






随着各种技术的发展,我们可以轻易的收集到大量的文本数据,如何从中提取到有用的信息成为一个重要的问题。例如在网页搜索中,用户在搜索框中输入问题,搜索引擎将返回与之相关的多个网页,这种方式虽然能满足一定的需求,但仍需用户投入大量的精力寻找想要的答案。一种更为好的方法是系统可以根据用户的问题直接返回答案,这种形式在移动端和智能助手上显得更为的有用。
我们可以将上述的问题归结为两阶段进行:
- 根据问题寻找可能包含答案的文档:这一步使用常规的信息检索方法即可实现
- 在上一步得到的相关文档或是段落中找到正确的答案:这一步通常可以归到阅读理解这个子方向上
阅读理解的发展历史

在《Towards the Machine Comprehension of Text:An Essay》中给出了关于机器阅读理解的定义:
A machine comprehends a passage of text if, for any question regarding that text that can be answered correctly by a majority of native speakers, that machine can provide a string which those speakers would agree both answers that question, and does not contain information irrelevant to that question.
简单来说,阅读理解解决的问题为:将问题 Q Q Q和文档 P P P输入到模型中希望得到答案 A A A。

开放域问答问题(Open-domain Question Answering)的发展历史

Stanford Question Answering Dataset(SQuAD)
SQuAD是NLP领域一个很常用的数据集,它包含100K个样例。对于每个文章都有对应的问题和在文中可以找到的答案。

SQuAD最新的榜单
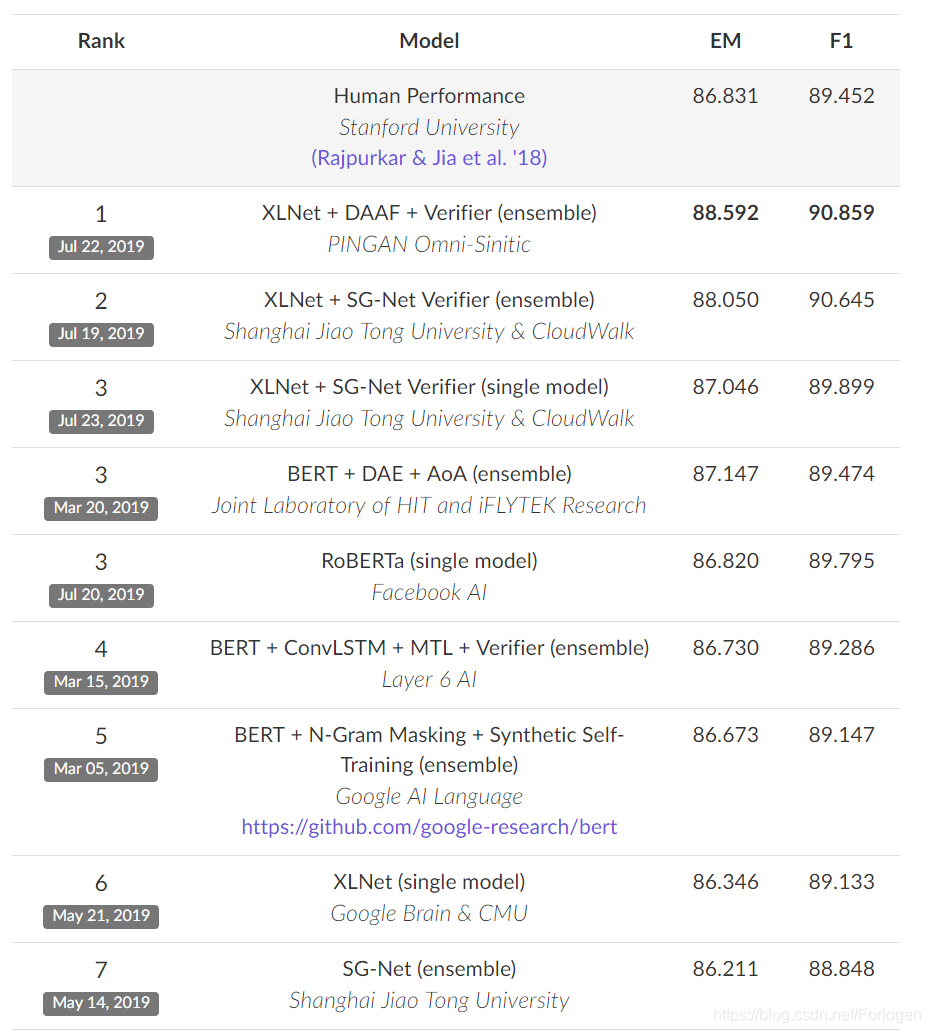
从中可以看出预训练模型在这方面的效果很好,排名靠前的是最近提出的XLNet,FAIR对于BERT的改进版本RoBRTa排名第三。
SQuAD的优缺点:

