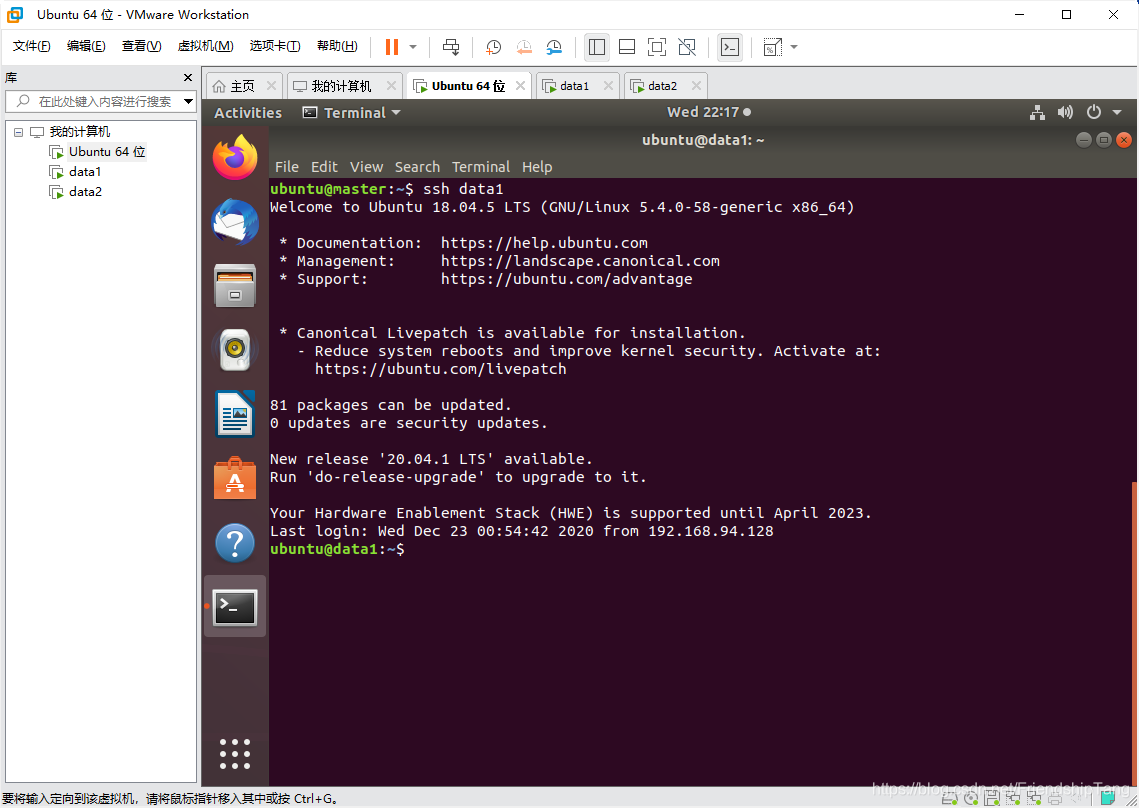
连接到data1虚机
ssh data1
连接到data1创建HDFS相关目录
# 删除HDFS所有目录
sudo rm -rf /usr/local/hadoop/tmp/dfs
# 创建DataNode存储目录
mkdir -p /usr/local/hadoop/tmp/dfs/data
# 将目录的所有者改为ubuntu(用户名)
sudo chown -R ubuntu:ubuntu /usr/local/hadoop/
