 循环神经网络(RNN)及LSTM详解
循环神经网络(RNN)及LSTM详解





 本文介绍了循环神经网络(RNN)。传统前馈神经网络无法持续思考,存在诸多不足,而RNN具有短期记忆能力,能处理任意长度序列。但RNN在时间维度深时会出现梯度问题,LSTM作为其变体可有效解决。此外,还列举了RNN的多种应用场景。
本文介绍了循环神经网络(RNN)。传统前馈神经网络无法持续思考,存在诸多不足,而RNN具有短期记忆能力,能处理任意长度序列。但RNN在时间维度深时会出现梯度问题,LSTM作为其变体可有效解决。此外,还列举了RNN的多种应用场景。
如何理解RNN?
当我们在面对一个新的问题时,我们总是会从头脑中搜索类似的问题的解决方案,看有什么可以借鉴的地方,而不是蒙头从零开始思考。同样的在阅读一篇文章时,如果想理解某一句话,我们可能需要看前面的几个词和后面的几个词,如果想要理解一段话,还可能需要结合上下文。人类这样的思维过程显示了我们的思考是一个持续的过程,某时刻的想法要依赖于前面所学得的东西。而深度学习中传统的前馈神经网络是做不到持续思考的,它具有如下的不足之处:
- 节点之间的而连接存在于前一层和后一层之间,同层的节点之间是没有连接的,也就是说同层节点间是无循环的
- 输入和输出的维数是固定的,不能任意的改变
- 无法处理边长的序列数据,例如语句、语音信号等
- 它基于假设每次输入都是独立的,即每一次网络的输出只依赖于当前的输入,与它之前、之后网络的输入都无关
例如下图是一个包含输入层、一个隐藏层和输出层的简单的前馈神经网络
