




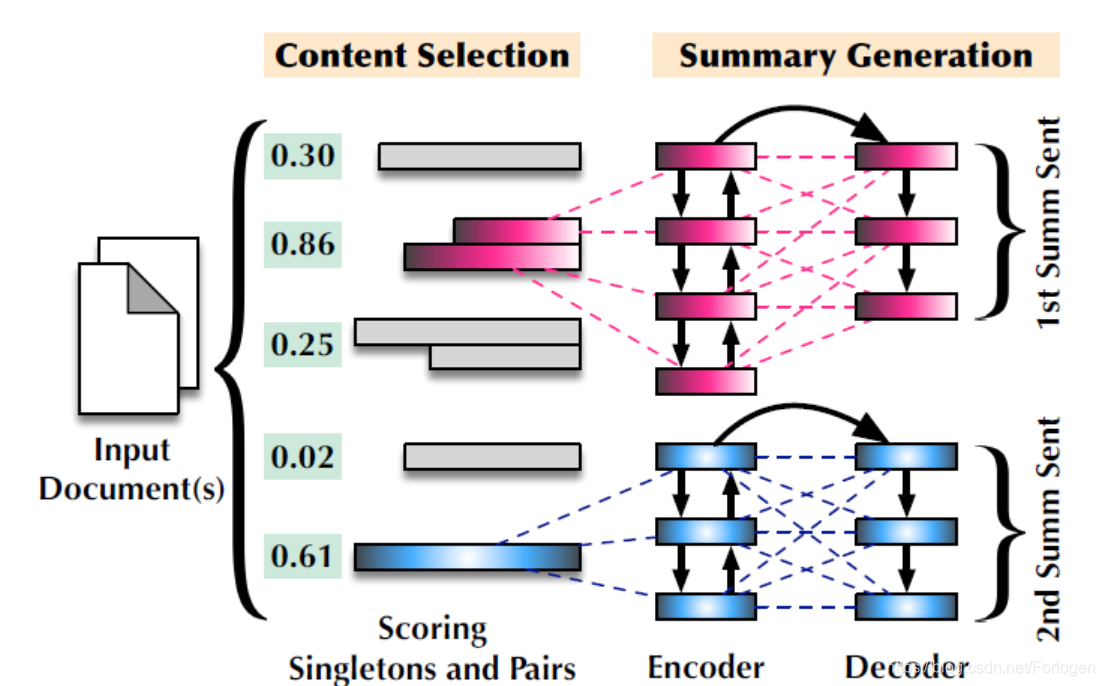
 本文介绍了一种针对抽象式摘要生成的框架,该框架通过选择单句或句子对,然后进行压缩和融合生成摘要,利用BERT进行表示学习,并在多个数据集上验证了有效性。
本文介绍了一种针对抽象式摘要生成的框架,该框架通过选择单句或句子对,然后进行压缩和融合生成摘要,利用BERT进行表示学习,并在多个数据集上验证了有效性。
Scoring Sentence Singletons and Pairs for Abstractive Summarization

在抽取式摘要生成中,模型可以看作一个文本二分类器,判断文档中的的每条语句是否会出现在最终的摘要中,最后将会出现在摘要中的句子组合成最终的结果。而在抽象式摘要生成中,模型需要根据文档中不同语句的表述生成最终的文档,而不只是简单的进行语句的直接抽取。
抛开模型不谈,首先考虑一下人是如何在阅读完文档后来写摘要的。总的来看,我认为人写摘要的过程更接近抽象式摘要生成过程。因为我们需要通读全文,然后根据自己的理解来进行总结,虽然很多内容可以在原文中找到,但是仍有一部分是不会出现在原文中。更具体的来说,我们往往会将多个句子归结为一句,让其代表所表述的内容,因此如何将单句和多个句子可以进行很好的信息融合,那么最终生成的摘要应该会满足要求。
另外从NLP具体的任务出发,在很多的数据集中,人给出的摘要中很大一部分也是通过多个句子的融合进行摘要的生成。因为作者提出了一种框架试图通过选择单句或句子对,然后再通过缩短单句及融合句子对生成最后的总结句,并在单文档和多文档的摘要数据集中进行实验,证明了想法的有效性。
