 VisionTransformersandMultimodalTechniquesinImageClassification
VisionTransformersandMultimodalTechniquesinImageClassification




1. Vision Transformer ViT
将W*H*C的图像分割为P*P*C,然后将flattened patches 进行线性投影,然后结合position embedding送入L layers of transformer encoder.最终外接一个MLP头,输出图像类别。特别的0 patch与额外的可学习的代表类别的embedding结合,而不用和图像patch结合。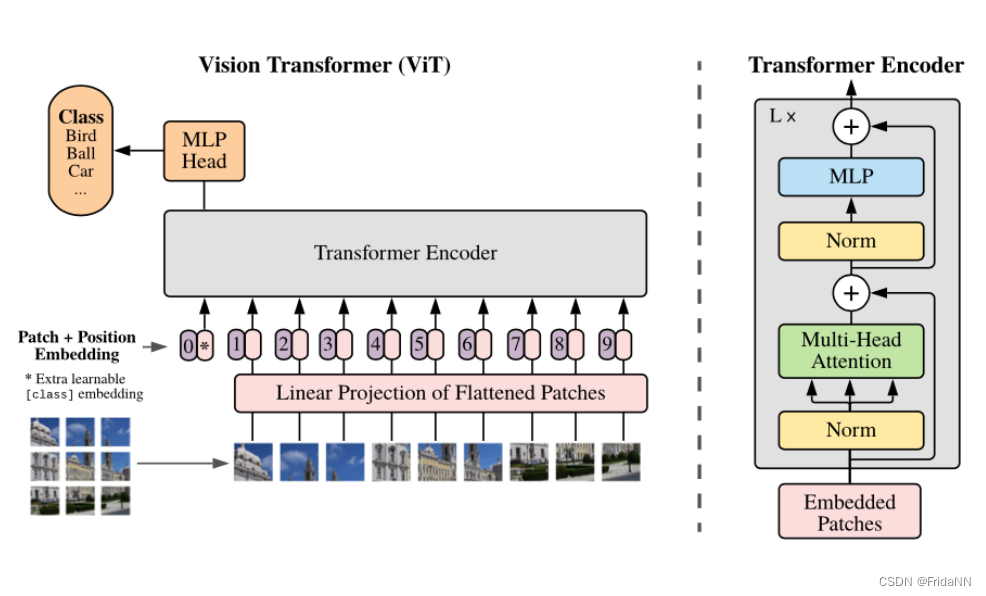
2. multimodal transformer
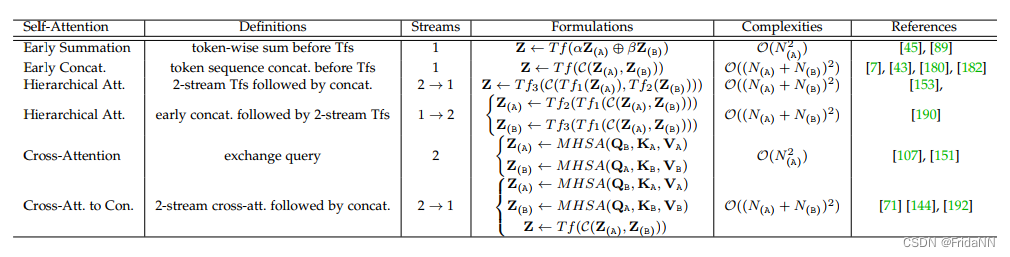
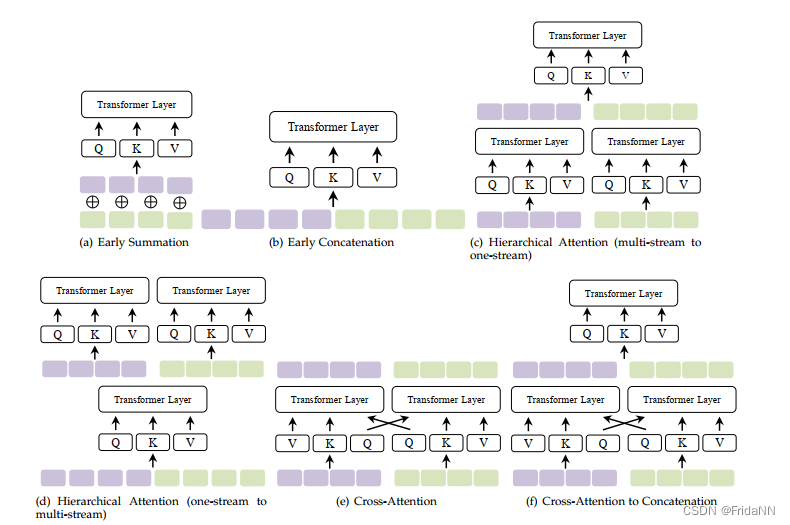
比较不同混合方式:
3)hierarchical attention(multi-stream to one-stream):两个模态首先分别通过transformer encode,再由transformer 混合。
4)Cross-Attention:缺点:每个模态内部没有self-attention
multi modal叠加后,中间层都是什么内容
3.关于diffuseStyleGesture的思考
1)为什么在学习局部特征的时候用routing transformer,学习全局特征时用self-attention transformer
routing transformer(Efficient Content-Based Sparse Attention with Routing Transformers)是一种动态sparse attention机制降低了self-attention机制对存储空间和计算量的需求。所以可以认为routing transformer更关注局部特征?
2)什么时候用element-wise addition.和concatenation
element-wise addition:源于 ResNet 。要求输入输出的channel数量相同。损失了一些信息,但保留网络的空间信息,并且计算上相比element-wise addition更高效因为不需要额外的内存。
concatenation:源于Inception nets以及之后的 DenseNet。不要求输入输出的channel数量相同。可能由于增加了输出的channel数量、保留了原有信息提高表现。
在DenseNet中认为element-wise addition可能污染中间卷积步骤和skip connection源头的feature map.所以所以可以先选择concatenation,再尝试element-wise addition简化网络。
3) 从代数的角度理解element-wise addition.和concatenation
两者的差别并不大。假设tensor x y被concatenate,后进行变换:
假设tensor xy被add,后进行变换:,当矩阵W的左右两部分相等时
,element-wise addition.和concatenation的效果相同。
4.什么是feature map/activation map
feature map是使用filter卷积后的输出,代表输入图像特征。feature map中的每个元素代表神经网络中某个神经元的激活情况,值大小代表该特征能多大程度的体现输入图像。
ps:
reformer: an efficient transformer2001.04451.pdf (arxiv.org)
routing transformer:Efficient Content-Based Sparse Attention with Routing Transformers

















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









