




 提出一种结合抽取和重写技术的文档摘要方法,利用强化学习优化句子选取,生成高质量摘要。
提出一种结合抽取和重写技术的文档摘要方法,利用强化学习优化句子选取,生成高质量摘要。
ACL 2018 Fast Abstractive SUmmarization with Reinforce-Selected Sentence Rewriting
背景
对于文档摘要任务来说,整体上可以将任务解耦为两部分:
- 选出显著性较高的K个句子(抽取式到此结束)
- 对于选择出的句子进行重写(抽象式)
因此对于抽象式方法来说,以上的两步中每一步的效果优劣都对于整体的效果有着显著的影响。如果在显著性句子抽取过程中可以正确的选择出包含主要信息的句子的话,那么在接下来的重写过程中就可以实现在不丢失主要信息的前提下得到流畅性、可读性更好的结果。
如果抽象式模型直接对输入的长文档进行处理,通常会出现解码慢、结果冗余度高等问题。因此,一个很自然的想法就是结合两种方法的优势:使用抽取式方法先得到包含主要信息的相关语句,从而减小重写过程中所需关注的信息量;另一方面,重写过程可以在关注主要信息的同时,以一种更加流畅的方式对文本进行描述。
但此时就出现了一个问题,两部分的训练由于无法直接传递梯度信息,并不能直接进行端到端的训练。因此,本文同样使用了强化学习来解决这个问题,将抽取模型看做agent,把抽取的句子进行重写后的结果和真实摘要进行比较,将比较的结果看做是一种reward,从而进行前一部分的更新。而重写模型依然可以使用最小化负对数似然的方式进行训练,这样强化学习就为两部分模型的训练搭建起了一个桥梁。
另外作者指出,由于在抽取部分得到的结果较好,即使在重写过程中不使用coverage机制等避免生成重复结果的技巧,重写得到的结果也是不错的。但为了解决最后结果中可能存在的跨句重复的问题,这里又使用了一个额外的reranker。
模型
抽取模型
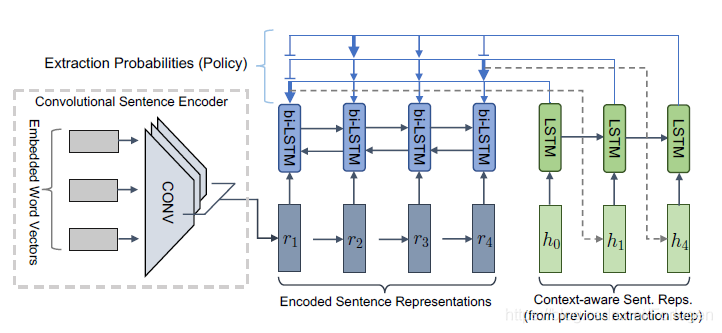
假设训练集由文档-摘要的配对数据 { x i , y i } i = 1 N \{x_{i},y_{i}\}_{i=1}^N {xi,yi}i=1N组成,抽取模型的目的是找到一个函数 h ( x i ) = y i h(x_{i})=y_{i} h(xi)=yi,重写模型希望找到一个函数 g ( d ) = s g(d)=s g(d)=s。抽取模型如上所示,它采用了一种层次化的方法来进行句子的选择:首先通过卷积网络得到文档中每个句子的初始表示向量 r j r_{j} rj,然后在使用Bi-LSTM在结合全局信息的基础上得到每个句子更加丰富的表示 h i h_{i} hi。
在得到文档中每个句子的表示后,这里使用了指针网络来进行句子的选择,每个句子被选择的概率为:
v
i
j
t
=
{
v
p
T
tanh
(
W
p
1
h
j
+
W
p
2
e
t
)
,
if
j
t
≠
j
k
−
∞
,
∀
k
<
t
v_{ij}^t =\begin{cases}v_{p}^T \tanh(W_{p1}h_{j}+W_{p2}e_{t}), & \text{if $j_{t} \neq j_{k}$} \\- \infty, & \forall k < t\end{cases}
vijt={vpTtanh(Wp1hj+Wp2et),−∞,if jt=jk∀k<t
其中
e
t
e_{t}
et使用一种称为glimpse的操作进行计算。另外使用了2-hop注意力机制,首先计算
h
j
h_{j}
hj对应的上下文向量
e
t
e_{t}
et,然后计算
h
j
h_{j}
hj被抽取的概率,这样通过两步骤的方式就可以根据文档中句子的表示实现关键句的抽取。
在得到关键句后需要使用重写模型进行重写操作,希望得到更加简短且精确的表述。文中这里并没有使用什么特别复杂的模型,因为抽取模型如果得到的关键句够准确,那么简单的Seq2Seq模型也足以得到够好的结果。
