




ICLR 2019 Coarse-Grain Fine-Grain Coattention Network for Multi-Evidence Question Answering
背景
本篇文章所关注的问题是机器阅读理解(Machine Reading Comprehension),即根据查询在给定的文档中寻找相应答案的部分,具体来说是多事实QA(multi-evidence QA)问题。现有的端到端模型在单文档QA问题上往往可以取得不错的效果,即此时文档较短,且查询对应的答案存在于文档的某一具体区域。但是当查询所涉及的文档较多,且文档所对应的evidence散落在多文档的多个部分时,已有的模型处理起来就有点吃力了。
为了解决上述存在的问题,作者在本文中提出了一种Coarse-Grain Fine-Grain Coattention Network (CFC),它以一种从粗粒度到细粒度的渐进的方式来寻找查询所对应的答案部分。模型整体上包括两部分:
- coarse-grain module:根据给定的查询和相应的文档通过coattention建立一种粗粒度的表示,然后通过自注意力进行总结,此时它是不知道候选答案的
- gine-grain module:通过比较查询在所有文档中出现候选答案的上下文来为每个答案打分,通过coattention建立关于候选答案所在上下文和问题的表示
在两个模块中均使用了层次化的coattention以及自注意力机制(self-attention),模型通过这两种注意力机制实现查询、支持文档和候选答案之间不同部分的关注。
CFC在WikiHop的测试集上取得了70.6%的准确率,在没有使用预训练编码器的情况下,以3%的优势好于现有的SOTA模型;另外在TriviaQA上也取得了更好的效果,从而证明了所提出模型的有效性和优越性。
模型
CFC模型整体上如下图所示:
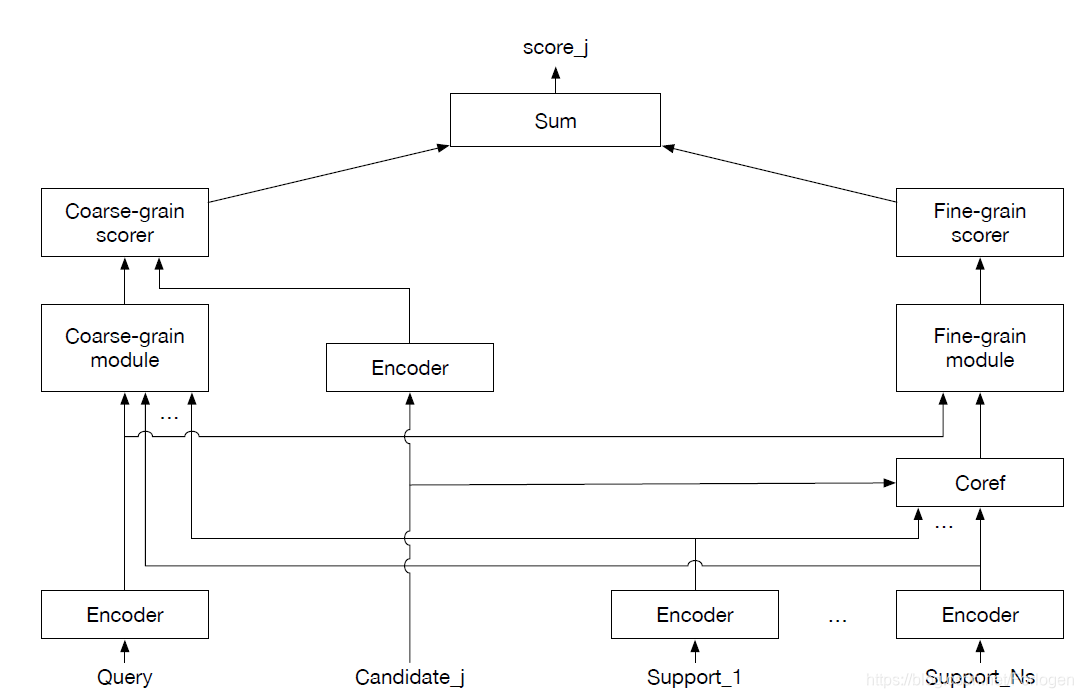
小声说:这是我看过这么多文章种画的最朴实的模型图了~
模型图一目了然,整体上包含上述的两个模块,它们分别处理查询(query)、和支持文档(support docs)。从这里可以看到两个模块都包含对应的打分器(scorer),最后综合考虑两部分的分数来选择问题对应的答案。
Coarse-grain module
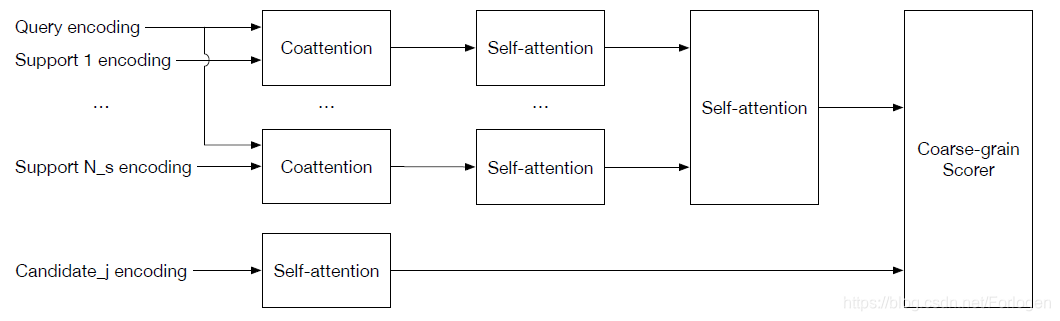
假设当前给定的查询为
q
q
q,支持文档集为
N
s
N_{s}
Ns,候选答案集为
N
c
N_{c}
Nc。首先通过Bi-GRU对各部分进行编码,其中查询、第
i
i
i个文档和第
j
j
j个候选答案所对应的表示向量为
L
q
L_{q}
Lq、
L
s
L_{s}
Ls和
L
c
L_{c}
Lc。
E
q
=
