



 本文通过掷骰子实例深入解析HMM模型,介绍了其构成要素(隐态、可观测状态、转移概率矩阵等)、概率计算、监督与无监督学习方法(包括Baum-Welch算法)、预测问题(维特比算法)及其在实际问题中的应用。
本文通过掷骰子实例深入解析HMM模型,介绍了其构成要素(隐态、可观测状态、转移概率矩阵等)、概率计算、监督与无监督学习方法(包括Baum-Welch算法)、预测问题(维特比算法)及其在实际问题中的应用。
【总结】隐马尔可夫(HMM)
目录
1)什么是HMM
李航《统计学习方法》第十章:给隐马尔可夫模型定义如下:
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程。
初识这个定义,晦涩难懂;搞不清楚什么是不可观测的状态,这里用一个例子阐述什么HMM模型以及相关概念;
还是用最经典的例子,掷骰子。假设我手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
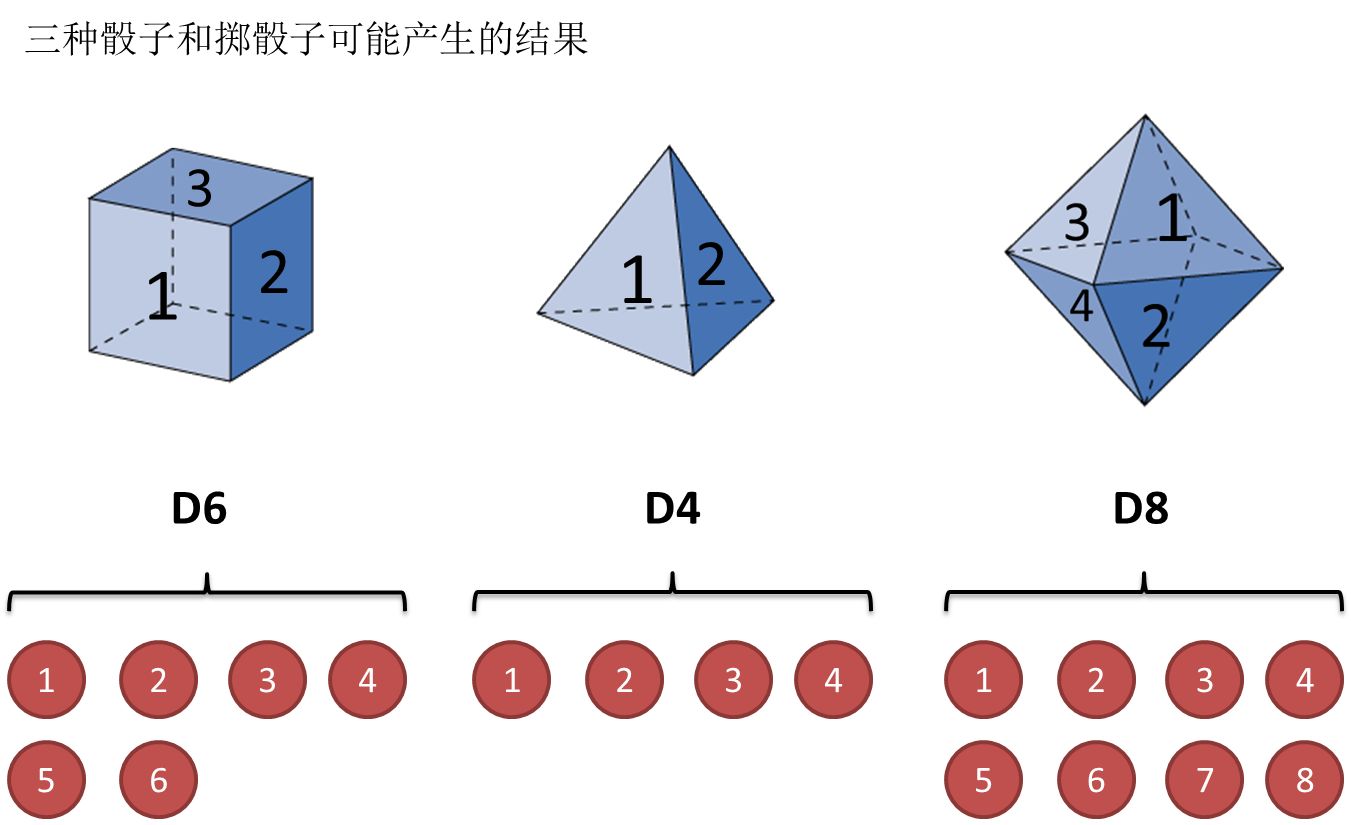
假设我们开始掷骰子,我们先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。然后我们掷骰子,得到一个数字,1,2,3,4,5,6,7,8中的一个。不停的重复上述过程,我们会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。例如我们可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4
