







1 Motivition: Question Answering
对于大量的文本,我们经常需要一个应用来实现根据询问的问题返回相应的答案,可以大致的分为两种:
- 1 返回一个文本,这个文本中可能包含答案
这个问题可以使用传统的**信息检索/网络搜索(information retrieval/web search)**技术解决
- 2 从一个文本段落或者文件中找答案
通常这个问题被称为阅读理解(Reading Comprehension)
这里主要关注第二种问题,可以表示如下形式:
P
a
s
s
a
g
e
(
P
)
+
Q
u
e
s
t
i
o
n
(
Q
)
→
A
n
s
w
e
r
(
A
)
Passage(P)+Question(Q) \to Answer(A)
Passage(P)+Question(Q)→Answer(A)
2 Stanford Question Answering Dataset (SQuAD)
2016年斯坦福提供的SQuAD数据集,包含10万个例子,其中答案(Answer)需要包含在提供的段落(Passage)中,所以也被称为抽取式问答(extractive question answering)。
SQuAD v1.1评价方法为,挑选三个正确答案作为gold answer,然后使用两种方式评价系统优劣,第一个为Exact match,就是你的系统提供的答案是否完全和这三个gold answer匹配,匹配为1,否则为0;第二个为F1,把系统提供的答案和gold answer视为词袋,然后评估F1,F1计算如下:
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
R
e
c
a
l
l
=
T
P
T
P
+
F
N
F
1
=
2
P
R
P
+
R
Precision = \frac{TP}{TP+FP} \\ Recall = \frac{TP}{TP+FN} \\ F1 = \frac{2PR}{P + R}
Precision=TP+FPTPRecall=TP+FNTPF1=P+R2PR
其中
- TP,True Positive
- FP,False Positive
- TN,True Negative
- FN,False Negative
SQuAD v2.0 添加了NoAnswer一个选项,使得系统倾向于判断一个问题是否拥有答案。
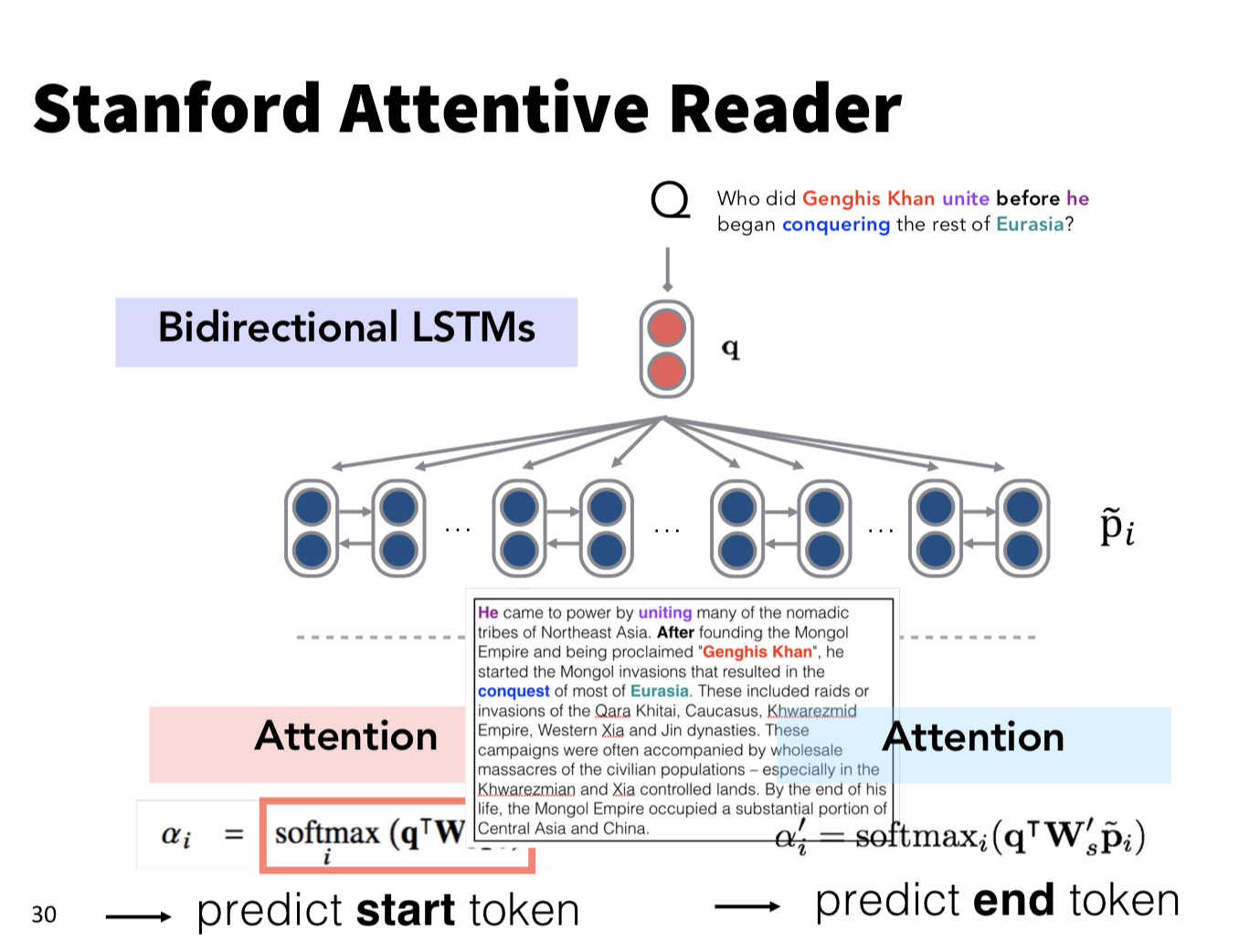
3 Stanford Attentive Reader
Danqi Chen提出的一个系统,表明了一个简单的系统就可以实现很好性能。结构如下,使用一个双向LSTM作用在passage上,然后应用attention机制,预测答案开始的位置和结束的位置。
4 BiDAF: Bi-Directional Attention Flow for Machine Comprehension
[Seo, Kembhavi, Farhadi, Hajishirzi, ICLR 2017]提出的BiDAF,中心思想是attention flow,即attention应该以两种方式流动,从内容到问题和从问题到内容。