BiGRU
(
tanh
(
W
q
L
q
+
b
q
)
)
E
s
=
BiGRU
(
L
s
)
E
c
=
BiGRU
(
L
c
)
E_{q}=\text{BiGRU}(\tanh (W_{q}L_{q}+b_{q})) \\ E_{s}=\text{BiGRU}(L_{s}) \\ E_{c}=\text{BiGRU}(L_{c})
Eq=BiGRU(tanh(WqLq+bq))Es=BiGRU(Ls)Ec=BiGRU(Lc)
从上图中可以看出,首先
E
s
E_{s}
Es和
E
q
E_{q}
Eq使用coattention来建立表示向量,再使用self-attention来和
E
c
E_{c}
Ec进行比较,从而完成最后的打分操作。
具体的过程为:在得到了如上的表示向量后,首先使用
E
s
E_{s}
Es和
E
q
E_{q}
Eq计算一个亲和度矩阵(affinity matrix)
A
=
E
s
(
E
q
)
T
A=E_{s}(E_{q})^T
A=Es(Eq)T
那么
E
s
E_{s}
Es和
E
q
E_{q}
Eq就可以通过
A
A
A得到各自对应的summary vector:
S
s
=
softmax
(
A
)
E
q
S
q
=
softmax
(
A
T
)
E
s
S_{s}= \text{softmax}(A)E_{q} \\ S_{q}= \text{softmax}(A^T)E_{s}
Ss=softmax(A)EqSq=softmax(AT)Es
然后通过Bi-GRU得到文档的上下文向量
C
s
=
BiGRU
(
S
q
softmax
(
A
)
)
C_{s}=\text{BiGRU}(S_{q}\text{softmax}(A))
Cs=BiGRU(Sqsoftmax(A))最后将
C
s
C_{s}
Cs和
S
s
S_{s}
Ss进行拼接得到
U
s
=
[
C
s
:
S
s
]
U_{s}=[C_{s}:S_{s}]
Us=[Cs:Ss]
以上过程可以简单的表述为 Coattn ( E s , E q ) → U s \text{Coattn}(E_{s},E_{q}) \rightarrow U_{s} Coattn(Es,Eq)→Us
接着使用两层的MLP来对
U
s
U_{s}
Us的每个位置进行打分,得到
G
s
G_{s}
Gs。接着使用self-attention来为每个支持文档计算一个对应的固定长度的summary vector,使用它们和候选答案进行Coarse-grain模块的打分操作。
G
c
=
Selfattn
(
E
c
)
G
′
=
Selfattn
(
G
)
y
c
o
a
r
s
e
=
tanh
(
W
c
o
a
r
s
e
G
′
+
b
c
o
a
r
s
e
)
G
c