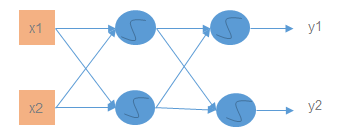
那么如何理解前馈神经网络无法做到持续思考的不足呢?下面我们用一个例子来看一下,如下图所示,我们有两个句子,唯一的不同之处在于Beijing前面的单词是不同的,这就导致了两句话表达的意思就完全是不同的。当我们将两个句子单独的输入到前馈神经网络中,我们希望网络可以做的的是:根据对于句子的理解,将第一个句子中的Beijing标注为destination,将第二个句子中的Beijing标注为place of departure

但是对于传统的前馈神经网络,这样的要求似乎有点强人所难了,因为它没有记忆呀!如果我们希望相同的词在不同的句子中可以被正确的区分所表达的不同的含义,前馈神经网络就无法满足要求了,这时就需要使用循环神经网络。
循环神经网络(Recurrent Neural Network,RNN)是一种具有短期记忆能力的神经网络,神经元不仅可以接受其他神经元的信息,也可以接收自身的信息,形成了一种具有环路的结构。它相比于前面的前馈神经网络具有如下的优势:
- 通过使用带自反馈的神经元,能够处理任意长度的序列
- 更加符合生物神经网络的结构
一个简单的的前向循环神经网络如下所示,它在基本的结构上多了一个记忆单元(memory cell),它可以存储当前的输出,将其作为下一个时刻网络的输入。这样的话,当我们分析当前的输入时,就可以结合前面输入的信息进行分析,解决了输入之间的依赖问题。
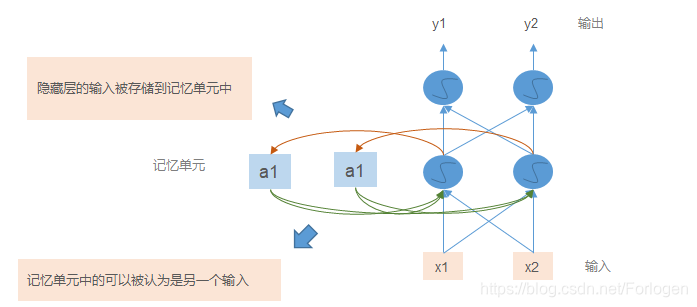
