






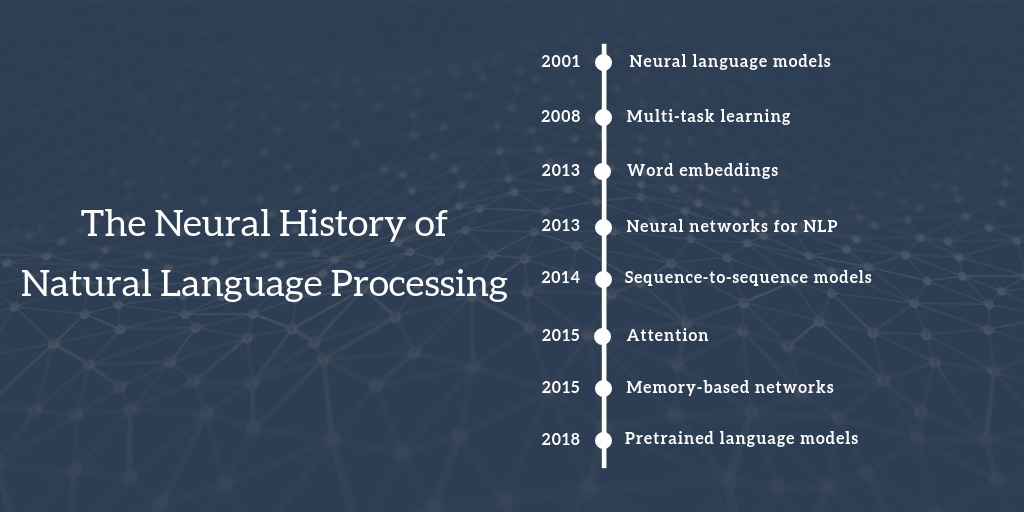
 本文回顾了自然语言处理中神经网络的关键里程碑,从2001年的神经语言模型到2018年的预训练语言模型,涵盖了多任务学习、词嵌入、循环神经网络、注意力机制等核心概念。
本文回顾了自然语言处理中神经网络的关键里程碑,从2001年的神经语言模型到2018年的预训练语言模型,涵盖了多任务学习、词嵌入、循环神经网络、注意力机制等核心概念。
以下内容主要是对最近看到的 A Review ofthe Neural History of Natural Language Processing 的翻译,中间也会补充一些其他相关的内容,能力有限,仅作个人总结学习之用~
整个blog的主要内容按如下的八个神经网络在NLP中的里程牌逐个阐述,因此对于很多传统的非神经网络的方法并没有太多提及,但并不表示它们不重要,只是这里的侧重不同而已。
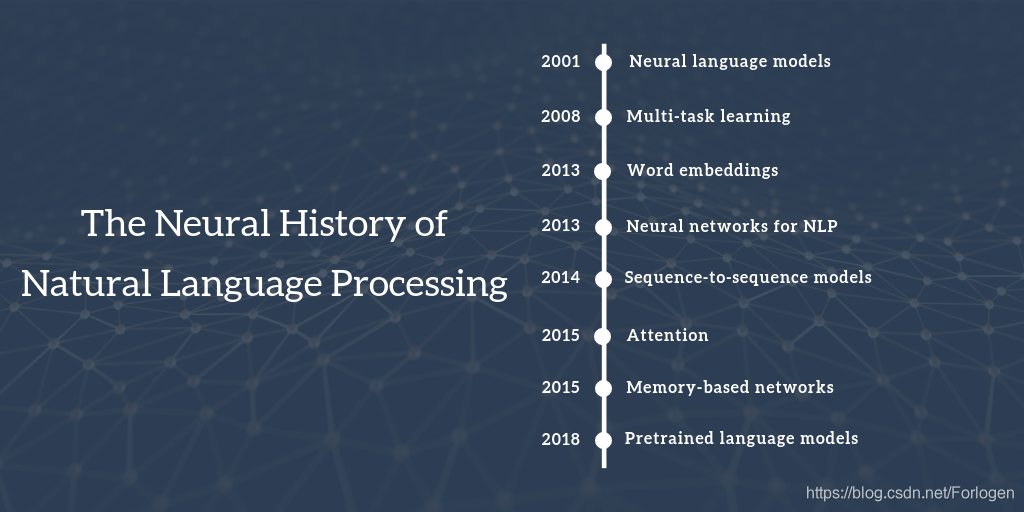
source:http://ruder.io/content/images/size/w2000/2018/10/neural_history_of_nlp_image.png
2001 - Neural language models
语言建模(Language modeling)的任务可看作是在文本给定的情况下,根据前面已知的词来预测下一个词是什么。这是NLP中最为简单的一种任务,但同样具有很多的应用场景,比如智能键盘、Email的回复建议、拼写自动更正等等。其中n-grams是一种最为经典的建模方法,它使用一种平滑的方式来处理不可见的n-grams,可以将其看作一种模糊匹配的方式。
第一个神经语言模型由Bengio, Y., Ducharme, R., & Vincent, P. 发表在在NIPS 2001 上的《A Neural Probabilistic Language Model》一文中提出,这里使用的是一个前馈神经网络(feed-forward neural network)模型
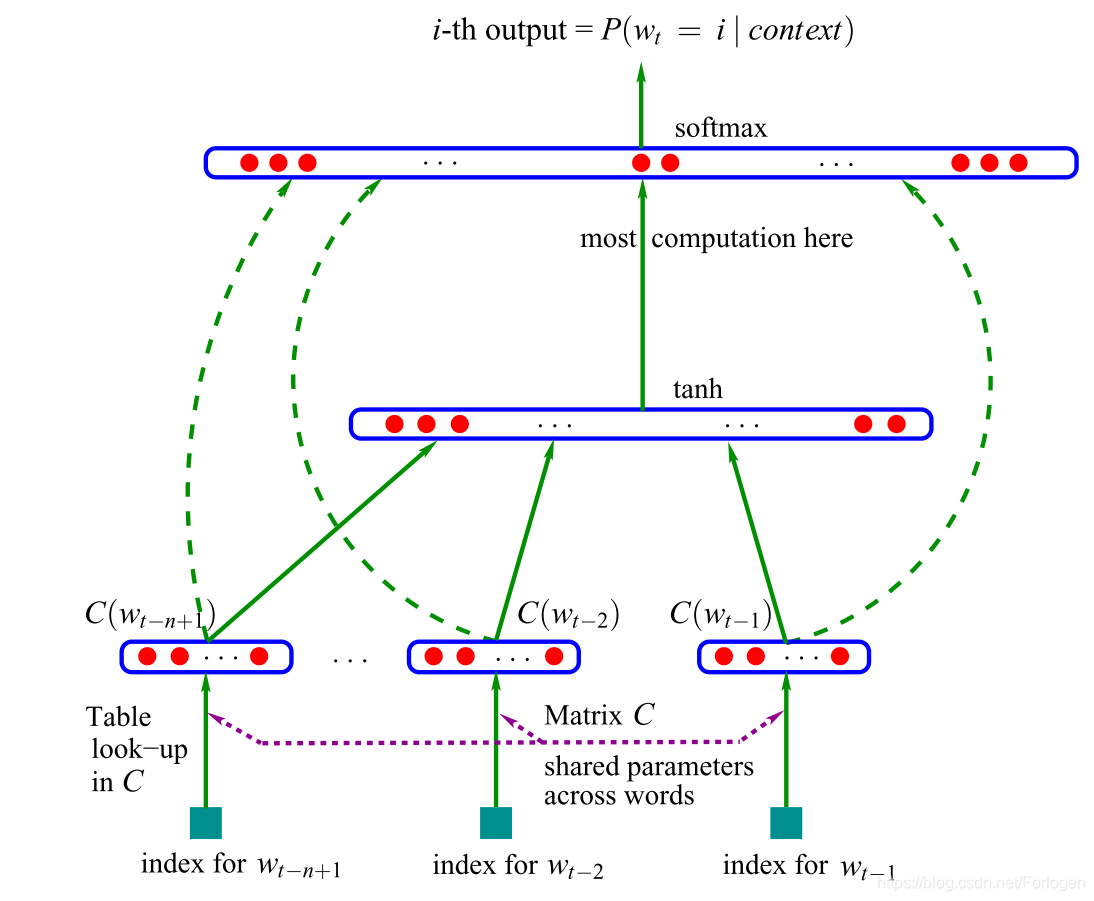
模型以 n n n个先前的单词的表征向量做为输入,这些表征向量可在表 C C C中查找得到,而这样的表征向量现在更多的称为词向量(word embedding)。这些词向量被连接恰里并做为一个隐藏层的输入,然后将隐藏层的输出提供给最后的Softmax层来得到最后的结果。
更多的细节部分建议查看paper,或是浏览On word embeddings - Part 1 这篇博文
而近些年来,研究者更多的是用递归神经网络(Recurrent Neural Netword,RNN)和长短时记忆网络(Long Short-term Memory Networs,LSTM)来进行语言建模,同时也已经提出了许多对经典LSTM扩展的新语言模型。尽管不断有新的改进模型的出现,经典的LSTM仍然是一个非常重要且强大的基准模型,甚至上述提到的经典的前馈神经网络模型在某些情况也可以和这些复杂模型竞争,因为它们通常只考虑给定的单词最近的几个词。如何更好的理解这样的语言模型所捕获到的信息,仍是一个活跃且重要的研究领域。
关于上述提到的模型,可参见对应的papers:
Mikolov, T., Karafiát, M., Burget, L., Černocký, J., & Khudanpur, S. (2010). Recurrent neural network based language model. In Eleventh Annual Conference of the International Speech Communication Association.
