




 本文详细介绍了Logistic回归的基本概念、模型分类、构建步骤、Sigmoid函数的作用、参数优化方法、模型评估以及其在实际问题中的应用条件。通过实例演示了如何使用Python和scikit-learn实现Logistic回归模型。
本文详细介绍了Logistic回归的基本概念、模型分类、构建步骤、Sigmoid函数的作用、参数优化方法、模型评估以及其在实际问题中的应用条件。通过实例演示了如何使用Python和scikit-learn实现Logistic回归模型。
目录
Logistic回归基本概念
Logistic回归(逻辑回归)是一种广泛应用于分类问题的统计方法,尤其是在二分类问题中。虽然它的名字里有“回归”二字,但实际上它是用来做分类预测的。Logistic回归通过使用logit函数(或称为逻辑函数、sigmoid函数)将线性回归的输出映射到一个介于0和1之间的概率值。这个特性使得Logistic回归非常适合于估计某个事件发生的概率。
Logistic回归模型的分类
Logistic回归模型主要可以分为以下几种类型:
二元Logistic回归:这是最基本的Logistic回归模型,用于处理两类分类问题。例如,预测一个人是否会得某种疾病(是或否)、一个电子邮件是否是垃圾邮件(是或否)等。
多元Logistic回归:当需要处理的问题涉及到三个或更多的互斥分类时,我们就需要使用多元Logistic回归。多元Logistic回归又可以分为多类别Logistic回归和排序Logistic回归。多类别Logistic回归用于处理目标变量有多个类别的情况,而这些类别之间没有顺序关系;排序Logistic回归则用于处理目标变量的类别具有顺序关系的情况,比如评级(优、良、中、差)。
混合Logistic回归:混合Logistic回归模型是一种可以处理混合数据的模型,即目标变量既包含连续的部分,也包含离散的部分。这种模型在生态学和医学研究中有广泛应用。
条件Logistic回归:条件Logistic回归用于处理配对的观察值,例如,在医学研究中,可能需要比较同一对双胞胎中的一个人得病与另一个人不得病之间的差异。
以上就是Logistic回归模型的主要分类,每种模型都有其特定的应用场景,但核心的思想都是利用Logistic函数将线性回归模型的输出转换为概率,以进行分类预测。
Logistic回归的步骤
Sigmoid函数
Sigmoid函数是Logistic回归中最核心的部分,其数学表达式为:
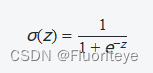
其中,z 是模型的线性预测值,即 ,w 是权重向量,x 是特征向量,b 是偏置项。Sigmoid函数的输出范围在0到1之间,可以表示为概率。
模型建立
在建立Logistic回归模型时,我们试图找到一组参数(权重和偏置),使得模型输出的概率最接近真实标签。对于给定的样本集合,其中
是第i个样本的特征向量,
是对应的标签(0或1),模型的预测值
由下式给出:
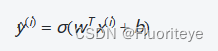
损失函数
为了训练模型,我们需要定义一个损失函数来衡量模型预测值与真实值之间的差异。Logistic回归通常使用对数损失函数(也称为交叉熵损失),对于单个样本,损失函数为:
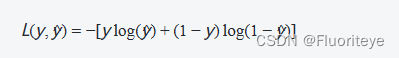
对于整个数据集,损失函数是所有单个损失的平均值。
参数优化
参数优化的目标是找到一组参数,使得损失函数值最小。这通常通过梯度下降或其变体进行。梯度下降通过迭代地调整参数来减少损失,具体来说,每次迭代中参数的更新规则为:
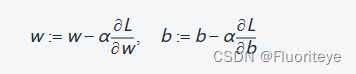
其中α是学习率,和
分别是损失函数对权重和偏置的偏导数。
模型评估
模型训练完成后,需要通过某些指标来评估其性能,常见的评估指标包括准确率、精确率、召回率和F1分数等。
Logistic回归的用途及应用条件
Logistic回归的用途
Logistic回归是一种非常流行的分类算法,它在多个领域都有广泛的应用,主要用途包括:
二分类问题:最常见的用途之一是处理二分类问题,例如垃圾邮件检测、疾病诊断(患病与否)、信用卡欺诈检测等。
概率预测:Logistic回归不仅能够进行分类,还可以直接提供事件发生的概率估计,这在风险评估和医疗诊断中特别有用。
多分类问题:通过扩展为多项Logistic回归,可以处理多于两个类别的分类问题,例如文本分类、图像识别中的物体分类等。
变量影响分析:Logistic回归可以用来分析不同因素对结果变量的影响程度,例如在流行病学研究中分析不同因素对疾病发生的贡献。
特征选择:在建模过程中可以使用正则化技术进行特征选择,以确定哪些变量对模型预测最为重要。
Logistic回归的应用条件
为了确保Logistic回归模型能够有效地工作,需要满足一些应用条件:
目标变量的二元性或多元性:Logistic回归适用于因变量是分类变量的情况,这通常意味着二分类或多分类。
观测独立性:数据集中的每个观测值应该是独立的,即一个观测值的结果不应该影响或决定另一个观测值的结果。
线性关系:Logistic回归要求输入变量和Logit变换后的目标变量之间存在线性关系。这可以通过变量转换或添加多项式项来解决非线性问题。
无多重共线性:模型中的特征不应该高度相关,即不存在多重共线性。如果特征之间相关性很高,可能需要进行特征选择或降维操作。
样本大小:Logistic回归对样本大小有一定的要求。一般来说,每个预测变量至少需要10个事件(也就是最小类别的案例数)。
特征尺度:虽然Logistic回归不要求变量具有正态分布,但最好对特征进行标准化处理,尤其是在使用正则化时。
当这些条件得到满足时,Logistic回归通常能够提供一个强大且可解释性强的模型。然而,如果数据存在复杂的非线性关系,可能需要考虑其他更复杂的机器学习方法,如决策树、随机森林或神经网络。
Logistic实例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 生成随机数据
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0, n_clusters_per_class=1, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建Logistic回归模型实例
model = LogisticRegression()
# 训练模型
model.fit(X_train, y_train)
# 可视化决策边界
plt.figure(figsize=(10, 6))
# 设置最大值和最小值以及网格密度
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
# 预测整个网格的值
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制等高线图和训练样本
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, s=20, edgecolor='k')
plt.title('Logistic Regression Classification')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
运行结果:
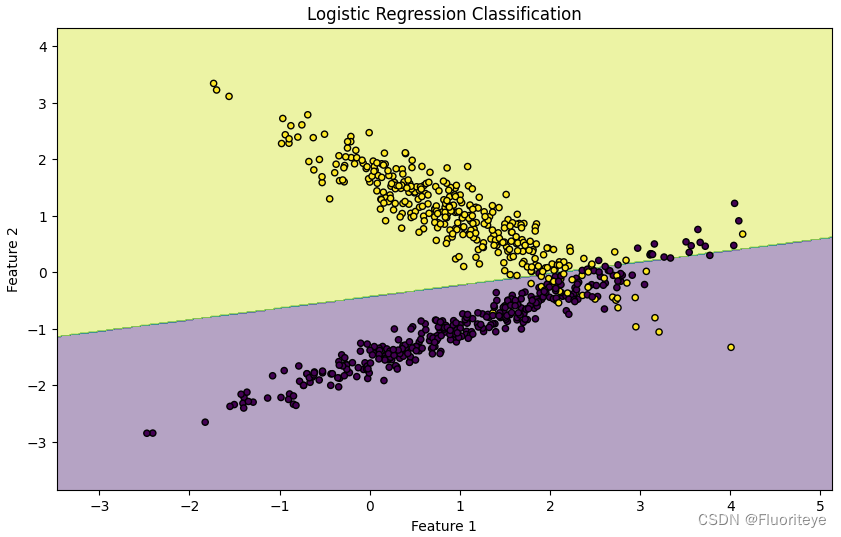
总结
在本次实验中,我们使用scikit-learn库在Python环境下演示了Logistic回归的基本应用。通过生成一个简单的二分类数据集,我们训练了一个Logistic回归模型,并将其应用于测试数据。实验结果通过可视化的决策边界清晰地展示了模型如何区分两个类别。这个过程体现了Logistic回归作为一个分类工具的直观性和易于实施性,同时也突出了它在处理简单线性可分数据时的有效性。

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