这串数字叫做可见状态链。但是在隐马尔可夫模型中,我们不仅仅有这么一串可见状态链,还有一串隐含状态链。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8
一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,以及隐含状态(骰子)之间存在转换概率(transition probability)。在我们这个例子里,D6的下一个状态是D4,D6,D8的概率都是1/3。D4,D8的下一个状态是D4,D6,D8的转换概率也都一样是1/3。这样设定是为了最开始容易说清楚,但是我们其实是可以随意设定转换概率的。比如,我们可以这样定义,D6后面不能接D4,D6后面是D6的概率是0.9,是D8的概率是0.1。这样就是一个新的HMM。
同样的,尽管可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。产生2,3,4,5,6的概率也都是1/6。我们同样可以对输出概率进行其他定义。比如,我有一个被赌场动过手脚的六面骰子,掷出来是1的概率更大,是1/2,掷出来是2,3,4,5,6的概率是1/10。
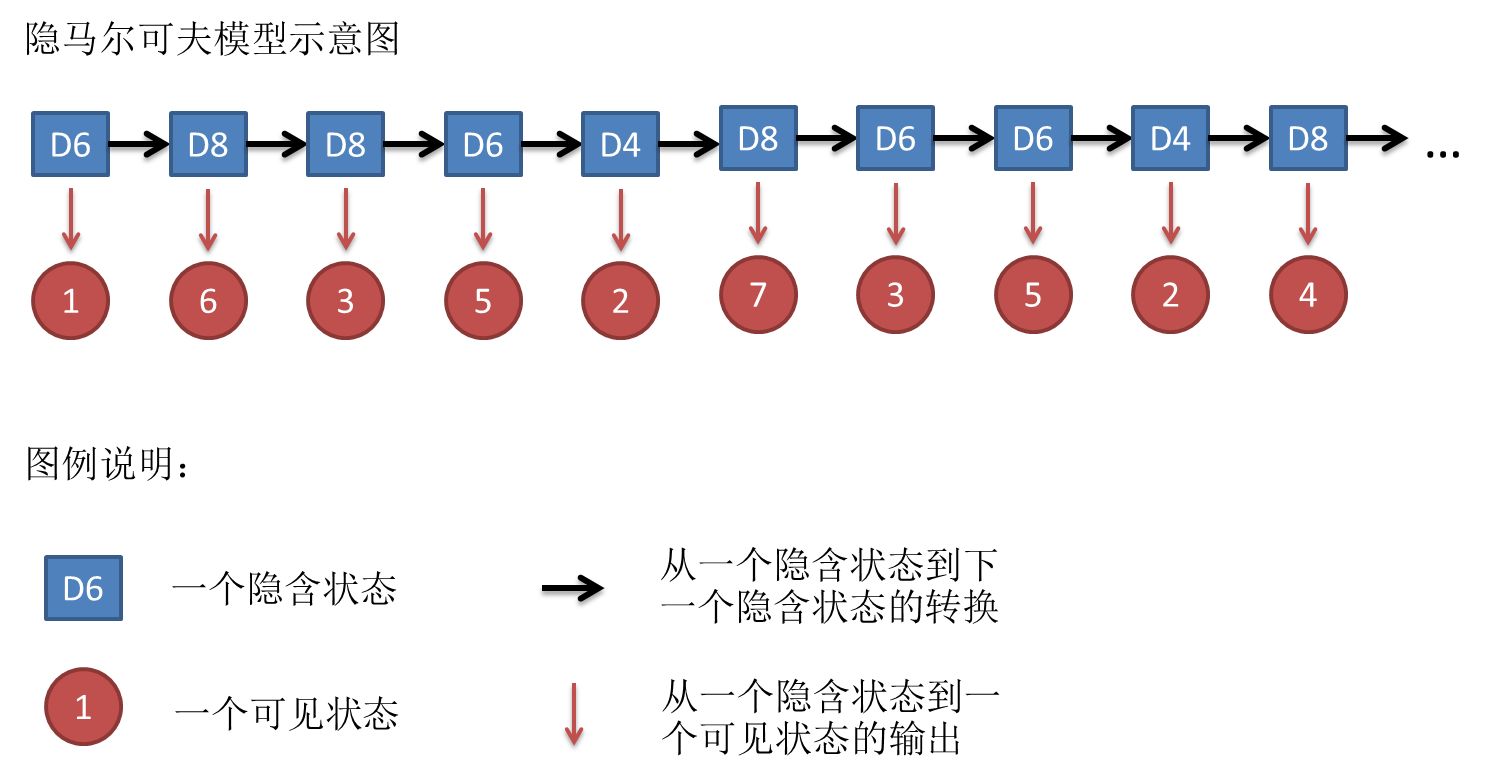

其实对于HMM来说,如果提前知道所有隐含状态之间的转换概率和所有隐含状态到所有可见状态之间的输出概率,做模拟是相当容易的。但是应用HMM模型时候呢,往往是缺失了一部分信息的,有时候你知道骰子有几种,每种骰子是什么,但是不知道掷出来的骰子序列;有时候你只是看到了很多次掷骰子的结果,剩下的什么都不知道。如果应用算法去估计这些缺失的信息,就成了一个很重要的问题。这些算法我会在下面详细讲。
2)归纳
HMM模型中有几个基本元素:
- 隐态集合Q:所有骰子的种类,设为N种