下面再通过一个简单的小栗子看一下上面所说的是什么意思,假设网络只有简单的三层,而且激活函数都是线性的,记忆单元中存储的值初始化为0,节点的输出自然也都是0,如下所示
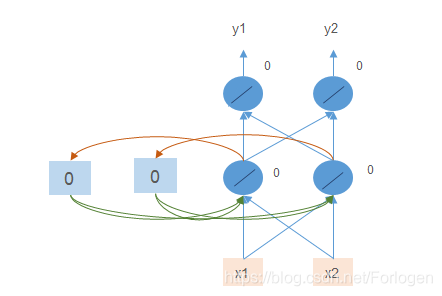
那么输入 [ 1 , 1 ] [1,1] [1,1],各节点的输出如下所示,输出的结果为 [ 4 , 4 ] [4,4] [4,4]
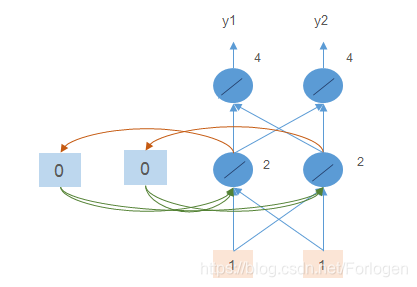
那么再输入 [ 1 , 1 ] [1,1] [1,1],此时由于前面的输入,记忆单元中的值更新为2、2,所以隐藏层节点的输出就变成了 1 + 1 + 2 + 2 = 6 1+1+2+2=6 1+1+2+2=6,最后输出 [ 12 , 12 ] [12,12] [12,12]
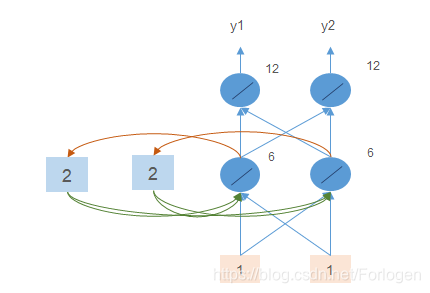
将多个简单的循环神经网络组合到一起,按照时间展开,就得到了一个简单的单向循环神经网络
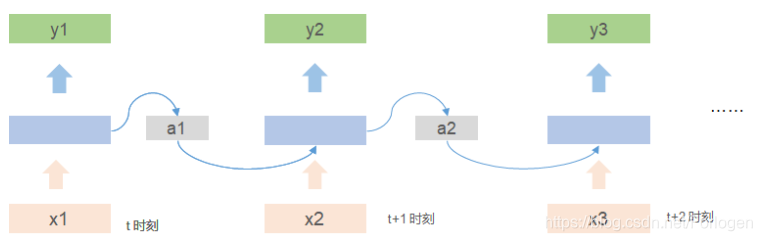
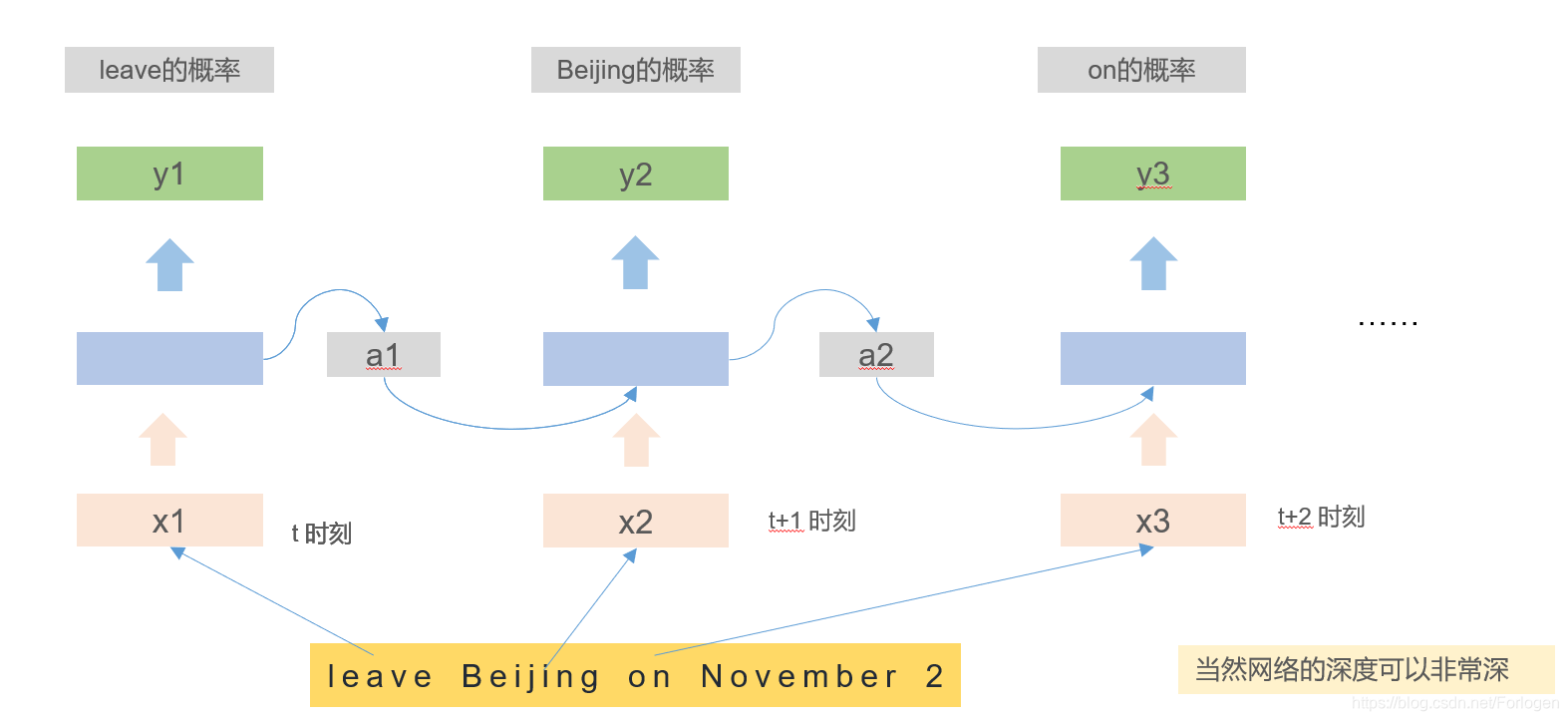
如果将"leave Beijing on November 2"输入到网络中,我们就可得到在Slot Filling问题中每个单词输入每个slot的概率值
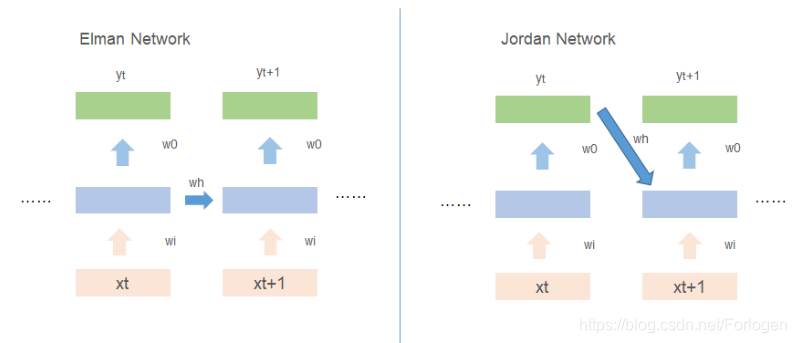
在单向的循环神经网络中,常用的有Elman Network、Jordan Network两种,不同之处在于对于记忆单元的更新,如下所示
