



在数字化转型与数据爆炸式增长的双重驱动下,企业非结构化数据(如图片、视频、日志、数据)爆炸性增长,这对存储系统的可扩展性、性能以及安全性提出了更高要求。对象存储以超高可扩展性、高可靠性和低成本的优势,成为企业应对大规模非结构化数据存储的首选方案。企业如何根据自身业务需求选择合适的对象存储服务成为亟待解决的问题。
在国内市场,阿里云、百度智能云、腾讯云等主流云厂商各自提供了自研的对象存储服务。本篇文章将从性能角度横向对国内主流云厂商的对象存储服务进行了性能实测,帮助您根据因业务需求对对象存储服务选型,希望给各位提供一些参考。
一、测试环境
1.1 硬件环境
为了确保测试的公正性和准确性,本次对比测试采用了统一的测试环境,均选取各个云厂商相同规格相似代次的云主机实例,具体配置信息如下:
|
属性 |
阿里云 |
百度智能云 |
腾讯云 |
|
实例类型 |
ecs.g6.xlarge |
bcc.g5.c4m16 |
S6.LARGE16 |
|
CPU 规格 |
4C/16G |
4C/16G |
4C/16G |
|
操作系统 |
Centos 7.5 |
Centos 7.5 |
Centos 7.5 |
|
云盘类型 |
ESSD AutoPL |
增强型 SSD_PL1 |
增强型 SSD |
|
云盘容量 |
100GiB |
100GiB |
100GiB |
|
云盘IOPS |
6800 |
6800 |
6800 |
|
云盘吞吐量 |
170 MBps |
170 MBps |
170 MBps |
1.2 网络环境
为了排除外网因素的干扰,所有厂商均的云主机实例均在 VPC 内通过内网访问对象存储的 Endpoint 进行读写访问。
二、测试方法
2.1 测试标准
本次选择日常业务中对业务有明显影响的指标,对各家的对象存储产品进行评测,以下是本地测试涉及到的主要指标:
-
吞吐量 (Throughput):单位时间内能够处理的数据量,通常以字节/秒 (Bytes/second) 或操作/秒 (Operations/second))表示,是上传、下载的总吞吐量或者单位时间内的可完成的操作数。为了标准统一且易于衡量,这里统一选取字节/秒 (Bytes/second)作为衡量吞吐能力的标准。高吞吐量意味着能够快速处理大量数据,这对于企业需要频繁上传、下载或处理大量数据的业务至关重要。 低吞吐量会导致数据处理速度缓慢,影响用户体验和业务效率。
-
典型场景:大规模数据备份、归档和日志系统是典型例子。 企业级数据备份需要在短时间内处理 PB 级数据,容忍一定延迟。 海量日志数据实时写入也对吞吐量提出极高要求,保证数据不丢失是首要目标。 此外,媒体内容分发网络(CDN)需要处理大量并发请求,快速分发视频和图片,吞吐量是关键性能指标。 这些场景更关注单位时间内处理的数据量,而非单个请求的响应速度。
-
-
延迟 (Latency):完成一个操作所需的时间,通常以毫秒 (milliseconds)表示。 这包括上传、下载、获取元数据等操作的延迟。当然延迟可以细分成多种延时指标,比如常见有下面的两种,从整体影响和直观的角度考虑,本次选取端到端延迟作为主要测试指标。
-
响应延迟 (Response Time)指的是从客户端发出请求到客户端接收到服务器的第一个字节响应之间的时间间隔。它衡量的是整个请求-响应周期的时长,包括网络传输时间、服务器处理时间以及其他可能的等待时间。包含网络延迟 (网络传输时间)、服务器排队延迟 (等待服务器处理请求的时间)、服务器处理延迟 (服务器处理请求所需的时间)、以及将响应发送回客户端的网络延迟。从用户的角度来看,平均响应延迟反映了用户感知到的系统响应速度,平均响应延迟越低表示系统响应速度越快,用户体验越好。