Graves, A. (2013). Generating sequences with recurrent neural networks.
Melis, G., Dyer, C., & Blunsom, P. (2018). On the State of the Art of Evaluation in Neural Language Models. In Proceedings of ICLR 2018.
Daniluk, M., Rocktäschel, T., Weibl, J., & Riedel, S. (2017). Frustratingly Short Attention Spans in Neural Language Modeling. In Proceedings of ICLR 2017.
Kuncoro, A., Dyer, C., Hale, J., Yogatama, D., Clark, S., & Blunsom, P. (2018). LSTMs Can Learn Syntax-Sensitive Dependencies Well, But Modeling Structure Makes Them Better. In Proceedings of ACL 2018 (pp. 1–11).
Blevins, T., Levy, O., & Zettlemoyer, L. (2018). Deep RNNs Encode Soft Hierarchical Syntax. In Proceedings of ACL 2018.
RNNs在语言建模领域可以发挥很强劲的作用,因为它的处理方式更符合人对语言处理的认知。同时语言建模是一种无监督学习的形式,Yann LeCun也将其称为预测学习(predictive learning),并将其作为获得常识的先决条件。尽管它很简单,但它确实在语言建模领域有着十分不错的效果,同时它也是后续讨论的许多改进模型的核心:
- Word Embedding:word2vec的目标是简化语言建模
- Sequence to Sequence models:通过每次预测一个单词来生成一个输出序列。
- Pretrained language models:使用来自语言模型的表示来进行迁移学习
反过来我们可以将NLP中许多最重要的最新进展都可以归结为语言建模的一种形式。为了做“真正的”自然语言理解,仅仅从原始文本的形式学习可能是不够的,我们需要新的方法和模型。
2008 - Multi-task learning
多任务学习是在多任务训练的模型之间共享参数的一种通用方法。在神经网络中,这可以很容易地通过捆绑不同层的权重来实现。多任务学习的概念最早由Rich Caruana于1993年提出,并应用于道路跟踪和肺炎预测(Caruana, 1998)。直观地说,多任务学习鼓励模型学习对许多任务均有用的表示。这对于学习一般的、低层次的表示,以集中模型的注意力,或者在训练数据有限的情况下尤其有用。想要更全面地了解多任务学习请看这篇文章。
Caruana, R. (1993). Multitask learning: A knowledge-based source of inductive bias. In Proceedings of the Tenth International Conference on Machine Learning.
Caruana, R. (1998). Multitask Learning. Autonomous Agents and Multi-Agent Systems, 27(1), 95–133.
Collobert和Weston在2008年首次将神经网络应用到了NLP的多任务学习中。在他们的模型中,查找表(或单词嵌入矩阵)在针对不同任务训练的两个模型之间共享,如下所示
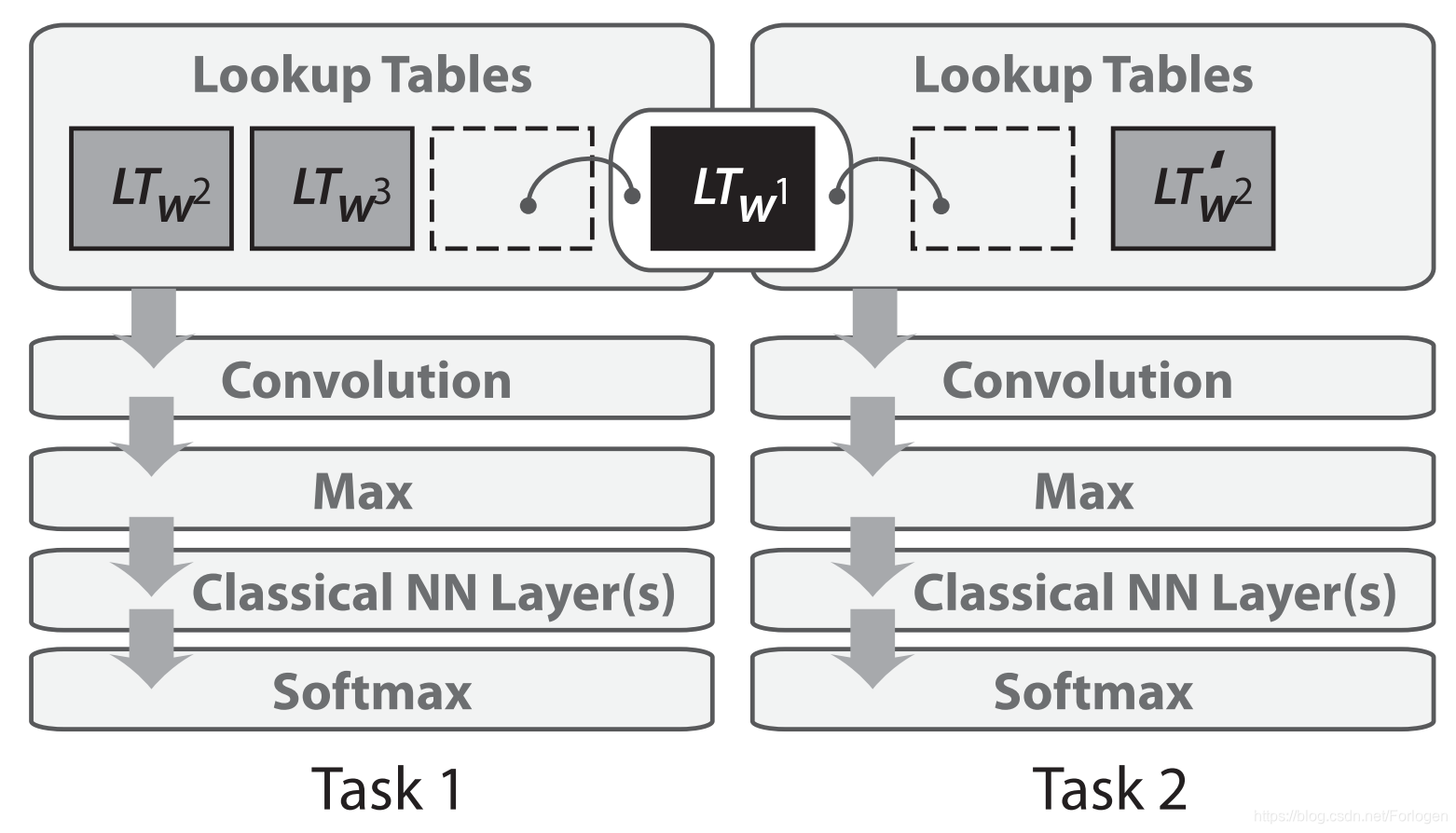
Collobert, R., & Weston, J. (2008). A unified architecture for natural language processing. In Proceedings of the 25th International Conference on Machine Learning (pp. 160–167).
Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., & Kuksa, P. (2011). Natural Language Processing (almost) from Scratch. Journal of Machine Learning Research, 12(Aug), 2493–2537.