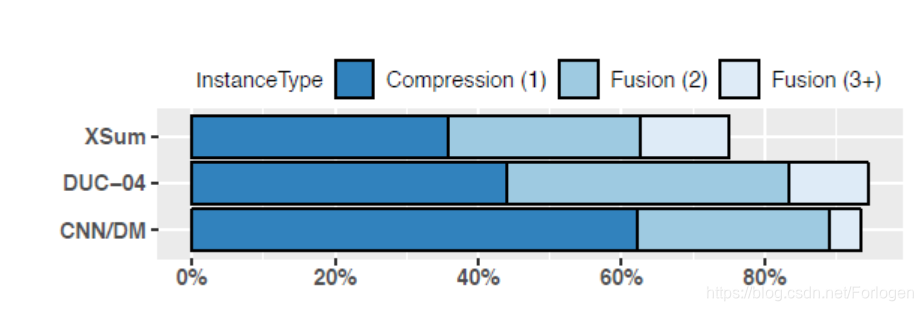
在真实数据集上单句压缩和多句融合对摘要的影响程度如下所示
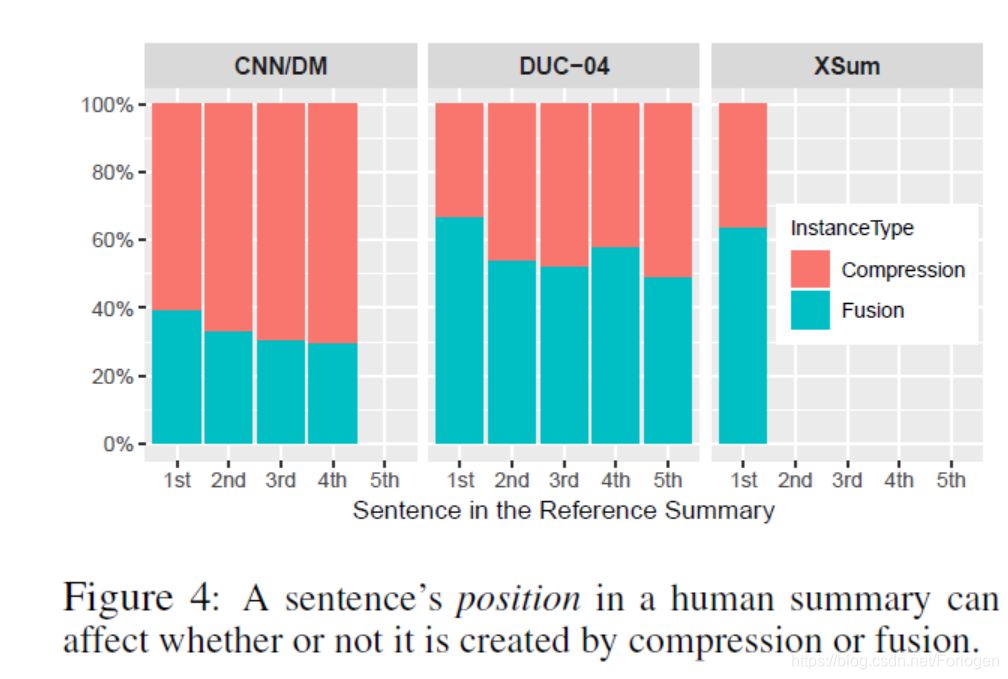
作者所提出的模型试图将单句和句子对都表示为位于同一向量空间中的实值向量,使得它们之间可以相互比较,从而希望可以捕获它们在语义上的相关性。但是由于单句和句子对在长度上通常是不相等的,因此如何处理不同长度语句的向量表示成为想法实现的关键一步。
对于给定的单文档或多文档,我们将文档中所有的单句和单句所可能组合成的句子对放入 D D D中,其中的单句和句子对这里称为实例(instance)。如何文档中存在 N N N个单句,那么可能组成的句子对就有 N ( N − 1 ) 2 \frac{N(N-1)}{2} 2N(N−1)个,那么 D D D中实例的个数为 ∣ D ∣ = N ( N − 1 ) 2 + N |D| = \frac{N(N-1)}{2} + N ∣D∣=2N(N−1)+N 。
但显然无法使用所有的实例来生成摘要,因此这里需要根据它们对于最终摘要的贡献进行评分,选择分数较高的句子来生成摘要。但又有一个问题:单句包含的信息可能比句子对多,句子对包含的信息也可能比单句多,如何学习到一种可以消除这种差异的表示将变得十分重要。
为了解决上述的问题,这里使用了BERT来进行单句和句子对的表示学习,然后使用二阶段的分类任务(判断单句或句子对是否包含人写的摘要中的信息)进行参数的精调。BERT提供了MASK LM 和Predict Next Sentence两种方式来进行模型的训练,作者认为表示一致的句子位置通常也是接近的,因此采用了第二种方式进行表示学习。