- 可见态集合V:也叫观测态集合,记做M种, 即所有可能投出的数字
- 隐态的状态转移概率矩阵A:
N*N的一个矩阵,表示每一种骰子在手的状态下,转化拿其他骰子的概率;此例子为3*3的矩阵; - 可见态输出概率矩阵B:
N*M的矩阵,记录每一个隐态下出现不同可见态的概率;也就是每一个骰子投出每一种数字的可能性; - 隐态链 I:投出骰子的序列;
- 可见态链 O:也叫观测序列,指投出的数字序列;
- 初始状态概率向量 π:表示初始时刻,出在某个隐态的概率;是一个N维向量;这里表示一开始投掷的时候,拿到的第一个骰子是哪一种的记录向量;
HMM模型由初始状态概率向量 π, 隐态的状态转移概率矩阵A, 可见态输出概率矩阵B决定;π 和 A决定了隐态序列,B 决定了可见态序列;因此,HMM模型可以用三元符号表示:
λ
=
(
A
,
B
,
π
)
\lambda = (A, B ,π)
λ=(A,B,π)
A,B,π 称为隐马尔可夫模型的三要素;
和HMM模型相关的算法主要分为三类,分别解决三种问题:概率问题、学习问题、预测问题;下面分别解释;
3)求解
HMM可以归类为三种问题:
1)概率计算问题:给定模型 λ \lambda λ 和 观测序列 O = ( o 1 , o 2 , . . . , o T ) O=(o_1, o_2, ..., o_T) O=(o1,o2,...,oT), 计算在模型 λ \lambda λ 下观测序列O出现的概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ) ;
也就是说我知道骰子有几种, 骰子转换概率知道,每一种骰子投出的每一种数字的概率知道,初始状态拿到哪一种骰也知道,现在我看到了一个数字序列,我想知道投出这个数字序列的概率是多少?