共享词嵌入(word embeddings)使模型能够协作并共享词嵌入矩阵(word embedded matrix)中的一般性的底层信息,通常词嵌入矩阵由模型中最多的参数构成。Collobert和Weston在2008年发表的论文证明,这样的方式的影响力已经超出了多任务学习的应用。它率先提出了一些想法,比如对单词进行预训练得到词嵌入,以及对文本使用卷积神经网络(CNNs),而这些想法在过去几年才被广泛采用。
多任务学习现在被广泛地应用于NLP任务中,利用现有的或“人工”任务已经成为NLP库中一个有用的工具。有关不同辅助任务的概述,请参阅Multi-Task Learning Objectives for Natural Language Processing。虽然参数共享通常是预定义的,但在优化过程中也可以学习到不同的共享模式。由于多任务学习优秀的泛化能力,许多的模型对它的关注越来越多,最近有人提出了专门针对多任务学习基准(benchmarks)。
更多详细信息可参阅下面的papers:
Ruder, S., Bingel, J., Augenstein, I., & Søgaard, A. (2017). Learning what to share between loosely related tasks. ArXiv Preprint ArXiv:1705.08142.
Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., & Bowman, S. R. (2018). GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding.
McCann, B., Keskar, N. S., Xiong, C., & Socher, R. (2018). The Natural Language Decathlon: Multitask Learning as Question Answering.
2013 - Word embeddings
文本的稀疏向量表示,即词袋(bag-of-words)模型在NLP中有着悠久的历史。如上所述,词的密集向量表示或词嵌入早在2001年就已经被使用。Mikolov等人在2013年提出的模型的主要创新点是通过去除隐藏层提升计算效率,并可以更好的逼近目标,使词嵌入的训练更加有效。虽然这些更改本质上很简单,但是它们与高效的word2vec实现一起实现大规模的词嵌入训练任务。
Word2vec有两种方法:CBOW和skip-gram。它们的目标不同:一个基于上下文的词预测中心词(centre word),而另一个则相反,示意图如下所示:
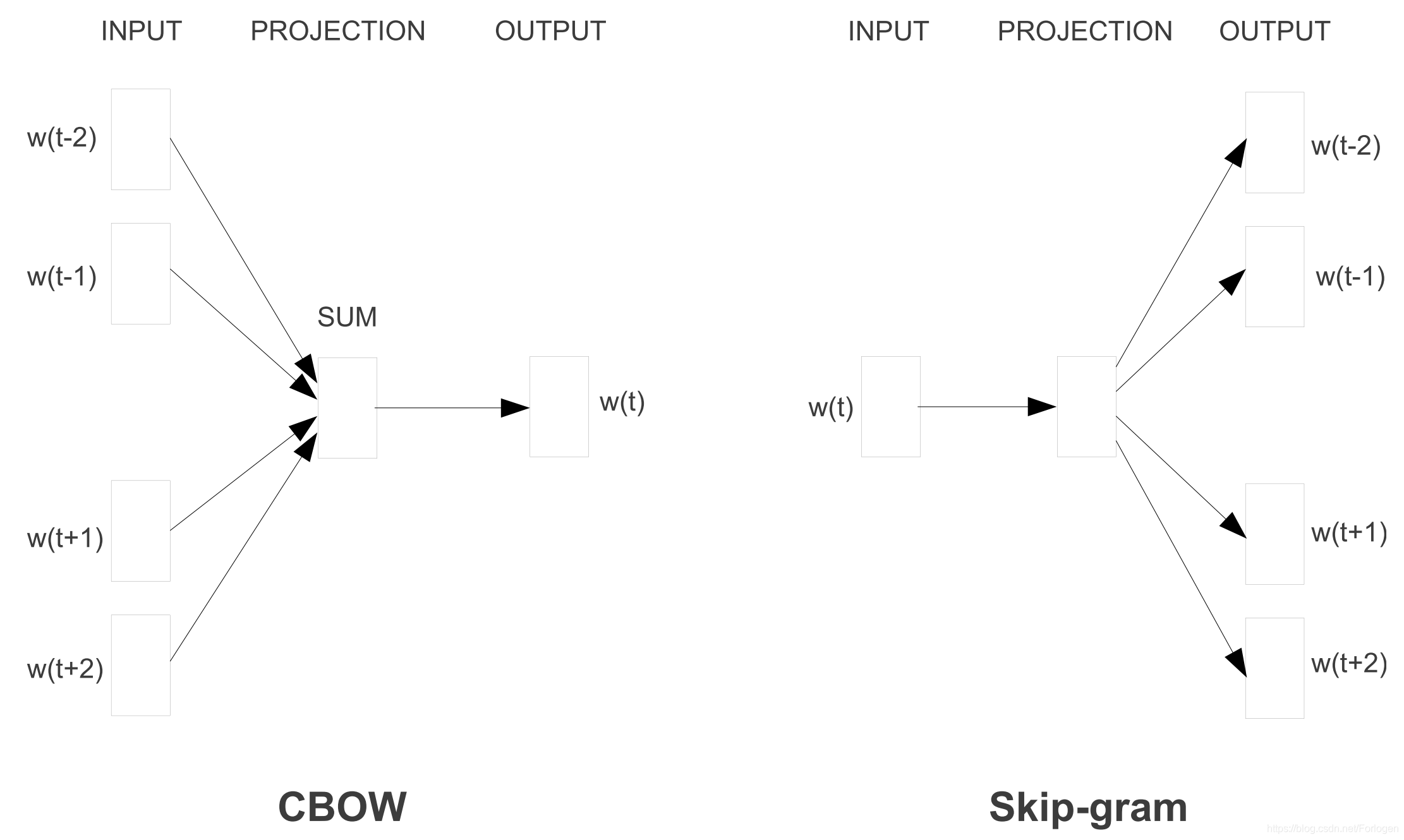
虽然使用word2vec得到的词嵌入与之前使用前馈神经网络学习的词嵌入在概念上没有什么不同,但是word2vec是在一个非常大的语料库上的训练,使得到的词向量能够近似于单词之间的某些关系,例如性别、动词-时态和国家-首都等,如下图所示:
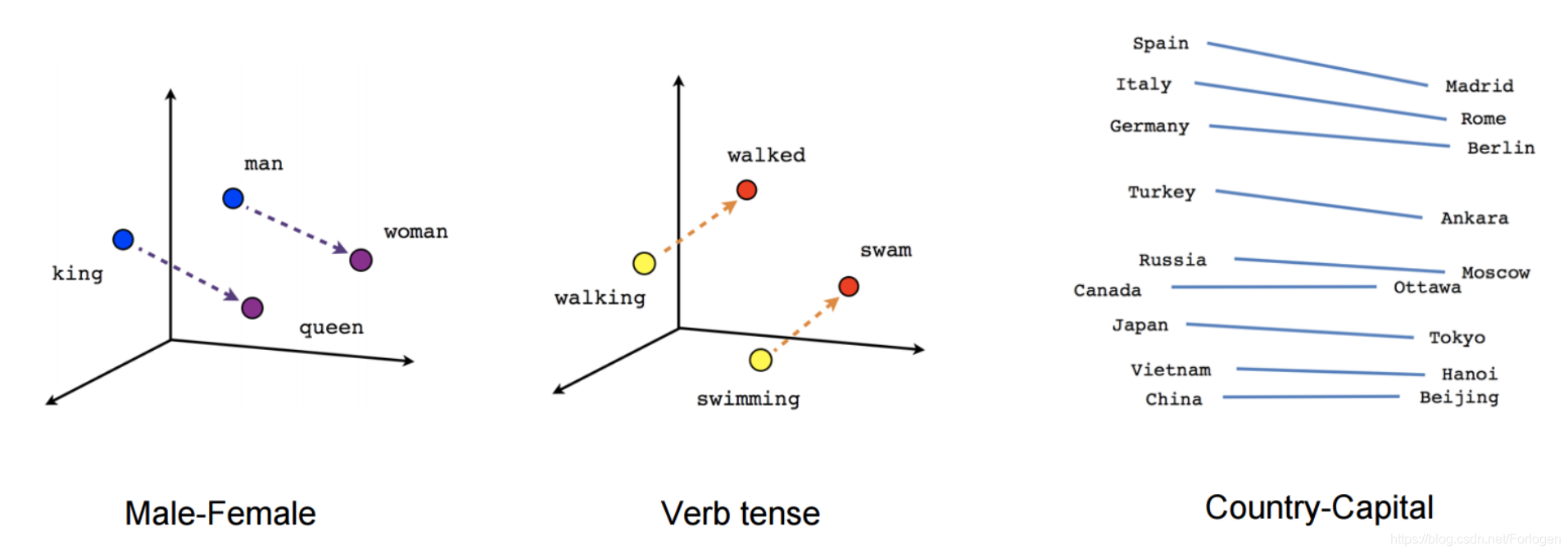
这些关系及其背后的含义引发了人们对词嵌入的最初兴趣,目前已有许多的研究工关注于这些线性关系的起源。然而,后来的研究表明,这些学习得到的关系并非没有偏置。将词嵌入作为当前NLP的主流的的做法是使用预训练的嵌入作为初始化,来提高下游任务的性能。
虽然word2vec捕捉到的关系具有一种直观的、几乎不可思议的特性,但后来的研究表明,word2vec本身并没有什么特别之处:词嵌入也可以通过矩阵分解来学习。通过适当的调整,使用例如SVD和LSA等经典的矩阵分解方法,也可以得到类似的结果。
从那时起,大量的工作开始探索词嵌入的不同方面。从Word embeddings in 2017: Trends and future directions这篇博文中,我们就可以了解一些趋势和未来的方向。尽管有了许多发展,word2vec仍然是如今一个流行的选择并在广泛使用。Word2vec的的能力甚至超出了词这个层次:带负采样的skipg -gram可以被用于学习句子的表示,甚至可以在网络和生物序列等方面发挥相似的作用.