-
处理延迟 (Processing Time)指的是服务器处理请求所需的时间,不包括网络传输时间。 它衡量的是服务器端处理请求的效率。包含服务器接收请求的时间、服务器处理请求逻辑的时间、以及服务器准备响应数据的时间。 它排除了网络延迟。从服务器的角度来看,平均处理延迟反映了服务器处理能力和效率。 一个较低的平均处理延迟表示服务处理能力强,效率高。
-
端到端延迟 (End-to-End Latency) 或者总延迟 (Total Latency)。 它包含了请求的各个阶段的所有延迟,能够综合所有影响反应最终业务使用时的延时说明。
-
典型场景:主要是有实时数据处理与分析需求的场景,例如物联网设备或金融交易系统生成实时数据,数据需要快速存储并被分析系统读取;同时,金融风控系统需要实时处理交易数据,延时过高会影响决策效率。还有日常我们所熟知的监控系统,需要低延时存取视频片段,保障实时性。
-
-
请求成功率/可用性(Availability):系统能够正常处理的 query 占总请求数的比例,这里仅统计状态码为 500 的请求作为失败请求进行统计,其他状态码的失败大概率并不是服务端原因造成的。高请求成功率/可用性意味着系统能够持续稳定地运行,这对于所有业务都至关重要。但是由于请求成功率跟服务端集群的负载、规模、请求类型、持续时间,甚至时段都有一定的关联性,总的来说随机性较大,需要做长周期的统计,因此请求成功率的参考意义有限,并不是本次横向测试主要的测试项。
总体来看,吞吐量和请求的延时表现是大部分业务最关注的性能指标,所以本次测试将其作为主要的关注指标。请求成功率/可用性从测试角度来看需要长周期验证才有一定的参考意义,只能上了业务才能随缘体验到各家的服务稳定性,因此该指标不在本次测试的重点。
2.2 测试方案
为了保证性能测试的全面性,按照梯度选择不同的文件大小分别测试读写 query 的失败率、时延和吞吐量数据。
-
针对中小文件,重点关注请求的成功率以及完成请求对应的时延,成功率越高,时延越低则性能更优;
-
针对大文件,不仅要关注成功率和完成的耗时,还需要关注单连接的吞吐能力以及在多并发的情况下吞吐能力的扩展性;
具体的测试 case 如下:
|
操作类型 |
文件大小 |
压力情况(并发数) |
对象数量 |
获取数据 |
备注 |
|
put |
100k |
20 |
3w~4w |
失败率 时延 |
大文件选取了三种线程数,其中单线程测试系统最大处理速率(即吞吐); 多线程测试集群在大并发下的处理能力是否线性增长。 |
|
1M |
10 |
1.8w~2w |
失败率 时延 | ||
|
10M |
5 |
1.5w~1.8w |
失败率 时延 | ||
|
100M |
1 |
4.5k~6k |
失败率 时延 吞吐量 | ||
|
1G |
1/5/10 |
400~550 |
失败率 时延 吞吐量 | ||
|
get |
100k |
20 |
3w~4w |
失败率 时延 |
同上 (选取 100M 200M 是为了说明有限速、吞吐不变,耗时加倍; 选取 1G 1 线程是为了看后端对于不同大小文件是否限速不同; 选取 1G 的1 5 10 线程是为了看多线程下后端的处理能力,比如吞吐是否有变) |
|
1M |
10 |
1.8w~2w |
失败率 时延 | ||
|
10M |
5 |
1.5w~1.8w |
失败率 时延 | ||
|
100M |
1 |
4.5k~6k |
失败率 时延 吞吐量 | ||