2)学习问题:已知观测序列 O = ( o 1 , o 2 , . . . , o T ) O=(o_1, o_2, ..., o_T) O=(o1,o2,...,oT),需要估计模型参数 λ = ( A , B , π ) \lambda = (A, B , π) λ=(A,B,π) ,使得在该模型下,观测序列的概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ)最大;
用极大似然的方法估计参数;
3)预测问题:已知模型 λ = ( A , B , π ) \lambda = (A, B , π) λ=(A,B,π) 和观测序列 O = ( o 1 , o 2 , . . . , o T ) O=(o_1, o_2, ..., o_T) O=(o1,o2,...,oT),求在该观测序列下,最有可能出现的隐态序列 I,即求条件概率 P ( I ∣ O ) P(I|O) P(I∣O)最大下的 隐态链 I;
预测问题也叫解码问题,
3.1 概率计算问题的解法
3.1.1 直接计算法
直接计算法理论上可行,但实际不可行,没有实用价值;看到这个求解概率问题,很容易想到联合概率公式来求解:
举个例子:假设知道骰子有几种,每种骰子是什么,每次掷的都是什么骰子,根据掷骰子掷出的结果,求产生这个结果的概率。
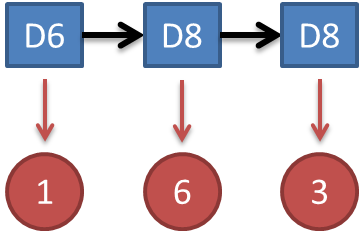
很简单,可以用联合概率,进行概率相乘:
P
=
P
(
D
6
)
∗
P
(
D
6
→
1
)
∗
P
(
D
6
→
D
8
)
∗
P
(
D
8
→
6
)
∗
P
(
D
8
→
D
8
)
∗
P
(
D
8
→
3
)
=
1
3
∗
1
6
∗
1
3
∗
1
8
∗
1
3
∗
1
8
P = P(D_6)*P(D_6 → 1)*P(D_6 → D_8 )*P(D_8→6)*P(D_8→D_8)*P(D_8→3)\\=\frac{1}{3}*\frac{1}{6}*\frac{1}{3}*\frac{1}{8}*\frac{1}{3}*\frac{1}{8}
P=P(D6)∗P(D6→1)∗P(D6→D8)∗P(D8→6)∗P(D8→D8)∗P(D8→3)=31∗61∗31∗81∗31∗81
这里我们已经确定了隐态链为D6 D8 D8; 回到概率计算问题上,这时你并不知道隐态链是什么;所以你需要列举所有可能长度为3的隐态链;计算每一种隐态链的概率,然后求和得到最终概率;问题就出在这里,考虑一下隐态链有多少种呢?
N
T
N^T
NT 种,这是一个以序列长度
T
T
T为指数的数字,虽然在这个例子中只有9种,不是很多,但在实际问题中,这个指数是很大的,计算不现实,所以说这个方法实际不可用;
3.1.2 前向算法
考虑一下直接计算法的弊端,分析一下,我们发现我们计算的粒度不妥当,我们是以每一种隐态链作为粒度,计算出每一种隐态链的概率后求和,这太多了;转换一下思路,不如我们以每一个时刻作为粒度来计算概率;《统计学习方法》中定义了成为前向概率的概念:
定义(前向概率):给定HMM模型 λ \lambda λ , 定义 到时刻t部分观测序列为 o 1 , o 2 , . . . , o t o_1,o_2,...,o_t o1,o2,...,ot ,且隐态为 q t q_t qt 的概率为前向概率,记做 a t ( i ) = P ( o 1 , o 2 , . . . , o t , i t = q t ∣ λ ) a_t(i) = P(o_1,o_2,...,o_t, i_t=q_t|\lambda) at(i)=P(o1,o2,...,ot,it=qt∣λ)
可以递推的求得前向概率 a t ( i ) a_t(i) at(i)以及观测概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ)
还是上面那个例子,从观测态出发;
首先,假设如果我们只丢一次骰子:
可以如下计算:
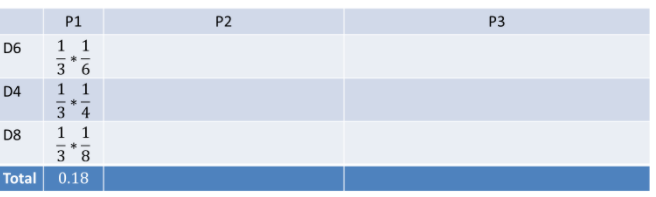
把这个情况扩展,投掷两个骰子;

每一个时刻,我们都可以计算出到此时间刻所有隐态的总概率,也就是定义中的前向概率;随意,只要按照一步一步的计算就可以算出我们的目标概率了,也就是观测链出现的概率,问题得以求解;
如下图, 求出最终概率为0.03:
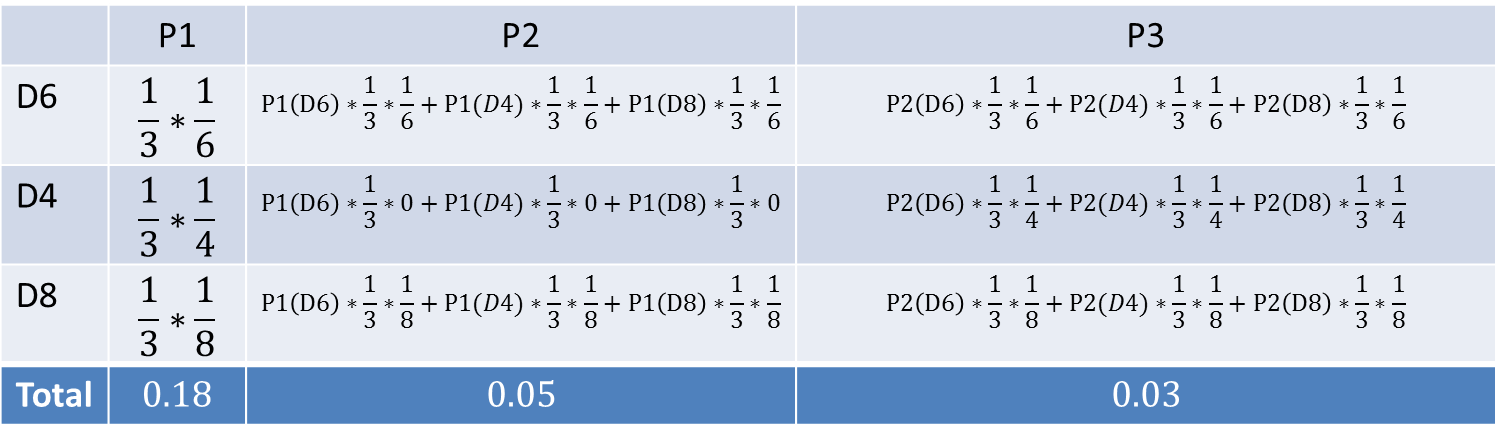
利用前向算法的计算量是 O ( N 2 T ) O(N^2T) O(N2T)阶的,而直接计算法是 O ( N T T ) O(N^TT) O(NTT)阶;
3.2.3 后向算法
后向算法和前向算法雷同,都是按照时刻计算概率,只是计算方向不同,从后开始往前计算:
后向算法的定义如下
定义(前向概率):给定HMM模型 λ \lambda λ , 定义 在时刻t且隐态为 q t q_t qt 的条件下, 从t+1 到T的部分观测序列为 o t + 1 , o t + 2 , . . . , o T o_{t+1},o_{t+2},...,o_T ot+1,ot+2,...,oT ,的概率为后向概率,记做 $\beta_t(i) $
这里不赘述了;
3.2 学习问题解法
回顾一下学习问题的定义:已知观测序列 O = ( o 1 , o 2 , . . . , o T ) O=(o_1, o_2, ..., o_T) O=(o1,o2,...,oT),需要估计模型参数 λ = ( A , B , π ) \lambda = (A, B , π) λ=(A,B,π) ,使得在该模型下,观测序列的概率 P ( O ∣ λ ) P(O|\lambda) P(O∣λ)最大;
我们需要估计模型参数;这里我们只知道观测序列,没告诉我们隐态序列;实际上,可以根据数据集是否提供隐态序列,我们可以把这个问题划分为监督学习和无监督学习,所以问题分两种;
1)观测序列和隐状态序列都给出,求HMM。这种学习是监督学习。
2)给出观测序列,但没给出隐状态序列,求HMM,这种是非监督学习,利用Baum-Welch算法(也就是EM算法)。
对于序列标注的问题;隐态可以当做序列的标签,观测态为原始序列数据;
这章分别介绍学习问题的解法
3.2.1 监督学习算法;
监督学习算法非常简单,利用极大似然估计法来估计参数;
1)隐态的状态转移概率
a
i
j
a_{ij}
aij
a
i
j
=
T
i
j
∑
j
=
1
N
T
i
j
,
i
=
1
,
2
,
.