在处理同一序列数据时,如果从前到后和从后到前同时进行,就得到了双向循环神经网络
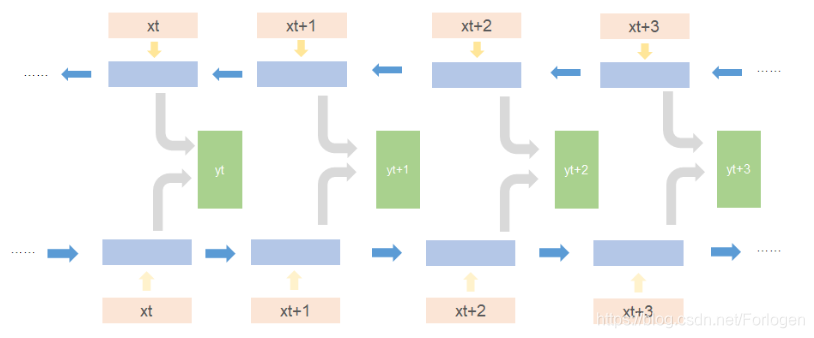
理论上,使用上面所提到的循环神经网络就可以建立长距离的依赖关系,但是有一个问题在于,当循环神经网络在时间维度上非常深时,就会出现梯度消失、梯度爆炸的问题。针对于梯度爆炸的问题,我们可以使用权重衰减、梯度截断等方法进行缓解,针对于梯度消失的问题,我们就可以使用LSTM。
长短期记忆(Long Short-Term Memory,LSTM)网络[Gers et al., 2000,Hochreiter and Schmidhuber, 1997] 是循环神经网络的一个变体,可以有效地解决简单循环神经网络的梯度爆炸或消失问题。LSTM中引入了门机制来控制信息传递的路径,引入了输入门(input gate)、输出门(output gate)和遗忘门(forget gate)三个门。
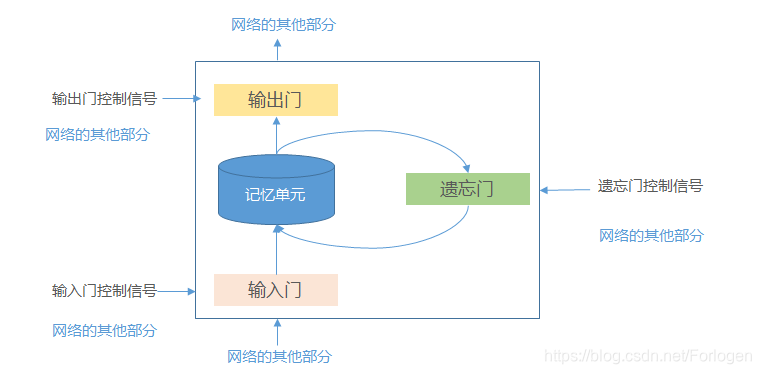
在基本的逻辑电路中,逻辑门只有两个取值 0 0 0和 1 1 1:0表示关闭,任何信息都不能通过;1表示开放,允许所有的信息通过。LSTM中的门类似于逻辑门,但它的取值在(0,1)之间,表示以一定的比例允许信息的通过。三个门的作用为:
- 输入门:控制当前时刻的候选状态有多少信息需要保存
- 输出门:控制当前时刻的内部状态有多少信息需要输出给外部状态
- 遗忘门:控制上一时刻的内部状态需要遗忘多少信息
LSTM的简单结构如下所示