|
1G |
1/5/10 |
400~550 |
失败率 时延 吞吐量 |
2.3 测试工具
本次测试为了尽量消除测试工具造成的差异,使用业界通用的 cosbench 工具,使用相同的配置对各厂商的对象存储统一通过 S3 兼容接口进行性能测试。
需要说明的是 cosbench 对吞吐的计算方法是 bandwidth=(读或写流量/总运行时间),而实际运行中读写会交替进行,因此总运行时间是包含了读+写的总运行时间,得到的测试结果中读或写的带宽约为时间的一半。
使用 cosbench 工具配置说明
-
100K 1个线程跑 20 min = 1200s
-
1M 1个线程跑 0.5 h = 1800s
-
4M 1个线程跑 0.5 h = 1800s
-
10M 1个线程跑 0.5h = 1800s
-
100M 1个线程跑 0.5h = 1800s
-
1G 1个线程跑 0.5h = 1800s
相关测试代码如下:
<workstage name="init">
<work type="init" workers="1" config="cprefix=test-bucket;csuffix=-1300938564;containers=r(1,1)" />
</workstage>
<workstage name="prepare">
<work type="prepare" workers="1" driver="driver1" config="cprefix=test-bucket;csuffix=-1300938564;containers=r(1,1);objects=r(1,1000);sizes=c(100)KB" />
</workstage>
<workstage name="readandwirte">
<work name="main" workers="10" runtime="1800" driver="driver1" >
<operation type="read" ratio="50" config="cprefix=test-bucket;csuffix=-1300938564;containers=u(1,1);objects=u(1,1000)" />
<operation type="write" ratio="50" config="cprefix=test-bucket;csuffix=-1300938564;containers=u(1,1);objects=u(1001,2000);sizes=c(100)KB" />
</work>
</workstage>
<workstage name="cleanup">
<work type="cleanup" workers="10" config="cprefix=test-bucket;csuffix=-1300938564;containers=r(1,1);objects=r(1,2000)" />
</workstage>
<workstage name="dispose">
<work type="dispose" workers="1" config="cprefix=test-bucket;csuffix=-1300938564;containers=r(1,1)" />
</workstage>
三、结果分析
CosBench 测试结果
avg 延时结果统计如下(单位为 m ):
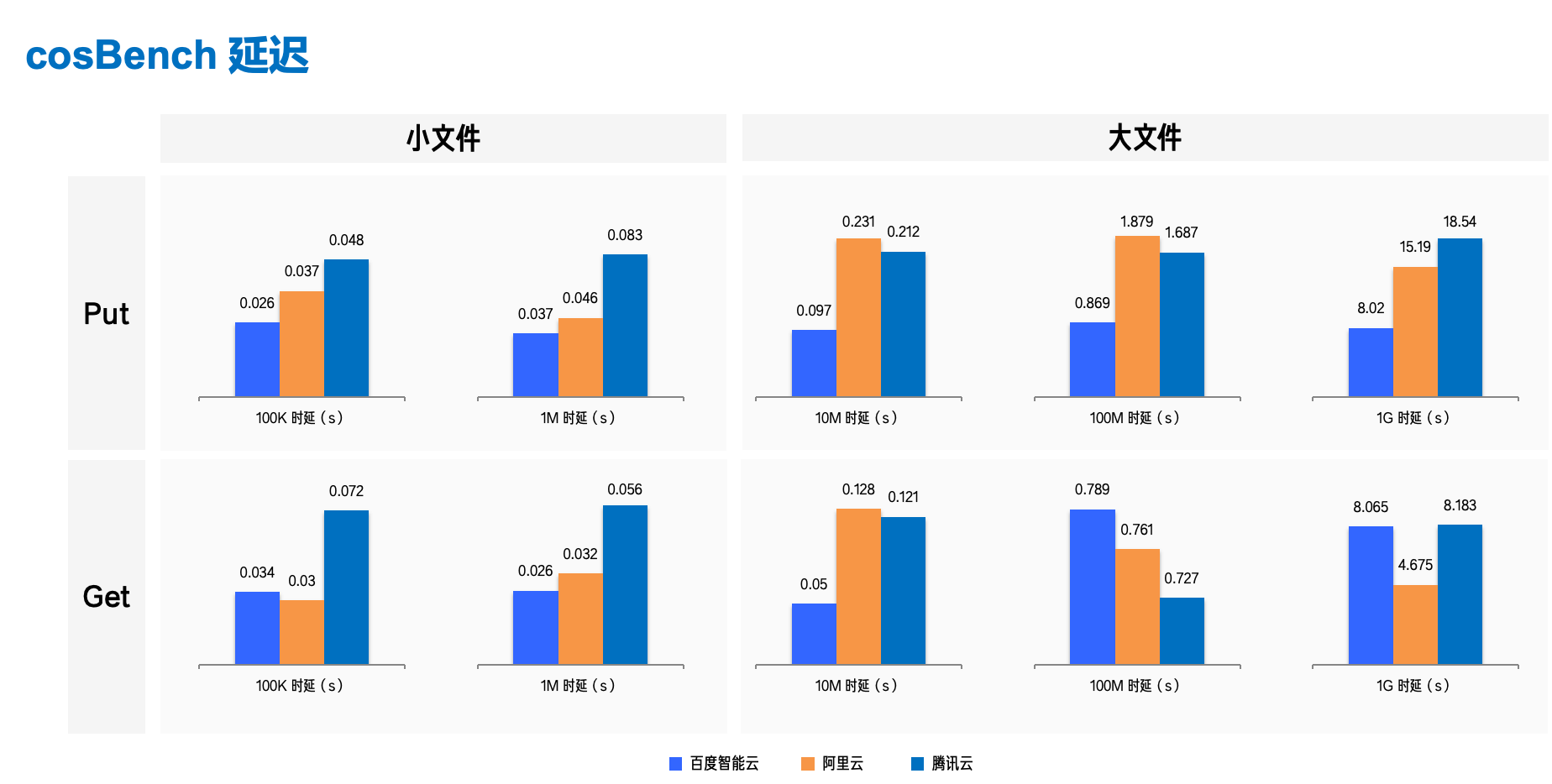
测试导出的详细延时测试结果如下:
3.1 阿里云 OSS
-
100K