.
.
,
N
;
j
=
1
,
2
,
.
.
.
N
a_{ij} = \frac{T_{ij}}{\sum_{j=1}^{N}T_{ij}},\\ i=1,2,...,N; \quad j = 1,2,...N
aij=∑j=1NTijTij,i=1,2,...,N;j=1,2,...N
这个式子中,我们设训练集中,时刻t处于状态i; 时刻t+1处于状态j 的频数为
T
i
j
T_{ij}
Tij
例如,在掷骰子的游戏中,我们的数据集中记录了所有的隐态链,我们想知道D4→D6的转换概率;则应该统计所有从D4开始到其他骰子的数目和目标D4到D6的数目;相除得到频率;
2)可见态输出概率 b j ( k ) b_j(k) bj(k)
同上,计算频率得到每一颗骰子投出每一种数字的概率值;
3)初始状态概率估计;
计算所有隐态链的初始时刻每一种隐态的概率;
由于监督学习需要使用标注的训练数据,而人工标注的训练数据往往代价很高,有时会利用无监督学习的算法;下面介绍;
3.2.2 Baum-Welch算法;
Baum-Welch算法本质是EM算法;
上述有监督条件下,我们已经知道了隐态链 I I I,现在呢,我们不知道,那如果 I I I已知,就可以利用上述极大似然法来估计各项概率了;问题是我们不知道,怎么办?答案是,自己假设。
通俗来讲,我们可以先假设出我们模型参数是什么,即假设出
λ
\lambda
λ ; 这个参数就相当于是预设的参数,记做
λ
‾
\overline{\lambda}
λ ; 我们可以根据这个预设的模型计算出在这组参数下最有可能的输出状态;那我们就可以计算出来,在这个预测参数下,观测序列出现的概率:
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ) , 见下式;而我们可以假设很多模型参数
λ
1
,
.
.
.
,
λ
n
\lambda_1, ...,\lambda_n
λ1,...,λn ,概率最大的那个不就是我们要找的参数吗;
P
(
O
∣
λ
)
=
∑
I
P
(
O
∣
I
,
λ
)
P
(
I
∣
λ
)
P(O|\lambda) = \sum_I P (O|I, \lambda) P(I|\lambda)
P(O∣λ)=I∑P(O∣I,λ)P(I∣λ)
具体算法步骤如下:
在步骤之前,先引入一个概念:完全数据的对数似然函数: l o g P ( O , I ∣ λ ) log{P(O, I|\lambda)} logP(O,I∣λ)
1)什么是完全数据,像HMM问题中,存在隐态链和可见态链;隐态链 I = ( i 1 , i 2 , . . . , i T ) I = (i_1, i_2,...,i_T) I=(i1,i2,...,iT) 可见态链 O = ( o 1 , o 2 , . . . , o T ) O=(o_1, o_2,...,o_T) O=(o1,o2,...,oT) ; 完全数据就是两个都知道,我们表示成 ( O , I ) = ( i 1 , i 2 , . . . , i T , o 1 , o 2 , . . . , o T ) (O, I) = (i_1, i_2,...,i_T, o_1, o_2,...,o_T) (O,I)=(i1,i2,...,iT,o1,o2,...,oT) ;
完全数据出现的概率记做 P ( O , I ∣ λ ) P(O, I|\lambda) P(O,I∣λ) ;
2)对其求对数,就得到对数似然函数: l o g P ( O , I ∣ λ ) log{P(O, I|\lambda)} logP(O,I∣λ)
完全数据的概率和对数概率可以衡量在参数 λ \lambda λ下,完全数据出现的概率;
1)首先,进行初始化,得到 λ ‾ \overline{\lambda} λ。
2)计算Q函数(计算隐态链的期望):
Q
(
λ
,
λ
‾
)
=
∑
I
[
l
o
g
P
(
O
,
I
∣
λ
)
]
⋅
P
(
O
,
I
∣
λ
‾
)
Q(\lambda, \overline{\lambda}) = \sum_I [log{P(O, I|\lambda)] \cdot P(O,I|\overline{\lambda})}