BERT的输入采用 [ C L S ] [\mathrm{CLS}] [CLS]和 [ S E P ] [\mathrm{SEP}] [SEP]来进行句子的组合,然后将学习后 [ C L S ] [\mathrm{CLS}] [CLS]的表示当做整个句子的表示用于下游的任务。假设句子 A = { w i A } , i = 1 , 2 , . . . , m A=\{w_{i}^A\},i=1,2,...,m A={wiA},i=1,2,...,m, B = { w j B } , j = 1 , 2 , . . . , n B=\{w_{j}^B\},j=1,2,...,n B={wjB},j=1,2,...,n,那么组合后的形式可以表示为 { w i } = [ C L S ] , w 1 A , w 2 A , … , [ S E P ] , w 1 B , w 2 B , … , [ S E P ] \left\{w_{i}\right\}=[\mathrm{CLS}], w_{1}^{\mathrm{A}}, w_{2}^{\mathrm{A}}, \ldots,[\mathrm{SEP}], w_{1}^{\mathrm{B}}, w_{2}^{\mathrm{B}}, \ldots,[\mathrm{SEP}] {wi}=[CLS],w1A,w2A,…,[SEP],w1B,w2B,…,[SEP]那么BERT的输入为
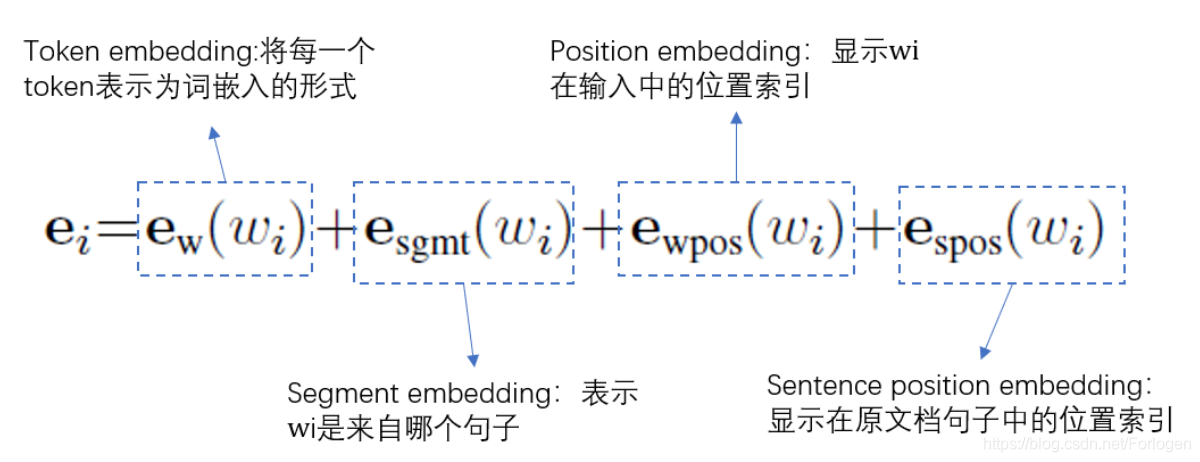
其中这些嵌入对于序列 ( A + B ) (A+B) (A+B)的贡献程度由以下因素影响:
- 词的突出性
- A A A或 B B B的重要性