一个特别令人兴奋的方向是将不同语言的词嵌入到同一个空间中,来实现zero-shot的迁移学习。以完全无监督的方式(至少对于类似的语言)学习一个好的映射变得越来越有可能,它将推动低资源语言学习(low-resource language)和非监督机器翻译(unsupervised machine translation)的应用的发展。
Mikolov, T., Corrado, G., Chen, K., & Dean, J. (2013). Efficient Estimation of Word Representations in Vector Space. Proceedings of the International Conference on Learning Representations (ICLR 2013).
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems.
Arora, S., Li, Y., Liang, Y., Ma, T., & Risteski, A. (2016). A Latent Variable Model Approach to PMI-based Word Embeddings. TACL, 4, 385–399.
Mimno, D., & Thompson, L. (2017). The strange geometry of skip-gram with negative sampling. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (pp. 2863–2868).
Antoniak, M., & Mimno, D. (2018). Evaluating the Stability of Embedding-based Word Similarities. Transactions of the Association for Computational Linguistics, 6, 107–119.
Wendlandt, L., Kummerfeld, J. K., & Mihalcea, R. (2018). Factors Influencing the Surprising Instability of Word Embeddings. In Proceedings of NAACL-HLT 2018.
Bolukbasi, T., Chang, K.-W., Zou, J., Saligrama, V., & Kalai, A. (2016). Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. In 30th Conference on Neural Information Processing Systems (NIPS 2016).
Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the Conference on Empirical Methods in Natural Language Processing, 1746–1751.
Pennington, J., Socher, R., & Manning, C. D. (2014). Glove: Global Vectors for Word Representation. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, 1532–1543.
Levy, O., & Goldberg, Y. (2014). Neural Word Embedding as Implicit Matrix Factorization. Advances in Neural Information Processing Systems (NIPS), 2177–2185.
Levy, O., Goldberg, Y., & Dagan, I. (2015). Improving Distributional Similarity with Lessons Learned from Word Embeddings. Transactions of the Association for Computational Linguistics, 3, 211–225.
Le, Q. V., & Mikolov, T. (2014). Distributed Representations of Sentences and Documents. International Conference on Machine Learning - ICML 2014, 32, 1188–1196.
Kiros, R., Zhu, Y., Salakhutdinov, R., Zemel, R. S., Torralba, A., Urtasun, R., & Fidler, S. (2015). Skip-Thought Vectors. In Proceedings of NIPS 2015.
Grover, A., & Leskovec, J. (2016, August). node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 855-864). ACM.
Asgari, E., & Mofrad, M. R. (2015). Continuous distributed representation of biological sequences for deep proteomics and genomics. PloS one, 10(11), e0141287.
Conneau, A., Lample, G., Ranzato, M., Denoyer, L., & Jégou, H. (2018). Word Translation Without Parallel Data. In Proceedings of ICLR 2018.
Artetxe, M., Labaka, G., & Agirre, E. (2018). A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings. In Proceedings of ACL 2018.