Q(λ,λ)=I∑[logP(O,I∣λ)]⋅P(O,I∣λ)
引入另外一个概念,Q函数: Q ( λ , λ ‾ ) = ∑ I l o g P ( O , I ∣ λ ) P ( O , I ∣ λ ‾ ) Q(\lambda, \overline{\lambda}) = \sum_I log{P(O, I|\lambda)P(O,I|\overline{\lambda})} Q(λ,λ)=∑IlogP(O,I∣λ)P(O,I∣λ)
Q函数是由两部分概率相乘得到的联合概率:预测参数下完全数据出现的概率和要极大化的模型参数下完全数据出现的概率;这个Q函数实际上是衡量隐态链 I I I在该假设条件下的期望;
上式公式需要注意两点,第一,仅仅取 P ( O , I ∣ λ ) P(O,I|λ) P(O,I∣λ)的对数, P ( O , I ∣ λ ‾ ) P(O,I|\overline{\lambda}) P(O,I∣λ)是在对数的外面;第二, 是确 P ( O , I ∣ λ ‾ ) P(O,I|\overline{\lambda}) P(O,I∣λ)定的值,即它可能为[0,1]中的任何值,根据 λ ‾ \overline{\lambda} λ算出。如果仔细观察式子的话,该式就是对随机变量 I I I求期望。即 E ( f ( I ) ) , 其 中 f ( I ) = l o g P ( O , I ∣ λ ) E(f(I)), 其中f(I) = log P (O, I|\lambda) E(f(I)),其中f(I)=logP(O,I∣λ)
3)极大化Q函数(M步:求期望的极大值)
这里推导略去,可以参考 推导(公式先改写成拉格朗日函数,然后求偏导,令结果为0),直接说结论
λ
\lambda
λ 在什么状况下取极大值:
i
i
i表示
I
I
I链的某一个时刻
π
i
=
P
(
O
,
i
1
=
i
∣
λ
‾
)
P
(
O
∣
λ
‾
)
a
i
j
=
∑
t
=
1
T
−
1
P
(
O
,
i
t
=
i
,
i
t
+
1
=
j
∣
λ
‾
)
∑
t
=
1
T
−
1
P
(
O
,
i
t
=
i
∣
λ
‾
)
b
j
(
k
)
=
∑
t
=
1
T
P
(
O
,
i
t
=
j
∣
λ
‾
)
I
(
o
t
=
v
k
)
∑
t
=
1
T
P
(
O
,
i
t
=
j
∣
λ
‾
)
π_i = \frac{P(O, i_1=i|\overline{\lambda})}{P(O|\overline{\lambda})}\\ a_{ij} = \frac{\sum_{t=1}^{T-1}P(O,i_t=i, i_{t+1} = j|\overline{\lambda})}{\sum_{t=1}^{T-1}P(O, i_t=i|\overline{\lambda})}\\ bj(k) = \frac{\sum_{t=1}^{T} P(O, i_t = j|\overline{\lambda})I(o_t=v_k)}{\sum_{t=1}^{T}P(O,i_t=j|\overline{\lambda})}
πi=P(O∣λ)P(O,i1=i∣λ)aij=∑t=1T−1P(O,it=i∣λ)∑t=1T−1P(O,it=i,it+1=j∣λ)bj(k)=∑t=1TP(O,it=j∣λ)∑t=1TP(O,it=j∣λ)I(ot=vk)
需要注意的是第三个公式,计算某个骰子掷出某个数字的概率;拉格朗日约束条件是
∑ k = 1 M b j ( k ) = 1 \sum_{k=1}^{M}b_j(k)=1 ∑k=1Mbj(k)=1
注意,只有在 o t = v k o_t=v_k ot=vk时 , b j ( o t ) 对 b j ( k ) b_j(o_t)对b_j(k) bj(ot)对bj(k)的偏导数才不为0,以 I ( o t = v k ) I(o_t=v_k) I(ot=vk)表示;
3.3 预测问题解法
预测问题的定义:已知模型 λ = ( A , B , π ) \lambda = (A, B , π) λ=(A,B,π) 和观测序列 O = ( o 1 , o 2 , . . . , o T ) O=(o_1, o_2, ..., o_T) O=(o1,o2,...,oT),求在该观测序列下,最有可能出现的隐态序列 I,即求条件概率 P ( I ∣ O ) P(I|O) P(I∣O)最大下的 隐态链 I;