中断data1连接,回到master
exit
连接到data2虚机
相关步骤与连接到data1一致,不再赘述。
master创建并格式化NameNone HDFS
重新创建NameNone HDFS 目录
# 删除HDFS所有目录
sudo rm -rf /usr/local/hadoop/tmp/dfs
# 创建DataNode存储目录
mkdir -p /usr/local/hadoop/tmp/dfs/name
# 将目录的所有者改为ubuntu(用户名)
sudo chown -R ubuntu:ubuntu /usr/local/hadoop/
格式化NameNone HDFS 目录
hadoop namenode -format
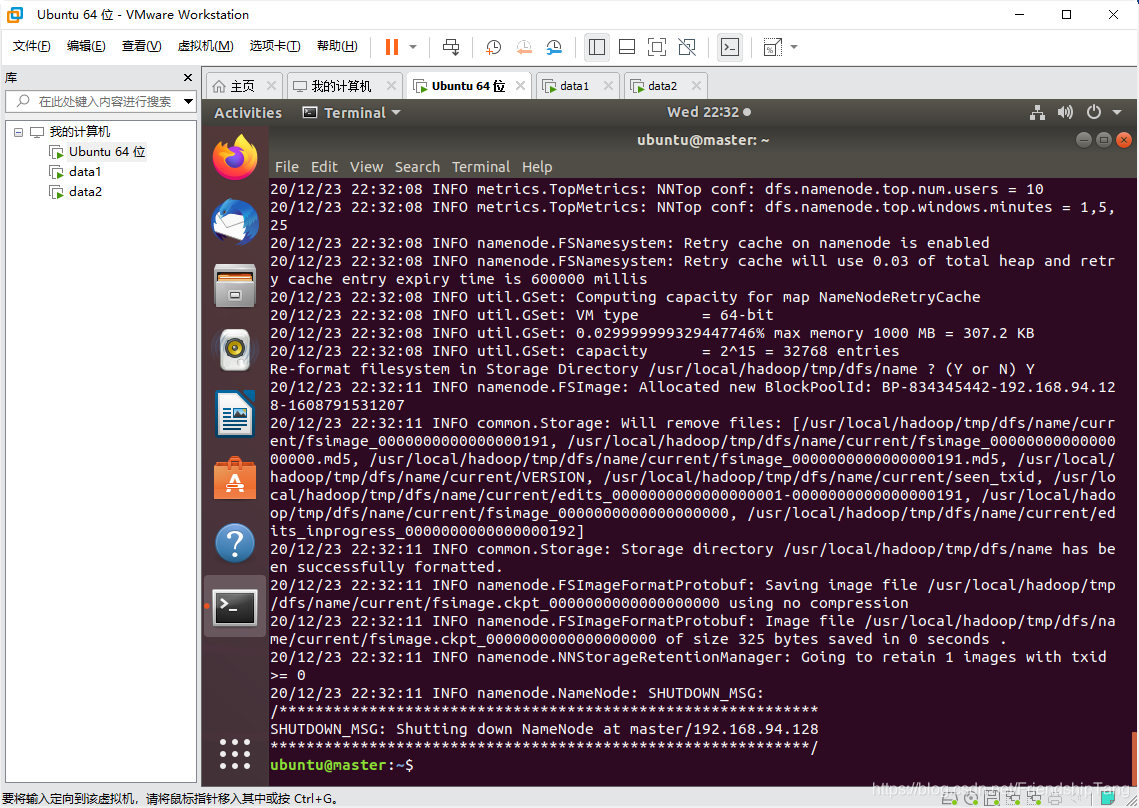
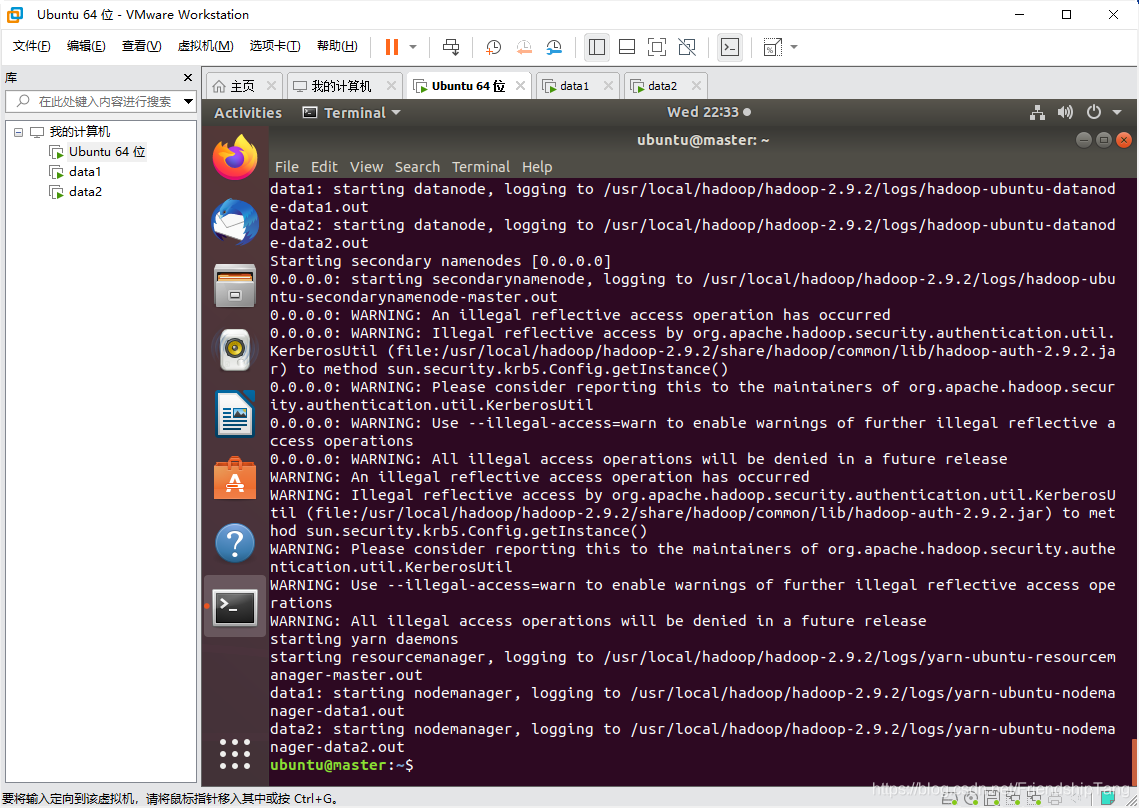