首先相似度矩阵为, S i j = w s i m T [ c i ; q j ; c i ∘ q j ] ∈ R S_{ij}=w_{sim}^T [c_i;q_j;c_i \circ q_j] \in \mathbb{R} Sij=wsimT[ci;qj;ci∘qj]∈R
Context-to-Question(C2Q) attention:
α
i
=
s
o
f
t
m
a
x
(
S
i
,
:
)
∈
R
M
∀
i
∈
{
1
,
…
,
N
}
a
i
=
∑
j
=
1
M
α
j
i
q
j
∈
R
2
h
∀
i
∈
{
1
,
…
,
N
}
\alpha_i = softmax(\mathbf{S}_i,:) \in \mathbb{R}^M \quad \forall i \in\{1,\dots,N \}\\ \mathbf{a}_i = \sum_{j=1}^M \alpha_j^i\mathbf{q}_j \in \mathbb{R}^{2h} \quad \forall i \in\{1,\dots,N \}
αi=softmax(Si,:)∈RM∀i∈{1,…,N}ai=j=1∑Mαjiqj∈R2h∀i∈{1,…,N}
Question-to-Context(Q2C) attention:
m
i
=
max
j
S
i
j
∈
R
∀
i
∈
{
1
,
…
,
N
}
β
=
s
o
f
t
m
a
x
(
m
)
∈
R
N
c
′
=
∑
i
=
1
N
β
i
c
i
∈
R
2
h
\mathbf{m}_i = \max_{j} \mathbf{S}_{ij} \in \mathbb{R} \quad \forall i \in\{1,\dots,N \} \\ \beta = softmax(\mathbf{m}) \in \mathbb{R}^N \\ c'= \sum_{i=1}^N\beta_i \mathbf{c}_i \in \mathbb{R}^{2h}
mi=jmaxSij∈R∀i∈{1,…,N}β=softmax(m)∈RNc′=i=1∑Nβici∈R2h
每一个位置,BiDAF的输出是
b
i
=
[
c
i
;
a
i
;
c
i
∘
a
i
;
c
i
∘
c
′
]
∈
R
8
h
∀
i
∈
{
1
,
…
,
N
}
\mathbf{b}_i = [\mathbf{c}_i; \mathbf{a}_i; \mathbf{c}_i \circ \mathbf{a}_i;\mathbf{c}_i\circ c'] \in \mathbb{R}^{8h} \quad \forall i \in\{1,\dots,N \}
bi=[ci;ai;ci∘ai;ci∘c′]∈R8h∀i∈{1,…,N}
5 Recent, more advanced architectures
在近几年引入attention的各种变体使得模型变得更加复杂,通常这样的模型能够获得更好的效果。
Dynamic Coattention Networks for Question Answering (Caiming Xiong, Victor Zhong, Richard Socher ICLR 2017)
FusionNet (Huang, Zhu, Shen, Chen 2017)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