The Stanford Attentive Reader
Stanford Attentive Reader将问题中的每一次表示为词向量的形式,然后将其输入到双向的LSTM中,将每个方向最后的隐状态拼接到一起做为整个问题的表示,然后再到文章中寻找答案。
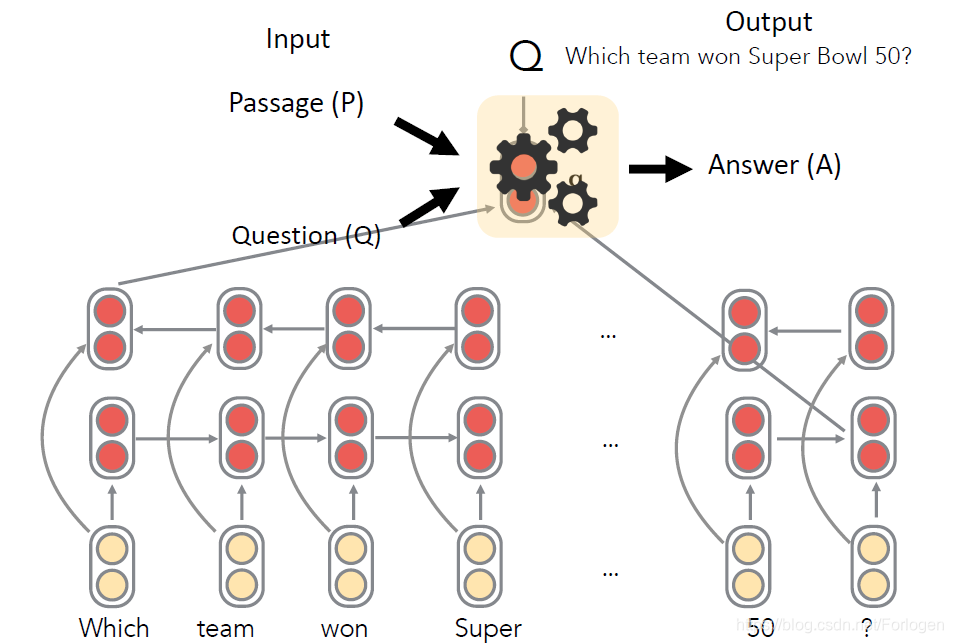
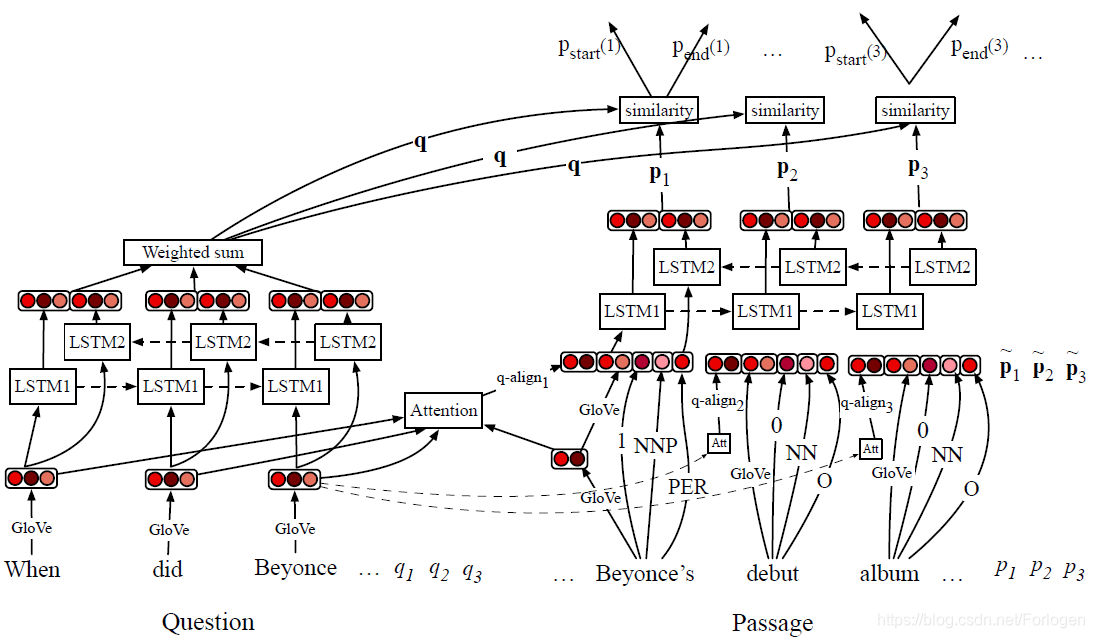
Stanford Attentive Reader++
BiDAF(Bi-Directional Attention Flow for Machine Comprehension)
