 神经网络与机器翻译
神经网络与机器翻译







 本文深入探讨了神经网络在机器翻译中的应用,包括RNN及其变体,Seq2Seq模型,注意力机制,以及NMT(神经机器翻译)的训练与解码策略。详细讲解了从统计机器翻译到神经网络翻译的演变,以及NMT模型如何自动学习特征,实现高质量的翻译。
本文深入探讨了神经网络在机器翻译中的应用,包括RNN及其变体,Seq2Seq模型,注意力机制,以及NMT(神经机器翻译)的训练与解码策略。详细讲解了从统计机器翻译到神经网络翻译的演变,以及NMT模型如何自动学习特征,实现高质量的翻译。
前两讲主要介绍的是RNN、RNN的多个变体和其中的梯度消失问梯度爆炸问题,以及相应的解决方法。这一将介绍了RNN的一种应用场景-机器翻译(Machine Translation,MT),并主要解释了在NLP中使用率极高的Sequence-to-Sequence(Seq2Seq)模型和用于提升模型效果的注意力机制(Attention)。
在正式介绍基于神经网络模型的机器翻译之前,首先简单的来看一下机器翻译的发展过程。机器翻译是一种将源语言序列 x x x转换为目标语言序列 y y y的技术,同时需要保证两者语义的一致性。

机器翻译最早可以追溯到1950s,那时由于冷战的需要,MT所做的工作主要是俄语和英语之间的相互翻译。而且那时的工作主要是基于规则的,需要俄语和英语对应的双语词典才能实现。基于规则的翻译系统需要专家手动的定义规则并不断的维护和更新规则,虽然具有一定的效果,但是系统的消耗和限制性很大。
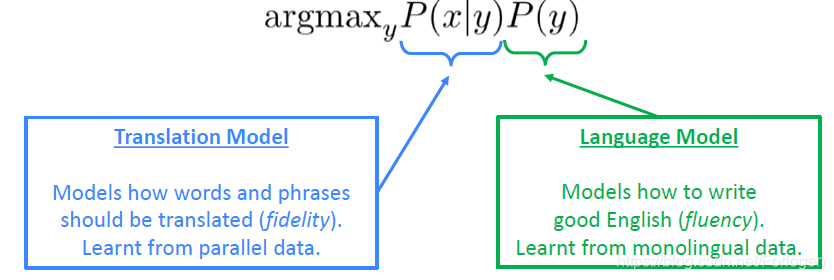
在1990s~2010s阶段机器翻译主要的工作集中于统计机器翻译(Statistical Machine Translation,SMT),核心思想是希望从数据中学习到一种概率模型,实现不同语言之间的相互转换。例如在法英的互译中,我们希望在给定法语句子 x x x的前提下找到最合适的英语句子 y y y,即计算概率 arg max y P ( y ∣ x ) \arg \max_{y}P(y|x) argmaxyP(y∣x)。通常为了计算上的方便,需要使用贝叶斯规则将其变换为 arg max y P ( x ∣ y ) P ( y ) \arg \max_{y}P(x|y)P(y) argmaxyP(x∣y)P(y)。其中
