




 介绍SIGIR2019提出的概要生成任务,利用层次化神经网络生成文档的大纲,包括章节识别与标题生成,适用于多段落文档结构理解。
介绍SIGIR2019提出的概要生成任务,利用层次化神经网络生成文档的大纲,包括章节识别与标题生成,适用于多段落文档结构理解。
SIGIR 2019 Outline Generation: Understanding the Inherent Content Structure of Documents
本文提出一种针对文本领域的新任务:outline generation,OG,它可以理解为大纲生成或是概要生成(为了方便表述,后续一律使用这种名称)。通过这样更细粒度的任务实现对于文本结构更深层次的理解,以及发现多段落多组成的文档内部的结构信息。概要生成任务可以简单的分为以下两个阶段进行:
- section identification:对于输入的多段落文档,根据不同段落表达的信息和风格,将其划分为不同的章节(section),可以将其看作序列标注任务
- heading generation:根据划分后章节的内容生成对应的概要,可以将其看作序列生成任务
因此,我们又可以将OG看做是一种层次化结构预测任务:预测章节的边界以及每个章节对应的标题,为此作者提出了一种层次化结构性神经网络生成模型(HistGen)。
为了保证章节边界预测的准确性和生成高质量的概要,这里引入了四种机制来保持生成过程中三个层次上的一致性:
- Markov paragraph dependency mechanism:马尔可夫段落依存机制,保证同一章节中各段落上下文之间的一致性,主要用于章节的划分
- section-aware attention mechanism:章节感知的注意力机制,保证章节上下文和生成的对应标题之间的一致性
- Markov heading dependency mechanism:马尔可夫概要依存机制,保证保证标题序列中前后标题上下文之间的一致性
- review mechanism:回顾机制,防止生成标题之间的内容的重复生成
由于任务的新颖性,作者同时使用维基百科构建了一个新的数据集WIKIOG,它包含1.75百万条文档-标题配对数据,以及最后通过在WIKIOG上的多类型实验证明了所提出模型的有效性。
在正式理解模型之前,我们先来看一些OG和NLP中其他类似任务的区别:
-
关键词抽取(keyword extraction):自动从文档中抽取一些关键词,主要分为两个步骤进行
-
获取关键词候选列表
-
根据关键词在文档中的重要性进行排序
但是它无法解决OOV问题,以及无法理解文本文本的内在语义。
-
-
标题生成(headline generation):生成一个表达紧凑、信息丰富的对应标题,常用的方法可以分为两类:
- 抽取式:从文档中抽取n-gram并进行排序,选择靠前的生成标题,或抽取关键语句并将其变换为要求的长度
- 神经网络式:使用Seq2Seq+Attention采用有监督的方式生成标题
-
文本摘要(text summarization):抽取或生成多个包含文档重要信息的语句组成摘要
-