启动 Hadoop Multi Node Cluster
start-all.sh
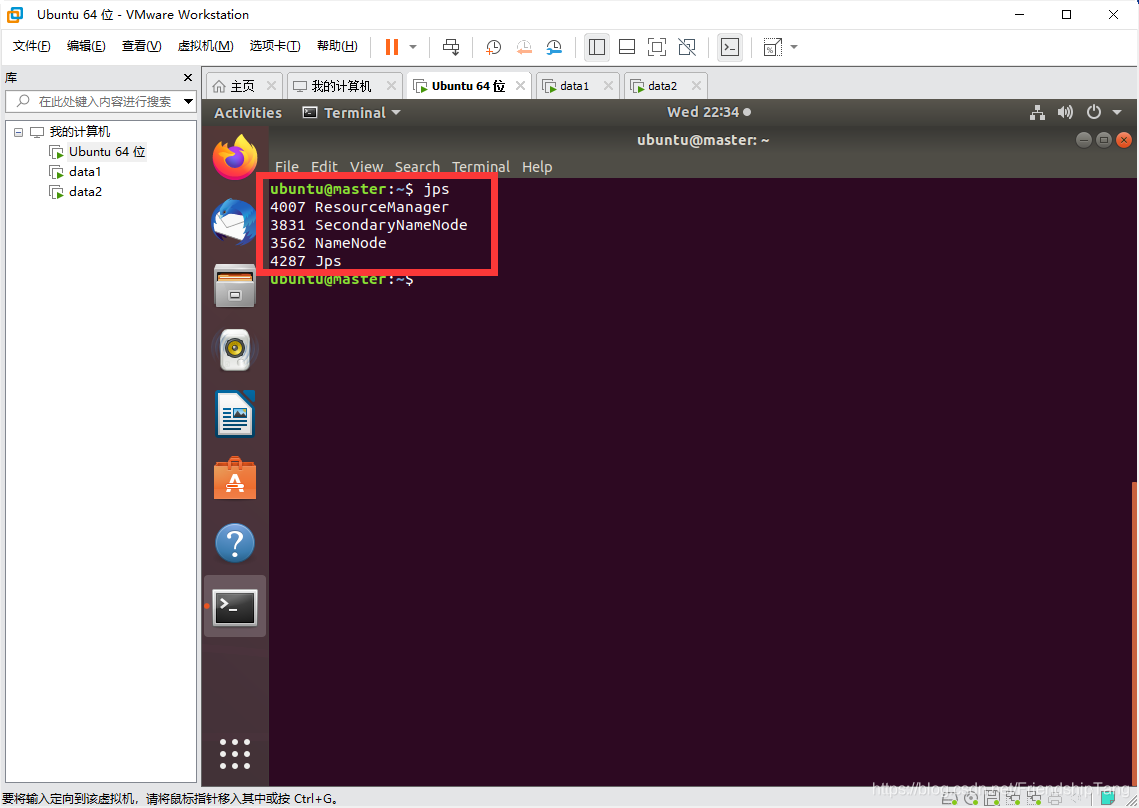
查看master(NameNode)进程
jps
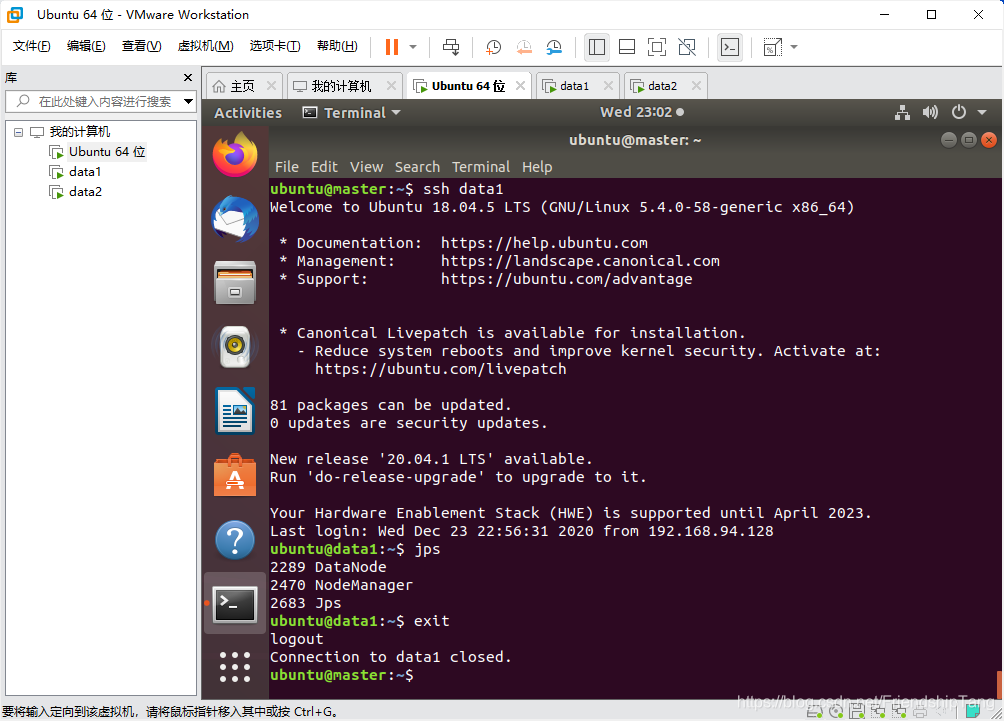
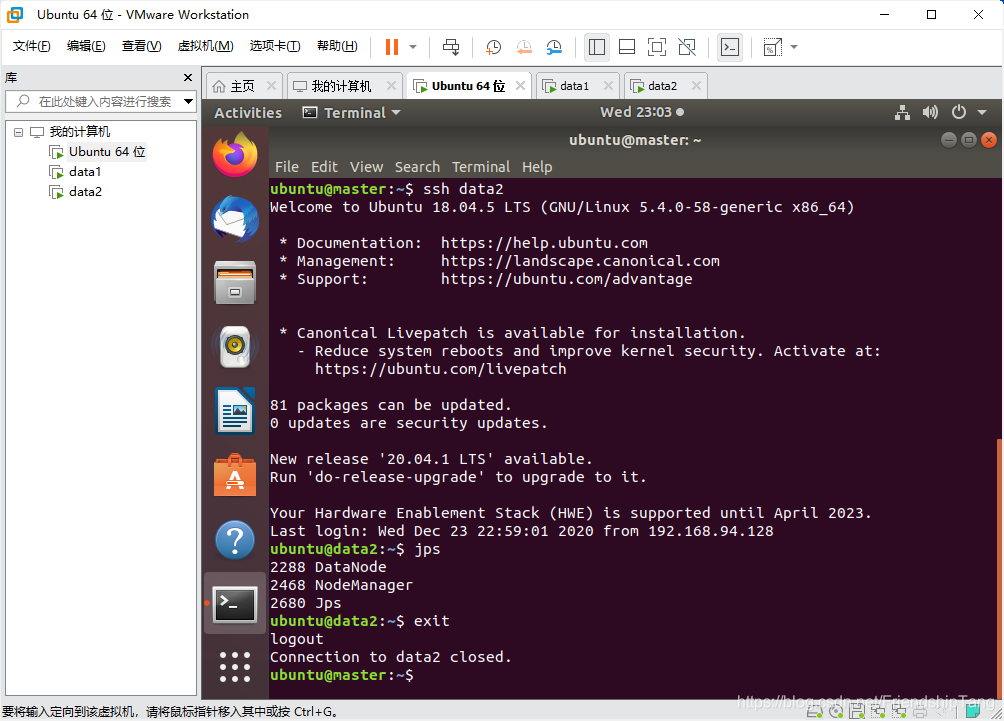
查看data1(DataNode)的进程
# SSH连接到data1
ssh data1