- P ( x ∣ y ) P(x|y) P(x∣y)看做翻译模型(Translation Model),实现从配对数据中学习两种语言词和短语之间的转换
-
P
(
y
)
P(y)
P(y)看做是之前所讨论的语言模型(Language Model),实现如何输入更好的满足要求的目标语句
根据前面所学习的知识,我们有很多的选择来建模后半部分的语言模型,现在最主要的工作是如何学习 P ( x ∣ y ) P(x|y) P(x∣y)。根据它所要完成的工作,首先需要想要互译的两种语言的配对数据,就像Rosetta Stone所提供的对于相同信息用不同的语言进行描述这类的数据。

假设可以有各种途径收集到想要的语料库,下一步考虑的是如何从得到的语料库中学习 P ( x ∣ y ) P(x|y) P(x∣y)。 进一步需要考虑的是 P ( x , a ∣ y ) P(x,a|y) P(x,a∣y),其中 a a a表示对齐模型,即根据此时每个输入词 x i x_{i} xi能量的大小,就可以知道应该使用哪个词与当前的 y i y_{i} yi进行对齐。这样的对齐方式又称为soft alignment, 也就是可以求得梯度, 所以可以与整个模型一起优化。
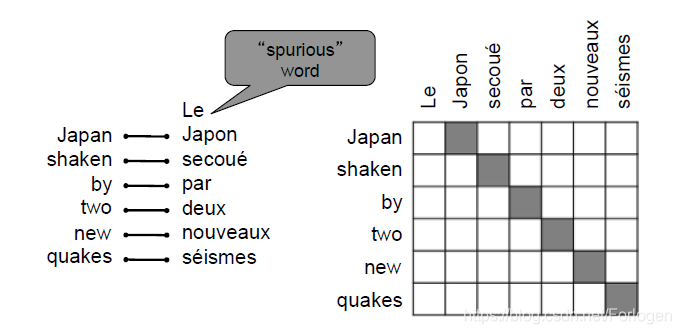
对齐表示的是源语言和目标语言之间某些词之间的对应关系,但需要注意的是某些词之间可能在另一种语言中并不存在对应的词。例如在下面的例子中,Le这个词在另一种语言中就不存在对应的词。
不同语言之间的对齐是很复杂的,存在着一对多、多对一和多对多的关系。
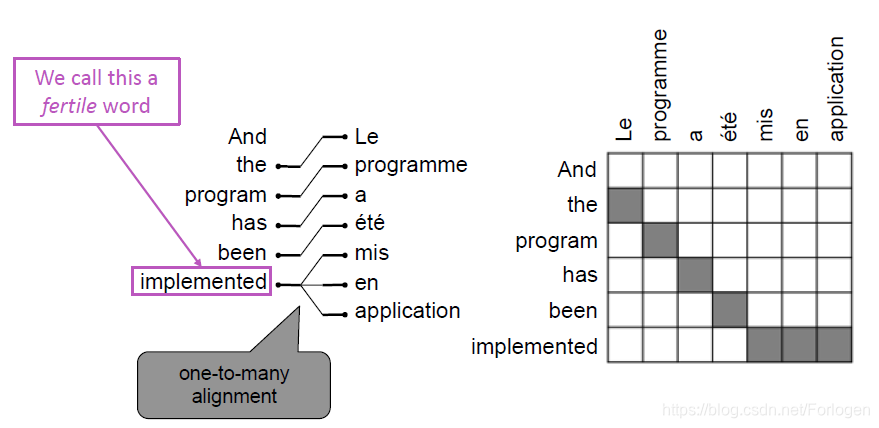
one-to-many
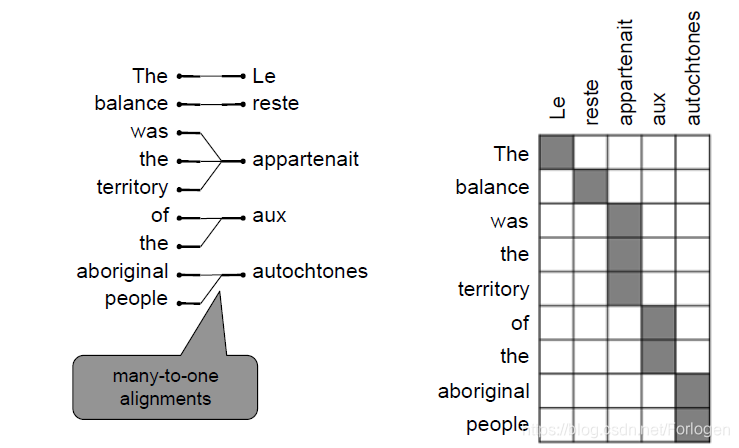
many-to-one
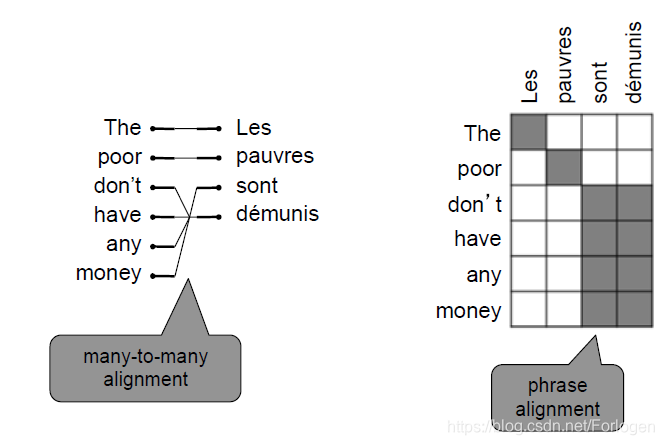
many-to-many
由于对齐关系的复杂性,在学习 P ( x , a ∣ y ) P(x,a|y) P(x,a∣y)时需要考虑很多的因素。在知道了有关 P P P的计算部分后,如何求解 arg max \arg \max argmax?这意味着我们需要找到最匹配源语句中指定词的目标词。一种暴力的方式就是进行穷举,但这样的方式耗费太大,显然不是可执行的方式。