Søgaard, A., Ruder, S., & Vulić, I. (2018). On the Limitations of Unsupervised Bilingual Dictionary Induction. In Proceedings of ACL 2018.
Lample, G., Denoyer, L., & Ranzato, M. (2018). Unsupervised Machine Translation Using Monolingual Corpora Only. In Proceedings of ICLR 2018.
Artetxe, M., Labaka, G., Agirre, E., & Cho, K. (2018). Unsupervised Neural Machine Translation. In Proceedings of ICLR 2018.
Ruder, S., Vulić, I., & Søgaard, A. (2018). A Survey of Cross-lingual Word Embedding Models. To be published in Journal of Artificial Intelligence Research.
2013 - Neural networks for NLP
2013年和2014年标志着神经网络模型开始在NLP中得到应用。目前应用最广泛的神经网络主要有三种:循环神经网络、卷积神经网络和递归神经网络。
RNN,Recurrent neural networks
有关循环神经网络的介绍,可查阅我之前的一片对于RNN的简单介绍:循环神经网络初识
CNN
随着卷积神经网络(CNN)被广泛用于计算机视觉,它们也开始应用于文本。用于文本的卷积神经网络仅在两个维度上操作,其中滤波器仅需要沿时间维度移动。如下所示是NLP中使用的典型CNN:
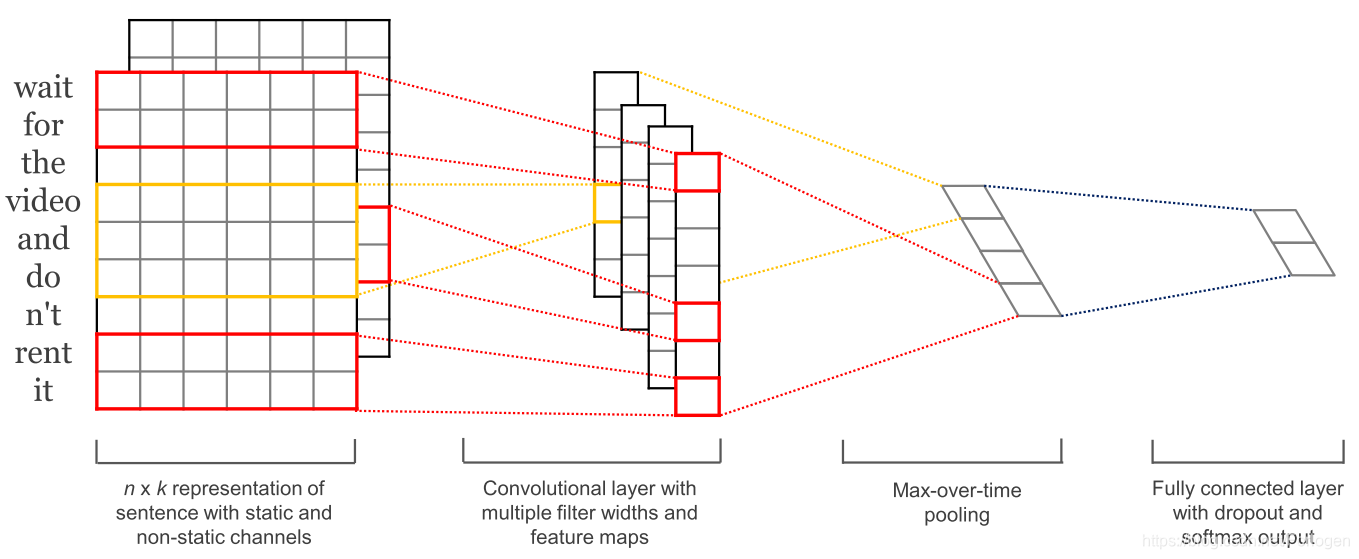
CNN的一个优点是它可并行化,因为每个时刻的状态仅取决于局部的上下文(通过卷积运算)而不是像RNN那样依赖于过去所有时刻的状态。CNN可以使用扩张卷积扩展感受野的范围,从而可以实现捕获更多的上下文的关系。 CNN和LSTM也可以组合和堆叠,并且可以使用卷积来加速LSTM。
RNN,Recursive neural networks
RNN和CNN都将语言视为一个序列,然而从语言学的角度来看,语言在内部是有一定的层次关系的:单词被组成高阶短语和子句,词可以根据一组生产规则递归地组合得到更高阶的短语和子句。如果将句子视为树而不是序列,就催生了递归神经网络,如下所示:
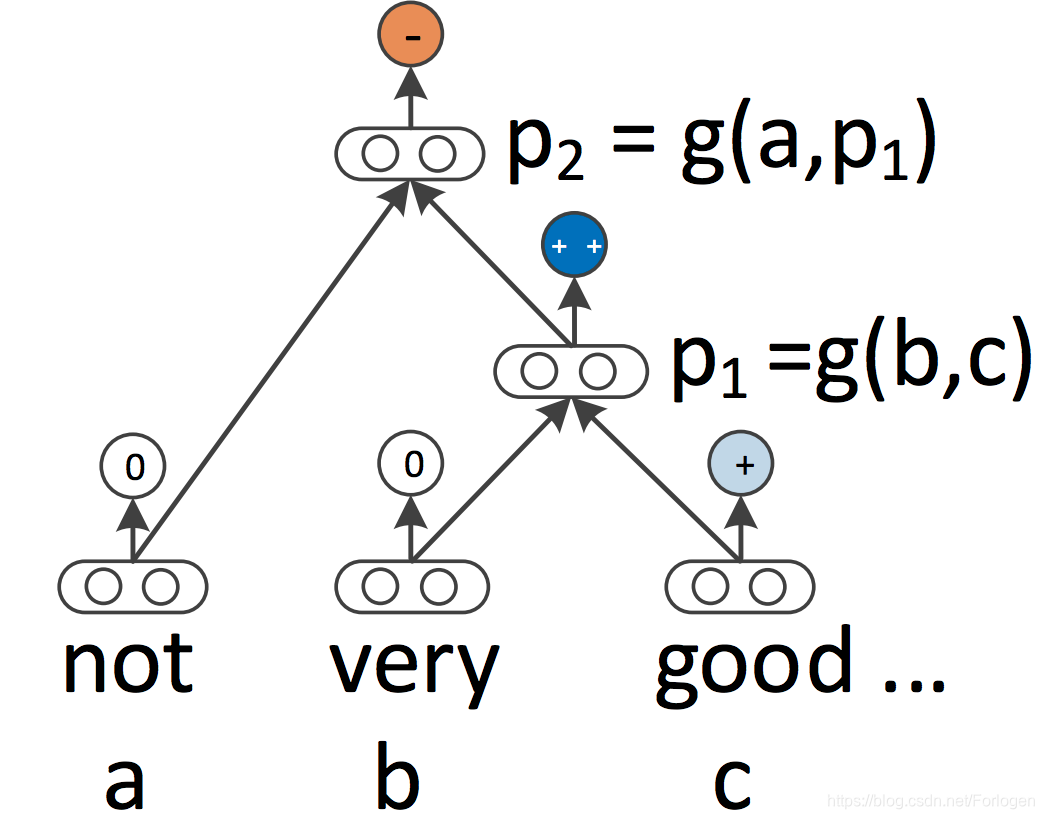
与从左到右或从右到左处理句子的RNN相比,递归神经网络从下到上构建序列的表示。对于树的每个节点来说,可以通过组合子节点表示来的方式计算得到新表示。由于树也可以被视为在RNN上施加不同的处理顺序,因此LSTM自然地扩展到树。
RNN和LSTM不仅仅可以被扩展来使用分层结构,而且不仅可以根据局部的语言学习词嵌入,而且可以基于文法背景来学习词嵌入;语言模型可以基于句法堆栈生成单词; 图卷积神经网络可以在树上运行。
Elman, J. L. (1990). Finding structure in time. Cognitive science, 14(2), 179-211.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
Graves, A., Jaitly, N., & Mohamed, A. R. (2013, December). Hybrid speech recognition with deep bidirectional LSTM. In Automatic Speech Recognition and Understanding (ASRU), 2013 IEEE Workshop on (pp. 273-278). IEEE.
Kalchbrenner, N., Grefenstette, E., & Blunsom, P. (2014). A Convolutional Neural Network for Modelling Sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (pp. 655–665).
Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the Conference on Empirical Methods in Natural Language Processing, 1746–1751.
Kalchbrenner, N., Espeholt, L., Simonyan, K., Oord, A. van den, Graves, A., & Kavukcuoglu, K. (2016). Neural Machine Translation in Linear Time.
Wang, J., Yu, L., Lai, K. R., & Zhang, X. (2016). Dimensional Sentiment Analysis Using a Regional CNN-LSTM Model. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016), 225–230.
Bradbury, J., Merity, S., Xiong, C., & Socher, R. (2017). Quasi-Recurrent Neural Networks. In ICLR 2017.
Socher, R., Perelygin, A., & Wu, J. (2013). Recursive deep models for semantic compositionality over a sentiment treebank. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 1631–1642.
Tai, K. S., Socher, R., & Manning, C. D. (2015). Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks. Acl-2015, 1556–1566.