- 词在输出序列中的位置
- 句子在文档中的位置
一般来说,文档中每段的前几句通常都是其总结性作用的,因此它们中所包含的词更有可能出现在摘要中。然后将输入的嵌入向量送到多个self-attention和multi-head attention所组成的BERT中,且其中多头注意力的计算为
h
i
1
=
f
self-attr
1
(
e
i
,
[
e
1
,
e
2
,
…
,
e
N
]
)
h
i
l
+
1
=
f
self-attn
l
+
1
(
h
i
l
,
[
h
1
l
,
h
2
l
,
…
,
h
N
l
]
)
\begin{aligned} \mathbf{h}_{i}^{1} &=f_{\text { self-attr }}^{1}\left(\mathbf{e}_{i},\left[\mathbf{e}_{1}, \mathbf{e}_{2}, \ldots, \mathbf{e}_{\mathrm{N}}\right]\right) \\ \mathbf{h}_{i}^{l+1} &=f_{\text { self-attn }}^{l+1}\left(\mathbf{h}_{i}^{l},\left[\mathbf{h}_{1}^{l}, \mathbf{h}_{2}^{l}, \ldots, \mathbf{h}_{\mathrm{N}}^{l}\right]\right) \end{aligned}
hi1hil+1=f self-attr 1(ei,[e1,e2,…,eN])=f self-attn l+1(hil,[h1l,h2l,…,hNl])
其中
h
i
h_{i}
hi表示隐状态,不同的
h
i
h_{i}