预测问题也叫解码问题;介绍解决该问题的两种算法:近似算法和维特比算法;
3.3.1 近似算法
近似算法的思想很简单,在每一个时刻 t t t ; 我们都可以计算出在已知模型和观测序列的条件下,该时刻的所有隐态的概率值;将其中最大的概率值近似认为是当前时刻的概率值;
例如在上述掷骰子的游戏中:
一直模型和序列 1 6 3 ;从第一个时刻开始计算:
P
(
D
6
)
=
P
(
π
→
D
6
)
⋅
P
(
1
∣
D
6
)
=
1
3
⋅
1
6
P
(
D
4
)
=
P
(
π
→
D
4
)
⋅
P
(
1
∣
D
4
)
=
1
3
⋅
1
4
P
(
D
8
)
=
P
(
π
→
D
8
)
⋅
P
(
1
∣
D
8
)
=
1
3
⋅
1
8
P(D_6) = P(π→D_6) \cdot P(1|D_6) = \frac{1}{3} \cdot \frac{1}{6}\\ P(D_4) = P(π→D_4) \cdot P(1|D_4) = \frac{1}{3} \cdot \frac{1}{4}\\ P(D_8) = P(π→D_8) \cdot P(1|D_8) = \frac{1}{3} \cdot \frac{1}{8}\\
P(D6)=P(π→D6)⋅P(1∣D6)=31⋅61P(D4)=P(π→D4)⋅P(1∣D4)=31⋅41P(D8)=P(π→D8)⋅P(1∣D8)=31⋅81
所以第一个时刻,概率最大的隐态为 D4 ; 那我们近似隐态链的第一个时刻为D4;
确定了第一个时刻就可以计算第二个时刻的概率, 同样将最大概率的隐态作为目标隐态确认下来:
P
2
(
D
n
)
=
P
(
D
4
→
D
n
)
⋅
P
(
6
∣
D
n
)
P2(D_n) = P(D_4 → D_n) \cdot P(6|D_n)
P2(Dn)=P(D4→Dn)⋅P(6∣Dn)
分析一下不难发现,这种按照时间序列逐个计算最大概率的方法,属于贪心策略,只考虑眼前这一步概率最大,而不是整体隐态链的概率最大;所以近似算法虽然简单,但是不能保证预测状态就是最优的;而我们实际应用的往往是全局最优解,下面介绍维特比算法;
3.3.2 维特比算法
维特比算法实际上是用动态规划求解;即用动态规范求概率最大路径;
所谓动态规划,就是有条件的穷举,我们只需要从时刻 t = 1 t=1 t=1 开始,递推地计算在时刻 t t t 隐态为 i i i 的各条部分路径中的最大概率,保留该路径,直至得到时刻 t = T t=T t=T 状态位 i i i 的各条路径的最大概率,时刻 t = T t=T t=T的最大概率对应的路径即为最优的路径;
举个例子,在这个掷骰子的游戏中,从第一个时刻出发;·每一种隐态只有一个路径,那就是 π → D n π→D_n π→Dn 不用考虑;
到第二是时刻,每一个隐态(状态)有三条路径: π → D 4 → D n π→D4→D_n π→D4→Dn ; π → D 6 → D n π→D6→D_n π→D6→Dn; π → D 8 → D n π→D8→D_n π→D8→Dn ;只需要保留一条到达此时刻状态的最佳路径即可;继续往下走,直至完成整个隐态链;
4)总结
总结一下,
1)HMM问题有7个基本元素,
隐态集合Q;可见态集合V;隐态的状态转移概率矩阵A;可见态输出概率矩阵B;隐态链 I;可见态链 O;初始状态概率向量 π
通常表示HMM模型有三个部分,模型参数 λ = ( A , B , π ) \lambda = (A, B ,π) λ=(A,B,π),可见态链,隐态链;
2)于HMM相关的问题分为三类:概率计算问题,学习问题,预测问题;
参考链接 :
https://www.zhihu.com/question/20962240
https://blog.youkuaiyun.com/xueyingxue001/article/details/51374100
🍅

















 981
981

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