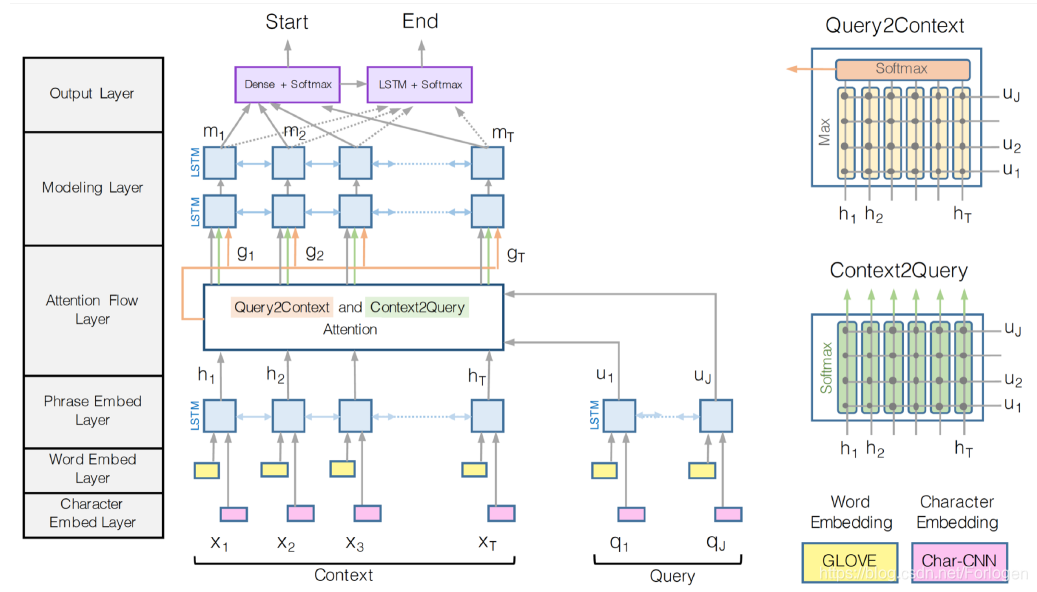
对于BiDAF的解读:
机器阅读理解系列文章-BiDAF(Bi-Directional Attention Flow for Machine Comprehension)
BiDAF:机器理解之双向注意力流
FusionNet
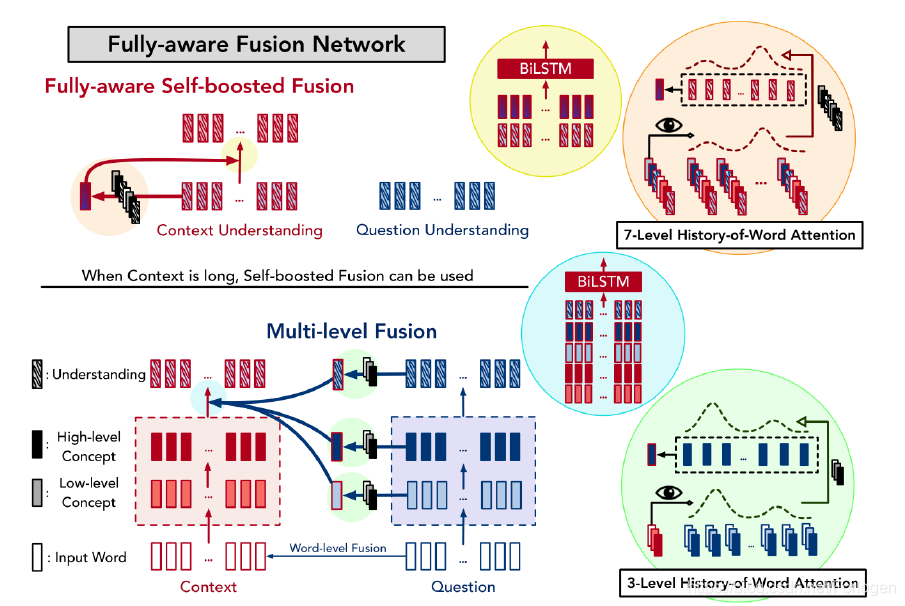
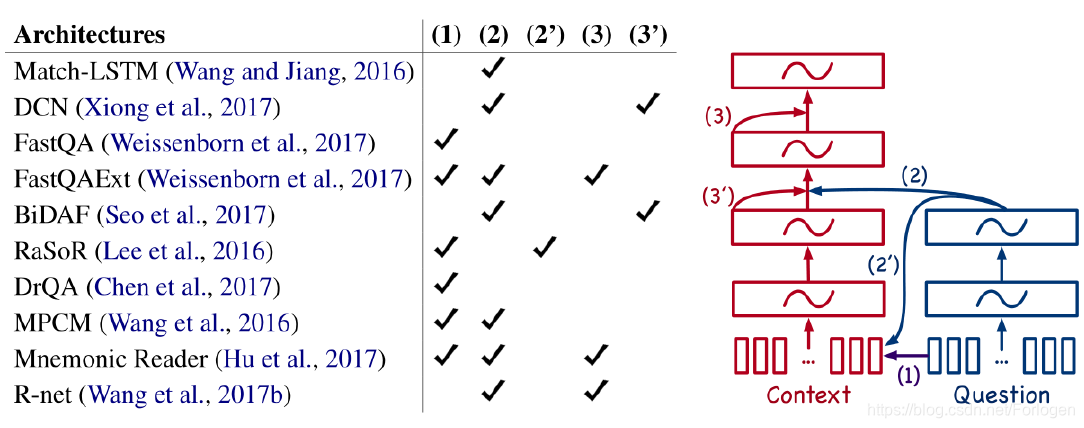
更多先进的模型架构

















 1233
1233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