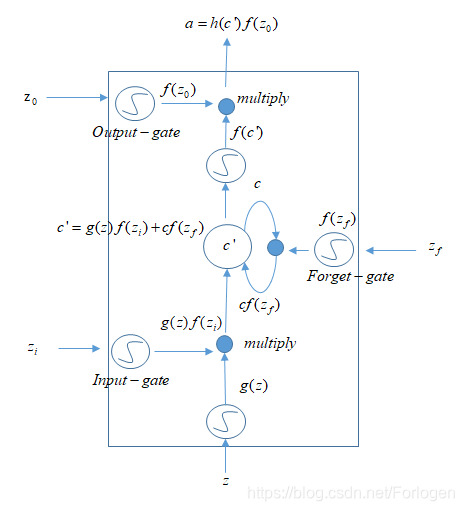
其中激活函数常使用的是Sigmoid函数,因为它可以将值挤压到(0,1)之间,与门机制的设定是一致的;而且由网络自己来控制门的开和闭。猛的一看,怎么这么复杂?!?下面我们就拿李宏毅老师所讲的“人肉LSTM”的例子来看一下它是怎么运行的。
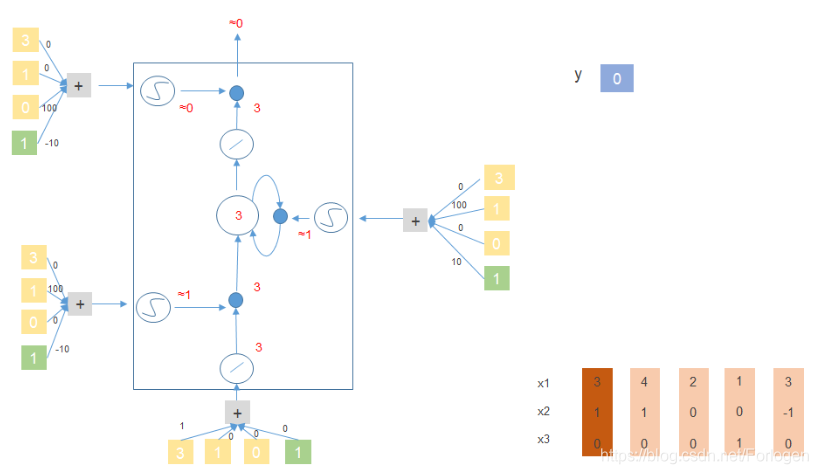
假设 [ x 1 , x 2 , x 3 ] 、 y 、 M e m o r y c e l l [x_{1},x_{2},x_{3}]、y、Memory\ cell [x1,x2,x3]、y、Memory cell如下所示,规定:当 x 2 = 1 x_{2}=1 x2=1时,将 x 1 x_{1} x1中的值添加到记忆单元中;当 x 2 = − 1 x_{2}=-1 x2=−1时,重置记忆单元;当 x 3 = 1 x_{3}=1 x3=1时,输出记忆单元中的值
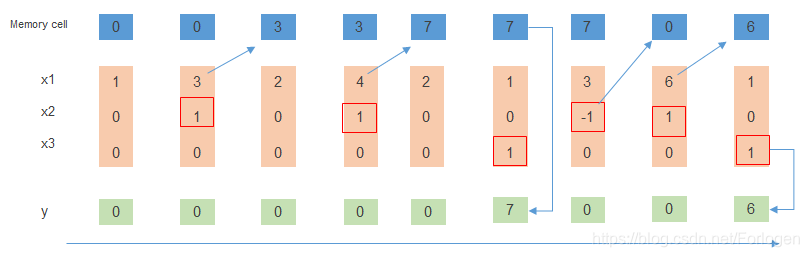
- [ 1 , 0 , 0 ] [1,0,0] [1,0,0]: x 2 = 0 , x 3 = 0 x_{2}=0,x_{3}=0 x2=0,x3=0,输出和记忆单元中的值都是0
- [ 3 , 1 , 0 ] [3,1,0] [3,1,0]: x 2 = 1 , x 3 = 0 x_{2}=1,x_{3}=0 x2=1,x3=0,需要将 x 1 x_{1} x1的值添加到记忆单元中,在下一时刻,记忆单元中的值就变成了3