hi的计算可并行化进行。然后将最后一层
[
C
L
S
]
[\mathrm{CLS}]
[CLS]位置的表示
h
[
C
L
S
]
L
h_{[\mathrm{CLS}]}^L
h[CLS]L做为习得的表示,再使用下游的任务进行精调。这是首次尝试为单句和句子对构建语义表示,从而来捕获两句话之间的信息和语义兼容性。
在得到了关于单句和句子对的表示之后,作者使用了MMR原理来选择得分最高的一组非冗余实例来进行摘要生成。然后根据下式来选择过滤后的实例,直到达到设置的摘要的长度阈值。
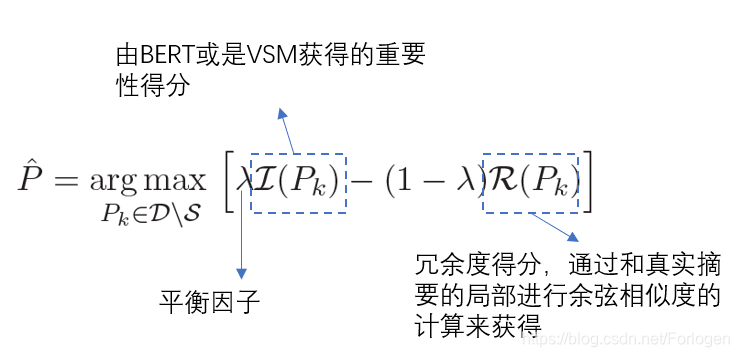
通过上式可以确保模型不会选择到和已生成的摘要相似度太高的句子。在得到得分最高的一组句子后,作者直接使用了pointer-generator networks来进行句子的融合。按照得分的高低,模型不断的融合句子生成摘要中的句子。
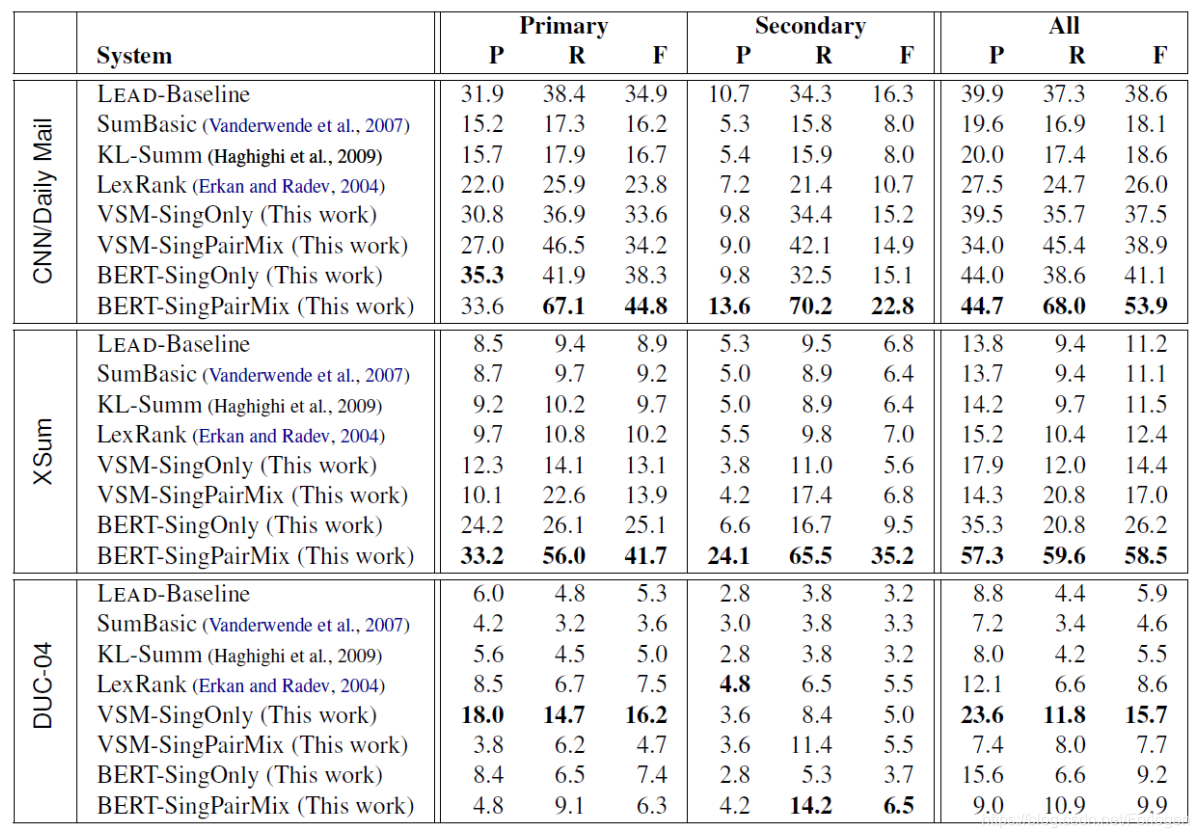
实验部分所采用的数据集有XSum、CNN/DM、DUC-04,评价指标为ROUGE-1, -2, -L scores,基准模型有SumBasic、KL-Sum、LexRank。实例选择的实验结果为
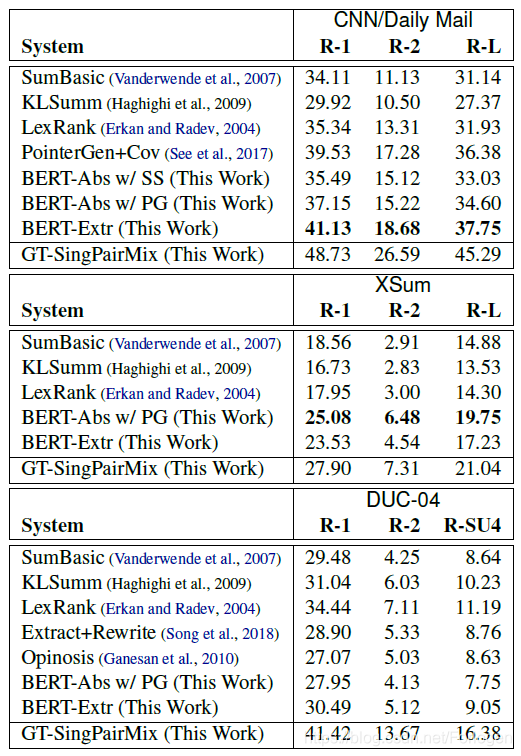
多个数据集上摘要的生成结果为
作者通过实验证明了框架的有效性,同时实例选择和摘要生成两个过程的松散结合也降低了对于标注数据的需求。

















 3771
3771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