-
1M

-
10M

-
100M

-
1G

3.2 腾讯 COS
- 100K

- 1M

- 10M

- 100M

- 1G

3.3 百度智能云 BOS
- 100K

- 1M

- 10M

- 100M

- 1G

延时结果越低越好,由统计结果得出以下结论:
-
小文件场景(100k 和 1M):百度智能云 > 阿里云 > 腾讯云
-
百度智能云 除了 100k 下载场景延时略高于阿里,其他场景延时均低于阿里和腾讯,具有显著优势;
-
阿里云在小文件场景表现良好,与百度智能云的差距不大,也显著优于腾讯云;
-
腾讯云小文件场景表现一般,延时甚至是百度智能云的两倍多。
-
-
大文件场景(10M、100M 和 1G):百度智能云 > 腾讯云 > 阿里云
-
百度智能云除了在 100M 文件下载场景不及腾讯外,其他类型的上传下载均表现优异;
-
阿里云只在 1G 文件下载表现较高,其他场景表现一般;
-
腾讯云在大文件场景表现反超阿里云,但在 1G 文件场景表现一般。
-
大文件吞吐测试结果统计如下:需要特别说明的是,由于 cosbench 对读写同时进行测试,读或写的 bandwidth 的计算方式为(读或写量/总运行时间),总运行时间是读操作和写操作的时长总和,因此以下记录的吞吐值大致为实际吞吐的一半。
单位为 MBps。
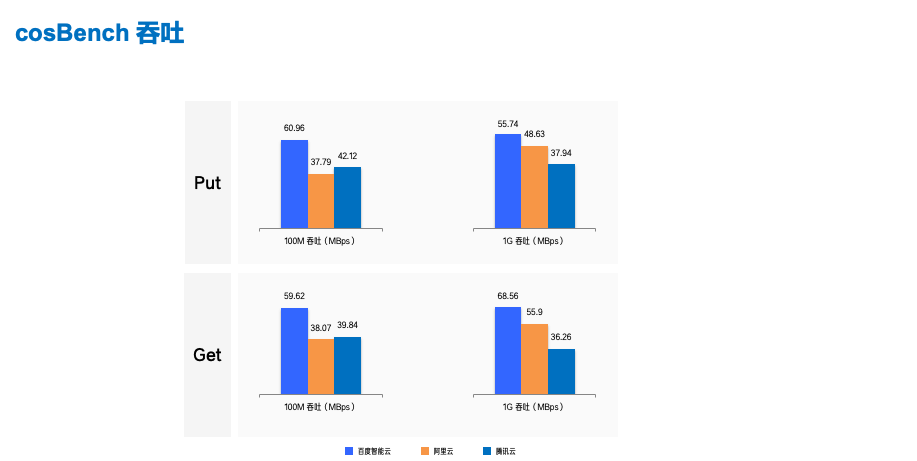
测试得到的性能图:
- 阿里云 OSS
- 100M

- 1G

- 100M
- 腾讯云 COS
- 100M

- 1G

- 100M
- 百度智能云 BOS
- 100M

- 1G

- 100M
吞吐数据越大越好,由统计结果可得到以下结论:
-
总体吞吐能力排序为百度智能云 > 阿里云 ≈ 腾讯云
-
百度智能云在各个场景吞吐能力均显著高于阿里云和腾讯云,各方面表现优异;
-
阿里云在 100M 文件下吞吐低于腾讯云,但在 1G 文件下吞吐高于腾讯云,在超大文件的读写操作时有优势;
-
腾讯云在 100M 文件场景下吞吐要高于 1G 文件场景,看起来最适合做几十 M 到百 M 文件的读写操作。
-
四、总结
本次测试对市面上场景的几家云厂商的对象存储产品,包括阿里云(OSS)、百度智能云(BOS)和腾讯云(COS),对象存储产品性能进行了全面评估。
通过 cosbench 工具测试可以相对公平反应各家对象存储的实际性能。综合测试结果,可以大致得到以下结论:
各厂商产品能力综合排名:百度智能云 > 阿里云 > 腾讯云
-
阿里云(OSS):综合能力处于中等水平,10M-100M 的文件延迟较差,其他常见场景如小文件的延时还是大文件的吞吐没有明显短板但是也没有突出的表现。
-
百度智能云(BOS):除了在大文件读场景延时略高,在其他常见的场景中均表现出色,时延低,吞吐量高,综合性价比高。
-
腾讯云(COS):小文件延时较差,大文件吞吐相较普通,整体略逊于其他厂商。
基于场景的产品选型建议:
-
混合场景:首推百度智能云 BOS,各个场景性能表现均很优异,综合性价比高。
-
小文件场景:可选百度智能云 BOS 或阿里云 OSS,两者在小文件处理上表现突出,均可满足高频率的小文件读写需求。
-
大文件场景:首选百度智能云 BOS,其时延和吞吐量均显著优于其他厂商。可以考虑阿里云 OSS 作为备选,其在大文件场景中表现也较为出色。

















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