# 查看所运行的进程
jps
# 回到master
exit
查看data2(DataNode)的进程
# SSH连接到data2
ssh data2
# 查看所运行的进程
jps
# 回到master
exit
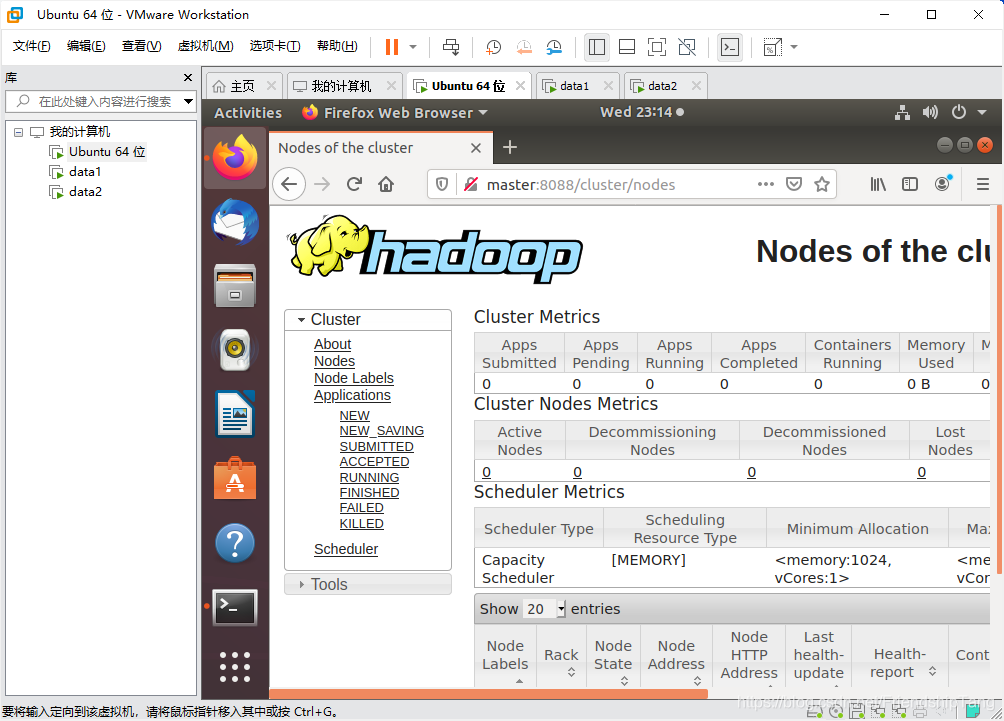
打开Hadoop ResourceManager Web 界面
http://master:8088
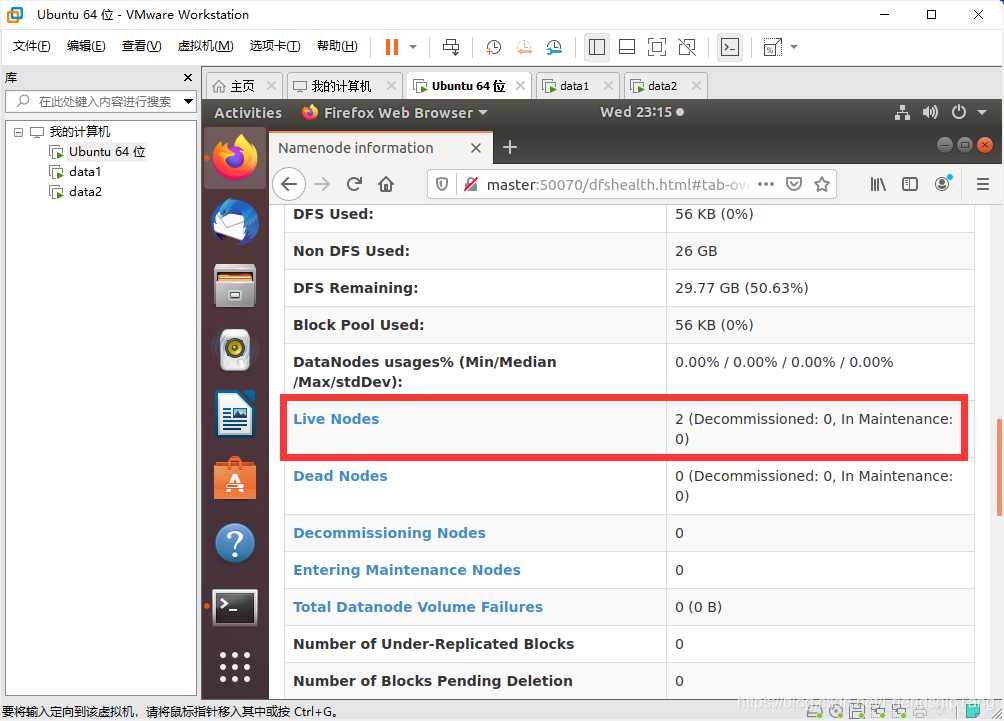
