




 研究探讨了基于深度学习的级联几何推理技术,结合稀疏颜色混合和场景特定的微调策略,以提升3D模型的精度和细节。
研究探讨了基于深度学习的级联几何推理技术,结合稀疏颜色混合和场景特定的微调策略,以提升3D模型的精度和细节。
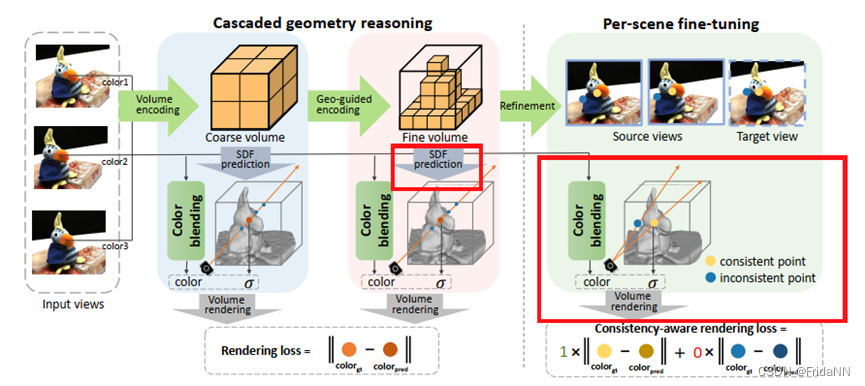
1.概述:
主要包含两部分,cascaded geometry reasoning\per-scene fine-tuning。级联几何推理包含两部分,一部分是由输入图片直接体编码得到粗网格体积,另一部分是几何引导编码得到更细粒度的细网格体积。
然后使用具有一致性的fine-tuning策略优化细网格体积,最终得到精细的曲面。
在外观预计部分,SparseNeus使用了多精度的颜色混合模块将图像、几何信息结合在一起预计表面颜色。
2. 详细内容
1)Geometry reasoning
(注:geometry encoding 和surface extraction方式和one234相同,但是one234省略了cascaded volumes scheme)
a)Geometry encoding 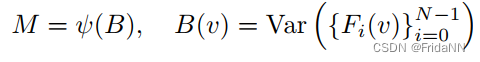
首先根据n张输入图像,估计bounding box大小能够覆盖region of intrest。通过2d神经网络,对n张图片分别提取n张feature map。然后将bounding box中的每个顶点都投影到N个feature map上插值出对应的特征值。
通过求所有特征值的方差,将所有的特征体整合为一个cost volume(认为每个特征体对cost volume的贡献相同)。
然后用稀疏的3d cnn从cost volume中提取geometry encoding volume
b)Surface extraction 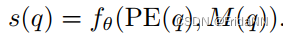
将经过位置编码的3d坐标PE(q)和q坐标下的geometry encoding volume M(q),输入MLP f![]() ,网络预测q坐标下的SDF值。
,网络预测q坐标下的SDF值。
c)Cascaded volumes scheme
为了平衡计算效率和重建精度,geometry encoding volume被分为两个精度。前者主要用于推断粗糙的几何。在重建更高精度的volume时,远离粗糙的平面的顶点会被抛弃。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