Levy, O., & Goldberg, Y. (2014). Dependency-Based Word Embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Short Papers) (pp. 302–308).
Dyer, C., Kuncoro, A., Ballesteros, M., & Smith, N. A. (2016). Recurrent Neural Network Grammars. In NAACL.
Bastings, J., Titov, I., Aziz, W., Marcheggiani, D., & Sima’an, K. (2017). Graph Convolutional Encoders for Syntax-aware Neural Machine Translation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing.
2014 - Sequence-to-sequence models
2014年,Sutskever等人提出Seq2Seq的学习方式,它是一个通过神经网络将一个序列映射到另一个序列的通用框架。在该框架中,Encoder逐个符号地处理句子并将其压缩成向量表示; 然后,Decoder基于Encoder的状态逐个符号地预测输出符号,在每一步都使用先前预测的符号作为输入,如下所示:
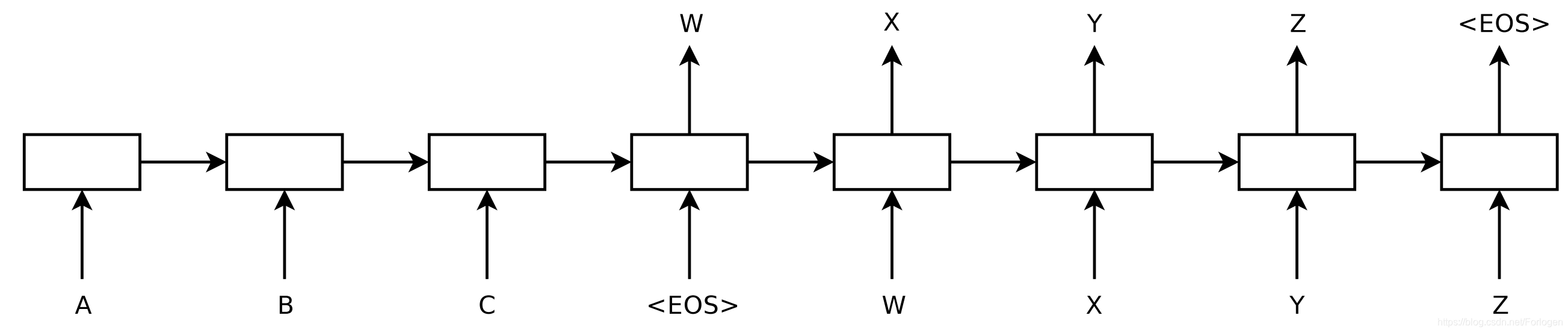
机器翻译从这种方法中受益良多。2016年,谷歌宣布开始用NMT模型替换其单一的短语的MT模型。Jeff Dean表示,这意味着用一个500行的神经网络模型可以替换50万行基于短语的MT代码。
由于其灵活性,该框架现在是NLP中生成任务的首选框架,编码器和解码器可以采用不同的网络模型。更为重要的是,解码器不仅可以以序列为条件,而且可以以任意表示为条件。例如,它支持基于图像生成标题,如下所示;基于表格的文本和基于源代码更改的描述,以及许多其他的应用。
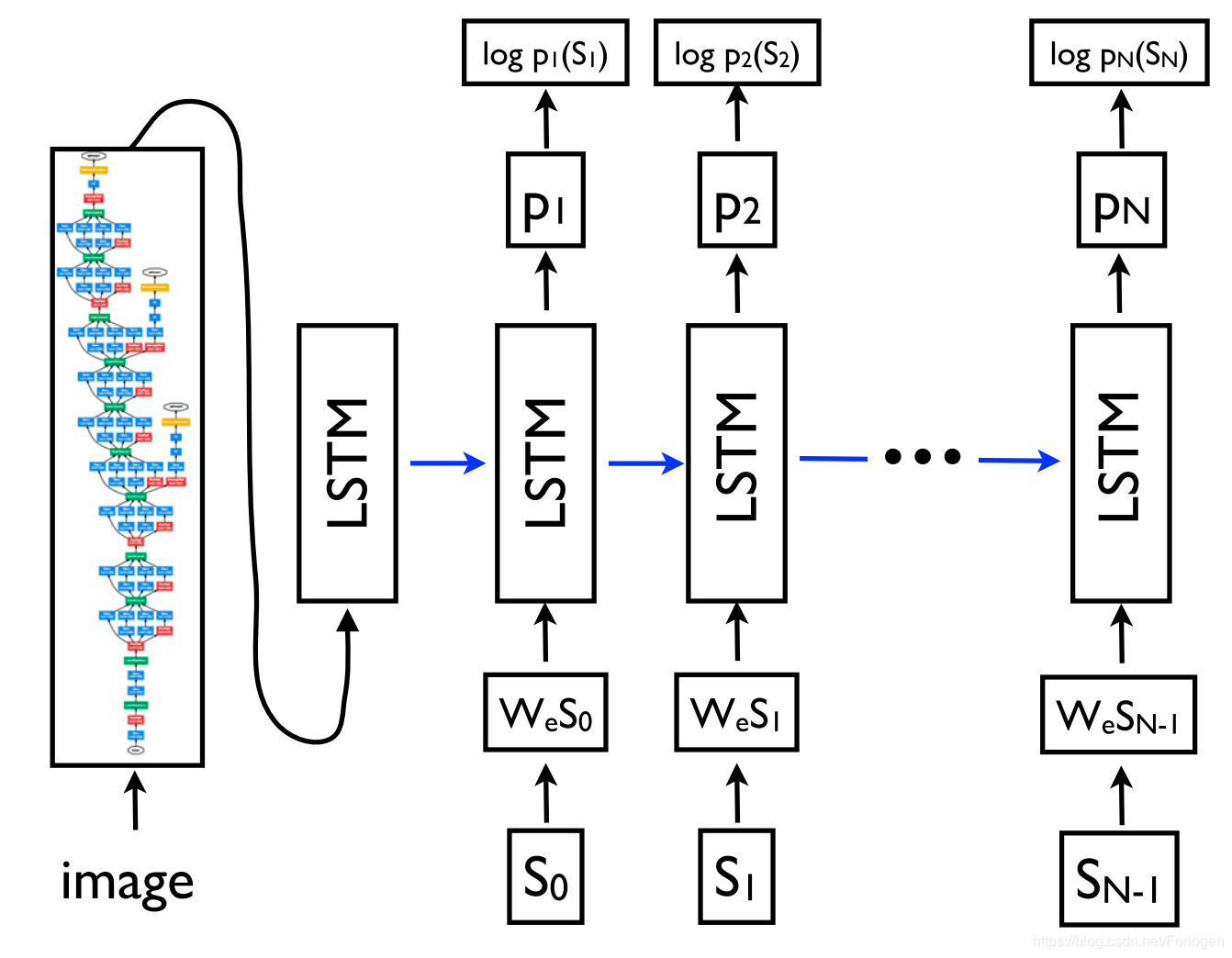
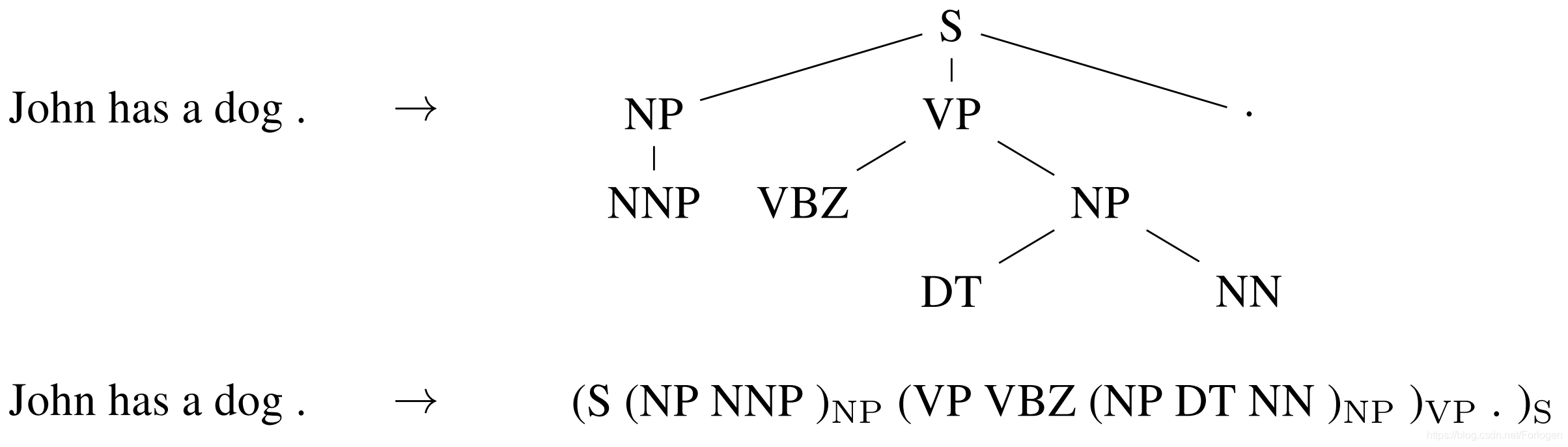
Seq2Seq甚至可以应用于NLP中常见的结构化预测(输出具有特定结构)任务。简单起见,输出可被看作线性的形式,如下所示。神经网络已经被证明了具有直接学习生成这种线性化输出的能力,只要提供足够的训练数据用于句法分析和命名实体识别等。
用于Seq2Seq和解码器的编码器通常基于RNN,但是也可以使用其他类型的网络模型。新的体系结构主要来自于MT中的工作,它可被看作是Seq2Seq体系结构的”培养皿“。最新的的模型有deep LSTMs 、convolutional encoders 、Transformer 以及LSTM和Transformer 的组合。
Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems.
Wu, Y., Schuster, M., Chen, Z., Le, Q. V, Norouzi, M., Macherey, W., … Dean, J. (2016). Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. (2015). Show and tell: A neural image caption generator. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3156-3164).
Lebret, R., Grangier, D., & Auli, M. (2016). Generating Text from Structured Data with Application to the Biography Domain. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing.
Loyola, P., Marrese-Taylor, E., & Matsuo, Y. (2017). A Neural Architecture for Generating Natural Language Descriptions from Source Code Changes. In ACL 2017.
Vinyals, O., Kaiser, L., Koo, T., Petrov, S., Sutskever, I., & Hinton, G. (2015). Grammar as a Foreign Language. Advances in Neural Information Processing Systems.
Gillick, D., Brunk, C., Vinyals, O., & Subramanya, A. (2016). Multilingual Language Processing From Bytes. In NAACL (pp. 1296–1306).
Wu, Y., Schuster, M., Chen, Z., Le, Q. V, Norouzi, M., Macherey, W., … Dean, J. (2016). Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation.
Kalchbrenner, N., Espeholt, L., Simonyan, K., Oord, A. van den, Graves, A., & Kavukcuoglu, K. (2016). Neural Machine Translation in Linear Time.
Gehring, J., Auli, M., Grangier, D., Yarats, D., & Dauphin, Y. N. (2017). Convolutional Sequence to Sequence Learning. ArXiv Preprint ArXiv:1705.03122.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … Polosukhin, I. (2017). Attention Is All You Need. In Advances in Neural Information Processing Systems.