故事线生成(storyline generation):总结文档中的主要事件并理解事件随时间的变化
而OG主要在一下四个方面区别于上述的四种任务:
- OG需要输出较短的结构化描述性文本
- OG需要在section-level生成序列化的标题,实现对语义细粒度的理解
- OG通过两阶段的任务实现对于文档内部结构的揭示
- OG关注于文档的多个章节
假设所需处理的文档ddd为段落的序列{p1,p2,...,pM}\{p_{1},p_{2},...,p_{M}\}{p1,p2,...,pM},我们的目标是找到一个结构化预测模型g(⋅)g(\cdot)g(⋅)来识别出章节的序列{s1,s2,..,sN}\{s_{1},s_{2},..,s_{N}\}{s1,s2,..,sN},并生成对应的标题{y1,y2,...,yN}\{y_{1},y_{2},...,y_{N}\}{y1,y2,...,yN},这个过程可以表示为:
g(p1,p2,...,pM)=(s1,s2,..,sN;y1,y2,...,yN)
g(p_{1},p_{2},...,p_{M})=(s_{1},s_{2},..,s_{N};y_{1},y_{2},...,y_{N})
g(p1,p2,...,pM)=(s1,s2,..,sN;y1,y2,...,yN)
再次强调一下,整个概要生成任务可以分为序列标注和序列生成两个阶段进行,而后一阶段的工作又具体的的依赖于前一阶段,因此如何逐阶段的高质量完成任务十分重要。
WIKIOG是本文中所使用的benchmark,它由维基百科上的文章所组成。为了实验的需要,这里去除了存在的标题,并将所有的段落拼接在一起形成了原始的文本输入{pm}m=1M\{p_{m}\}_{m=1}^M{pm}m=1M,所有的章节使用它们对应的边界{lm}m=1M\{l_{m}\}_{m=1}^M{lm}m=1M标记,每个章节对应的标题记为{yn}n=1N\{y_{n}\}_{n=1}^N{yn}n=1N。这样整个数据集就变成了由多个三元组<p,l,y><p,l,y><p,l,y>所组成。
在了解了任务的定义和所用数据集后,下面我们看一下本文中的结构化预测模型是如何实现的。HistGen仍然采用的是Encoder-Decoder的模型架构,其中Encoder负责获取多段落所组成的文档的向量表示,Decoder负责保持三个层次的一致性,从而帮助模型更好的为每个章节生成概要。
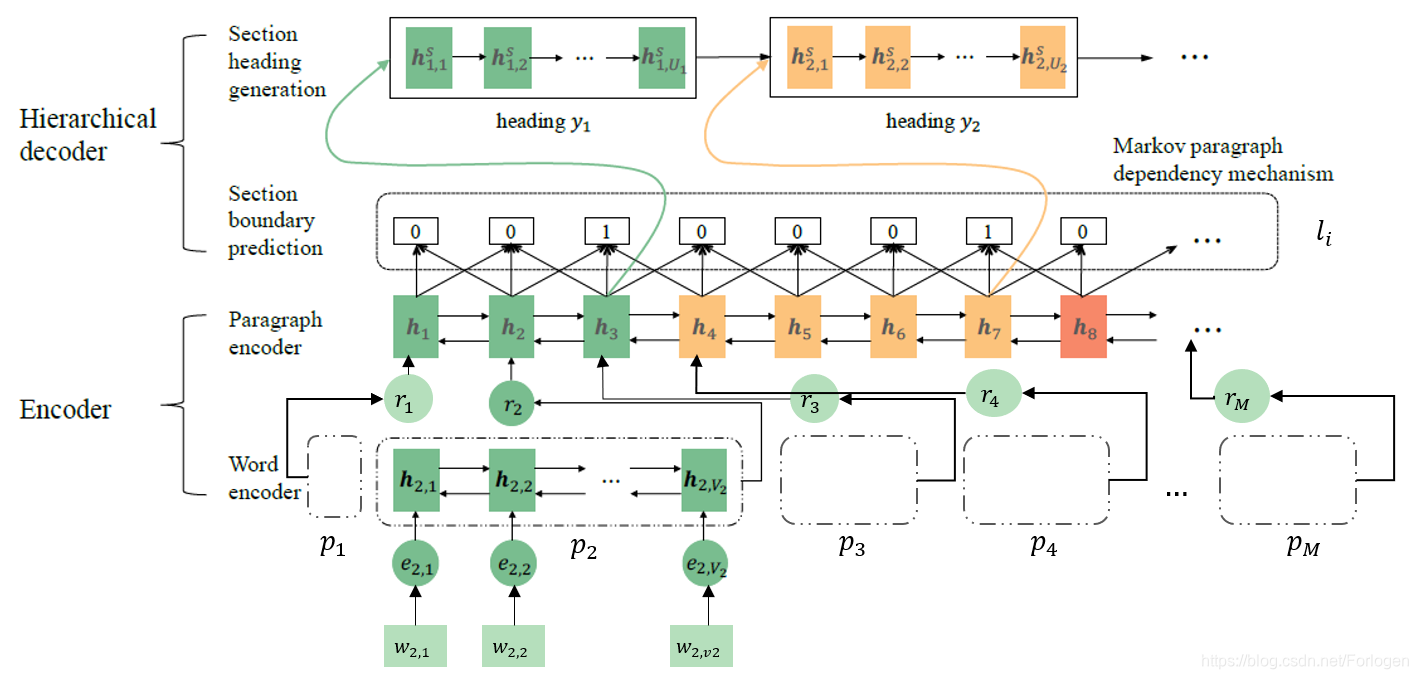
Encoder
Encoder采用基于Bi-GRU的层次化架构,首先使用word encoder获取段落ppp中词www的表示eee,然后使用paragraph encoder获取整个文档的表示向量。
p∼{e1,e2,...,em}ei∼wi
p \sim \{e_{1},e_{2},...,e_{m}\} \\ e_{i} \sim w_{i}
p∼{e1,e2,...,em}ei∼wi