另一种方式就是使用启发式的搜索算法来寻找较优的词,这个过程也称为解码(decoding)。
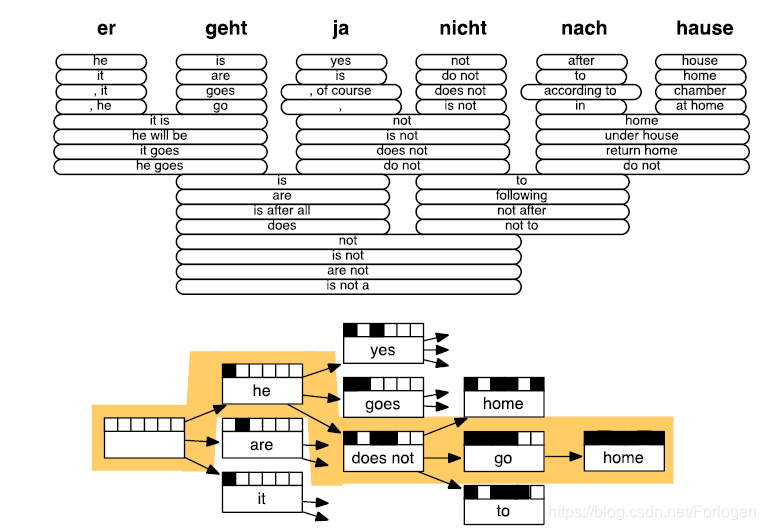
SMT的发展已经取得了不错的成果,在很多场景中得到了充分的应用。但是它本身的复杂性、大量的特征工程、资源的消耗量和人为介入的工作,使得它仍具有很多的不足之处。
2014年之后,基于神经网络的机器翻译(Neural Machine Translation,NMT)给机器翻译的研究提供了另一种更加有效的解决思路,并逐渐的替代基于统计的模型在机器翻译中的地位。它希望借助神经网络强大的学习能力,自动的学习到某些需要的特征,自动的实现两种语言间的互译。而NMT常使用的网络架构包含两个RNNs,因此模型架构也称为sequence-to-sequence或seq2seq。
seq2seq模型如下所示,整个模型主要包含encoder和decoder两个部分。encoder复杂将源语言语句转换成编码,然后将其送到decoder中,使用语言模型的那一套方式逐步的产生目标语句。
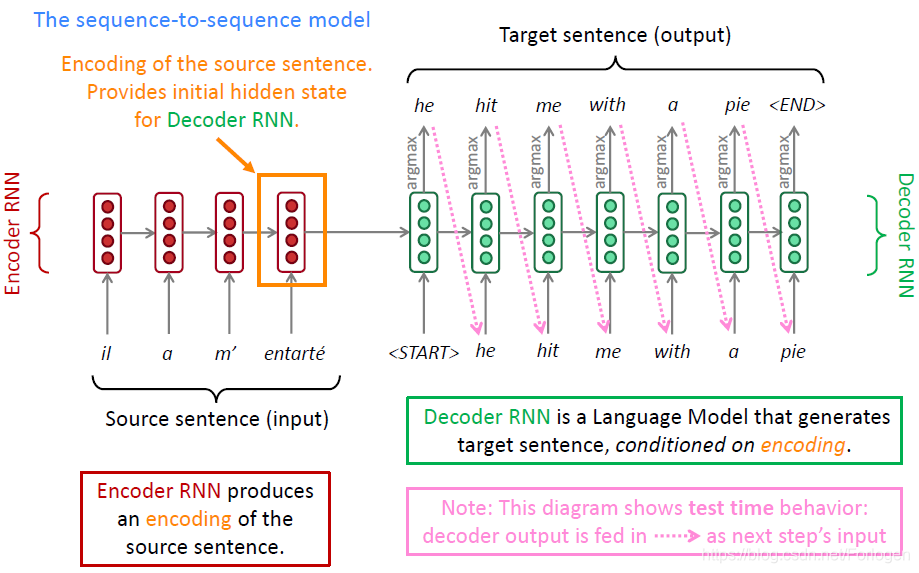
当然seq2seq的模型不仅只可以适用于机器翻译,同样也可以应用于NLP的其他领域,例如自动摘要、对话生成、文本生成等。

seq2seq的模型可以看做是条件语言模型(Conditional Language Model)的一个例子。语言模型是指decoder在产生目标语句的时候需要预测下一个词;而条件是指在产生 y y y的时候需要根据 x x x。
因此 P ( y ∣ x ) P(y|x) P(y∣x)的计算过程可以表示为:

那如何训练一个NMT模型呢?首先同样需要收集大量的配对数据,构建大型的语料库。然后使用交叉熵或是负对数似然构建损失函数,使用反向传播进行end-to-end的训练,不断的调整模型参数,直到收敛或是到达指定的停止条件。
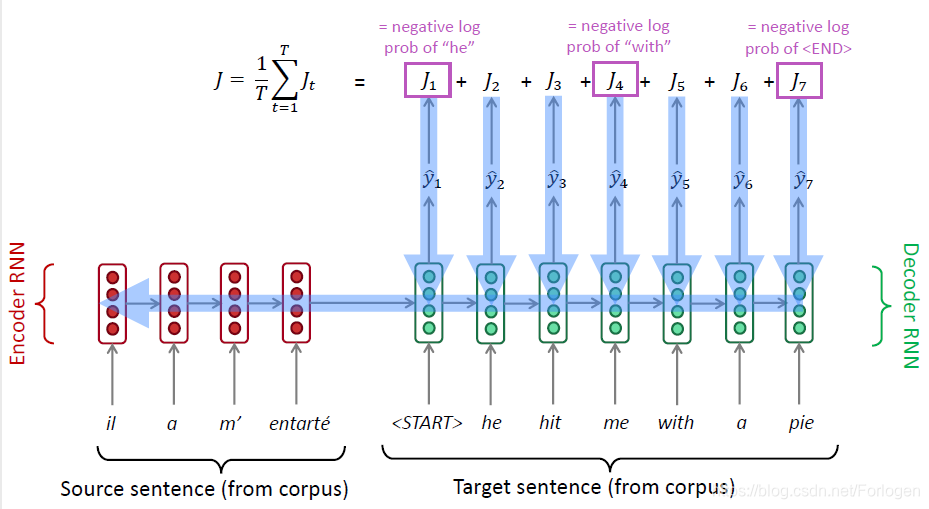
在解码的过程中,模型无法直接生成完整的语句,往往采用贪婪编码(greedy decoding)的方式每一时间步生成一个词。而且每一时间步产生的词往往不止一个,一旦某一步选错,错误就会随着时间不断的累积。