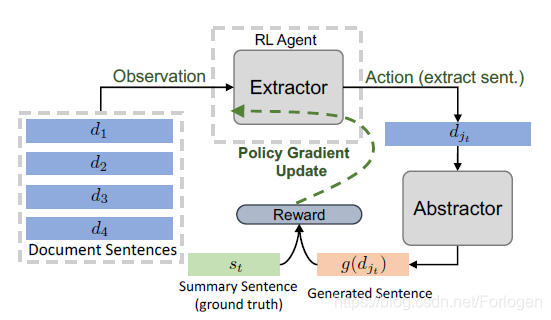
为了将两部分整合起来进行联合训练,作者采用如上强化学习的方法进行训练。首先Extractor根据当前的奖励值会决定抽取哪些句子给Abstractor,然后Abstractor根据抽取的句子进行重写,将重写后的结果和真实摘要进行比较,此时比较的结果作为下一时刻的奖励值用于Extractor的更新。
但模型整体上很依赖于两部分各自的效果,如果抽取部分得到的句子是相关性很差的,那么即使重写模型能力再强得到的结果也是无用的。因此,两部分各自通过最大化似然来进行训练,同时使用强化学习使得两部分可以采用端到端的方式进行训练。
训练
抽取部分的问题这里看做是简单的二分类问题,即某个句子是否应该做为抽取的结果。但是数据集中并不存在针对于文档中句子的标签,因此这里将句子和文档对应摘要的ROUGE-L分数作为对应的标签,最后通过优化交叉熵损失函数进行训练。
j
t
=
arg
max
(
ROUGE-L
r
e
c
a
l
l
(
d
i
,
s
t
)
)
j_{t}=\arg \max (\text{ROUGE-L}_{recall}(d_{i},s_{t}))
jt=argmax(ROUGE-Lrecall(di,st))
重写部分和普通的抽象式模型并无区别,同样是通过优化交叉熵损失函数进行训练。
L
(
θ
a
b
s
)
=
−
1
M
∑
m
=
1
M
log
P
θ
a
b
s
(
w
m
∣
w
1
:
m
−
1
)
L(\theta_{abs})=-\frac{1}{M} \sum_{m=1}^M \log P_{\theta_{abs}}(w_{m}|w_{1:m-1})
L(θabs)=−M1m=1∑MlogPθabs(wm∣w1:m−1)
强化学习部分将整体看作是马尔可夫决策过程,时刻
t
t
t对应的状态为
c
t
=
(
D
,
d
j
t
−
1
)
c_{t}=(D,d_{j_{t-1}})
ct=(D,djt−1),根据此时状态所采取的动作为
j
t
∼
π
θ
a
,
w
(
c
t
,
j
)
=
P
(
j
)
j_{t} \sim \pi_{\theta_{a},w}(c_{t},j)=P(j)
jt∼πθa,w(ct,j)=P(j),那么下一时刻的奖励值即生成的摘要和真实摘要比较的ROUGE分数
r
(
t
+
1
)
=
ROUGE-L
F
1
(
g
(
d
j
t
)
,
s
t
)
r(t+1)=\text{ROUGE-L}_{F_{1}}(g(d_{j_{t}}),s_{t})
r(t+1)=ROUGE-LF1(g(djt),st)
这里使用的是A2C算法进行策略梯度更新。另外,由于强化学习训练过程并不涉及重写部分的训练,因此并不会影响得到的摘要的流畅性和可读性。
但是究竟抽取多少个句子才够呢,或者说强化学习的训练何时终止呢?作者这里在动作空间中加入了stop操作,它和句子的表示具有相同的维度,当抽取到 v E O E v_{EOE} vEOE(stop对应的表示向量)时,模型所提供的奖励值为零,表示训练应该停止了。
最后为了尽可能得到冗余度小的结果,作者使用一种重排机制来消除跨句(across-sentence)的重复问题。基本思想为:将解码得到的k个句子进行重排,重排的依据是重复的N-grams的数量,数量越小,表示得到的结果越好。
实验
数据集:CNN/Daily Mail,评价指标:ROUGE、METEOR
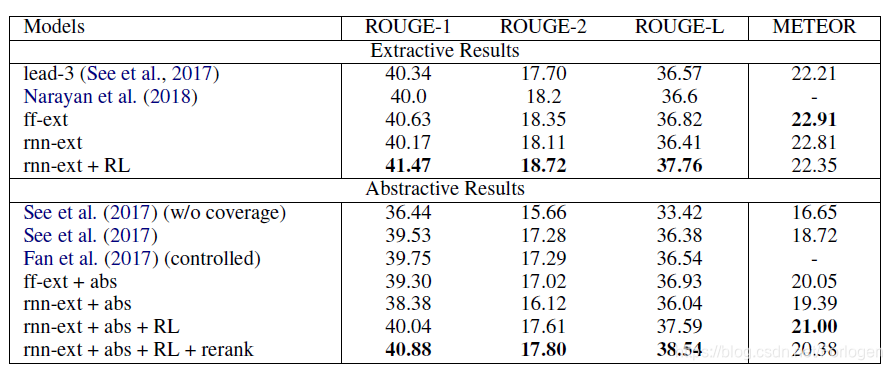
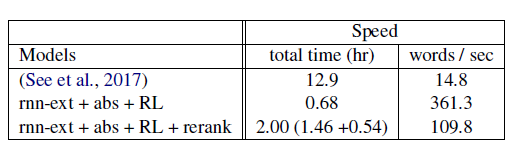
除了评价指标的提升之外,一个最大的提升便是训练时间大幅缩短。因为重写部分可以并行运算,不同的句子之间解码时候相互不影响。

















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