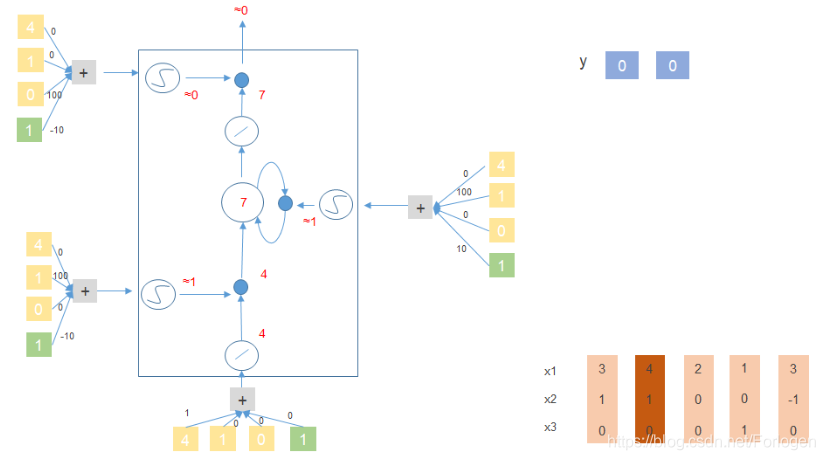
- [ 2 , 0 , 0 ] [2,0,0] [2,0,0]: x 2 = 0 , x 3 = 0 x_{2}=0,x_{3}=0 x2=0,x3=0,输出和记忆单元中的值不做改变
- [ 4 , 1 , 0 ] [4,1,0] [4,1,0]: x 2 = 1 x_{2}=1 x2=1, 需要将 x 1 x_{1} x1中的值4添加到记忆单元中,在下一时刻,记忆单元中的值更新为 4 + 3 = 7 4+3=7 4+3=7
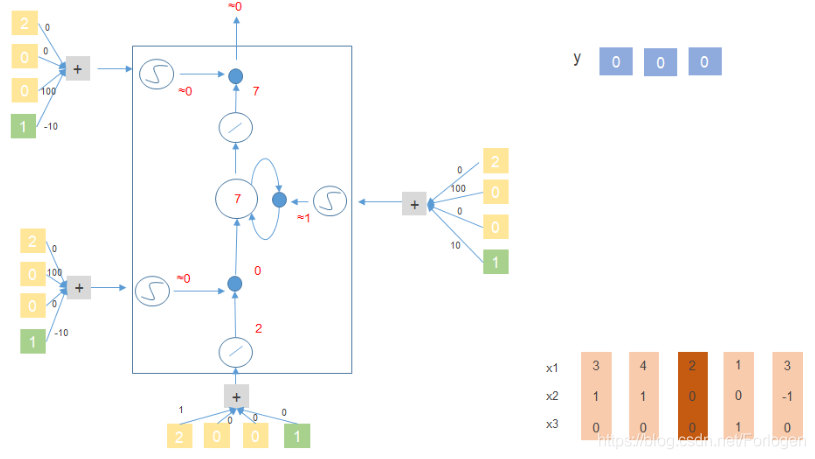
- [ 2 , 0 , 0 ] [2,0, 0 ] [2,0,0]: x 2 = 0 , x 3 = 0 x_{2}=0,x_{3}=0 x2=0,x3=0,输出和记忆单元中的值不做改变
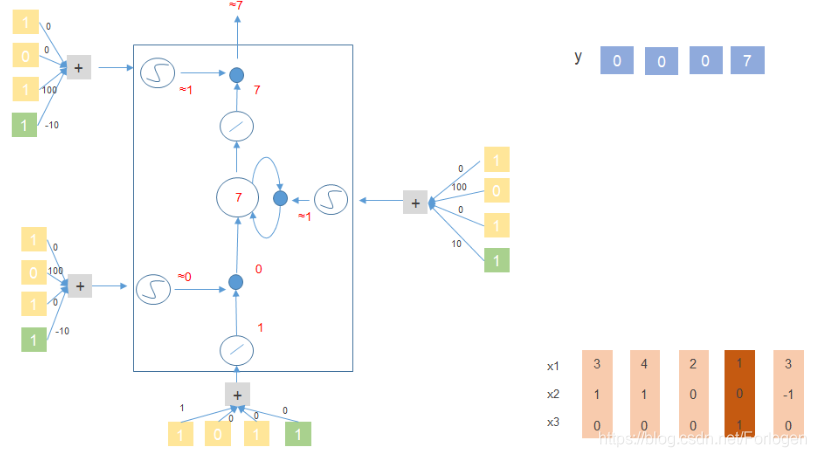
- [ 1 , 0 , 1 ] [1,0,1] [1,0,1]: x 3 = 1 x_{3}=1 x3=1 ,输出记忆单元中的值7
- ……
下面以 [ 3 , 1 , 0 ] 、 [ 4 , 1 , 0 ] 、 [ 2 , 0 , 0 ] 、 [ 1 , 0 , 1 ] 、 [ 3 , − 1 , 0 ] [3,1,0]、[4,1,0]、[2,0,0]、[1,0,1]、[3,-1,0] [3,1,0]、[4,1,0]、[2,0,0]、[1,0,1]、[3,−1,0]来看一下它在上面提到的简单的LSTM结构中是怎么做的?