对于段落pmp_{m}pm中的第vvv个词wm,vw_{m,v}wm,v来说,首先通过word encoder得到它的表示向量em,ve_{m,v}em,v,然后通过GRU得到前后两个方向的隐状态表示,那么最后wm,vw_{m,v}wm,v的隐状态表示为两个方向的拼接hm,v=[hm,v→∣∣hm,v←]\text{h}_{m,v}=[\overrightarrow{\text{h}_{m,v}}|| \overleftarrow{\text{h}_{m,v}}]hm,v=[hm,v∣∣hm,v],最后拼接两个方向最后一个隐状态,做为整个段落的表示rm=[hm,vm→∣∣hm,1←]\text{r}_{m}=[\overrightarrow{\text{h}_{m,v_{m}}} || \overleftarrow{\text{h}_{m,1}}]rm=[hm,vm∣∣hm,1]。对于每一个段落都执行这样的操作,我们便可以得到文档中所有段落的表示序列{rm}m=1M\{r_{m}\}_{m=1}^M{rm}m=1M。接下来将其送到同样是基于Bi-GRU的paragraph encoder中得到每个段落的隐状态表示hm=[hm→∣∣hm←]\text{h}_{m}=[\overrightarrow{\text{h}_{m}} || \overleftarrow{\text{h}_{m}}]hm=[hm∣∣hm]。
Decoder
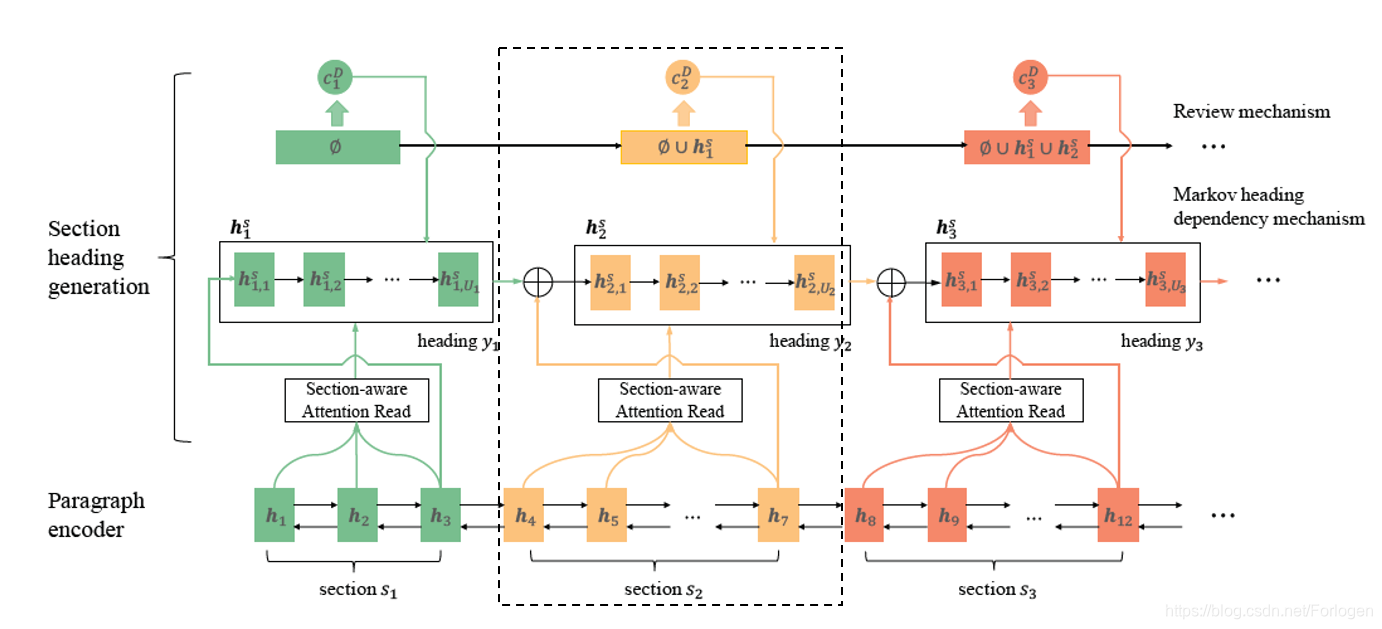
Decoder同样采用层次化的结构,它的输入为Encoder的输出,即文档中所有段落的隐状态表示{hm}m=1M\{h_{m}\}_{m=1}^M{hm}m=1M。它主要完成两件事情:章节边界的预测(或章节的划分)和章节对应概要的生成。
(p1,p2,...,pM)→(l1,l2,...,lM)→(s1,s2,..,sN)→(y1,y2,...,yN)
(p_{1},p_{2},...,p_{M}) \rightarrow (l_{1},l_{2},...,l_{M}) \rightarrow (s_{1},s_{2},..,s_{N}) \rightarrow (y_{1},y_{2},...,y_{N})
(p1,p2,...,pM)→(l1,l2,...,lM)→(s1,s2,..,sN)→(y1,y2,...,yN)
其中li∈(0,1)l_{i} \in (0,1)li∈(0,1)表示某一段落的标签,当lm=1l_{m}=1lm=1时,表示第mmm段为该章节的最后一段,此时应生成对应的概要;否则继续向后进行,直到遇到l=1l=1l=1的段落。
直觉上来看,属于同一章节的段落在表达内容和风格上应该是一致的。因此,为了保持这种一致性,作者这里使用了马尔可夫段落依存机制。它的思想在于:满足一致性的段落应该具有马尔可夫特性。
马尔可夫过程是一类随机过程,它具有如下特性:在已知目前状态(现在)的条件下,它未来的演变(将来)不依赖于它以往的演变(过去)。那么,最简单的马尔可夫过程即每一个状态的转移只依赖于之前的那个状态。
马尔科夫假设是指模型的每个状态都只依赖于之前的状态。