Chen, M. X., Foster, G., & Parmar, N. (2018). The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation. In Proceedings of ACL 2018
2015 - Attention
注意力是神经机器翻译的关键创新之一,也是使NMT模型优于传统基于短语的MT系统的关键思想。Seq2Seq学习的主要瓶颈是它需要将源序列的整个内容压缩成固定大小的向量。注意力通过允许解码器查看源序列隐藏状态来缓解这种情况,然后计算这些状态加权平均值提供给解码器作为额外的输入,如下所示:
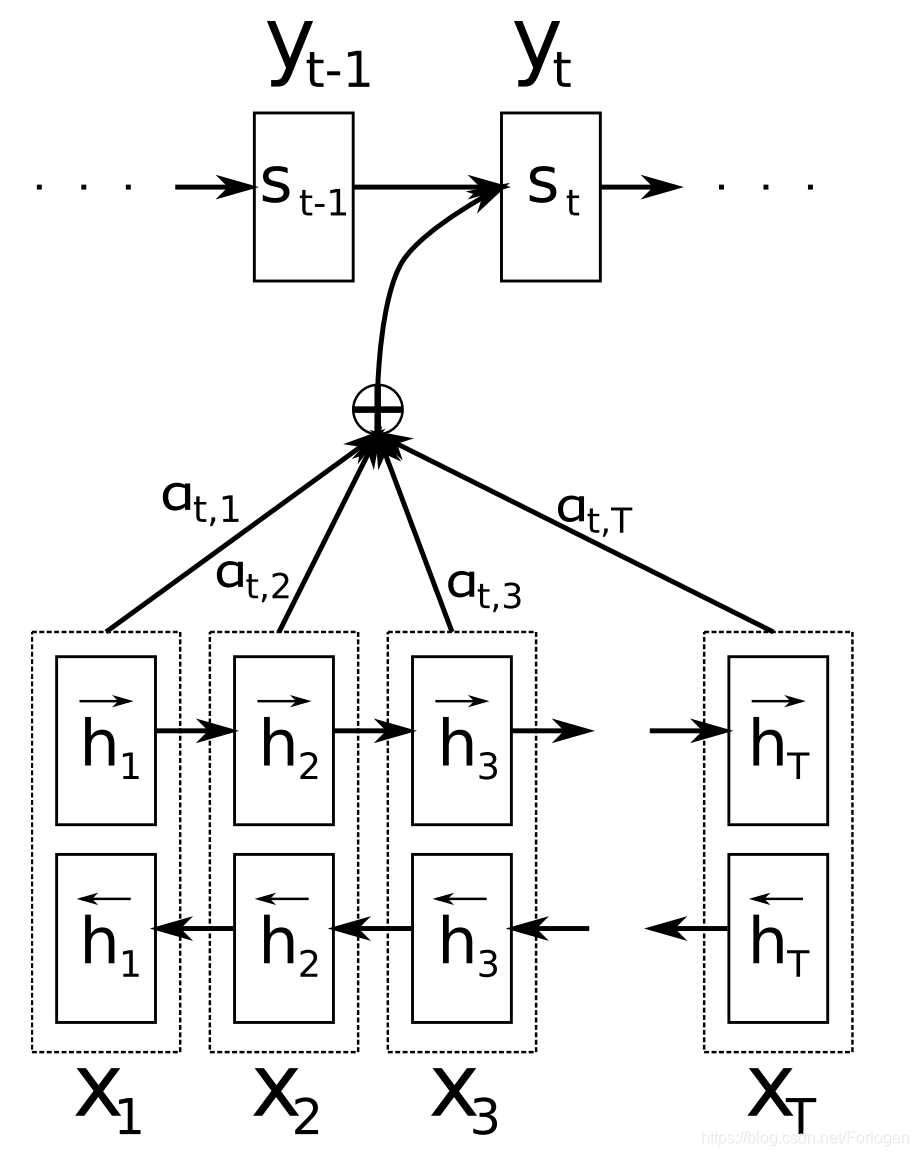
注意力有不同的形式,在多种任务中广泛适用,并且可能对任何需要根据输入的某些部分做出决策的任务有用。它已被应用于句法分析、阅读理解、one-shot学习等。输入不需要是序列,但可以包括其他表示,例如如下所示的图像标题(image caption)。注意力通过基于注意力权重检查输入的哪些部分与特定输出相关,从而提供了一个了解模型内部工作机制的方式。

注意力也不仅限于查看输入序列,Self-Attention可用于查看句子或文档中的周围单词,以获得更具上下文敏感性的单词表示。Multi-head self-attention是Transformer架构的核心,Transformer是目前最先进的NMT模型。
关于注意力机制的介绍可查阅我之前的两篇博文的相关部分:
Attention?Attention!
Transformer
Bahdanau, D., Cho, K., & Bengio, Y. (2015). Neural Machine Translation by Jointly Learning to Align and Translate. In ICLR 2015.
Luong, M.-T., Pham, H., & Manning, C. D. (2015). Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of EMNLP 2015.
Vinyals, O., Kaiser, L., Koo, T., Petrov, S., Sutskever, I., & Hinton, G. (2015). Grammar as a Foreign Language. Advances in Neural Information Processing Systems.
Hermann, K. M., Kočiský, T., Grefenstette, E., Espeholt, L., Kay, W., Suleyman, M., & Blunsom, P. (2015). Teaching Machines to Read and Comprehend. Advances in Neural Information Processing Systems.
Vinyals, O., Blundell, C., Lillicrap, T., Kavukcuoglu, K., & Wierstra, D. (2016). Matching Networks for One Shot Learning. In Advances in Neural Information Processing Systems 29 (NIPS 2016).
Xu, K., Courville, A., Zemel, R. S., & Bengio, Y. (2015). Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of ICML 2015.
2015 - Memory-based networks
注意力可以看作是模糊记忆的一种形式,其中记忆由模型的过去隐藏状态组成,模型选择从记忆单元中中检索所需的内容。许多具有更明确记忆的模型已经被提出,它们有不同的变体,例如神经网络图灵机、记忆网络、和端到端的记忆网络、动态记忆网络、可微神经计算机、递归实体网络等。
内存的访问通常基于与当前状态的相似性,类似于注意力,通常可以写入和读取,模型的不同之处在于它们如何实现和利用内存。例如,端到端记忆网络(End-to-end Memory Networks)对输入进行多次处理,并更新内存以支持多个推理步骤;神经图灵机也有一个基于位置的寻址,这使它们可以学习类似排序等简单的计算机程序。基于记忆的模型通常应用在需较长时间内保持信息应该是有用的任务中,如语言建模和阅读理解。记忆是一个通用性非常强的概念:知识库或表可以作为内存使用,同时也可以根据整个输入或记忆的特定部分填充记忆。
Graves, A., Wayne, G., & Danihelka, I. (2014). Neural turing machines.
Weston, J., Chopra, S., & Bordes, A. (2015). Memory Networks. In Proceedings of ICLR 2015.
Sukhbaatar, S., Szlam, A., Weston, J., & Fergus, R. (2015). End-To-End Memory Networks. In Proceedings of NIPS 2015.
Kumar, A., Irsoy, O., Ondruska, P., Iyyer, M., Bradbury, J., Gulrajani, I., … & Socher, R. (2016, June). Ask me anything: Dynamic memory networks for natural language processing. In International Conference on Machine Learning (pp. 1378-1387).
Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwińska, A., … Hassabis, D. (2016). Hybrid computing using a neural network with dynamic external memory. Nature.
Henaff, M., Weston, J., Szlam, A., Bordes, A., & LeCun, Y. (2017). Tracking the World State with Recurrent Entity Networks. In Proceedings of ICLR 2017.