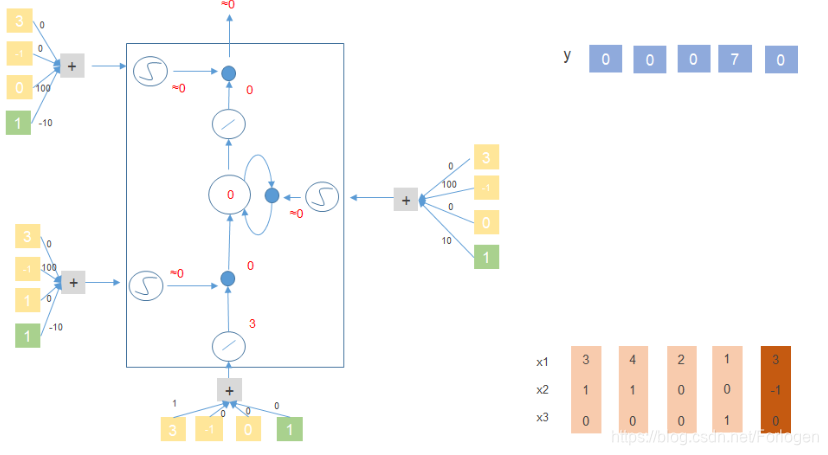
关于这个例子的PPT我重新做了一份,方便逐步理解,需要的可以到 https://download.youkuaiyun.com/download/forlogen/11160568 下载(P.S. 系统自动设置了下载要5个积分…如果有人知道怎么设置为不需积分,望告知一下)
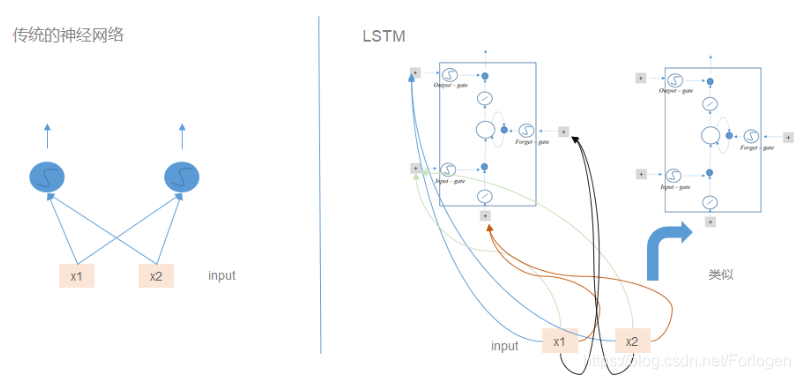
相比于传统的前馈神经网络,每一个输入都需要作为LSTM所需的4个输入项,所以参数量就增加为之前的4倍
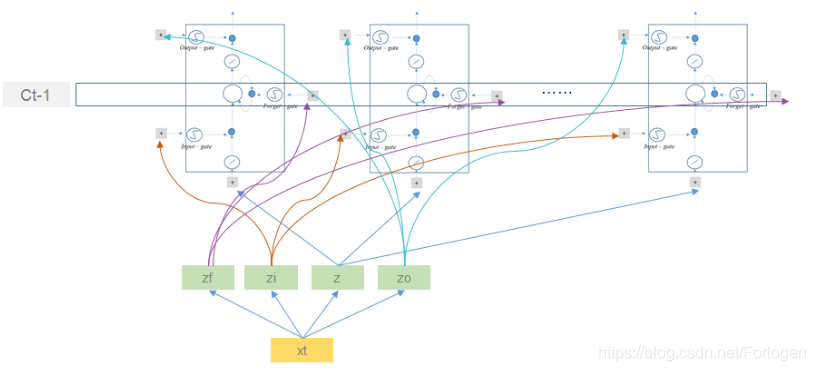
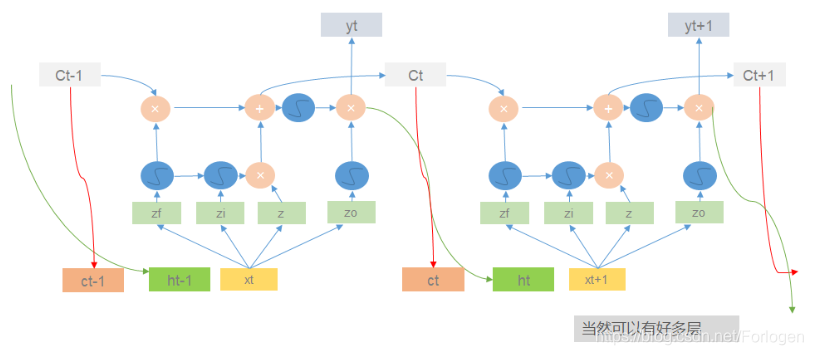
但是对于输入 x 1 x_{1} x1(对于其他的输入同理,这里以 x 1 x_{1} x1为例说明)来说,它并不直接作为LSTM的输入,而是先经过转换操作,得到四个向量 z f 、 z i 、 z 、 z o z_{f}、z_{i}、z、z_{o} zf、zi、z、zo,它们的维度正好了记忆单元的个数相同,然后再分别作为不同时刻的对应输入,如下所示