而在本文的实际情况中,因为在Decoder之前我们已经得到了关于所有段落的表示,因此决定某个段落(除去首尾段落)是否是章节的最后一个段落时,不仅需要看它的前一个段落,还需要看它的后一个段落。如下图虚线框所示,在判断h2h_{2}h2的标签时,需要同时看h1h_{1}h1和h3h_{3}h3。
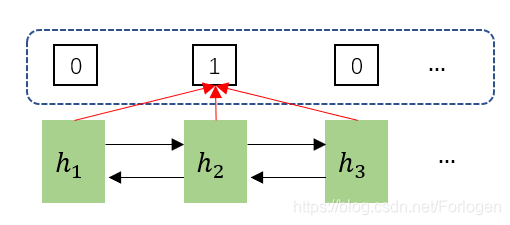
那么整个标签获取的过程可以表示为:
p(lm=1∣p≤m)=σ(hm−1⋅W1⋅hm+hm⋅W2⋅hm+1)p(lm=0∣p≤m)=1−σ(hm−1⋅W1⋅hm+hm⋅W2⋅hm+1)
p(l_{m}=1|p_{\leq m})= \sigma(h_{m-1} \cdot W_{1} \cdot h_{m}+h_{m} \cdot W_{2} \cdot h_{m+1}) \\ p(l_{m}=0|p_{\leq m})=1- \sigma(h_{m-1} \cdot W_{1} \cdot h_{m}+h_{m} \cdot W_{2} \cdot h_{m+1})
p(lm=1∣p≤m)=σ(hm−1⋅W1⋅hm+hm⋅W2⋅hm+1)p(lm=0∣p≤m)=1−σ(hm−1⋅W1⋅hm+hm⋅W2⋅hm+1)
根据上面的过程我们得到了段落对应的划分标签,也就得到了划分好的章节,接着需要为每个章节生成对应的概要。这一阶段使用了前面所说的四种机制中的后三种:
- 使用章节感知的注意力机制,使概要生成过程更加关注章节中重要的上下文信息
- 使用马尔可夫概要依存机制保持章节和对应概要表示的一致性
- 使用回顾机制保证新的概要不重复生成之前概要中已有的内容
在计算概要yny_{n}yn中第uuu个词的隐状态hn,ush_{n,u}^shn,us时,为了概要和章节内容的一致性,这里将章节感知的上下文向量cn,uc_{n,u}cn,u和概要感知的上下文向量cn,uDc_{n,u}^Dcn,uD做为计算过程额外的输入项,这个过程可以表示为:
hn,us=fs(wn,u−1,hn,u−1s,cn,u,cn,uD)
h_{n,u}^s = f_{s}(w_{n,u-1},h_{n,u-1}^s,c_{n,u},c_{n,u}^D)
hn,us=fs(wn,u−1,hn,u−1s,cn,u,cn,uD)
那么根据下面的概率公式来选择yny_{n}yn中第uuu个词:
p(wn,u∣w≤n,≤u,d)=fg(wn,u−1,hn,us,cn,u,cn,uD)
p(w_{n,u}|w_{\leq n,\leq u},d) = f_{g}(w_{n,u-1},h_{n,u}^s,c_{n,u},c_{n,u}^D)
p(wn,u∣w≤n,≤u,d)=fg(wn,u−1,hn,us,cn,u,cn,uD)
所谓的概要感知注意力机制就是为概要中的每个词维持它对应的上下文向量ccc,概要yny_{n}yn中第uuu个词的上下文向量计算为:
cn,u=∑k=1Knαu,khK1+K2+...,Kn−1+k
c_{n,u}=\sum_{k=1}^{K_{n}} \alpha_{u,k}h_{K_{1}+K_{2+...,K_{n-1}+k}}
cn,u=k=1∑Knαu,khK1+K2+...,Kn−1+k