G_{c}=\text{Selfattn}(E_{c}) \\ G'=\text{Selfattn}(G) \\ y_{coarse}=\tanh(W_{coarse}G'+b_{coarse})G_{c}
Gc=Selfattn(Ec)G′=Selfattn(G)ycoarse=tanh(WcoarseG′+bcoarse)Gc
Fine-grain module
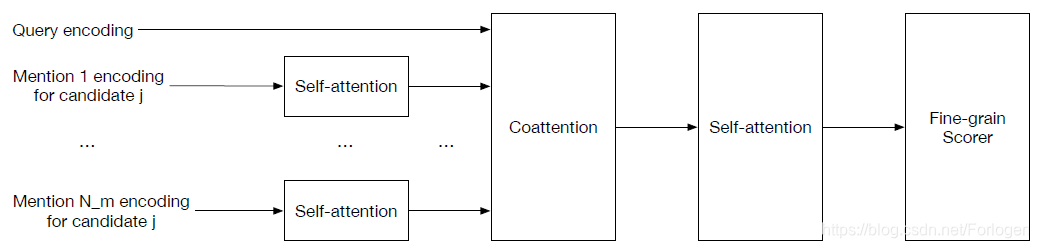
根据前面对于fine-grain模块的描述,它会根据候选答案在支持文档中找到对应的上下文部分,这里称为mention。其中每一个mention都是通过self-attention得到对应的summary vector,接着根据summary vectors和query使用coattention来计算一个coattention context,最后使用self-attention来对每个mention进行打分。
假设第
i
i
i个文档中存在
m
m
m个mention,其中每一个mention表示为答案对应的起始和终止的索引
i
s
t
a
r
t
i_{start}
istart和
i
e
n
d
i_{end}
iend,那么第
k
k
k个mention可以表示为:
M
k
=
Selfattn
(
E
s
[
i
s
t
a
r
t
:
i
e
n
d
]
)
M_{k}=\text{Selfattn}(E_{s}[i_{start}:i_{end}])
Mk=Selfattn(Es[istart:iend])
对所有的mention使用self-attention就可以得到所有mention的表示序列
M
M
M,然后根据
E
q
E_{q}
Eq计算
U
m
U_{m}
Um和
G
m
G_{m}
Gm
U
m
=
Coattn
(
M
,
E
q
)
G
m
=
Selfattn
(
U
m
)
U_{m}=\text{Coattn}(M,E_{q}) \\ G_{m}=\text{Selfattn}(U_{m})
Um=Coattn(M,Eq)Gm=Selfattn(Um)最后通过一个线性层计算gine-grain模块的分数
y
f
i
n
e
=
W
f
i
n
e
G
m
+
b
f
i
n
e
y_{fine}=W_{fine}G_{m}+b_{fine}
yfine=WfineGm+bfine
实验部分可见原文。
这篇文章看的并不是很明白,所以应该有认识不正确的地方。但总的看下来感觉所涉及的内容并不复杂,主要还是一种渐进优化思想的应用,后面有新的体会再更新吧~

















 3953
3953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