在每一个结构中的运算过程如下所示
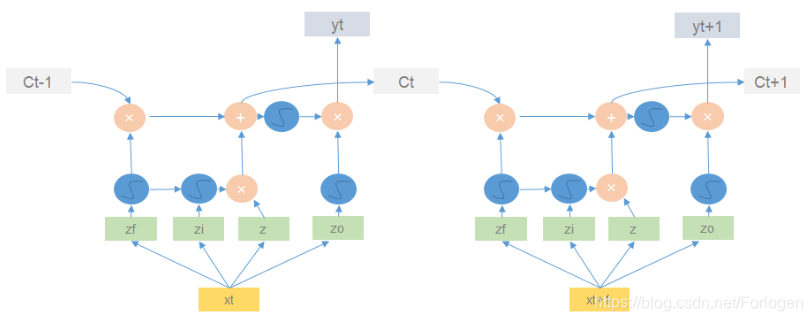
其实输入还不光有 x t x_{t} xt,还有上一时刻的记忆单元中的值 c t − 1 c_{t-1} ct−1、上一时刻输出值 h t h_{t} ht,完整的LSTM结构如下所示
应用场景
- 语音识别:输入的语音数据,生成相应的语音文本信息
- 机器翻译:不同语言之间的相互转换
- 音乐生成:使用RNN网络生成音乐,一般会用到RNN中的LSTM算法
- 文本生成:利用RNN亦可以生成某种风格的文字
- 情感分类:输入文本或者语音的评论数据,输出相应的打分数据
- DNA序列分析:输入的DNA序列,输出蛋白质表达的子序列
- 视频行为识别:识别输入的视频帧序列中的人物行为
- 实体名字识别:从文本中识别实体的名字
- ……

















 575
575





 到【灌水乐园】发言
到【灌水乐园】发言