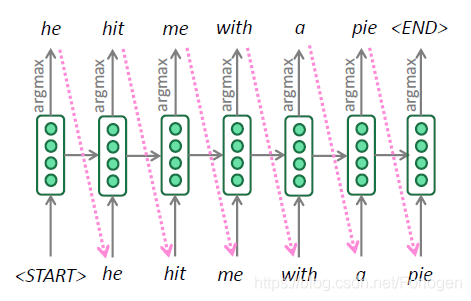
理想情况下,我们希望模型通过最大化
P
(
y
∣
x
)
=
P
(
y
1
∣
x
)
P
(
y
2
∣
y
1
,
x
)
P
(
y
3
∣
y
1
,
y
2
,
x
)
…
,
P
(
y
T
∣
y
1
,
…
,
y
T
−
1
,
x
)
=
∏
t
=
1
T
P
(
y
t
∣
y
1
,
…
,
y
t
−
1
,
x
)
\begin{aligned} P(y | x) &=P\left(y_{1} | x\right) P\left(y_{2} | y_{1}, x\right) P\left(y_{3} | y_{1}, y_{2}, x\right) \ldots, P\left(y_{T} | y_{1}, \ldots, y_{T-1}, x\right) \\ &=\prod_{t=1}^{T} P\left(y_{t} | y_{1}, \ldots, y_{t-1}, x\right) \end{aligned}
P(y∣x)=P(y1∣x)P(y2∣y1,x)P(y3∣y1,y2,x)…,P(yT∣y1,…,yT−1,x)=t=1∏TP(yt∣y1,…,yt−1,x)来生成目标句
y
y
y,那么就需要计算所有可能的
y
y
y的概率。那么在每个时间步
t
t
t,当词汇表大小为
V
V
V时就需要考虑
V
t
V^t
Vt中可能的部分翻译(partial translations),但这需要
O
(
V
T
)
O(V^T)
O(VT)的时间复杂度,这对于实际应用来说是难以接受的。
另一种好的方法是集束搜索(Bean search ),它的核心思想是在解码的每个时间步,选择K个最可能的词作为下一步的翻译,K这里称为beam size。
假设字典为[a,b,c],beam size选择2:
-
在生成第1个词的时候,选择概率最大的2个词,那么当前序列就是a或b
-
生成第2个词的时候,我们将当前序列a或b,分别与字典中的所有词进行组合,得到新的6个序列aa ab ac ba bb bc,然后从其中选择2个概率最高的,作为当前序列,即ab或bb
-
不断重复这个过程,直到遇到结束符为止。最终输出2个概率最高的序列。
在
y
1
,
.