\
2018 - Pretrained language models
预训练的词嵌入与上下文无关,而且仅用于初始化模型中的第一层。最近几个月,一系列监督任务被用于预训练神经网络。相比之下,语言模型只需要未标记的文本;,因此训练可以扩展到数十亿个tokens,新领域和新语言。 2015年就首次提出了预训练语言模型,但直到最近,它们才被证明对各种各样的任务都有用。可以使用语言模型嵌入做为目标模型的特征,也可以使用目标任务数据进行微调得到更好语言模型。预训练模型已经在很多不同的任务上取得了state-of-the-art的效果:
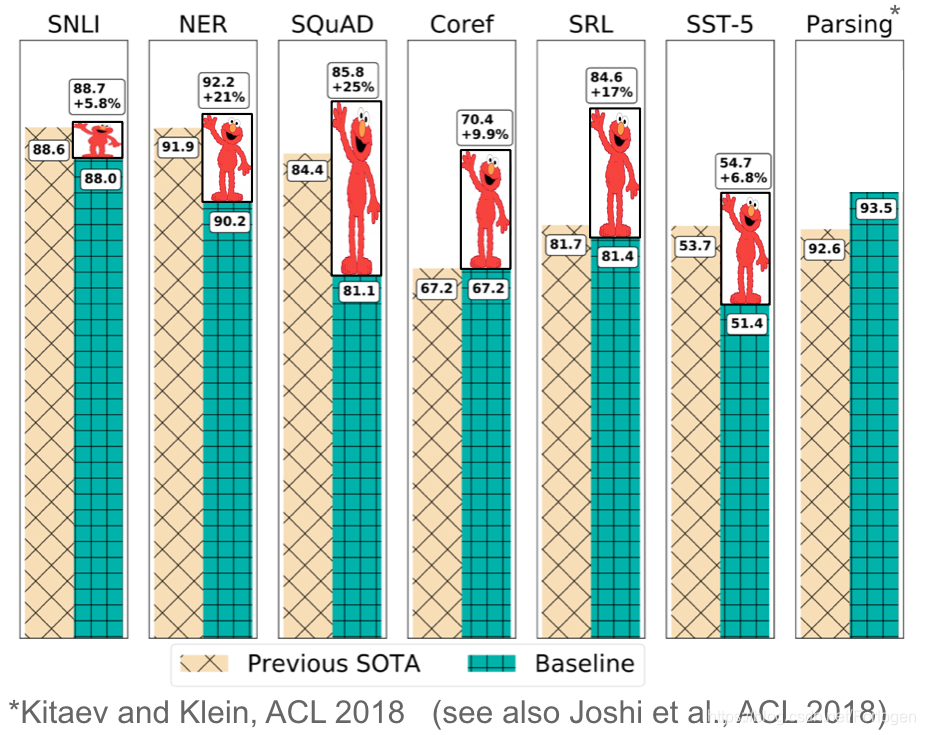
预训练模型已被证明可以用更少的数据进行学习。由于语言模型只需要未标记的数据,因此对于标记数据稀缺的低资源语言,它们尤其有用。有关预训练语言模型潜力的更多信息,请查阅 NLP’s ImageNet moment has arrived。
Conneau, A., Kiela, D., Schwenk, H., Barrault, L., & Bordes, A. (2017). Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing.
McCann, B., Bradbury, J., Xiong, C., & Socher, R. (2017). Learned in Translation: Contextualized Word Vectors. In Advances in Neural Information Processing Systems.
Subramanian, S., Trischler, A., Bengio, Y., & Pal, C. J. (2018). Learning General Purpose Distributed Sentence Representations via Large Scale Multi-task Learning. In Proceedings of ICLR 2018.
Dai, A. M., & Le, Q. V. (2015). Semi-supervised Sequence Learning. Advances in Neural Information Processing Systems (NIPS ’15).
Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. In Proceedings of NAACL-HLT 2018.
Ramachandran, P., Liu, P. J., & Le, Q. V. (2017). Unsupervised Pretraining for Sequence to Sequence Learning. In Proceedings of EMNLP 2017.
Howard, J., & Ruder, S. (2018). Universal Language Model Fine-tuning for Text Classification. In Proceedings of ACL 2018.
Other milestones
其他一些发展没有上述发展那么普遍,但仍然具有广泛的影响。
-
基于字符的表示(Character-based representations):在字符上使用CNN或LSTM来获得基于字符的词表示是相当普遍的,特别是对于形态学丰富的语言和形态信息很重要或具有许多未知单词的任务。据我所知,基于字符的表示首先用于序列标记。基于字符的表示减少了必须以增加计算成本处理固定词汇表的需要,并且能够实现诸如完全基于字符的NMT之类的应用
-
对抗学习(Adversarial learning):对抗性方法在机器学习领域掀起了一场风暴,在NLP中也以不同的形式得到了应用。对抗性示例越来越广泛地被广泛使用,不仅作为探测模型和作为一种理解其失败的工具,而且还可以使它们更加鲁棒。域对抗性损失是可以同样使模型更加鲁棒的有用的正规化形式。生成对抗网络(GAN)对于自然语言生成来说还不是太有效,但是例如在分布匹配方面还是有用的。
-
强化学习(Reinforcement learning):强化学习已经被证明对于具有时间依赖性的任务是有用的,例如在训练期间选择数据和建模对话。RL对于直接优化诸如ROUGE或BLEU之类的非可微结束度量而不是优化替代损失和机器翻译也是有效的。反向强化学习在犒赏太复杂而无法指定的环境中可能是有用的,例如视觉叙事。
Ling, W., Luis, T., Marujo, L., Astudillo, R. F., Amir, S., Dyer, C., … Trancoso, I. (2015). Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation. In Proceedings of EMNLP 2015 (pp. 1520–1530).
Ballesteros, M., Dyer, C., & Smith, N. A. (2015). Improved Transition-Based Parsing by Modeling Characters instead of Words with LSTMs. In Proceedings of EMNLP 2015.
Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K., & Dyer, C. (2016). Neural Architectures for Named Entity Recognition. In NAACL-HLT 2016.
Plank, B., Søgaard, A., & Goldberg, Y. (2016). Multilingual Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Models and Auxiliary Loss. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics.
Kim, Y., Jernite, Y., Sontag, D., & Rush, A. M. (2016). Character-Aware Neural Language Models. In Proceedings of AAAI 2016
Ling, W., Trancoso, I., Dyer, C., & Black, A. (2016). Character-based Neural Machine Translation. In ICLR.
Lee, J., Cho, K., & Bengio, Y. (2017). Fully Character-Level Neural Machine Translation without Explicit Segmentation. In Transactions of the Association for Computational Linguistics.
Jia, R., & Liang, P. (2017). Adversarial Examples for Evaluating Reading Comprehension Systems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing.
Miyato, T., Dai, A. M., & Goodfellow, I. (2017). Adversarial Training Methods for Semi-supervised Text Classification. In Proceedings of ICLR 2017.
Yasunaga, M., Kasai, J., & Radev, D. (2018). Robust Multilingual Part-of-Speech Tagging via Adversarial Training. In Proceedings of NAACL 2018.
Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Laviolette, F., … Lempitsky, V. (2016). Domain-Adversarial Training of Neural Networks. Journal of Machine Learning Research, 17.
Kim, Y., Stratos, K., & Kim, D. (2017). Adversarial Adaptation of Synthetic or Stale Data. In Proceedings of ACL (pp. 1297–1307).
Semeniuta, S., Severyn, A., & Gelly, S. (2018). On Accurate Evaluation of GANs for Language Generation.
Conneau, A., Lample, G., Ranzato, M., Denoyer, L., & Jégou, H. (2018). Word Translation Without Parallel Data. In Proceedings of ICLR 2018.
Fang, M., Li, Y., & Cohn, T. (2017). Learning how to Active Learn: A Deep Reinforcement Learning Approach. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing.
Wu, J., Li, L., & Wang, W. Y. (2018). Reinforced Co-Training. In Proceedings of NAACL-HLT 2018.
Liu, B., Tür, G., Hakkani-Tür, D., Shah, P., & Heck, L. (2018). Dialogue Learning with Human Teaching and Feedback in End-to-End Trainable Task-Oriented Dialogue Systems. In Proceedings of NAACL-HLT 2018.
Paulus, R., Xiong, C., & Socher, R. (2018). A deep reinforced model for abstractive summarization. In Proceedings of ICLR 2018.
Celikyilmaz, A., Bosselut, A., He, X., & Choi, Y. (2018). Deep communicating agents for abstractive summarization. In Proceedings of NAACL-HLT 2018.
Ranzato, M. A., Chopra, S., Auli, M., & Zaremba, W. (2016). Sequence level training with recurrent neural networks. In Proceedings of ICLR 2016.
Wang, X., Chen, W., Wang, Y.-F., & Wang, W. Y. (2018). No Metrics Are Perfect: Adversarial Reward Learning for Visual Storytelling. In Proceedings of ACL 2018.
Non-neural milestones
这部分内容不涉及神经网络,就偷下懒了,有兴趣的可查阅原文的相关部分。


















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}