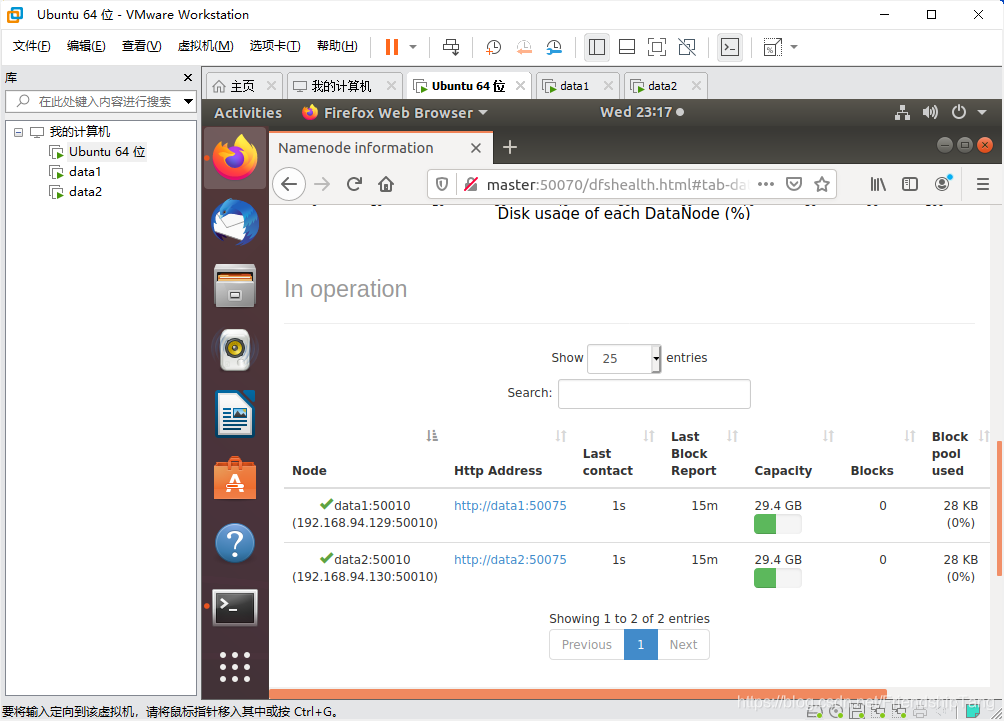
打开NameNode Web 界面
http://master:50070
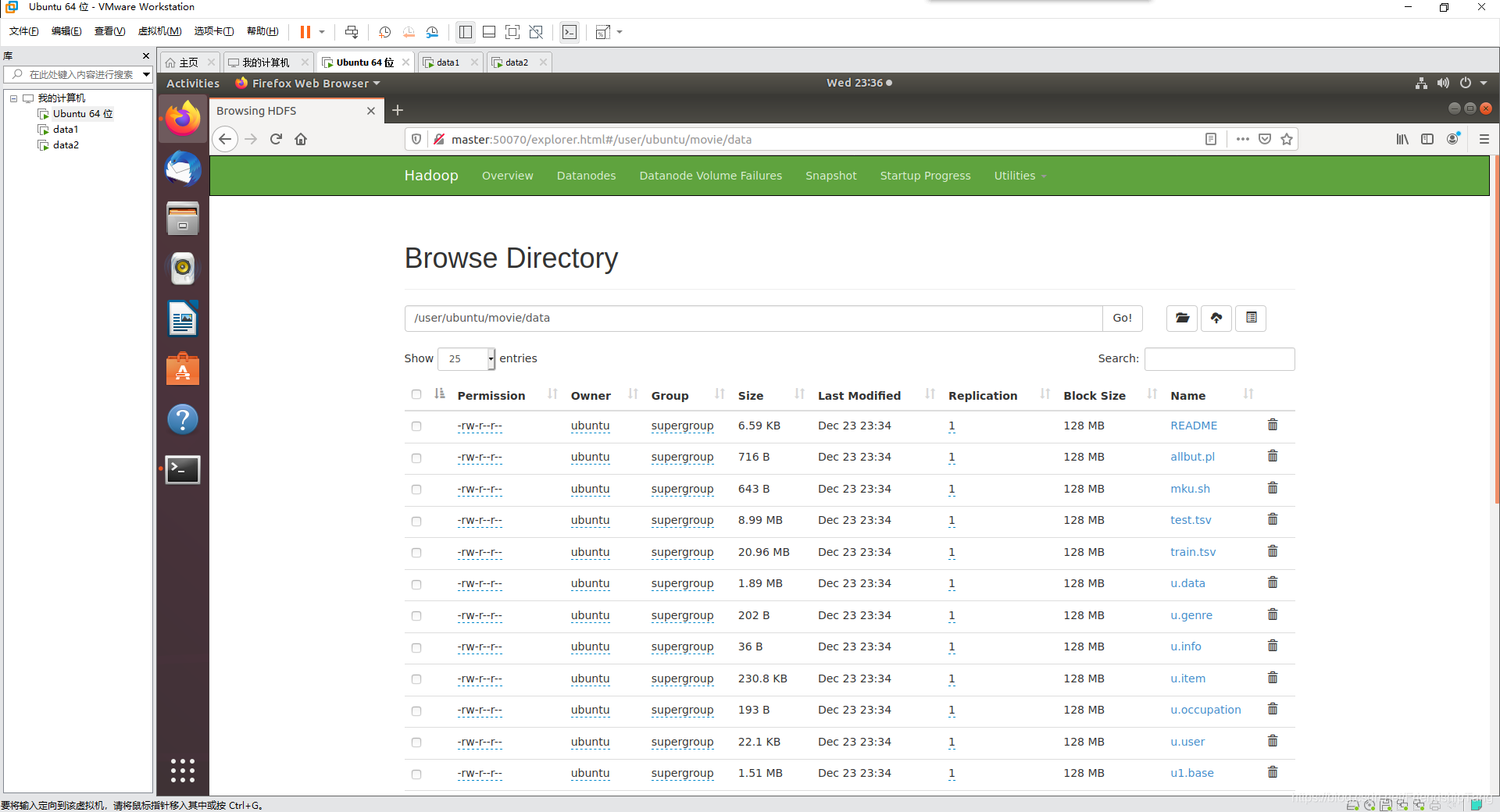
创建与查看HDFS目录
# 创建多级目录
hadoop fs -mkdir -p /user/ubuntu/movie
# 查看所有目录
hadoop fs -ls -R /
# 上传
hadoop fs -put ./movie/data /user/ubuntu/movie/data
# 删除目录
hadoop fs -rm -R /user/ubuntu/movie/data
http://master:50070/explorer.html
未完待续…


















 2226
2226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