.
.
,
y
t
y_{1},...,y_{t}
y1,...,yt的产生过程中,每个
y
i
y_{i}
yi都有一个分数,整个序列的得分为
score
(
y
1
,
…
,
y
t
)
=
log
P
L
M
(
y
1
,
…
,
y
t
∣
x
)
=
∑
i
=
1
t
log
P
L
M
(
y
i
∣
y
1
,
…
,
y
i
−
1
,
x
)
\operatorname{score}\left(y_{1}, \ldots, y_{t}\right)=\log P_{\mathrm{LM}}\left(y_{1}, \ldots, y_{t} | x\right)=\sum_{i=1}^{t} \log P_{\mathrm{LM}}\left(y_{i} | y_{1}, \ldots, y_{i-1}, x\right)
score(y1,…,yt)=logPLM(y1,…,yt∣x)=i=1∑tlogPLM(yi∣y1,…,yi−1,x)
其中所有的得分都是非负的,得分越高表示越好。但是集束搜索同样不能保证找到最优的目标序列,但是比穷举搜索更加有效。
下图是集束搜索的一个示例
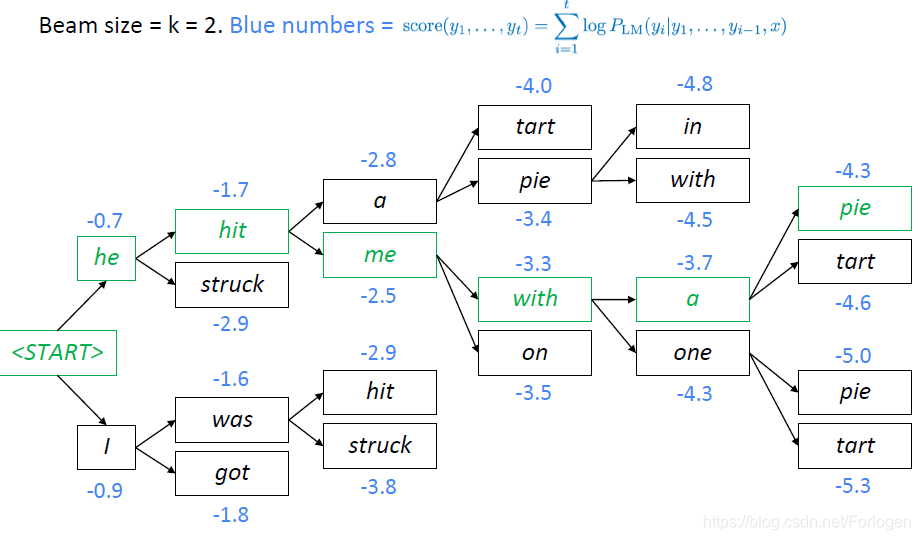
在贪婪搜索中解码过程进行到 < E N D > <END> <END>时停止,而在集束搜索中不同的假设往往会在不同的时间步产生 < E N D > <END> <END>,但是当产生 < E N D > <END> <END>后就认为生成的序列已经是完整的。重复进行此过程,直到达到设定的时间步 T T T或已生成 n n n个序列。
当搜索停止时,需要从中选择一个得分最高的结果。但是往往长的序列具有较低的得分,为了缓解这种矛盾需要进行归一化操作 1 t ∑ i = 1 t log P L M ( y i ∣ y 1 , … , y i − 1 , x ) \frac{1}{t} \sum_{i=1}^{t} \log P_{\mathrm{LM}}\left(y_{i} | y_{1}, \ldots, y_{i-1}, x\right) t1∑i=1tlogPLM(yi∣y1,…,yi−1,x)。
NMT的优势在于:
- 效果更好:生成的语句更流畅,更好的利用了上下文信息等
- 可以使用end-to-end的方式轻松训练
- 不过分的依赖于特征工程等人的参与
NMT的不足在于:
- 解释性差:神经网络模型的共同缺陷
- 难以控制:当出问题时无法判断是哪一部分出现了问题
在机器翻译领域一种自动化的评估方式为BLEU(Bilingual Evaluation Understudy),它通过比较机器生成的翻译语句和人写的翻译语句的相似性,得出相似性得分。虽然BLEU被普遍使用,但是它同样并不是一个完美的评估手段。

虽然基于神经网络的机器翻译取得了很好的效果,但仍有很多的问题没有解决,,有很多同样也是NLP各个领域共同的问题

后面关于注意力机制的部分这里就不写了,可以参考我之前翻译的 Attention?Attention!。

















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