其中αu,k\alpha_{u,k}αu,k表示注意力权重,表示章节中的第kkk个段落在yny_{n}yn生成第uuu个词时的贡献。
而马尔可夫概要依存机制和前面的马尔可夫段落依存机制类似,不过由于我们无法预测知道未来的东西,那么这里在生成新的概要时只能依赖于章节的内容和前面已生成的概要。
另外,不同的概要之间应该在表示上是“独立”的,即新的概要不应重复生成前面概要中已有的内容。因此,这里使用了回顾机制(和文本摘要中的coverage机制原理是一致的)。做法是使用已生成的概要构建一个heading-aware集合Rn,u={h1,1s,h1,2s,...,hn,u−1s}R_{n,u}=\{h_{1,1}^s,h_{1,2}^s,...,h_{n,u-1}^s\}Rn,u={h1,1s,h1,2s,...,hn,u−1s},将其融合到新的heading-aware向量中做为新概要生成过程的指导信息。
cn,uD=∑i,j=1n,u−1βn,uijhi,jsβn,uij=exp(enuij)∑p,q=1n,u−1exp(enupq)enuij=vTtanh(W5hi,js+W6hn,u−1s+b2)
c_{n,u}^D=\sum_{i,j=1}^{n,u-1}\beta_{n,u}^{ij}h_{i,j}^s \\ \beta_{n,u}^{ij}=\frac{\exp(e_{nu}^{ij})}{\sum_{p,q=1}^{n,u-1}\exp(e_{nu}^{pq})} \\ e_{nu}^{ij}=v^T \tanh(W_{5}h_{i,j}^s+W_{6}h_{n,u-1}^s+b_{2})
cn,uD=i,j=1∑n,u−1βn,uijhi,jsβn,uij=∑p,q=1n,u−1exp(enupq)exp(enuij)enuij=vTtanh(W5hi,js+W6hn,u−1s+b2)
因为该任务最终仍要落到生成任务上,所以训练过程同样使用最大似然函数作为指导来更新参数。
argmaxθ,β∑d∈D∑n=1Nlogp(yn∣sn,y<n;θ)p(sn∣d;β)
\arg \max_{\theta,\beta} \sum_{d \in D} \sum_{n=1}^N \log p(y_{n}|s_{n},y_{<n};\theta)p(s_{n}|d;\beta)
argθ,βmaxd∈D∑n=1∑Nlogp(yn∣sn,y<n;θ)p(sn∣d;β)
使用最大似然函数作为指导来更新参数。
argmaxθ,β∑d∈D∑n=1Nlogp(yn∣sn,y<n;θ)p(sn∣d;β)
\arg \max_{\theta,\beta} \sum_{d \in D} \sum_{n=1}^N \log p(y_{n}|s_{n},y_{<n};\theta)p(s_{n}|d;\beta)
argθ,βmaxd∈D∑n=1∑Nlogp(yn∣sn,y<n;θ)p(sn∣d;β)
实验略~

















 1893
1893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









